
重新温习软件设计之路(2)
 如果说学习数据结构和常用算法可以帮助我们写出较为高效的代码,那么学习软件设计相关知识则可以帮助我们写出较为高质量的代码,本文是我学习课程《软件设计之美》的学习总结的第二部分,分享如何了解一个软件的设计:先看模型,再看接口,最后看实现。经历了这三步,我们就基本可以了解一个软件的设计了。
如果说学习数据结构和常用算法可以帮助我们写出较为高效的代码,那么学习软件设计相关知识则可以帮助我们写出较为高质量的代码,本文是我学习课程《软件设计之美》的学习总结的第二部分,分享如何了解一个软件的设计:先看模型,再看接口,最后看实现。经历了这三步,我们就基本可以了解一个软件的设计了。
本文是我学习课程《软件设计之美》的学习总结第二部分,分享如何了解一个软件的设计。
上一篇:重新温习软件设计之路(1)
1 了解一个软件的三步
我们在职业生涯中肯定有去接手和维护一个已有项目的时候,项目到来时,我们大部分时候可能都会首先就去看源代码。但是,过不了多久就开始打退堂鼓了。
看源代码是了解软件设计的必经之路,但却不是第一步。
郑晔老师说道,了解一个软件的设计,可以从三个部分着手,它们是:模型、接口和实现。
-
所谓模型,它也被称之为抽象,它是软件的核心内容,理解模型就可以帮助我们从高维度建立对软件的整体认知。比如,DI依赖注入是一种模型解决了组件创建和组装的问题,MapReduce也是一种模型解决了分布式计算中节点分发和调度的问题。
-
所谓接口,它是用户与软件交互的入口,约定了软件通过怎样的方式对外暴露自己的能力。
-
所谓实现,它指软件提供的模型和接口在内部是如何实现的。实现的内容有很多,实际中也并不存在一个通用的实现解决方案。
可以看到,“实现”固然重要,但是它需要建立在稳定的模型和接口的基础之上。模型才是一个软件最核心的部分,如果模型变了那么软件就不再是原来的样子,甚至偏离了方向。接口反映的是模型,因此模型和接口都应该是较为稳定的,而实现则会随着软件的演化和发展而不断地调整。
因此,郑晔老师建议,了解一个软件的设计,应该遵循这样的一个三步走的顺序:先模型,在接口,最后是实现。
了解一个大软件的设计,我们需要一层一层地展开,每个层次可能都会有一些小模型,对这些小模型也按照模型-接口-实现的顺序去理解,就有可能会在脑中形成一棵设计树。
2 分析软件的模型
任何模型都是为了解决问题而创建,所以理解一个模型的关键在于,要了解这个模型设计的来龙去脉,即要知道它要解决什么问题,又为何要解决相应问题。
以DI容器(依赖注入)中间件为例,它要解决的是什么问题(What)?又为何要解决这个问题(Why)?
到底解决啥问题?
其实,不论是.NET应用还是Java应用,它们中的DI容器解决的都是组件/依赖项的创建和组装的问题。
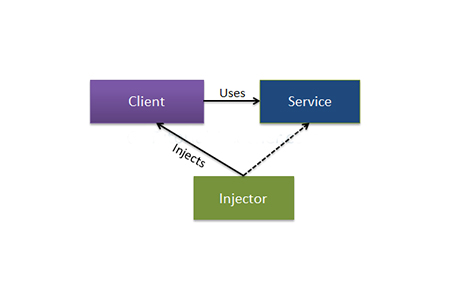
为啥要解决这个问题?
还是以上篇中的一个常见的例子来看看,这是一个服务层调用仓储进行数据持久化的场景:
public class ProductService { private readonly DBProductRepository repository; public ProductService(string connStr) { repository = new DBProductRepository(connStr); } public Product GetProduct(long id) { return repository.GetProduct(id); } }
看起来并没啥毛病,但是一旦想要测试,我们就会发现,十分麻烦。要让ProductService跑起来,我得先让DBProductRepository跑起来,要让DBProductRepository跑起来,我还得先给它准备数据库连接字符串。
一时间,我们开始怀疑人生,这是我该做的事儿吗?
其实,在我们开始创建对象的时候,就出现了问题。因为引入了一个具体的实现,需要将其周边的相关配套的所有东西都引入进来,但是这些玩意好像与这个Service的业务逻辑没有多大关系。
郑晔老师打了一个生动的比方(惊呼郑晔老师的打比方能力,这是需要深刻理解本质才能做出的比方),你原本打算买一套家具,但是现在需要你必须了解树是怎么种的、怎么伐的 又是 怎么加工生产的一些列工作,然而你想要的就仅仅是一套能直接使用的家具而已。
对上一段代码,我们做了如下如下优化之后:
public class ProductService { private readonly IProductRepository _repository; public ProductService(IProductRepository repository) { _repository= repository; } public Product GetProduct(long id) { return _repository.GetProduct(id); } }
这时候,我们就可以很方便的测试ProductService,只需要Mock一个IProductRepository的GetProduct方法的实现即可完成这个Service的测试。这就是对象创建的分离。
但是,还需要有一个地方去组装,也就是在生成ProductService实例的时候,将DBProductRepository的实例传入。
ProductService service = new ProductService(new DBProductRepository(connStr));
这是一段无聊但且重要的代码,对我们来说就是一些重复的劳动。
人之初,性本懒,有谁愿意生来就996的?偷懒划水,是人的本性。记得微信的张小龙曾说,研究产品,就是研究人性,人性的本质就是贪、嗔、痴。软件也一样,软件做的再好,没有人用也不能算是好软件。好的软件,也一定是需要研究人性的。帮助程序员这个群体偷一点懒的软件,就是这些经过高度封装的中间件/组件 又或者是 更高级的编程语言。
从汇编语言到高级语言,从过程编程到面向对象编程,从线程模型到协程模型… 每次的发展都是一个编程模型不断进化发展的过程,也是编程思维的升级。
因此,DI容器出世,它的目的就是帮助我们节省这些重复的劳动。换句话说,它解决了每次初始化时依赖对象的传入问题,让程序员提高生产率。
比如ASP.NET Core中的DI容器,它封装了对象的创建和组装的工作,我们已经对它的工作没有感知了。
public void ConfigureServices(IServiceCollection services) { services.AddScoped<IProductRepository, DBProductRepository>(); ...... }
又如开源DI容器组件Autofac,它还提供了更丰富的如属性注入和批量注入等方式供我们使用,又大大提高了我们的效率,在偷懒的道路上我们又进了一步。
// 批量匹配注入,使用AutoFac提供的容器接管当前项目默认容器 var builder = new ContainerBuilder(); // 注入entity层的repository类builder.RegisterType(typeof(TUserRepository)).As(typeof(IUserRepository)).InstancePerDependency(); // 批量注入Repository的类 builder.RegisterAssemblyTypes(typeof(TUserRepository).Assembly) .Where(t => t.Name.EndsWith("Repository")) .AsImplementedInterfaces(); builder.Populate(services); var container = builder.Build(); // ConfigureServices方法由void改为返回IServiceProvider return new AutofacServiceProvider(container);
此时,我们知道了DI容器要解决的问题,为何要解决这个问题的来龙去脉。开心的是,现在的DI组件已经能够让我们很方便地去实现组件的创建和组装了。对于程序员来说,已经习惯了不需要关注组件的创建和组装的编程模型了,因此写业务代码的时候也就几乎已经感觉不到DI做的工作了。
总结,从上面的分析可以看到,了解模型设计的来龙去脉十分重要,是了解一个软件设计的第一步。对于常见的开源项目来说,阅读和查看github上的官方文档,一般优秀的开源项目的官方文档都会对其来龙去脉,比如为何会有这个项目,要解决什么问题等会有较为清晰的描述。
3 分析软件的接口
分析一个软件的第二步,接口。但是,现在随便一个软件的接口少则几十个,多个上百个,如何高效地去分析接口呢?
郑晔老师提供了一个思路:找主线,看风格。
找主线就是找到一条功能主线,建立起对项目结构的结构性认知。有了主线,就有了着力点,找到了突破口。
看风格就是从项目的接口风格中看出设计者的品味,因为我们要维护项目的一致性,所以必须要有一个统一的风格。
郑晔老师在课程中以Ruby on Rails这个曾经很火爆的开发框架为例,我们可以借着它的起步文档开始,了解它的接口主线:
(1)Web应用对外暴露的接口即REST API
(2)程序员写程序时用到的接口即API
(3)程序员在开发过程中用到的接口即命令行
接下来,就可以针对各条主线去观察它们各自的接口风格了。
比如,从Rails的对外暴露的REST接口设计中,可以看到,它对REST的使用方式做了一个约定,只要遵循Rails的习惯写法,写出来的结果就基本上符合REST规范的。换句话说,Rails将REST这个模型用一种更实用的方式落地了。
Rails.application.routes.draw do ... resources :articles ... end
看到这里,我们不禁想起,这不就是“约定大于配置”的设计吗?ASP.NET MVC里面的Controller不也是这样设计的吗?嗯,ASP.NET MVC框架其实也是将MVC这个模型用一种更实用的方式落地了,让大家可以尽可能的统一风格。
毫无疑问,这就是一种将最佳实践固化在接口中的方式。
又如,从Rails的程序员编写的API接口设计中,可以发现它十分关注API的表达性,可以很方便地表达一对多的关系:
class Article < ApplicationRecord has_many :comments ... end
而如果我们用.NET或Java来写,可能都是这个样子的风格:
public class Article { public List<Comment> Comments { get; set; } ... }
而这样的风格,并没有错,只是无法很直白的表现出一对多的关系,而Rails的“has_many”表达地更加直白。当然,我们也可以通过其他的方式去支持这种直白的关系表达,但并不能像Rails这样将其直接提供出来。
记得我在2018年学习Spring Cloud的时候,接触了Spring Data JPA这个框架,现在看来,它就参考了Rails的接口设计,这时如果再需要表达一对多关系的时候,就可以在Java中写成这个样子了:
class Article { @OneToMany private List<Comment> comments; ... }
特别是它也参考Rails对数据访问的代码做了高度封装,使得我们只需要定义好接口就可以自动帮我们生成对应的SQL语句,如下所示。现在看来,这也是一种“约定大于配置”的接口设计,你只要接口设计的名字满足规范,我就能帮你生成对应的SQL语句,让你无须编写普通的SQL查询代码,只需要在Service里面调用这个Repository的接口即可。
interface ArticleRepository extends JpaRepository<Article, Long> { Article findByTitle(String title); Article findByTitleAndAuthor(String title, String author); }
作为.NET程序员,自然想知道在.NET生态中有没有一个这样的组件呢?杨中科老师就自己封装了一个类似Spring Data JPA的组件ZackData,支持如下图所示的写法,即只要按照命名约定声明接口,即可自动进行数据库操作,不用写实现方法。

上面的接口在被调用时会生成如下图所示的SQL,可以看到它是基于EF Core来做的封装:

综述,作为分析软件设计的第二步,我们可以通过“找主线,看风格”的方法来看接口,即找到一条或多条功能主线,对项目建立起结构性的了解,然后沿着主线将相关接口都梳理出来。对于常见的开源项目来说,阅读其官方文档中的Quick Start即Wiki,可以帮助我们梳理出主线,便于我们从主线深入查看其风格。
4 分析软件的实现
我们知道了,模型和接口都是相对稳定的部分,但是实现却会根据模型和接口的需要而有所不同。
一旦进入实现,就有可能会迷失在海洋里。所以,我们不太可能记住实际项目中的所有细节。郑晔老师建议,研究实现,需要找到两个关键点:软件的结构 和 关键的技术。
软件的结构其实也算是软件的模型,不过,这里的结构具体指展开实现之后的模型(因为,大部分的模型都是分层的,从整体看是完整的一块,而打开之后看就是多个模块的组合)。
对于软件结构,最佳实践就是能够找到一张结构图,以便我们准确了解其结构。但是,往往我们的开发团队在项目开发时往往都不会对设计做文档化的沉淀,这也是大部分团队的一个通病,或许是因为项目工期的原因,或许是因为设计者个人的原因,总之,大部分接手已有项目的开发人员在接手初期过得都很痛苦,在心里痛骂这个项目之前的作者。
假设我们通过各种方式(比如请高级别同事吃火锅喝阔乐然后跪求他画一张,如果一顿火锅不行,那就两顿)已经得到了一张最简单的结构图,该怎么继续抓重点呢?郑叶老师建议,带着问题上路,假设自己就是这个软件的设计者,问问自己要怎么设计,再去和原作者的设计做比较。

Kafka的最简单结构图,出自郑晔《软件设计之美》
从最基本的结构图开始,不断提出自己的问题,在代码中对这些问题进行有针对性的探索,然后不断完善这个图,最终就会成为你了解实现的主线。
构建了自己对于实现的主线也就是软件的结构图之后,还需要去了解这个软件的关键技术,即到底是什么玩意儿让这个软件的实现与众不同?而去了解其关键技术的目的,就在于尽可能保证我们对这个项目的代码的调整不会使得项目出现明显的劣化。
郑晔老师以Kafka为例,Kafka为何与RabbitMQ等其他MQ与众不同?因为它针对写入操作做了优化,所以它的整体吞吐能力很强。原因就在于,Kafka利用了磁盘顺序读写的特性,对于前些年广泛采用机械硬盘的服务器来说,它相比传统的随机写大幅度减少了磁头的运动,所以效率提高了不少。如果只看实现,似乎觉得这理所应该。但是,站在设计的角度,让我们作为Kafka的设计者,则不一定能想的出来。因为,这需要作为设计者的人,要具备很强的软硬结合的能力,即也对硬件的机制有较为深入的掌握。
看到这里,我回头看了一眼我书柜里面的那本《深入理解计算机系统》,嗯,它已经吃灰了很多年了,而我一次也没有宠幸过它。

综述,要理解实现,需要带着自己的问题,去了解软件的结构 和 关键的技术。
5 小结
本文我们学习了了解一个软件的设计的三步走:先模型,后接口,最后是实现。对于模型,我们需要尽可能了解它的来龙去脉,要解决的问题,为什么要解决这个问题。对于接口,我们需要找到主线,然后看风格。对于实现,我们需要带着自己的问题,了解软件的结构和关键的技术。经历了这三步,我们就基本可以了解一个软件的设计了。
最后,感谢郑晔老师的这门《软件设计之美》课程,让我受益匪浅!我也诚心把它推荐给关注各位童鞋!
参考资料
郑晔,《软件设计之美》(极客时间课程,推荐订阅学习)




 浙公网安备 33010602011771号
浙公网安备 33010602011771号