
摘要:
 题目:请实现一个函数,把字符串中的每个空格替换成"%20"。例如输入“We are happy.”,则输出“We%20are%20happy.”。在网络编程中,如果URL参数中含有特殊字符,如空格、'#'等,可能导致服务器端无法获得正确的参数值。我们需要将这些特殊符号转换成服务器可以识别的字符。转换的规则是在'%'后面跟上ASCII码的两位十六进制的表示。 阅读全文
题目:请实现一个函数,把字符串中的每个空格替换成"%20"。例如输入“We are happy.”,则输出“We%20are%20happy.”。在网络编程中,如果URL参数中含有特殊字符,如空格、'#'等,可能导致服务器端无法获得正确的参数值。我们需要将这些特殊符号转换成服务器可以识别的字符。转换的规则是在'%'后面跟上ASCII码的两位十六进制的表示。 阅读全文
题目:请实现一个函数,把字符串中的每个空格替换成"%20"。例如输入“We are happy.”,则输出“We%20are%20happy.”。在网络编程中,如果URL参数中含有特殊字符,如空格、'#'等,可能导致服务器端无法获得正确的参数值。我们需要将这些特殊符号转换成服务器可以识别的字符。转换的规则是在'%'后面跟上ASCII码的两位十六进制的表示。 阅读全文
 排序(Sorting)是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为按关键字“有序”的记录序列。如何进行排序,特别是高效率地进行排序时计算机工作者学习和研究的重要课题之一。排序有内部排序和外部排序之分,若整个排序过程不需要访问外存便能完成,则称此类排序为内部排序,反之则为外部排序。本篇主要介绍插入排序、交换排序、选择排序和归并排序这几种内部排序方法。
排序(Sorting)是计算机内经常进行的一种操作,其目的是将一组“无序”的记录序列调整为按关键字“有序”的记录序列。如何进行排序,特别是高效率地进行排序时计算机工作者学习和研究的重要课题之一。排序有内部排序和外部排序之分,若整个排序过程不需要访问外存便能完成,则称此类排序为内部排序,反之则为外部排序。本篇主要介绍插入排序、交换排序、选择排序和归并排序这几种内部排序方法。  哈希(散列)技术既是一种存储方法,也是一种查找方法。然而它与线性表、树、图等结构不同的是,前面几种结构,数据元素之间都存在某种逻辑关系,可以用连线图示表示出来,而哈希技术的记录之间不存在什么逻辑关系,它只与关键字有关联。因此,哈希主要是面向查找的存储结构。哈希技术最适合的求解问题是查找与给定值相等的记录。
哈希(散列)技术既是一种存储方法,也是一种查找方法。然而它与线性表、树、图等结构不同的是,前面几种结构,数据元素之间都存在某种逻辑关系,可以用连线图示表示出来,而哈希技术的记录之间不存在什么逻辑关系,它只与关键字有关联。因此,哈希主要是面向查找的存储结构。哈希技术最适合的求解问题是查找与给定值相等的记录。  只要你打开电脑,就会涉及到查找技术。如炒股软件中查股票信息、硬盘文件中找照片、在光盘中搜DVD,甚至玩游戏时在内存中查找攻击力、魅力值等数据修改用来作弊等,都要涉及到查找。当然,在互联网上查找信息就更加是家常便饭。查找是计算机应用中最常用的操作之一,也是许多程序中最耗时的一部分,查找方法的优劣对于系统的运行效率影响极大。因此,本篇讨论一些查找方法。
只要你打开电脑,就会涉及到查找技术。如炒股软件中查股票信息、硬盘文件中找照片、在光盘中搜DVD,甚至玩游戏时在内存中查找攻击力、魅力值等数据修改用来作弊等,都要涉及到查找。当然,在互联网上查找信息就更加是家常便饭。查找是计算机应用中最常用的操作之一,也是许多程序中最耗时的一部分,查找方法的优劣对于系统的运行效率影响极大。因此,本篇讨论一些查找方法。 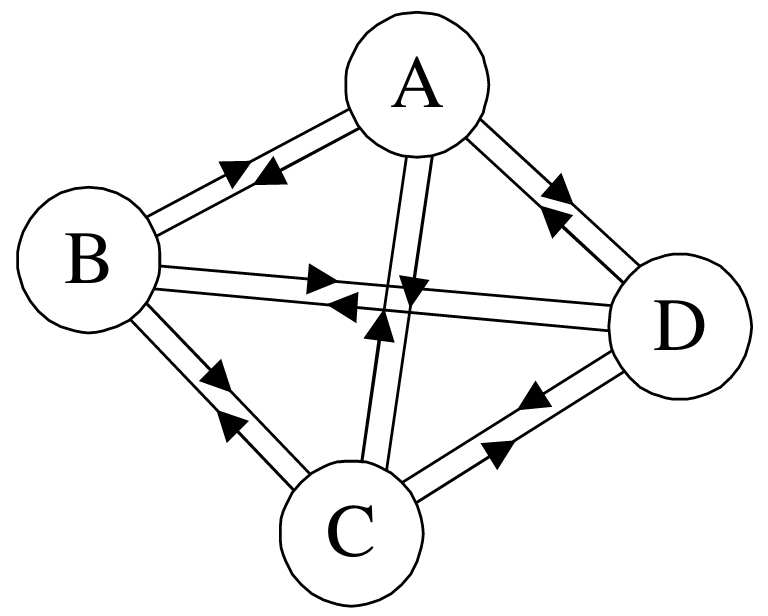 图的最重要的应用之一就是在交通运输和通信网络中寻找最短路径。例如在交通网络中经常会遇到这样的问题:两地之间是否有公路可通;在有多条公路可通的情况下,哪一条路径是最短的等等。这就是带权图中求最短路径的问题,此时路径的长度不再是路径上边的数目总和,而是路径上的边所带权值的和。
图的最重要的应用之一就是在交通运输和通信网络中寻找最短路径。例如在交通网络中经常会遇到这样的问题:两地之间是否有公路可通;在有多条公路可通的情况下,哪一条路径是最短的等等。这就是带权图中求最短路径的问题,此时路径的长度不再是路径上边的数目总和,而是路径上的边所带权值的和。  一个由C/C++编译的程序占用的内存分为以下几个部分:1、栈区(stack):又编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构的栈。2、堆区(heap):一般是由程序员分配释放,若程序员不释放的话,程序结束时可能由OS回收,值得注意的是他与数据结构的堆是两回事,分配方式倒是类似于数据结构的链表。
一个由C/C++编译的程序占用的内存分为以下几个部分:1、栈区(stack):又编译器自动分配释放,存放函数的参数值,局部变量的值等,其操作方式类似于数据结构的栈。2、堆区(heap):一般是由程序员分配释放,若程序员不释放的话,程序结束时可能由OS回收,值得注意的是他与数据结构的堆是两回事,分配方式倒是类似于数据结构的链表。  GCC(GNU Compiler Collection)是一套功能强大、性能优越的编程语言编译器,它是GNU计划的代表作品之一。GCC是Linux平台下最常用的编译器,GCC原名为GNU C Compiler,即GNU C语言编译器,随着GCC支持的语言越来越多,它的名称也逐渐变成了GNU Compiler Collection。下面对GCC的基本使用方法进行介绍。这里我们主要使用Windows系统进行C程序的开发调试,所以我们选择GCC for Windows版本的编译器。
GCC(GNU Compiler Collection)是一套功能强大、性能优越的编程语言编译器,它是GNU计划的代表作品之一。GCC是Linux平台下最常用的编译器,GCC原名为GNU C Compiler,即GNU C语言编译器,随着GCC支持的语言越来越多,它的名称也逐渐变成了GNU Compiler Collection。下面对GCC的基本使用方法进行介绍。这里我们主要使用Windows系统进行C程序的开发调试,所以我们选择GCC for Windows版本的编译器。 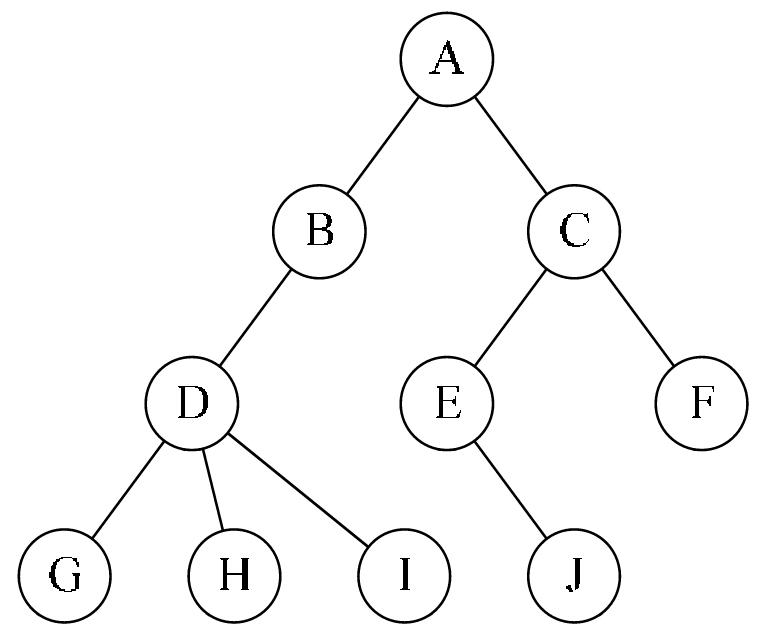 上面两篇我们了解了树的基本概念以及二叉树的遍历算法,还对二叉查找树进行了模拟实现。数学表达式求值是程序设计语言编译中的一个基本问题,表达式求值是栈应用的一个典型案例,表达式分为前缀、中缀和后缀三种形式。这里,我们通过一个四则运算的应用场景,借助二叉树来帮助求解表达式的值。首先,将表达式转换为二叉树,然后通过先序遍历二叉树的方式求出表达式的值。
上面两篇我们了解了树的基本概念以及二叉树的遍历算法,还对二叉查找树进行了模拟实现。数学表达式求值是程序设计语言编译中的一个基本问题,表达式求值是栈应用的一个典型案例,表达式分为前缀、中缀和后缀三种形式。这里,我们通过一个四则运算的应用场景,借助二叉树来帮助求解表达式的值。首先,将表达式转换为二叉树,然后通过先序遍历二叉树的方式求出表达式的值。