像素缓冲区对象PBO 记录
像素缓冲区对象PBO 记录
和所有的缓冲区对象一样,它们都存储在GPU内存中,我们可以访问和填充PBO,方法和其他的缓冲区一样。
- 当一个PBO被绑定到GL_PIXEL_PACK_BUFFER,任何读取像素的OpenGL操作都会从PBO中获取它们的数据,如glReadPixels,glGetTexImage和glGetCompressedTexImage。通常的操作会从FBO或纹理中抽取数据,并将它们读取客户端内存中。当PBO绑定到GL_PIXEL_PACK_BUFFER时,像素数据在GPU内存中的PBO,而不会下载到客户端的内存。
- 当一个PBO绑定点是GL_PIXEL_UNPACK_BUFFER,任何绘制像素的OpenGL操作都会向一个绑定的PBO对象写入数据。如glTexImage*D,glTexSubImage*D等等。通常的这些操作将数据和纹理从CPU内存中上传到帧缓冲区中,当PBO绑定到GL_PIXEL_UNPACK_BUFFER时,上传数据和纹理过程经过PBO。如图(from:http://www.songho.ca/opengl/gl_pbo.html)
PBO的主要优势:
- 可以通过DMA (Direct Memory Access) 快速地在显卡上传递像素数据,而不需要耗费CPU的时钟周期。
- 另一个优势是它还具备异步DMA传输。
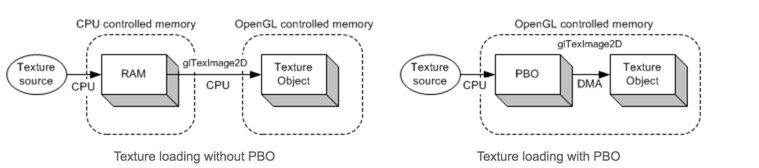
左侧图是从图像文件或视频中加载纹理。首先,资源被加载到系统内存(Client)中,然后使用glTexImage2D()函数从系统内存上传到OpenGL纹理对象中(Client->Server)。这两次数据传输(加载和复制)完全由CPU执行。
右侧图中图像可以直接加载到PBO中,而PBO是由OpenGL控制的。虽然CPU有参与加载纹理到PBO,但不涉及将像素数据从PBO传输到纹理对象的工作,而是由GPU(OpenGL驱动)来负责PBO到纹理对象的数据传输的,这也就意味着OpenGL执行DMA传输操作不会占用CPU的时钟周期。此外,OpenGL还可以安排稍后执行的异步DMA传输。所以glTexImage2D立即返回,CPU也无需等待像素数据的传输了,可以继续其他工作。
使用
当绘制内容在屏幕上显示时,可能需要在像素彻底消失之前再次取回,原因可能是检查实际的渲染情况,也可能是应用到后续帧的效果需要使用前面帧的像素进行合成;总之这时需要glReadPixels函数发挥作用。
glReadPixels本身是同步操作,需要操作完成后才返回,这期间对程序性能会有很大冲击,是影响性能的关键点。
//从缓存区中读取像素数据到PBO,避免了复制到客户端的内存上可能带来的性能问题 glBindBuffer(GL_PIXEL_PACK_BUFFER, pixBufferObj[0]); glReadPixels(0, 0, width, height, GL_RGB, GL_UNSIGNED_BYTE, NULL); glBindBuffer(GL_PIXEL_PACK_BUFFER, 0); //接下来将PBO绑定为解包缓冲区,然后直接将像素读取到PBO,然后直接将像素加载到纹理中 glBindBuffer(GL_PIXEL_UNPACK_BUFFER, pixBufferObj[0]); glActiveTexture(GLTexture0 + X); glTexImage2D(GL_Texture_2D, 0, GL_RGB8, width, height, 0, GL_RGB, GL_UNSIGNED_BYTE, NULL); glBindBuffer(GL_PIXEL_UNPACK_BUFFER, 0);
这样能将像素重定向到GPU中的PBO中,避免复制到客户端内存可能带来的性能问题。
参考
- 《OpenGL 超级宝典 (第5版))》
- http://www.songho.ca/opengl/gl_pbo.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号