OO_第一单元总结
前言
第一单元的题目是表达式化简,涉及因子:
|
|--变量因子
| |--幂函数
| |--三角函数
| |--自定义函数调用
| |--求和函数
|--常数因子
| |--带符号整数
|--表达式因子
. |--'('表达式')'
项由因子相乘构成,表达式由因子相加/减构成。
大致要求:展开所有括号(除三角函数括号),由答案长度判定性能。
一.整体思路简介
1.结构分析
程序结构如下
│
│ MainClass(主类)
│ AnswerParse(化简表达式)
│ Atom(形成答案的基本原子,形式:系数*x**指数*三角函数*三角函数*...)
│
├─Factor
│ Factor(所有因子的父类)
│ Expr(表达式)
│ Term(项)
│ Number(带符号整数)
│ Trig(三角函数)
│ Var(幂函数)
│
├─Math
│ AddSub(加减法)
│ Mul(乘法)
│
└─Parse
ParseFirst(分析输入表达式,替换求和函数以及自定义函数)
SumParse(求和函数替换)
Def(保存自定义函数)
DefParse(自定义函数替换)
2.思路简介
对传入表达式进行解析
1.替换自定义函数以及求和函数(ParseFirst)
2.分析表达式,依加减号拆分为项(Expr.analysis())
3.分析项,依乘号拆分为因子(Term.analysis())
4.因子转换为Atom类型,并在term、Expr进行计算合并
5.化简输出
3.类图


4.化简思路
- 在分析计算时,于atom级合并表达式成为“系数*x**指数*三角函数*三角函数*...”的最简形式,在加减类和乘法类里,最大限度合并可以合并的项,例如在加减类,把除了系数外其他元素相同的项合并等。
- 输出结果,按系数从大到小排列,优先输出系数为正的数据,省略加号
- x**2更改为x*x,sin(0)、cos(0)分别化简为0、1,将指数为0的因子化简为1
- 我对于三角函数公式化简比较谨慎,考虑到部分同学性能优化导致答案出现问题,或者程序TLE,我在观察了强测的答案后,最终选择仅采用sin(x)**2+cos(x)**2 = 1的化简方法,具体实现为把cos(x)**2更改为1-sin(x)**2,将一个项变为两个项,代入结果,最后进行加减法合并化简。
- 由于cos()函数为偶函数,可以考虑将()内的因子负号去掉
在化简部分的确做得不够好,但是在保证正确性的前提下,最终结果还不是很差。后两次作业都有三个测试点总分近80,还有很大的提升空间。希望以后的作业可以合理分配精力,努力提高一下性能分。
二.程序分析
1.度量分析
方法复杂度分析(仅展示了部分圈复杂度较大的方法)
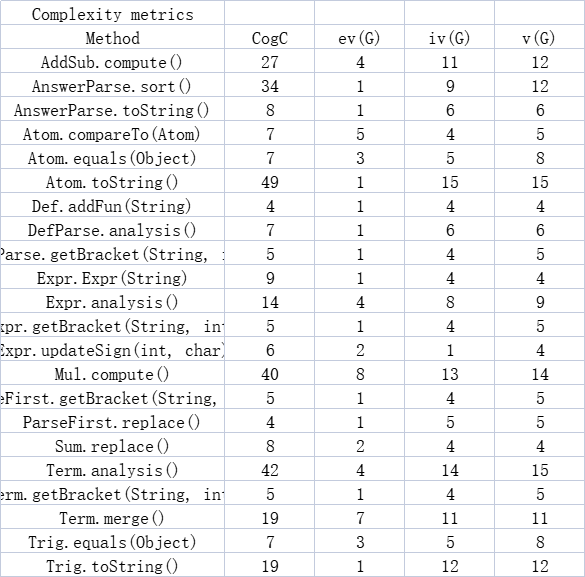
圈复杂度饼状图
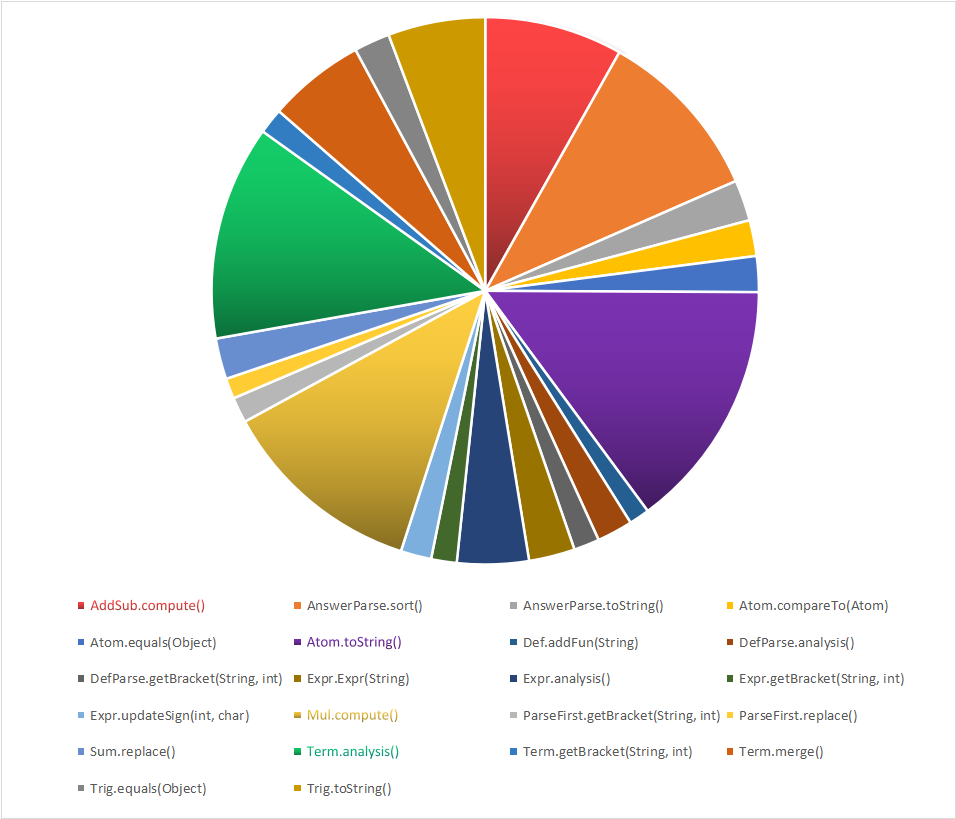
类复杂度分析
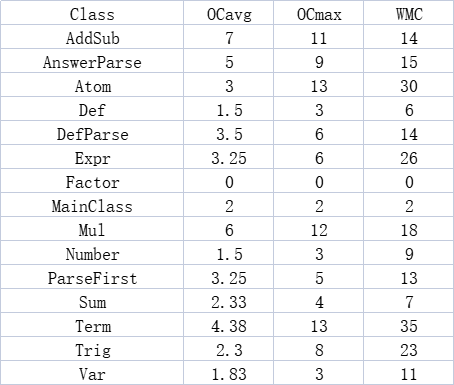
圈复杂度总和饼状图(类)
2.耦合度&复杂度分析
关注两个指标:
- v(G),圈复杂度,数值越大,意味着代码中错误的可能性更大,维护的成本更高。
- iv(G),设计复杂度,数值越大,意味模块耦合度高,可读性及可维护性差。(衡量指标是模块和其他模块的调用关系)
程序部分方法iv(G)较大,说明这些方法的耦合度高,内聚性差,模块的可重用性、移植性较差。
Trig.toString()方法,分析后发现这个方法是多余的,忘删了- Term.analysis()方法,耦合度高,因为在分析因子时,调用了各种因子类,并且在这一步尝试初步化简。
- Term.merge()方法,将analysis得到的因子进行初次合并化简,调用了乘法运算,耦合度较高。
- AddSub以及Mul的compute方法,多次调用atom类以及Trig类,在atom级进行运算并合并,耦合度较高。
- Atom.toString()方法,在atom级化简,由于调用了许多因子类,耦合度较高。
饼状图显示,v(G)较大的四个方法分别为AddSub和Mul类里的compute,Atom类里的toString,以及Term类里的analysis,原因大致同上。
为了达到表达式最简化,Term.analysis()里使用了众多的判断条件,企图在事先分析出sin(0)、cos(0)、去掉表达式因子的括号、将指数为0的因子直接存为1,然而由于圈复杂度过大,这个部分也包含了一个很严重的bug。
三.BUG分析
1.作业bug分析
在前两次作业中,未发现bug。
在第三次作业中,在互测时发现了一个bug————忘记在sumParse把i的替换值两边加上括号。这个bug导致对于i=-1,i**2的类型的替换出错,错误结果是-1**2 = -1,而正确的答案是(-1)**2 = 1。
由于我在本地生成的随机数据不包含sum,导致这一个点没有被测试到,这也是我测试做得不够完善的原因。
另外一个强测以及互测都没有被发现的bug,就在圈复杂度高达42的Term.analysis()里。
重写了三角函数类的equals方法后,我判断的两个三角函数equals是指数相等,三角函数类型相等,三角函数括号内的元素相等。
在Term.analysis(),我想判断一个三角函数组里面是否包含一个三角函数,和指定的另一个三角函数类型、括号内元素相等,可是判断代码写成了:
if(trig.contains(trig)){...}
这就导致,判断的条件加了一个指数相等,把某些符合条件的数组略去了,直接引发了后面乘法模块的错误。
实际上,较短的随机数据无法测出我的bug,我在本地随机生成的十几万条数据长度都限制在了35,调整为50,就能发现错误的样例。
2.自动化测试
主要借助了python的sympy库来进行测试,在本地生成测试数据,利用自己的数据和sympy化简结果进行对拍。
但是sympy不能化简带前导零的整数,而且对于一些三角函数里面带两层括号的较长的输出,也会显示不匹配,只能靠人眼比对,目前不清楚为什么。
借鉴讨论区后,找到了可以一次对拍多人的方法。后面在互测阶段,进行黑盒测试的时候会轻松点。
3.总结
- 本地测试,代码努力做到全覆盖
- 充分做边界数据的测试
四.架构设计体验
1.迭代
- 第一次,从0开始构建代码时最为艰难,甚至思考了好久都没敢开始,一直在想思路,现在的架构其实是开始就想出来的,但也是在否定完后面所有的设想后,才选择了最初的思路。第一次设计架构的时候,将表达式因子单独作为一个类提出,程序不支持多层嵌套。
- 第二次,在第一次的基础上,将表达式因子类和表达式类合并。增加了三角函数,自定义函数和求和函数调用,发现了HashMap的离奇之处。就像助教解释的“将对象【放入 HashSet】或【作为 HashMap 的 Key】时,一定要注意保持这个对象的【不可变性】——即:放进去之后就不能修改这个对象。否则整个哈希表的结构就会产生混乱,引发一些非常奇怪的 bug,而且这个比较难调试”。
- 第三次,在第二次的基础上,将所有的HashMap换为ArrayList,增加了sin(x)**2+cos(x)**2 = 1 的优化。
这三次作业起码没有经历重构,还是节省了不少的时间。
2.讨论课及课堂知识
- 注意类的设计,只把这个类该有的属性和方法赋给它。在第二次迭代的时候,把数学运算从term和expr类里面抽离出来,另外设计了加减运算类和乘法运算类。
- 对于题面给的要求,进行合理地变通。例如把**换为^,把小x换为大X等,的确可以很方便处理。
3.第一单元完结体验
开始迟迟没有定下具体思路,周二一整天,都在不断地否定中,进度为0,其实还是很慌的,担心自己第一次作业就寄掉,后来,最终确定思路,并把它实现的那一刻,十分开心。整体上看,很好理解题意,设计程序的时候思路可以更清晰,也可以省去很多bug,但是想得太多也不行,真正开始写代码,才能找到真正的难点所在,也才能更好理清思路。
第二次作业,大中午昏昏沉沉中一直在找一个bug,感谢助教开了个测试点,de出了一个十分傻的bug,我觉得以后还是清醒时debug比较好。
暴力替换求和函数和自定义函数真的很容易出现bug,高耦合、圈复杂度高的代码段往往是bug集中点。对容器的理解不够深,导致我出现了循环中删元素,写出的代码和自己的设想不一致等bug。
第一个月的OS任务相对轻松,我可以将大部分的时间投入到OO里面,之后随着OS的任务加重,希望我能提高效率,利用好时间,更好平衡两门专业课。
总之,要学的还很多,要努力像优化程序一样优化自身,像修复bug一样不断自省。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号