
MySQL核心知识学习之路(1)
作为一个后端工程师,想必没有人没用过数据库,跟我一起复习一下MySQL吧,本文是我学习《MySQL实战45讲》的总结笔记的第一篇,总结了MySQL的基础架构、一个查询语句的执行过程 以及 一条更新语句的执行过程。
1 MySQL的基础架构
为了窥其全貌,我们首先需要了解一下MySQL的基础架构,如下图所示:
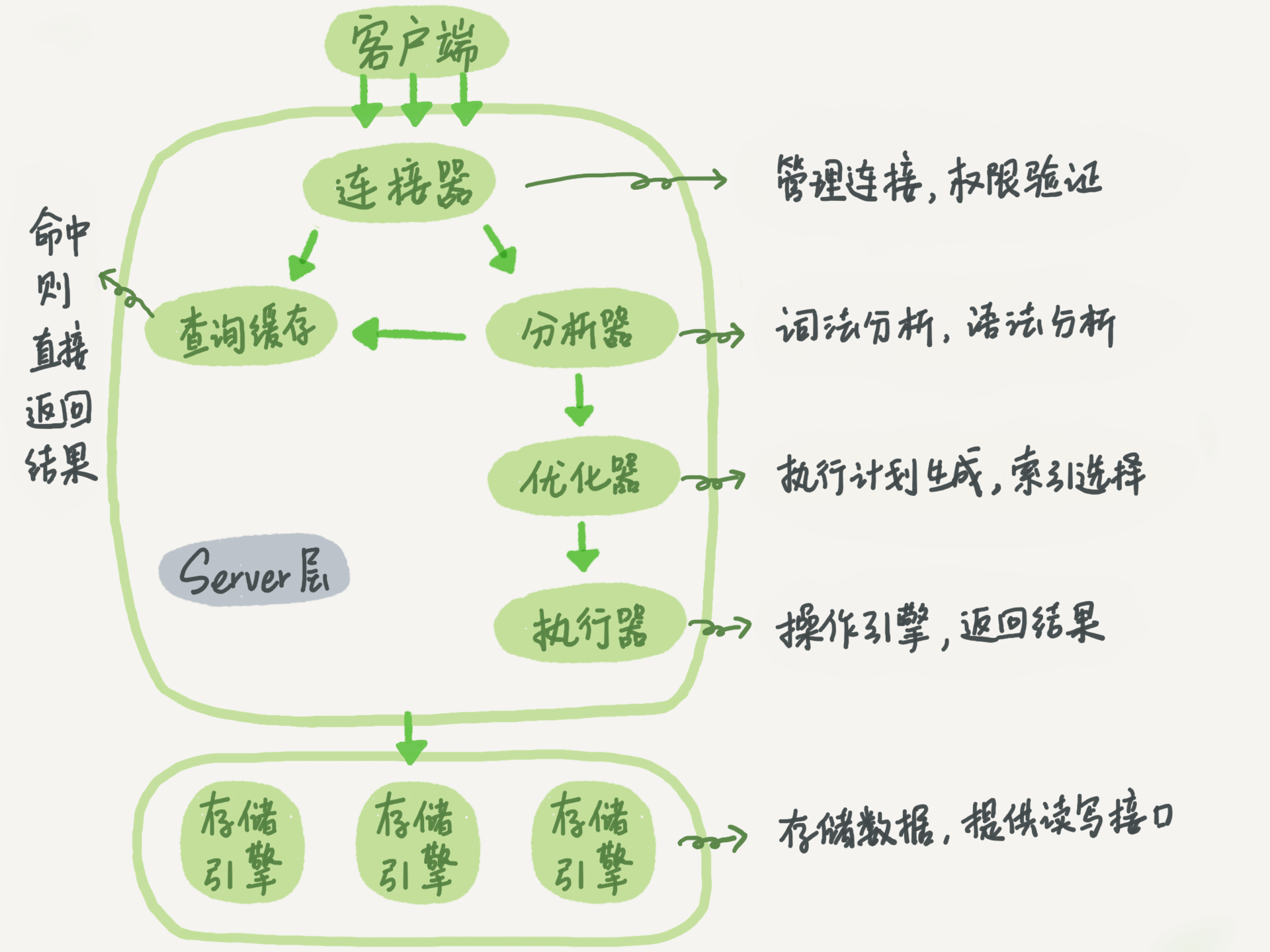
图片来自林晓斌《MySQL实战45讲》
可以从图中看到,MySQL分为了Server层和存储引擎层,Server层包括了连接器(用于管理连接和权限验证)、查询缓存(用于缓存查询结果)、分析器(词法分析和语法分析)、优化器(执行计划生成及索引选择)以及执行器(操作存储引擎接口,返回最终结果),而存储引擎层则负责数据的存储和提取。存储引擎层是插件式架构,目前MySQL默认存储引擎是InnoDB。当然,你也可以切换为MyISAM或Memory。
2 一个查询语句的执行过程
现在我们来看一个查询语句的执行过程,会涉及到刚刚提到的基础架构中的所有组件。查询语句如下:
select * from T where ID=10;
(1)连接器
首先,我们需要通过以下语句连接到这个数据库上,这时候我们使用的就是连接器这个组件来创建和MySQL的连接。
mysql -h$ip -P$port -u$user -p
建立连接的过程通常是比较复杂的,建议尽量使用长连接!
长连接累计过多也可能会导致内存占用问题,解决方案有以下两种:
-
定期断开长连接
-
通过执行mysql_reset_connection来重新初始化连接资源(MySQL 5.7+)
(2)查询缓存
查询缓存顾名思义就是对查询结果的缓存,它会直接存放在内存中。但是,查询缓存的失效非常频繁,弊大于利。因此,它只适用于静态配置表之类的场景,而MySQL新版本(8.0)直接将其废弃了。
建议对于查询缓存按需使用,设置参数:query_cache_type=DEMAND。对于确定使用缓存的时候,可以直接通过以下语句查询:
select SQL_CACHE * from T where ID=10;
(3)分析器
对于不走缓存的命令,就要开始执行词法分析和语法分析了。
词法分析,就是从这一行语句中识别出:select是查询关键词、字符串T是表名T,字符串ID是列ID,以此类推。
语法分析,就是根据语法规则判断语句是否满足MySQL语法,如果语句不对,则会抛出“You have an error in your SQL syntax”的错误提示。
(4)优化器
正式执行之前,优化器会对你的语句进行一些优化,比如:
-
在表中含有多个索引的时候,决定使用哪个索引。
-
在一个语句中有多表关联(join)的时候,决定各个表的连接顺序。
(5)执行器
前期准备工作就绪之后,正式开始执行。
首先,判断用户是否对此表具有执行查询的权限。
其次,根据表的引擎定义,使用这个引擎提供的接口。
对于这个语句而言,具体步骤如下:
-
调用InnoDB引擎接口取这个表的第一行,判断ID值是不是10,是则将这行存在结果集中。
-
调用引擎接口取“下一行”,重复相同的逻辑判断。
-
将满足条件的记录集作为结果集返回给客户端。
到此,这个语句就执行完成了。
最终,我们可以通过下图所示的流程来回顾一下这个查询语句的执行过程全貌。
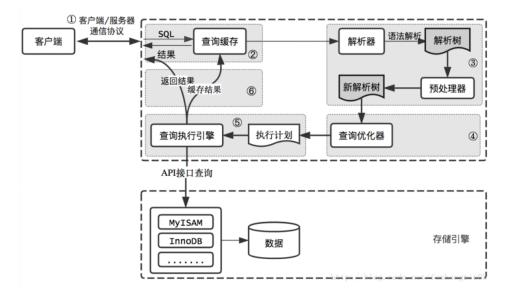
综述,对于一个查询语句的执行过程有了初步了解,实际就是对MySQL逻辑架构有了一个初步印象。
3 一个更新语句的执行过程
现在我们来看看如下所示的一条更新语句的执行过程:
update T set c=c+1 where ID=2;
事实上,更新语句和查询语句所经历的流程一模一样,不同的地方在于更新语句在执行器阶段还会涉及到两个日志模块:redo log(重做日志)和 binlog(归档日志)。
redo log
redo log即重做日志,它是InnoDB引擎特有的日志。
当有一条记录需要更新时,InnoDB引擎会将其记录(记录内容:在某个数据页上做了什么修改)写到redo log中,并更新内存。然后,InnoDB引擎会在适当的时候将这个操作记录更新到磁盘里面。
redolog是循环写入的方式,空间固定会用完,因此当空间满了的话,需要提前擦除一些数据腾空间。
有了redolog,InnoDB引擎才可以说具有了crash-safe的能力。
binlog
binlog即归档日志,它是MySQL Server层实现的,所有引擎(包括InnoDB)均可使用。
binlog属于逻辑日志,记录的内容类似于“给 ID=2 这一行的 c 字段加 1”这种。与redolog不同,binlog是通过“追加写”的形式记录的。
binlog在MySQL主从备份的场景中使用较多,如果我们需要从数据库同步主数据库的内容,我们就可以通过binlog来进行同步。而阿里的开源项目Canal则是一个针对binlog消费的经典案例:

那么,问题来了:为什么有两套日志?
因为早期MySQL的默认引擎是MyISAM,那时还没有InnoDB,而binlog只能用于归档,因此不具备crash-safe的能力。因此,后来InnoDB自己通过redo log实现了crash-safe能力。
两阶段提交
对开头提到的这个更新语句的执行过程如下图所示:
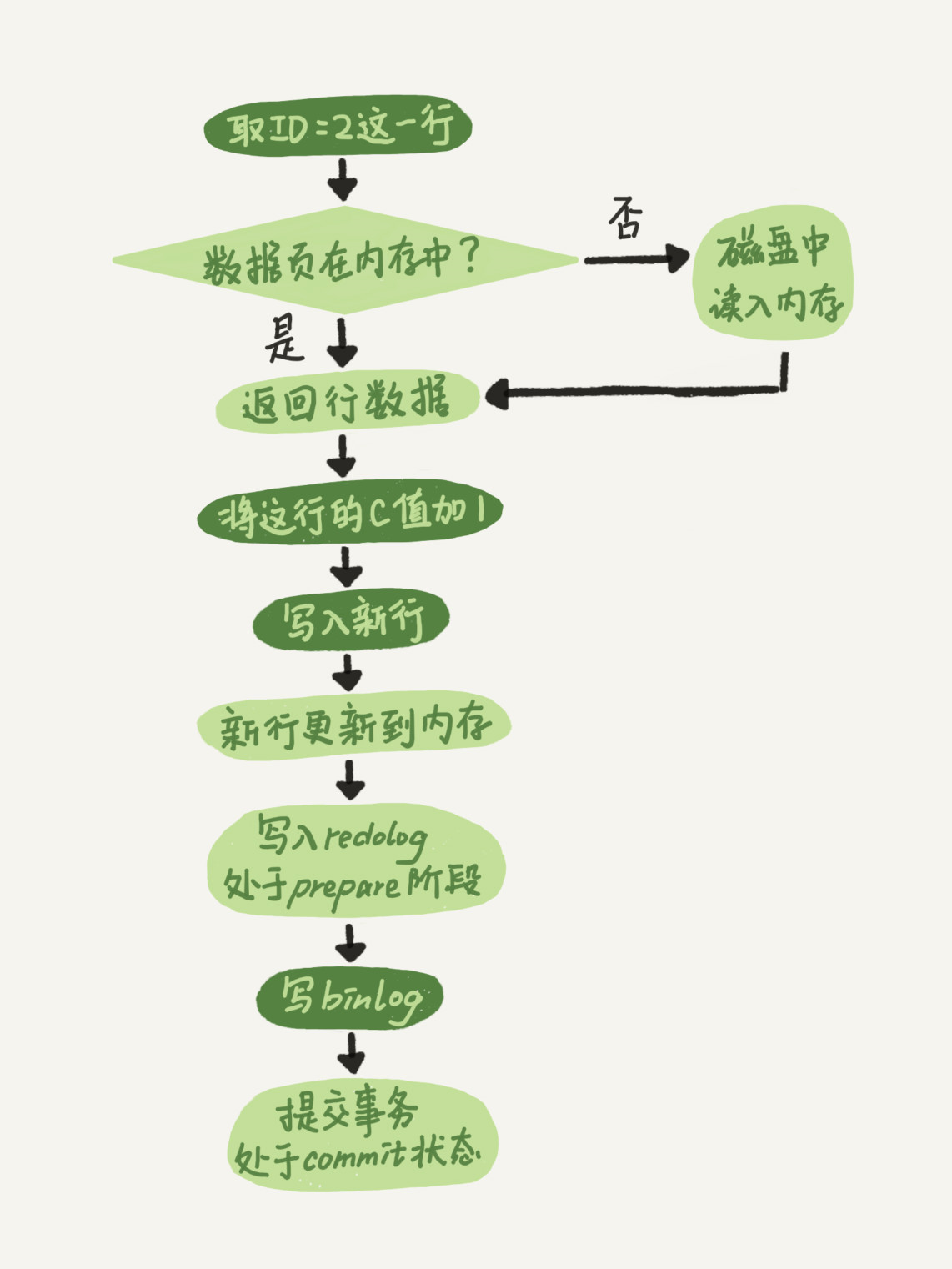
图片来自林晓斌《MySQL实战45讲》
我们可以看到,引擎会将新数据先更新到内存中,同时将其操作记录到redo log中,这时redo log处于prepare状态。
然后,告知执行器执行完成,时刻准备着提交事务。
执行器收到通知,开始生成这个更新操作的binlog,并将其写入磁盘。
最后,执行器调用引擎提供的提交事务的接口,这时引擎会将写入的redo log改成commit状态,代表更新操作正式结束。
这就是MySQL的两阶段提交,prepare和commit两个状态。
那么,问题来了:为什么要两阶段提交?
因为redo log 和 binlog 都可以用于表示事务的提交状态,而两阶段提交就是让这两个状态保持逻辑上的一致。两阶段提交也是跨系统维持数据逻辑一致性的一个常见方案。
4 小结
本文总结了MySQL的基础架构、一条查询语句和一条更新语句的执行过程,通过高屋建瓴的视角俯视了MySQL最常见的应用场景,可以帮助我们有一个初步的了解。
参考资料
林晓斌(丁奇),《MySQL实战45讲》
👇扫码订阅《MySQL实战45讲》




 浙公网安备 33010602011771号
浙公网安备 33010602011771号