[06] 优化C#服务器的思路和工具的使用
优化C#服务器的思路和工具的使用
优化服务器之前, 需要先对问题的规模做合理的预估, 然后对关键的数据做采样, 做对比, 看和自己的预估是否一致, 误差大在什么地方, 是预估的不对, 还是系统实现有问题.
策划对某游戏服务器的要求是3000到5000人在线.
大概的估算
玩了玩游戏, 在前期任务的流程中, 客户端对服务器发生的有效请求数, 实际上是比较少的. 跑路, 点击NPC, 打怪等等, 每一个状态变化中间需要的时间实际上是比较长的. 所以一秒的请求数应该是在0.5~1.0qps左右.
战斗因为是无目标的ARPG, 一点砍瓜切菜的感觉, 输入大概在1.0~2.0qps, 输出就比较高了, 目测系数有5.0~10.0. 也就是一个请求, 可能对应5-10个返回回来. 而且很有可能会有多个广播包.
移动和普通的MMOG差别不是很大, 只是如果用键盘操作的话, 状态变化会非常频繁; 如果是手机的话, 应该在1.0qps左右, 应该就够了. 唯一需要处理的就是广播系数, 周围的玩家越多, 需要广播的包就越多. 某游戏服务器一个场景大概有40~50人. 目测系数有10.0左右.
还有DB IO, 也需要估算, 因为单次操作比较耗时. 战斗过程中大概率是不需要访问DB的, 移动也是, 只有普通的任务和养成系统对DB写依赖比较高; 然后玩家登陆过程中, 因为游戏内有大量的系统, 可能需要10次load操作. 所以按照以往的经验, 卡牌类型的游戏1.0~2.0qps, 那么这个ARPG游戏服务器可能就0.5~1.0qps的样子.
采集数据
最开始处理的MongoDB的读写数据采样. 按照我们的估算, load一个玩家需要10个DB操作, 一个玩家在线大概只需要0.5~1.0个DB操作. 但是我们用机器人去跑, 发现处理MongoDB读写的队列经常因为过大, 进而系统OOM.
所以, 对已经完成DB操作, 和正在队列中的DB操作进行统计分析, 需要统计的数据:
-
类型(简单标注一下自己是哪个系统的)
-
文件, 行数(进行准确的追踪)
C#有
CallerLineNumber,CallerFilePath, 可以方便在编译时期获取类似于C/C++的__FILE__,__LINE__.
下来采集的是客户端的输入, 和发送给客户端的返回.
还有一种采集, 就是内存快照, 可以通过dotMemory来搞, 直接用VS获取内存快照最后会发现看不清楚. dotMemory在这方面做得不错.
处理思路
我在计算机程序设计艺术第一卷这本书里面学到一个东西, 就是时间复杂度和系数. 我们在一般的数据结构或者算法书里面只会看到时间复杂度的大概分析, 不会告诉你准确的公式是什么样子的.
然而, 我们游戏里面需要处理的在线玩家数量所呈现出来的公式, 应该是一次函数:𝑓(𝑥)=𝐴𝑥+𝐵.
所以优化的思路, 肯定尽可能降低系数A. 因为我们无法降低在线玩家数量, 整个系统就一个进程, 策划还需要3000-5000人在线, 如果我们能拆进程, 那么就可以降低x.
MongoDB IO的处理
最开始用机器人做压力测试, DB队列总是会OOM. 经过采样和分析, 发现:
-
绝大部分操作都是道具上的
道具占最多这个是能想到的. 仔细研究数据和代码, 后来发现逻辑层代码有很多实现不太合. 例如:
- 生成一个道具需要写两次DB, 一次记录道具本身, 一次记录用来做道具最大ID(算唯一ID用的)
- 更新一个道具的时候, 很有可能更新了两次
- 玩家登陆的时候, 会把刚刚load的每个道具都保存一次
- 等等
这是道具本身实现不太合理的地方, 还有就是机器人程序, 测试程序本身也要设计的比较合理, 但是通过分析发现, 某一些功能对DB压力非常大. 例如:
- 某个功能机器人会把所有的装备都删一遍, 然后再加一遍
- 某个功能机器人可能会不停的添加道具(或者装备), 最后背包满了, 就要往邮件里面塞
- 类似的功能有很多等等
测试程序本身, 需要比较合理的设计, 尽可能去贴合玩家的真实操作.
-
玩家的定时存档
大部分操作都是立即存档的, 但是涉及到Player这张表, 就会延迟存档(大概1-2分钟), 这是MMOG常用的操作.
经过观察发现, 2分钟网卡流量会有一次高峰(这是正常的), 但是相应时间内计算的延迟也会增加(服务器的帧率变低了). 这在最开始也是难以想通的. 尝试过几次修改, 发现MongoDB上batch操作和单次操作都无法解决帧率变低. 后来把所有玩家的2分钟一起写变成了每个玩家自己2分钟想写一次, 把批量写换成了离散写, 帧率才稳定.
后来通过VS内存分析看到, MongoDB驱动会产生非常多的垃圾对象, 单个对象直接写和多个对象批量写最终所产生的的垃圾对象是一样多. 所以只有离散写可以降低GC的压力.
-
DB操作的时间越来越长
系统没有过载的时候, DB操作耗时还比较正常. 过载了之后DB上的操作会越来越慢, 甚至会变长. 但是单独写一个写DB的Benchmark程序去直连MongoDB就是好的.
虽然减少了很多不必要的DB操作, 系统略微可以使用, 但是单独这个优化是没有解决DB操作变长这个问题.
广播和网络IO处理
这个系列第一篇文章就讲怎么合理的网络编程. 但是实际上从NetUV更换DotNetty, 然后将整个编解码完全重新实现, 再到后面批量发送的实现, 还是消耗了一定的时间. 整个核心思想就是减少每一个包上的编解码消耗(以及产生的垃圾对象).
但是通过消息的输入输出统计分析, 还是发现一些端倪(重点关注游戏内的广播消息), 例如:
-
机器人移动一秒会发3次消息
因为客户端有预判, 不会等到服务器返回自己开始走, 服务返回之后会不断矫正的位置, 差别不大就不需要矫正.
所以机器人一秒发3次消息是不合理的, 正常情况下一秒1次左右就够了.
-
一个跳跃有4个左右的消息, 一个滑步有3个左右的消息
每次跳跃和滑步都需要使用怒气(能量类似的东西), 然后这些东西加减, 也需要同步给所有客户端, 实际上这些可以让客户端自己去模拟和维护.
还有跳跃和滑步也是, 最多1~2个输入就可以完成.
-
战斗部分
由于是无目标战斗, 所以大部分技能都是AOE技能, 砍一刀很有可能砍刀10个怪, 但是伤害如果发10个怪, 那么就需要做10个编解码, 发10次广播消息.
等等类似的东西.
内存分配的优化
内存分配的优化, 是C#服务器的关键. 这个系列文章里面大篇幅都围绕着内存分配, 整个过程下来, 对算法的优化几乎没有, 服务器内甚至连AOI都没有做, 就是去场景内定时遍历维护视野列表(可以理解为N^2时间复杂度, N上限是40~50). 这跟很多人的以往的知识是相冲突的, 但是实际上通过profile工具分析的结果这个并不是重点.
当然内存的分析就需要借助于Visual Studio了, 具体可以看前面的文章. 处理方式也比较简单--逢山开路遇水搭桥, 找到一个fix一个就行了.
比较关键的两个东西, 一个是闭包, 比如这个闭包在Player处理某个东西时候需要, 那么就把闭包和闭包的状态存在Player身上; 另外一个临时的容器, 这个比较多, 需要同ThreadLocal来搞, 每次用的时候clear一下就行了.
还有一个比较关键的是, Linux下native部分的内存分配. 服务器在WindowsServer下长时间跑, 都没有内存泄漏, 但是在Linux下跑会有内存泄漏, 最后查找原因是非托管部分泄漏了. 然后换成jemalloc之后解决, 这一点在最开始并没有想到.
计算性能的优化
这是最后需要做的事情!!! 而不是一开始需要做的.
直接去用profile工具优化性能, 会被GC极大的干扰. 例如某游戏服务器内, 30%的时间是在跑物理引擎, 物理引擎内有大量的sin/cos计算, 由于GC没有优化好, GC和sin/cos计算就有可能碰撞, 然后会发现有采样的结果里面有大量的sin/cos计算. 这是违反常识的.
直到后来GC问题解决掉了之后, 就看不到这样很离谱的结果, 包括MongoDB执行更新操作耗时越来越长这种难以解释的情况.
但是不是说系统中就没有比较好的东西了, 优化到最后, 单个耗时比较高的函数都被搞掉, 只是物理引擎的耗时没有被优化掉, 这块占整个逻辑线程30%的时间片.
考虑到5000人在线, 腾讯云SA2机型32C64G机型, 大概CPU占有率在15%的样子, 所以就没有再继续优化, 如果还想要提高人数上限, 那么就需要对物理引擎优化.
工具的使用
先优化内存, 直到GC对计算没有影响之后, 再去优化计算.
内存分配采样
这是一张采样的图片, 左下角是对象和分配次数, 右下角是分配的堆栈(可以点开, 也可以右键转到源码). 可以非常方便的找到系统内分配内存次数较多的地方.
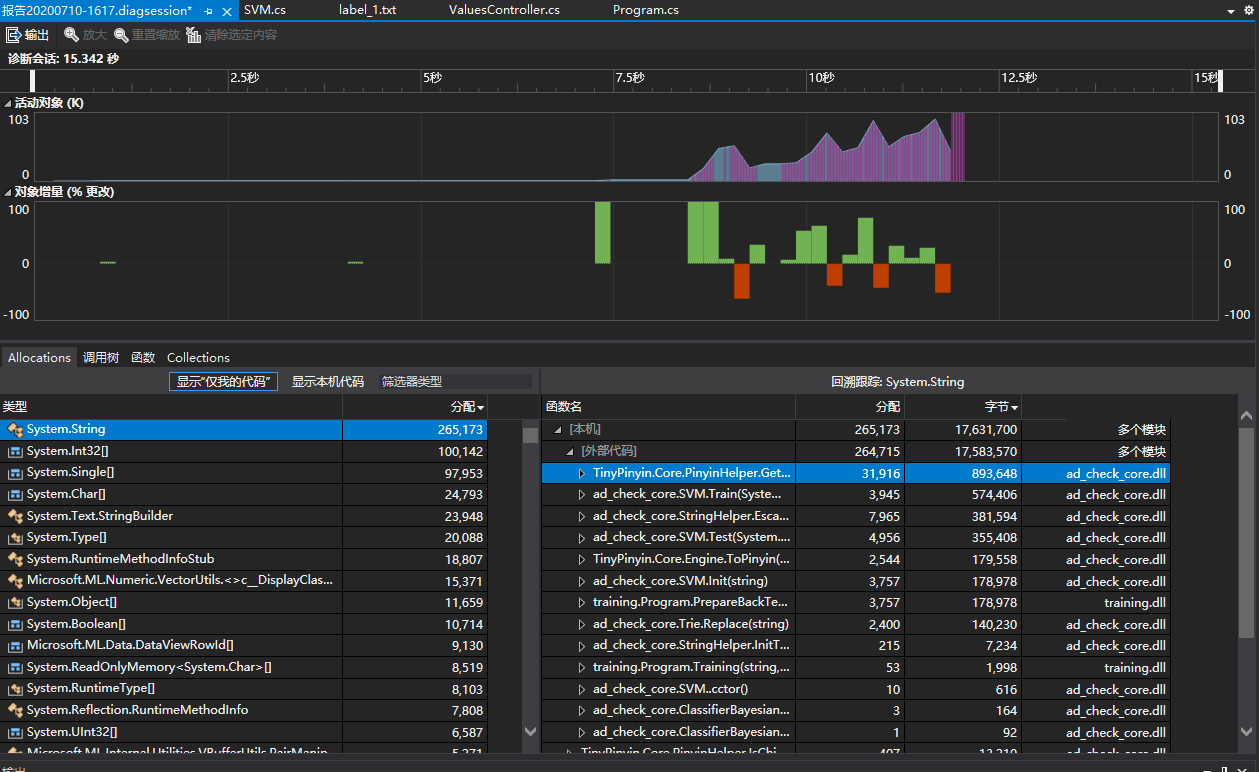
但是需要注意的是, 如果开几百个机器人访问服务器, 那么采样的时候不能每个对象都跟踪, 可以选择100个对象跟踪一次, 跑几分钟就可以了.
内存快照
dotMemory这个工具在获取内存快照这方面做得非常好, Windows和Linux下均可以使用, 其中Linux是命令行程序获取数据, 然后Windows客户端可以打开结果分析.
之前在跑机器人战斗的时候, 发现内存占用越来越大, 然后通过dotMemory获取快照, 发现LuaEnv占用内存非常多, 然后找到某一个LuaEnv, 详细的查看其内存占用.
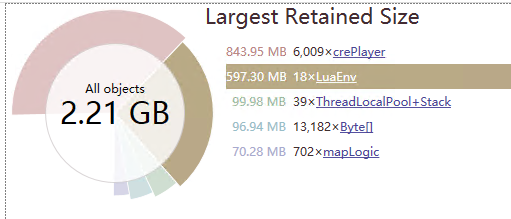
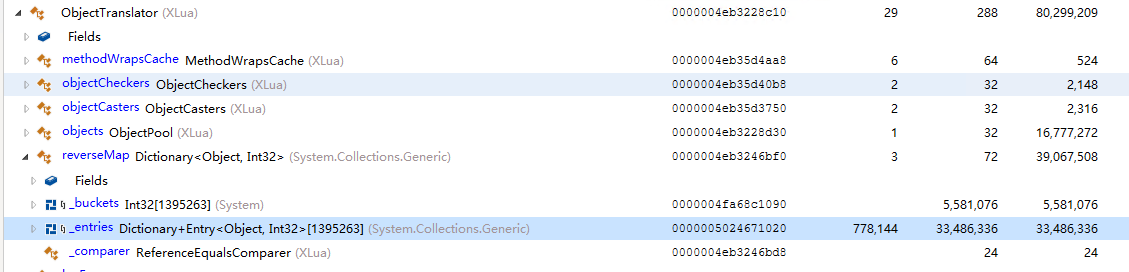
发现光这个ObjectTranslator对象就占用了33M内存, 上面100W+个元素, 后来优化Lua GC之后这个问题就不存在了(服务器大概每2帧做一次GC).
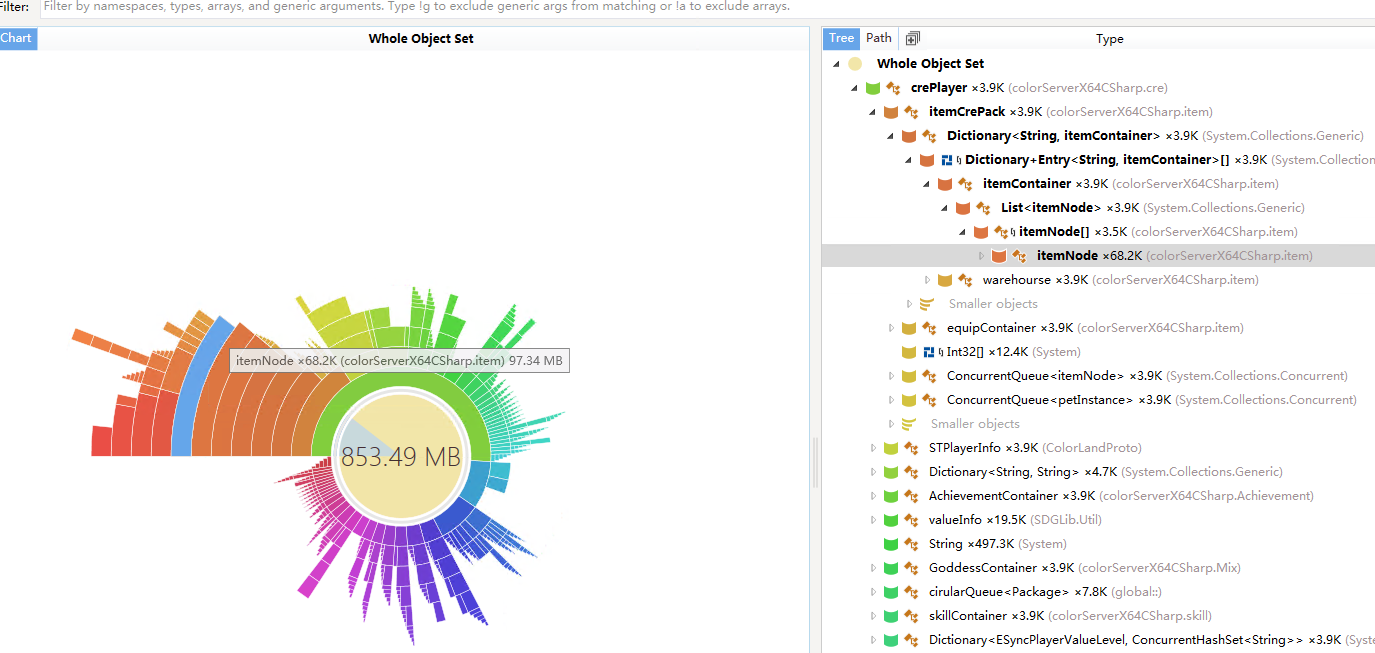
还有dotMemoryDominators, 可以分析出各个系统之间的内存占用, 例如下图中, 道具占比有一点不太正常, 研究后发现每个装备都缓存了大概25K的数据而且从来都没有使用过.
性能采样工具
之所以单独说采样工具, 是因为除了sampling技术外, 还有tracing技术也经常用于性能调优.
但是tracing工具, 本身是一个观察者, 对性能比较敏感的程序会造成影响, 最终就不知道到底是观察者有问题, 还是程序有问题, 还是GC有问题. 所以一般不太使用tracing技术, 而选用sampling技术. VS的sampling一般是1000HZ, perf的话大概选用99HZ的.
Linux下通过perf和flamegraph也能获取到图形化的数据, 这边不在赘述, 可以看之前的文章. 但是一般还是在Windows下调优好, 再上Linux上面去验证. Linux的perf只是一个辅助手段.
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号