CS294-112 深度强化学习 秋季学期(伯克利)NO.3 Reinforcement learning introduction





first order markov chain








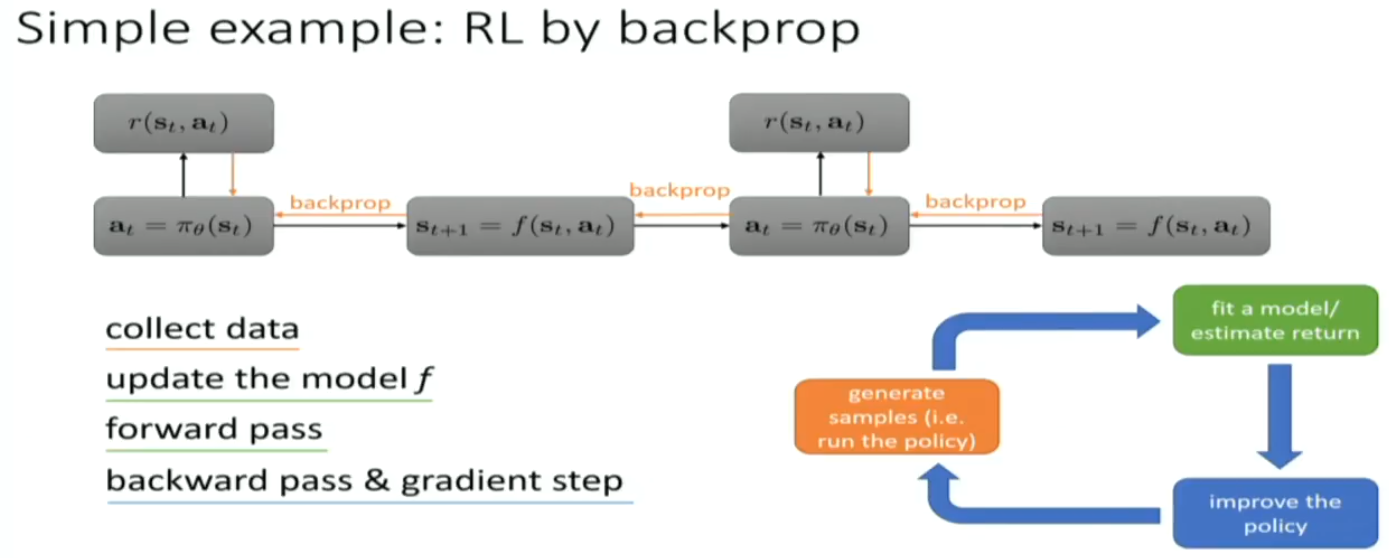









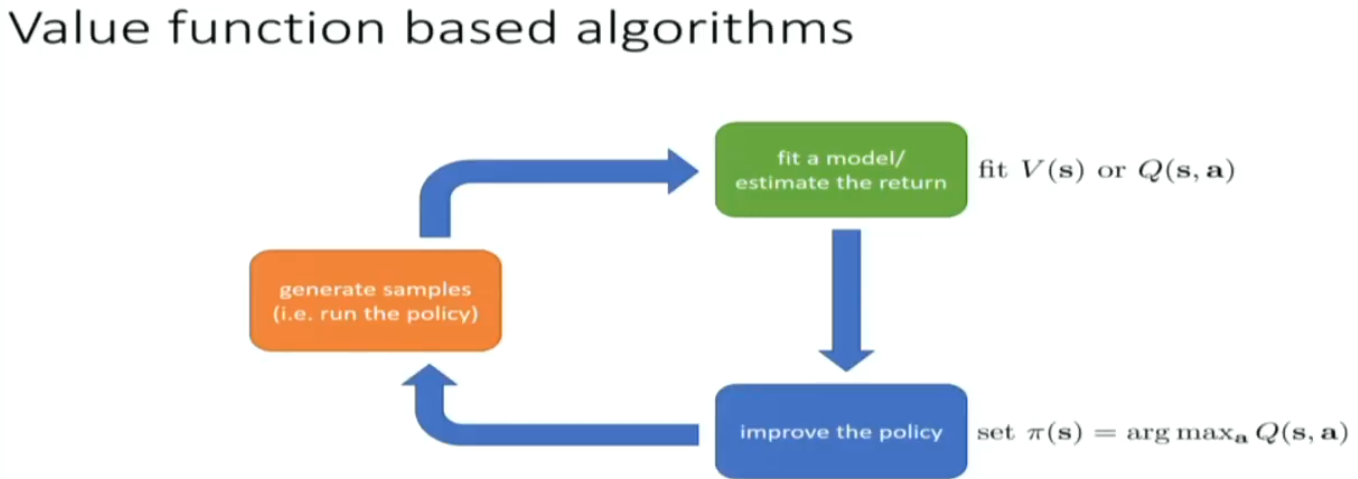






on policy algorithm is easier to be paralleled
off policy algorithm has to fit transition net, and policy net. much more computationally expensive









 浙公网安备 33010602011771号
浙公网安备 33010602011771号