
AI应用实战课学习总结(6)分类算法分析实战
 本文介绍了机器学习中的分类场景问题,常用的分类算法 以及 分类和回归的简单对比,最后通过一个医疗数据诊断分类的案例做了一次实战,相信对你理解分类应用应该有所帮助。
本文介绍了机器学习中的分类场景问题,常用的分类算法 以及 分类和回归的简单对比,最后通过一个医疗数据诊断分类的案例做了一次实战,相信对你理解分类应用应该有所帮助。
大家好,我是Edison。
最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第6站,一起了解下分类算法基本概念 以及 通过分类算法辅助疾病诊断的案例。
分类问题介绍
分类算法是用来预测离散标签的算法,它可以预测输入的数据标签属于哪一个类别。
举个例子,给定各种各样的垃圾,让你判断它们都是什么样的垃圾?是干垃圾,湿垃圾,有害垃圾 还是 可回收物。
分类问题实际上是输入特征后通过函数输出类别,这个类别是算法认为可能性最大的一个。

分类和回归的区别
回归问题 和 分类问题 的应用场景不同,目前分类问题的机器学习应用场景比回归问题的广泛一些。
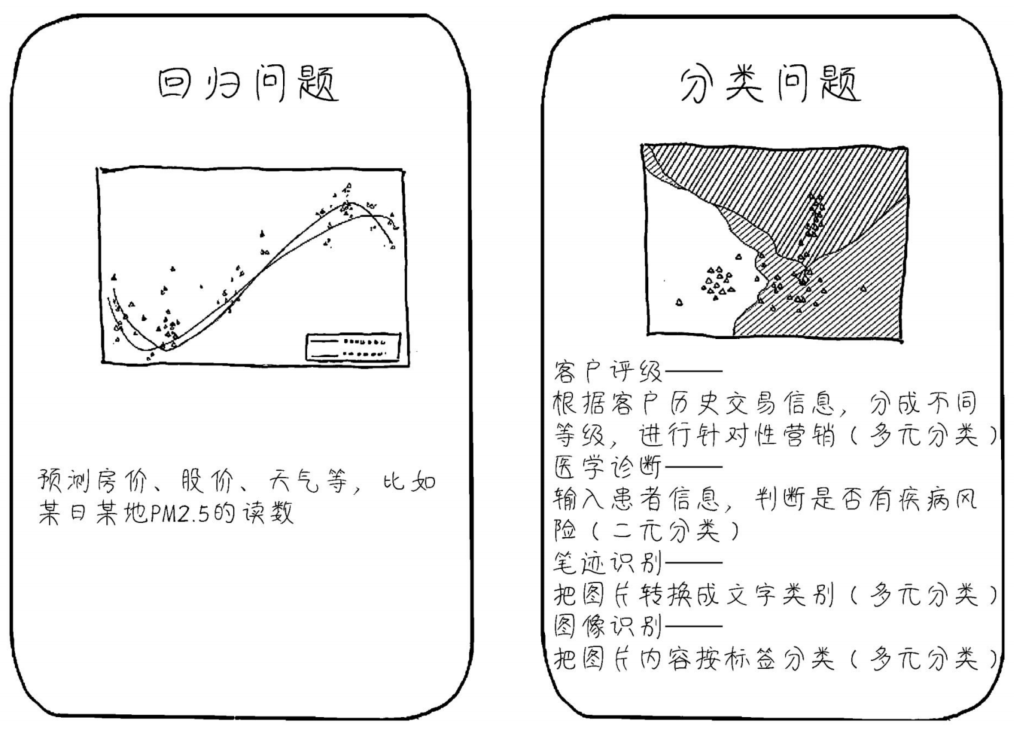
由上图可知,回归问题主要用于预测一些数值如房价、股价的场景,而分类问题则可以用于做一些客户评级、医学诊断、图像识别等等场景。
那么,回归问题 和 分类问题 在数据分布上有什么样的区别呢?回归问题主要是线性的数据分布,而分类问题则主要是离散的数据分布。
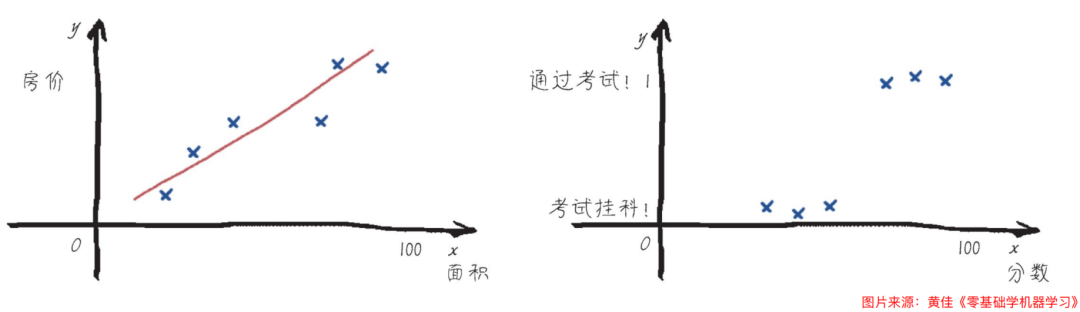
常见分类算法
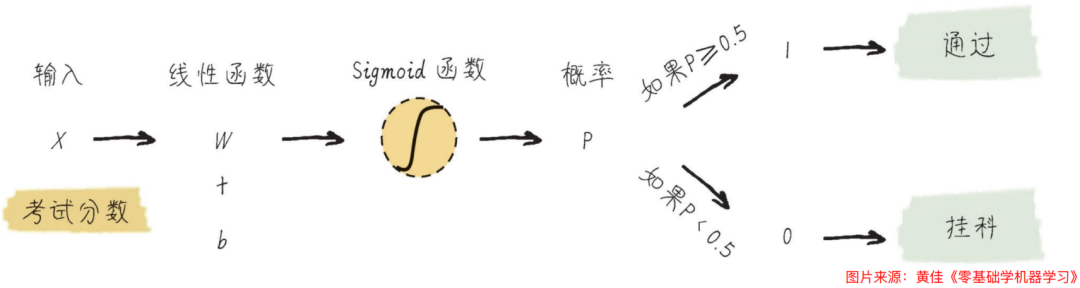
最简单最常见的分类算法就是 逻辑回归 了,虽然它带有回归二字,但却是主要应用在分类问题场景中,不过它也的确是从线性回归衍生而来的。它通过将线性模型的输出通过Sigmoid函数映射到(0,1)区间,得到事件发生的概率。逻辑回归的输出结果表示了某个事件发生的概率,而非具体的数值。
例如,有一个判断考试分数 是 通过 还是 挂科 的二分类问题,它的重点就在于 线性回归函数 + Sigmoid函数 配合起来从而得到 一个输出概率(这个概率也叫做逻辑回归的假设函数),假设得到的概率是0.5,那么如果概率>=0.5那就认为是通过,如果<0.5那就认为是挂科。
对于逻辑回归的升级版分类算法,用于处理更加复杂的问题,深度学习神经网络就是这样一种大杀器。在神经网络中,每个神经元都可以看做一个逻辑回归处理节点。

除此之外,常见的分类算法还有:
- 决策树(Decision Tree)
- 随机森林(Random Forest )
- 支持向量机(Support Vector Machine, SVM)
- K近邻(K-Nearest Neighbors, KNN)
- 朴素贝叶斯(Naive Bayes)
常见的分类算法的评估指标如下所示,对于分类问题,往往需要参考多个评估指标:
-
准确率(Accuracy)
-
精确率(Precision)
-
召回率(Recall)
-
F1分数(F1-Score)
-
混淆矩阵(Confusion Matrix)
这里,Edison再次推荐像我一样的零基础小白可以学习B站博主“五分钟机器学习”的视频,它在基础篇通俗易懂地讲解了 线性回归、逻辑回归、K近邻、决策树、KMeans、SVM、随机森林等算法,在进阶篇中介绍了梯度下降算法,简洁易懂,适合快速扫盲。
好了,这里总结一下:
-
分类是一种非常强大且应用广泛的统计分析方法。
-
分类可以应用于各种领域,如自动驾驶、生物学、医学等。
-
一般我们不需要自己写分类算法,调用现成的算法库即可。
医疗疾病分类诊断案例
问题背景:
-
某医院记录一批病人乳腺细胞的特征
-
病人数据包括的特征:细胞的平均半径、面积、致密度、光滑度等
-
病人数据包括的标签:诊断结果(是确诊 or 健康)
NOTE:和我们之前的第4站做数据可视化时使用的是同一个数据集。

问题目标:
-
根据历史数据,确定新的问诊者的检查结果
NOTE:在医疗诊断中,确诊通常用英文表达为Positive,而健康则表达为Negative。比如在前几年新冠检测中,检测结果显示Positive就表示确认为阳性。
医疗诊断分类代码实战
Step1 读取数据 及 数据预处理
import pandas as pd # 导入Pandas数据处理工具 # 读取数据 data = pd.read_csv('medical-demo-data.csv') data.head() # 显示前5行数据
输出的数据展现成下面的样子:

Step2 特征工程
这里特征和标签都很明显了,标签就是诊断结果,特征就是除了ID和诊断结果之外的字段。
# 设置X和y y = data["诊断结果"] X = data.drop(["诊断结果", "ID"], axis=1) X.describe()
X的特征统计信息展示:

Step3 数据标准化 并 拆分训练集 和 测试集
这里我们使用sklearn提供的StandardScaler进行数据标准化,先计算训练集上数据的均指和标准差,然后利用得到的均指和标准差在测试集上进行标准化。
from sklearn.model_selection import train_test_split from sklearn.preprocessing import LabelEncoder # Encode the '诊断结果' column le = LabelEncoder() data['诊断结果'] = le.fit_transform(data['诊断结果']) # Define the features and the target X = data.drop(['ID', '诊断结果'], axis=1) y = data['诊断结果'] # Split the data into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) from sklearn.preprocessing import StandardScaler #导入数据标准化工具 scaler = StandardScaler() # 数据标准化 # 先计算X_train 上数据的均值和标准差 X_train = scaler.fit_transform(X_train) # 使用之前在 X_train 上计算得到的均值和标准差对 X_test 进行标准化。 X_test = scaler.transform(X_test) X_train[:5], y_train[:5] # Display the first few rows of the training data
为了直观地看到标准化后的数据结果,可以画个柱状图来看看:
import matplotlib.pyplot as plt # 设置字体为SimHei,以正常显示中文标签 plt.rcParams["font.family"]=['SimHei'] plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示负号 plt.rcParams['axes.unicode_minus']=False # Select a feature for comparison feature = '平均半径' # Extract the selected feature from the original data and the standardized data original_feature = X[feature] standardized_feature = pd.DataFrame(X_train, columns=X.columns)[feature] # Plot the histograms fig, axes = plt.subplots(1, 2, figsize=(12, 5)) original_feature.hist(ax=axes[0], color='c', edgecolor='black') axes[0].set_title('原始数据') axes[0].set_xlabel(feature) axes[0].set_ylabel('频数') standardized_feature.hist(ax=axes[1], color='c', edgecolor='black') axes[1].set_title('标准化数据') axes[1].set_xlabel(feature) axes[1].set_ylabel('频数') plt.tight_layout() plt.show()
展示的柱状图如下图所示:左图为原始数据,右图为标准化后的数据。可以看到,标准化后的数据分布,就在一个比较小的区间,机器学习算法就能够比较好读(相较于原始数据分布而言)。

Step4 使用逻辑回归拟合并评估分类结果
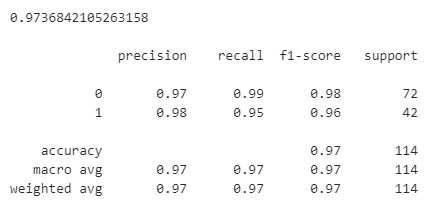
# 逻辑回归分类 # 导入并初始化模型 from sklearn.linear_model import LogisticRegression logreg = LogisticRegression(random_state=42) # 训练模型 logreg.fit(X_train, y_train) # 进行预测 y_pred = logreg.predict(X_test) # 评估预测结果 from sklearn.metrics import accuracy_score, classification_report accuracy_log = accuracy_score(y_test, y_pred) classification_rep_log = classification_report(y_test, y_pred) print(accuracy_log,"\n"), print(classification_rep_log)
得到的准确率和评估指标(精确度、召回率、F1分数等)如下所示。需要说明的是,F1分数是精确率和召回率两个指标的一个平衡,通常位于精确率和召回率之间,说明算法不能"偏科",要多个指标都还行,F1分数才够好。
Step5 更多模型做分类效果对比
除了逻辑回归之外,我们可以用多种模型来做一个效果的对比,比如下面我们引入决策树和随机森林来和逻辑回归一起做个对比,添加一些代码如下:
(1)决策树分类结果
# 决策树分类 # 导入并初始化模型 from sklearn.tree import DecisionTreeClassifier dt = DecisionTreeClassifier(random_state=42) # 训练模型 dt.fit(X_train, y_train) # 进行预测 y_pred_dt = dt.predict(X_test) # 评估预测结果 accuracy_dt = accuracy_score(y_test, y_pred_dt) classification_rep_dt = classification_report(y_test, y_pred_dt) print(accuracy_dt,"\n"), print(classification_rep_dt)
得到的准确率和评估指标(精确度、召回率、F1分数等)如下所示。可以看到,决策树的F1分数比逻辑回归要差一些。
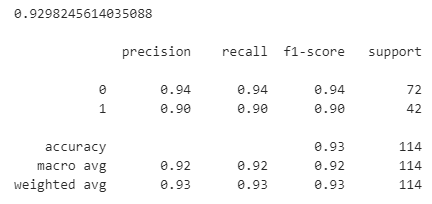
(2)随机森林分类效果
# 随机森林分类 # 导入并初始化模型 from sklearn.ensemble import RandomForestClassifier rf = RandomForestClassifier(random_state=42) # 训练模型 rf.fit(X_train, y_train) # 进行预测 y_pred_rf = rf.predict(X_test) # 评估预测结果 accuracy_rf = accuracy_score(y_test, y_pred_rf) classification_rep_rf = classification_report(y_test, y_pred_rf) print(accuracy_rf,"\n"), print(classification_rep_rf)
得到的准确率和评估指标(精确度、召回率、F1分数等)如下所示。回归森林的F1分数以及准确率是接近于逻辑回归的。

(3)三种模型的混淆矩阵对比
混淆矩阵是一个表格,用于展示分类模型的性能,特别是在二分类或多分类问题中。它通过比较模型的预测结果和实际标签来评估模型的准确性。
在代码实现中,我们可以借助Seaborn这个库来实现绘制混淆矩阵:
# 混淆矩阵评估模型结果 from sklearn.metrics import confusion_matrix import seaborn as sns # 计算混淆矩阵 cm_logreg = confusion_matrix(y_test, y_pred) cm_dt = confusion_matrix(y_test, y_pred_dt) cm_rf = confusion_matrix(y_test, y_pred_rf) # 显示混淆矩阵 fig, axes = plt.subplots(1, 3, figsize=(15, 5)) sns.heatmap(cm_logreg, annot=True, fmt='d', cmap='Blues', ax=axes[0]) axes[0].set_title('Logistic Regression\nConfusion Matrix') axes[0].set_xlabel('Predicted') axes[0].set_ylabel('True') sns.heatmap(cm_dt, annot=True, fmt='d', cmap='Blues', ax=axes[1]) axes[1].set_title('Decision Tree\nConfusion Matrix') axes[1].set_xlabel('Predicted') axes[1].set_ylabel('True') sns.heatmap(cm_rf, annot=True, fmt='d', cmap='Blues', ax=axes[2]) axes[2].set_title('Random Forest\nConfusion Matrix') axes[2].set_xlabel('Predicted') axes[2].set_ylabel('True') plt.tight_layout() plt.show()
最终的混淆矩阵如下图所示:
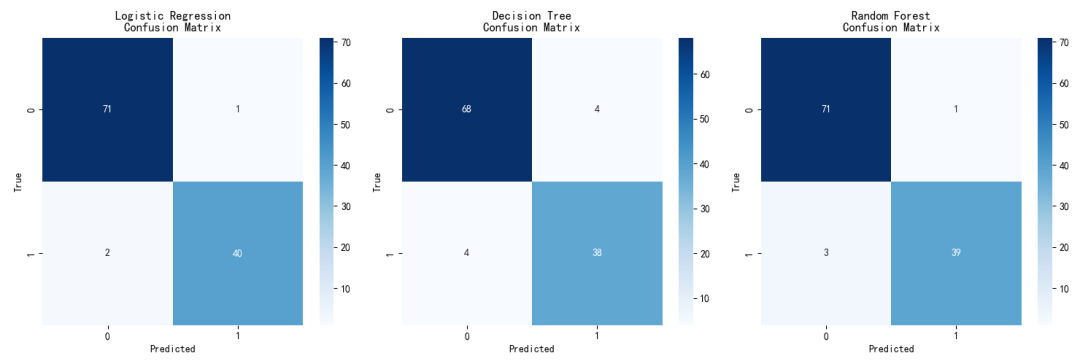
可以看出,两个结论:
- 逻辑回归成功实现了确认40个真正患病的患者,也就说健康(Negative)的患者检查为健康,它的分类效果比其余两个算法都要准确一些。
- 决策树在负样本区域的数量是最多的有4个,也就说把确诊(Positive)判断为健康(Negative)的有4个,因此可能造成误诊导致的后果越大。
NOTE: 对于医疗诊断业务来说,最重要的是把真正患病确诊的人找出来,因此负样本结果比成功判定健康的结果更加重要。
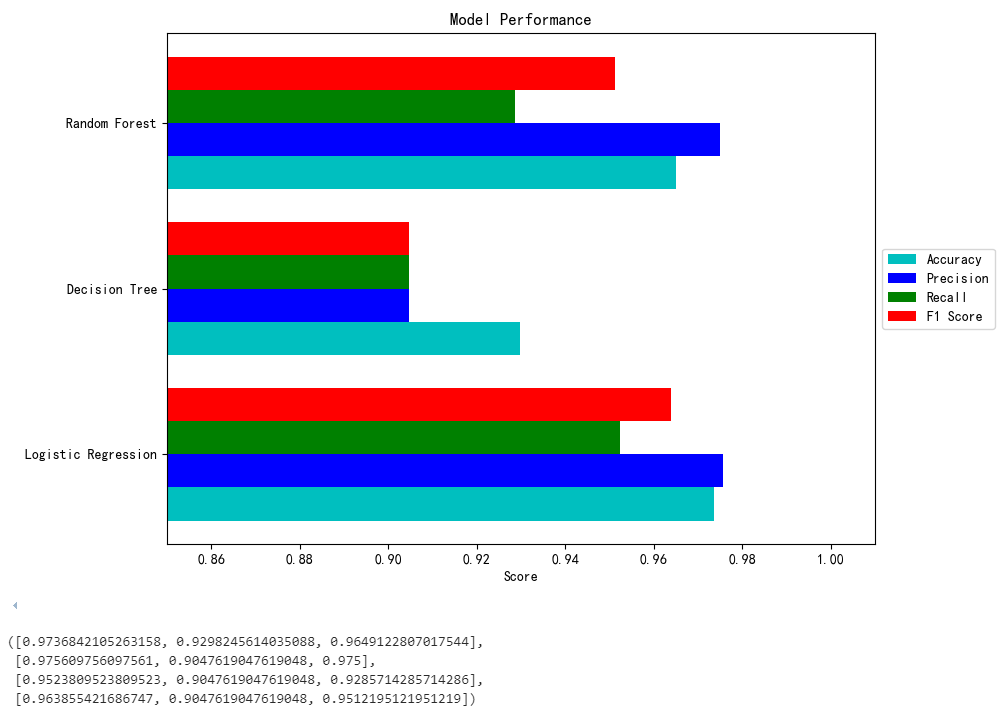
(4)三种模型的其他评估指标对比
除了混淆矩阵之外,我们还需要评估多种模型的其他重要指标,如精确度、准确度、召回率、F1分数等。
# 查看其他评估指标 from sklearn.metrics import precision_score, recall_score, f1_score # 计算其它评估指标 models = ['Logistic Regression', 'Decision Tree', 'Random Forest'] y_preds = [y_pred, y_pred_dt, y_pred_rf] accuracies = [accuracy_score(y_test, y_pred) for y_pred in y_preds] precisions = [precision_score(y_test, y_pred) for y_pred in y_preds] recalls = [recall_score(y_test, y_pred) for y_pred in y_preds] f1_scores = [f1_score(y_test, y_pred) for y_pred in y_preds] # 把这些评估指标整体展示 fig, ax = plt.subplots(figsize=(10, 6)) x = range(len(models)) ax.barh(x, accuracies, color='c', height=0.2, label='Accuracy') ax.barh([p + 0.2 for p in x], precisions, color='b', height=0.2, label='Precision') ax.barh([p + 0.4 for p in x], recalls, color='g', height=0.2, label='Recall') ax.barh([p + 0.6 for p in x], f1_scores, color='r', height=0.2, label='F1 Score') ax.set_xlabel('Score') ax.set_title('Model Performance') ax.set_yticks([p + 0.3 for p in x]) ax.set_yticklabels(models) ax.set_xlim(0.85, 1.01) plt.legend(loc='center left', bbox_to_anchor=(1, 0.5)) plt.tight_layout() plt.show() accuracies, precisions, recalls, f1_scores
最终的对比结果如下图所示:
小结
本文介绍了机器学习中的分类场景问题,常用的分类算法 以及 分类和回归的简单对比,最后通过一个医疗数据诊断分类的案例做了一次实战,相信对你理解分类应用应该有所帮助。
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)



 浙公网安备 33010602011771号
浙公网安备 33010602011771号