
借助 Lucene.Net 构建站内搜索引擎(下)
 上一篇我们学习了Lucene.Net的基本概念、分词以及实现了一个最简单的搜索引擎,这一篇我们开始开发一个初具规模的站内搜索项目,通过开发站内搜索模块,我们可以方便地在项目中集成站内搜索功能。本次Demo所使用到的技术包括:ASP.Net WebForms,ADO.Net,Lucene.Net,Log4Net,Quartz.Net,jQuery Ajax等,虽然它只是一个小Demo,但是麻雀虽小,五脏俱全,值得学习。
上一篇我们学习了Lucene.Net的基本概念、分词以及实现了一个最简单的搜索引擎,这一篇我们开始开发一个初具规模的站内搜索项目,通过开发站内搜索模块,我们可以方便地在项目中集成站内搜索功能。本次Demo所使用到的技术包括:ASP.Net WebForms,ADO.Net,Lucene.Net,Log4Net,Quartz.Net,jQuery Ajax等,虽然它只是一个小Demo,但是麻雀虽小,五脏俱全,值得学习。
前言:上一篇我们学习了Lucene.Net的基本概念、分词以及实现了一个最简单的搜索引擎,这一篇我们开始开发一个初具规模的站内搜索项目,通过开发站内搜索模块,我们可以方便地在项目中集成站内搜索功能。本次示例Demo麻雀虽小,五脏俱全,值得学习。
一、项目初窥
1.1 项目背景
本项目模拟一个BBS论坛的文章内容管理系统,当用户发帖之后首先将内容存到数据库,然后对内容进行分词后存入索引库。因此,当用户在论坛站内搜索模块进行搜索时,会直接从索引库中进行匹配并获取查询结果。站内搜索界面的效果如下图所示:
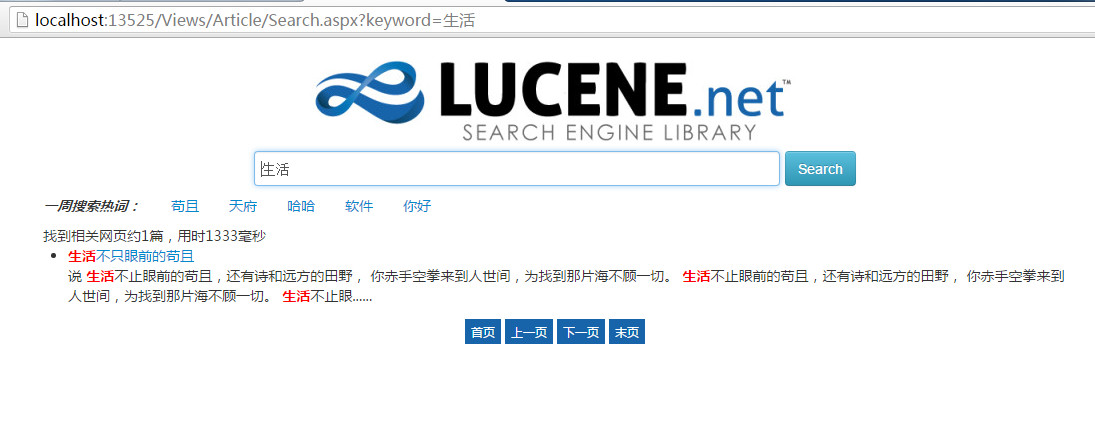
所以,本Demo的重点就在于如何搭建这样的一个站内搜索模块,其他例如文章帖子的CRUD不会多做介绍,请自行下载源码查看。
首先,来看看本Demo的项目结构,虽然只是做一个小Demo,还是使用了简单地三层结构来进行开发:
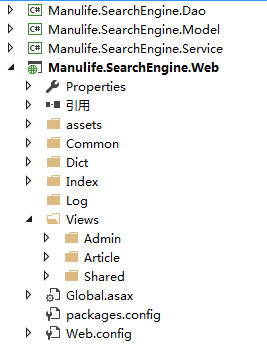
(1)Manulife.SearchEngine.Dao
顾名思义,数据访问层,与数据库进行交互,各种SQL!
(2)Manulife.SearchEngine.Service
业务逻辑层,对数据访问接口进行简单的封装,为UI层提供服务接口。
(3)Manulife.SearchEngine.Model
公共的实体对象,为各个层次提供Entity。
(4)Manulife.SearchEngine.Web
一个ASP.NET WebForm的网站,主要提供Admin管理操作(文章帖子的CRUD)以及站内搜索(我们的关注点就在这儿)。
1.2 数据访问层
(1)本次数据库只涉及到三张表:
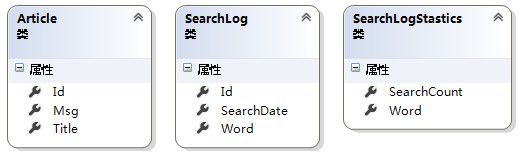
其中,Article是文章表,SearchLog是搜索日志表,SearchLogStastics则是搜索日志统计表(例如:什么关键词搜索了多少次之类的统计)。
(2)为操作这些表提供数据访问对象类
这些代码都很简单,由代码生成器生成,不用care。
1.3 业务逻辑层
本次Demo的业务逻辑层仅仅是对数据访问层方法的简单封装,同样,也是由代码生成器生成,不用care。

其中,对于获取搜索热词考虑到每个用户都会看到热词,为了减轻数据库访问的压力,使用了ASP.NET自带的Cache进行优化,该方法会首先从Cache中查找是否已有了搜索热词,没有才会去数据库中获取,并且设置缓存失效时间为1小时。也就是说,在1小时以内,所有用户看到的搜索热词都是相同的。
public DataTable GetHotKeyword() { // 首先判断缓存中是否有记录 var cacheData = HttpRuntime.Cache["HotKeywords"]; if (cacheData == null) { var hotKeywords = new SearchLogStasticsDao().GetHotKeyword(); // 将结果放入缓存,并设定1小时替换一次缓存 HttpRuntime.Cache.Insert("HotKeywords",hotKeywords,null, DateTime.Now.AddHours(1), TimeSpan.Zero); return hotKeywords; } else { return cacheData as DataTable; } }
1.4 UI界面层
界面层是本次Demo的重点,因为关于站内搜索的所有功能都写在这一层的逻辑代码中。首先,我们来看看Web层的项目结构:
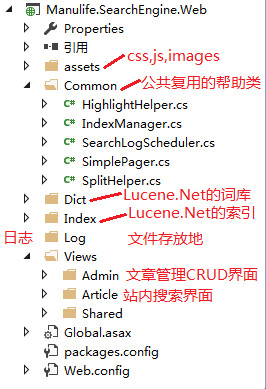
(1)assets
这个不用多说,里面就存放一些css,js与image文件,都是Demo需要使用的。
(2)Common
这个folder下主要是对一些常用功能的封装,以便尽可能实现代码复用。当然,也对Lucene.Net的一些例如创建索引的操作进行了封装,保证代码的单一职责。
(3)Dict与Index

这两个folder下主要是存放Lucene.Net必须要用到的词库与索引文件,如果你还不熟悉,请浏览上一篇进行学习。这里需要注意的是,Dict文件夹下的词库文件需要设置为:如果较新则复制,这样才可以在编译时自动同步到Bin目录下。
(4)Log
这个folder下主要是存放系统一些关键操作的日志记录,以及用户搜索的日志记录。按照年月日进行区分,使用log4net组件进行日志的读写。
(5)Views
这个folder下就是一些我们熟悉的页面了,其中:Admin目录下是后台管理操作,对文章的CRUD操作;Article目录下则是针对前台用户的站内搜索和文章浏览的页面。Shared目录下是一些公用的模板页。这里为了快速开发原型系统所以主要采用ASP.Net WebForms技术进行实现,没有采用ASP.Net MVC。
二、核心代码
2.1 文章索引的创建与更新
(1)设计IndexManager
考虑到文章的发布和修改都需要更新到索引库,因此我们将更新索引库的操作提取出来封装一个class命名为IndexManager。
①首先,索引库的更新是一个耗时的操作,并且IO资源是很珍贵的,所以我们将IndexManager设置为一个单例:
public class IndexManager { public static readonly IndexManager Instance = new IndexManager(); private IndexManager() { } static IndexManager() { } }
这里采用了.NET中独有的静态构造函数方法保证实例的唯一,CLR已经为我们考虑了线程安全的问题了。
C#的语法中有一个函数能够确保只调用一次,那就是静态构造函数。由于C#是在调用静态构造函数时初始化静态变量,.NET运行时(CLR)能够确保只调用一次静态构造函数,这样我们就能够保证只初始化一次instance。
②其次,借助生产者消费者的思想,通过消息队列的方式将原来同步的创建索引操作变为任务队列的异步操作。由此用户在发布文章时,不用等待索引创建完成后才得到提示,只需要等到保存到数据库之后就可以退出进行其他操作。
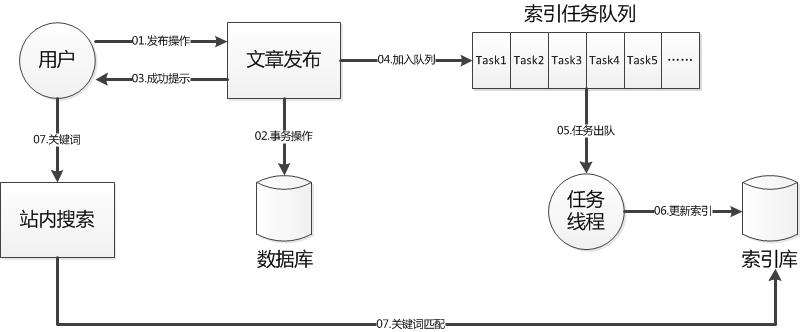
关键代码如下所示:
public class IndexManager { ...... public void Start() { Thread thread = new Thread(WatchIndexTask); thread.IsBackground = true; thread.Start(); log.Debug("IndexManager has been lunched successfully!"); } private Queue<IndexTask> indexQueue = new Queue<IndexTask>(); private void WatchIndexTask() { while (true) { if (indexQueue.Count > 0) { // 索引文档保存位置 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(IndexPath), new NativeFSLockFactory()); bool isUpdate = IndexReader.IndexExists(directory); //判断索引库是否存在 log.Debug(string.Format("The status of index : {0}", isUpdate)); if (isUpdate) { // 如果索引目录被锁定(比如索引过程中程序异常退出),则首先解锁 // Lucene.Net在写索引库之前会自动加锁,在close的时候会自动解锁 // 不能多线程执行,只能处理意外被永远锁定的情况 if (IndexWriter.IsLocked(directory)) { log.Debug("The index is existed, need to unlock."); IndexWriter.Unlock(directory); //unlock:强制解锁,待优化 } } // 创建向索引库写操作对象 IndexWriter(索引目录,指定使用盘古分词进行切词,最大写入长度限制) // 补充:使用IndexWriter打开directory时会自动对索引库文件上锁 IndexWriter writer = new IndexWriter(directory, new PanGuAnalyzer(), !isUpdate, IndexWriter.MaxFieldLength.UNLIMITED); log.Debug(string.Format("Total number of task : {0}", indexQueue.Count)); while (indexQueue.Count > 0) { IndexTask task = indexQueue.Dequeue(); long id = task.TaskId; ArticleService articleService = new ArticleService(); Article article = articleService.GetById(id); if (article == null) { continue; } // 一条Document相当于一条记录 Document document = new Document(); // 每个Document可以有自己的属性(字段),所有字段名都是自定义的,值都是string类型 // Field.Store.YES不仅要对文章进行分词记录,也要保存原文,就不用去数据库里查一次了 document.Add(new Field("id", id.ToString(), Field.Store.YES, Field.Index.NOT_ANALYZED)); // 需要进行全文检索的字段加 Field.Index. ANALYZED // Field.Index.ANALYZED:指定文章内容按照分词后结果保存,否则无法实现后续的模糊查询 // WITH_POSITIONS_OFFSETS:指示不仅保存分割后的词,还保存词之间的距离 document.Add(new Field("title", article.Title, Field.Store.YES, Field.Index.ANALYZED, Field.TermVector.WITH_POSITIONS_OFFSETS)); document.Add(new Field("msg", article.Msg, Field.Store.YES, Field.Index.ANALYZED, Field.TermVector.WITH_POSITIONS_OFFSETS)); if (task.TaskType != TaskTypeEnum.Add) { // 防止重复索引,如果不存在则删除0条 writer.DeleteDocuments(new Term("id", id.ToString()));// 防止已存在的数据 => delete from t where id=i } // 把文档写入索引库 writer.AddDocument(document); log.Debug(string.Format("Index {0} has been writen to index library!", id.ToString())); } writer.Close(); // Close后自动对索引库文件解锁 directory.Close(); // 不要忘了Close,否则索引结果搜不到 log.Debug("The index library has been closed!"); } else { Thread.Sleep(2000); } } } ...... }
这里使用了.NET内置的队列数据结构Queue来实现更新索引任务的队列。
③考虑到新增索引和更新索引操作的差异,为页面提供两个接口,其本质都是向任务队列插入一条新的任务。只不过任务的TaskType枚举不一样,通过此枚举标识,在更新索引时会进行判断是否需要删除原来的索引进行重建。
public class IndexManager { ...... public void AddArticle(IndexTask task) { task.TaskType = TaskTypeEnum.Add; indexQueue.Enqueue(task); } public void UpdateArticle(IndexTask task) { task.TaskType = TaskTypeEnum.Update; indexQueue.Enqueue(task); } } public class IndexTask { public long TaskId { get; set; } public TaskTypeEnum TaskType { get; set; } } public enum TaskTypeEnum { Add, Update }
(2)IndexManager的使用
在文章编辑保存按钮的事件中使用IndexManager暴露的两个接口方法进行索引的创建和更新:
protected void btnSave_Click(object sender, EventArgs e) { string action = Request["action"]; if (action == "Edit") { ...... // 更新数据库 articleService.Update(art); // 更新索引库 IndexTask task = new IndexTask(); task.TaskId = id; IndexManager.Instance.UpdateArticle(task); Response.Redirect("ArticleList.aspx"); } else if (action == "AddNew") { ...... // 更新数据库 art = articleService.Add(art); // 更新索引库 IndexTask task = new IndexTask(); task.TaskId = art.Id; IndexManager.Instance.AddArticle(task); Response.Redirect("ArticleList.aspx"); } else { throw new Exception("action错误!"); } }
2.2 统计任务的调度与执行
(1)统计任务的背景
考虑到用户可能对其他用户搜索的热词的需求,系统需要对用户输入的搜索词进行记录,并统计出一段时间内用户搜索频率最高的一些关键词,类似于微博的热搜榜:

而我们要做的就是需要统计一周内所有用户搜索次数最多的5个关键词,并固定显示在搜索页面中。通过SearchLog表(用户的每一次搜索操作都会记录到数据库中)的分析,我们可以通过如下语句进行统计:
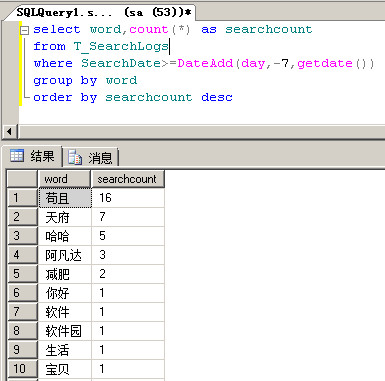
因此,我们只需要将Top 5的热词绑定到页面即可。
(2)借助Quartz.Net实现定时统计任务
Quartz.NET是一个开源的作业调度框架,是OpenSymphony 的 Quartz API的.NET移植,它用C#写成,可用于winform和asp.net应用中。它提供了巨大的灵活性而不牺牲简单性。你能够用它来为执行一个作业而创建简单的或复杂的调度,就像你创建一个Windows的定时任务一样,So Easy!
这里我们的业务流程是:每一个小时(如果间隔很短会对数据库造成压力)对SearchLogStatics表(搜索记录统计表)进行更新,更新的详细流程如下图所示:

使用Quartz.Net有三个核心部分:Schedule、Job和Trigger,一句话概括就是:给某个人(工作线程)指定一个计划(Schedule),具体是做什么事(Job),在什么时候开始做(Trigger)。
public static class SearchLogScheduler { public static void Start() { // 每隔一段时间执行任务 IScheduler sched; ISchedulerFactory sf = new StdSchedulerFactory(); sched = sf.GetScheduler(); // IndexJob为实现了IJob接口的类 JobDetail job = new JobDetail("job1", "group1", typeof(BuildStasticsJob)); // 5秒后开始第一次运行 DateTime ts = TriggerUtils.GetNextGivenSecondDate(null, 5); // 每隔1小时执行一次 TimeSpan interval = TimeSpan.FromHours(1); // 每若干小时运行一次,小时间隔由appsettings中的IndexIntervalHour参数指定 Trigger trigger = new SimpleTrigger("trigger1", "group1", "job1", "group1", ts, null, SimpleTrigger.RepeatIndefinitely, interval); sched.AddJob(job, true); sched.ScheduleJob(trigger); sched.Start(); } } /// <summary> /// 具体要执行的任务 /// </summary> public class BuildStasticsJob : IJob { private SearchLogStasticsService stasticService; public BuildStasticsJob() { stasticService = new SearchLogStasticsService(); } public void Execute(JobExecutionContext context) { // 删除所有统计记录 stasticService.Delete(); // 重新统计插入表中 stasticService.Stastic(); } }
2.3 获取搜索结果
(1)搜索页的工作
在搜索主页面加载时,需要进行三件事:

protected void Page_Load(object sender, EventArgs e) { // 绑定一周热词 BindHotKeywords(); if (Request["keyword"] == null) { return; } string keyword = Request["keyword"].ToString(); // 绑定搜索结果 BindPagerHtml(keyword); // 添加搜索记录 AddSearchLog(keyword); }
(2)这里主要看看如何获取搜索结果

private void BindSearchResult(string keyword, int startIndex, int pageSize, out int totalCount) { string indexPath = Context.Server.MapPath("~/Index"); // 索引文档保存位置 FSDirectory directory = FSDirectory.Open(new DirectoryInfo(indexPath), new NoLockFactory()); IndexReader reader = IndexReader.Open(directory, true); IndexSearcher searcher = new IndexSearcher(reader); IEnumerable<string> keyList = SplitHelper.SplitWords(keyword); PhraseQuery queryTitle = new PhraseQuery(); foreach (var key in keyList) { queryTitle.Add(new Term("title", key)); } queryTitle.SetSlop(100); PhraseQuery queryMsg = new PhraseQuery(); foreach (var key in keyList) { queryMsg.Add(new Term("msg", key)); } queryMsg.SetSlop(100); BooleanQuery query = new BooleanQuery(); query.Add(queryTitle, BooleanClause.Occur.SHOULD); // SHOULD => 可以有,但不是必须的 query.Add(queryTitle, BooleanClause.Occur.SHOULD); // SHOULD => 可以有,但不是必须的 // TopScoreDocCollector:盛放查询结果的容器 TopScoreDocCollector collector = TopScoreDocCollector.create(1000, true); // 使用query这个查询条件进行搜索,搜索结果放入collector searcher.Search(query, null, collector); // 首先获取总条数 totalCount = collector.GetTotalHits(); // 从查询结果中取出第m条到第n条的数据 ScoreDoc[] docs = collector.TopDocs(startIndex, pageSize).scoreDocs; // 遍历查询结果 IList<SearchResult> resultList = new List<SearchResult>(); for (int i = 0; i < docs.Length; i++) { // 拿到文档的id,因为Document可能非常占内存(DataSet和DataReader的区别) int docId = docs[i].doc; // 所以查询结果中只有id,具体内容需要二次查询 // 根据id查询内容:放进去的是Document,查出来的还是Document Document doc = searcher.Doc(docId); SearchResult result = new SearchResult(); result.Url = "ViewArticle.aspx?id=" + doc.Get("id"); result.Title = HighlightHelper.HighLight(keyword, doc.Get("title")); result.Msg = HighlightHelper.HighLight(keyword, doc.Get("msg")) + "......"; resultList.Add(result); } // 绑定到Repeater rptSearchResult.DataSource = resultList; rptSearchResult.DataBind(); }
这里使用Lucene.Net提供的BooleanQuery进行复合查询,何为复合查询?举个例子,假设某个帖子的Title为“阿凡达大战机器猫”,帖子内容Content为“呵呵,你妹!”。这时,假设我们只对Content进行查询,那么用户搜索阿凡达就会搜不到。所以,我们需要对Title和Content都进行查询,也就需要使用BooleanQuery。
2.4 搜索建议提示

相信我们在使用百度等搜索引擎进行搜索时都会看到每当我们输入一个词时,会弹出提示框,下面有很多相关的搜索项。这里我们可以通过AJAX操作完成搜索建议功能。
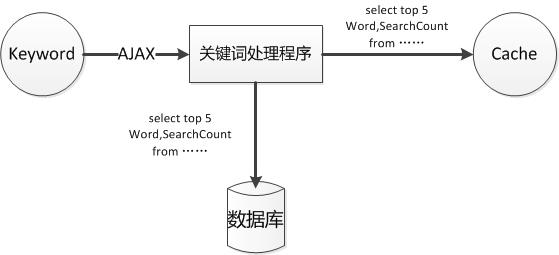
这里我们得AutoComplete使用的是一个jQuery UI的AutoComplete插件,前端调用其封装的Ajax请求方法:
$(function () { $("#txtKeyword").autocomplete({ source: "SearchSuggestionHandler.ashx", select: function (event, ui) { $("#txtKeyword").val(ui.item.value); $("#mainForm").submit(); } }); $("#txtKeyword").focus(); });
后端是一个一般处理程序,负责将Keyword与数据库中搜索记录表中的Item进行匹配,如果有匹配项则序列化为JSON传递到前端,前端负责将JSON反序列化并显示到AutoComplete框中:
public class SearchSuggestionHandler : IHttpHandler { public void ProcessRequest(HttpContext context) { context.Response.ContentType = "text/plain"; // 注意这里传过来的参数name是term string keyword = context.Request["term"]; IList<string> keywordList = new List<string>(); SearchLogStasticsService statService = new SearchLogStasticsService(); DataTable dt = statService.GetSuggestion(keyword); foreach (DataRow dr in dt.Rows) { keywordList.Add(Convert.ToString(dr["Word"])); } JavaScriptSerializer jss = new JavaScriptSerializer(); string json = jss.Serialize(keywordList); context.Response.Write(json); } }
三、效果演示
前面说了那么多,终于到了Show Time。不过,也没什么好Show的:
(1)一周热词

(2)搜索提示

(3)搜索结果

附件下载
站内搜索Demo:https://github.com/EdisonChou/SearchEngineWithLuceneNet
【提示:数据库文件在App_Data目录下,建议使用MS SQL Server 2008及以上版本附加】
参考资料
(1)杨中科,《Lucene.Net站内搜索公开课》
(2)痞子一毛,《Lucene.Net》
(3)MeteorSeed,《使用Lucene.Net实现全文检索》
(4)Lucene.Net官方网站:http://lucenenet.apache.org/download.html


 浙公网安备 33010602011771号
浙公网安备 33010602011771号