CS294-112深度增强学习课程(加州大学伯克利分校 2017)NO.4 Learning policies by imitating optimal controllers



There are some problems: mismatch of model and reality; gradient explosion
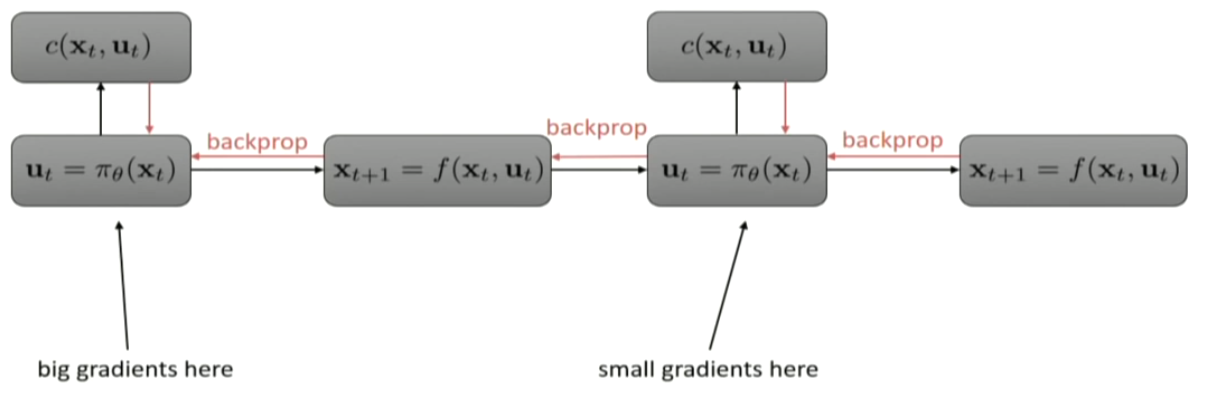
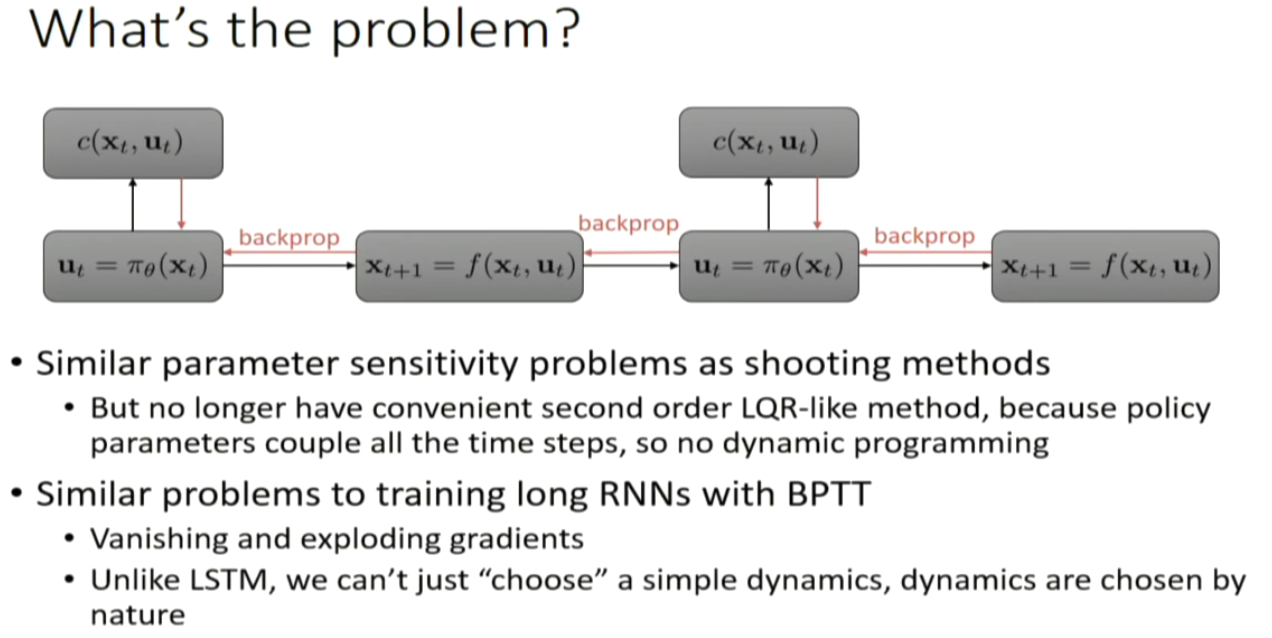
so, the dynamics can be quite messy, and backpropogating can be quite problematic.
sudden change in velocity and so on. schochastic system. gradient descent can be tough.
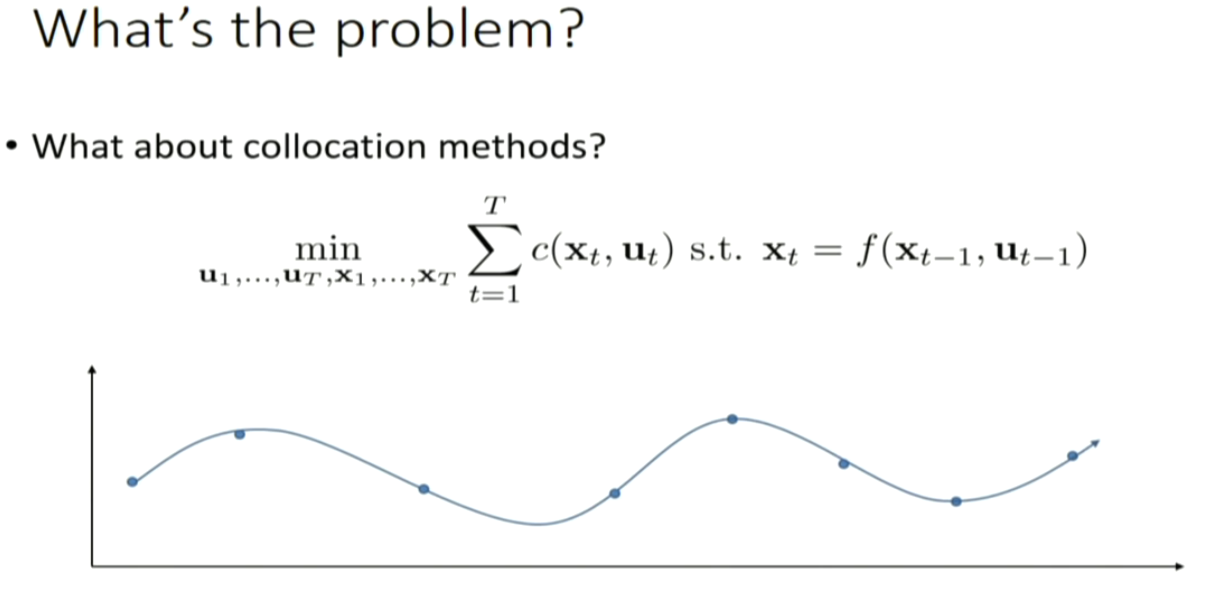
can we apply this trajectory optimization method to optimize policy?

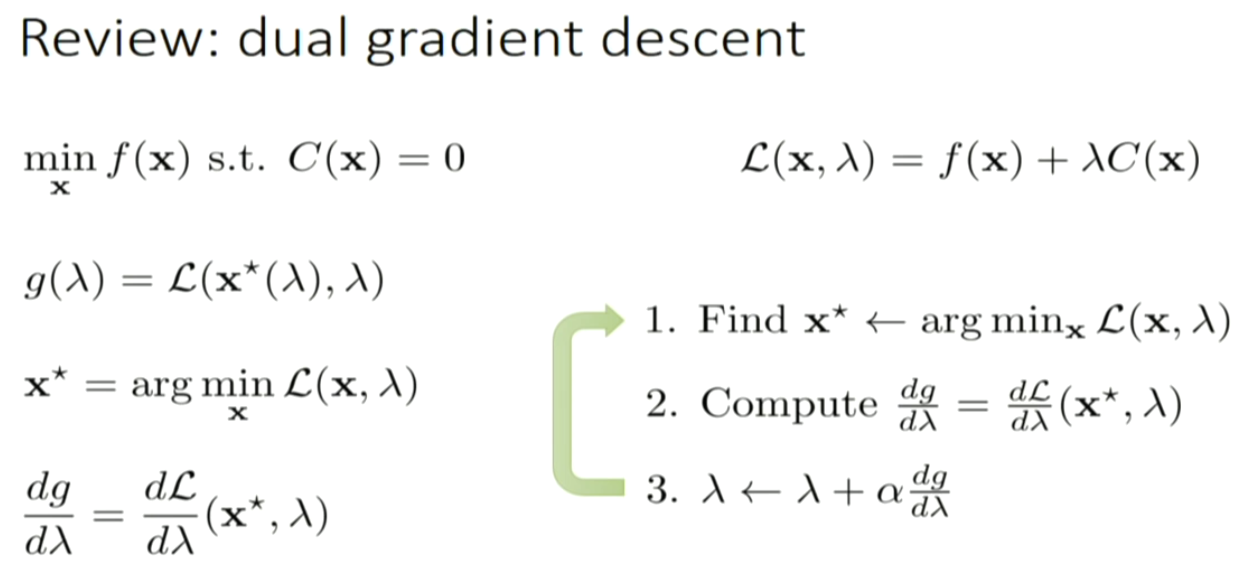




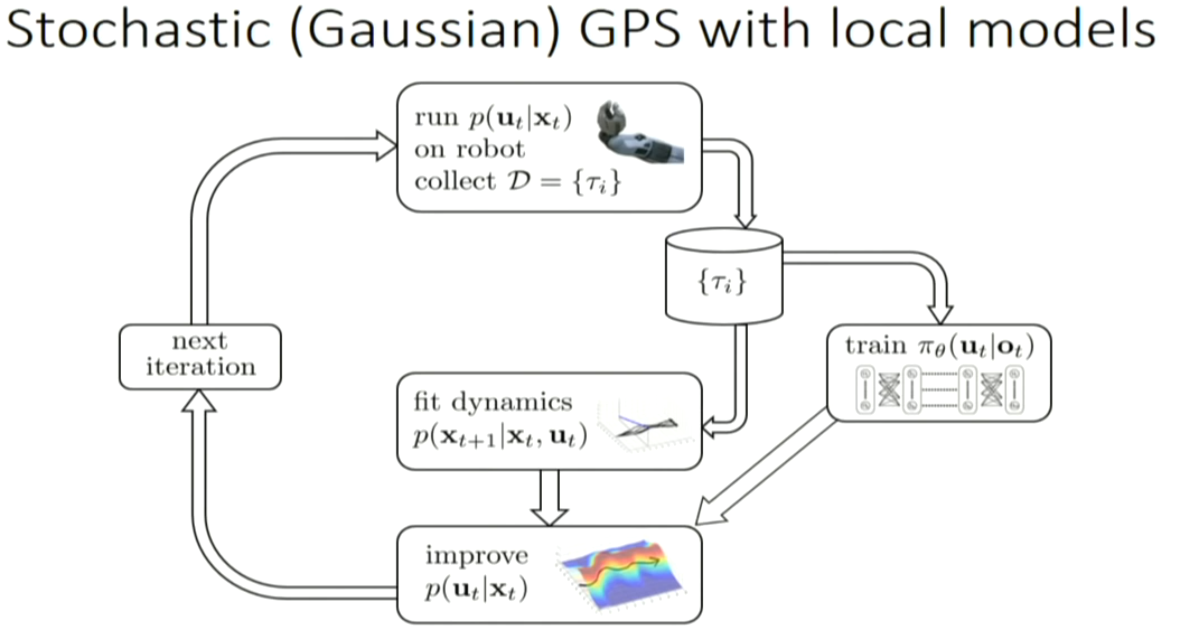
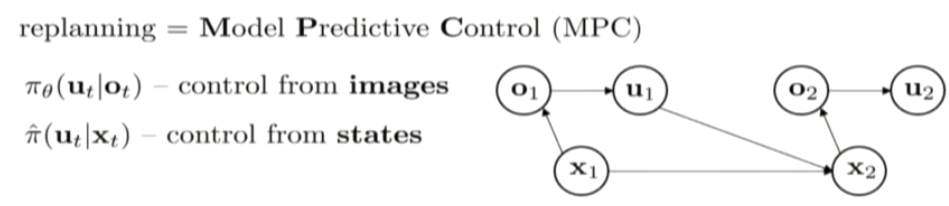
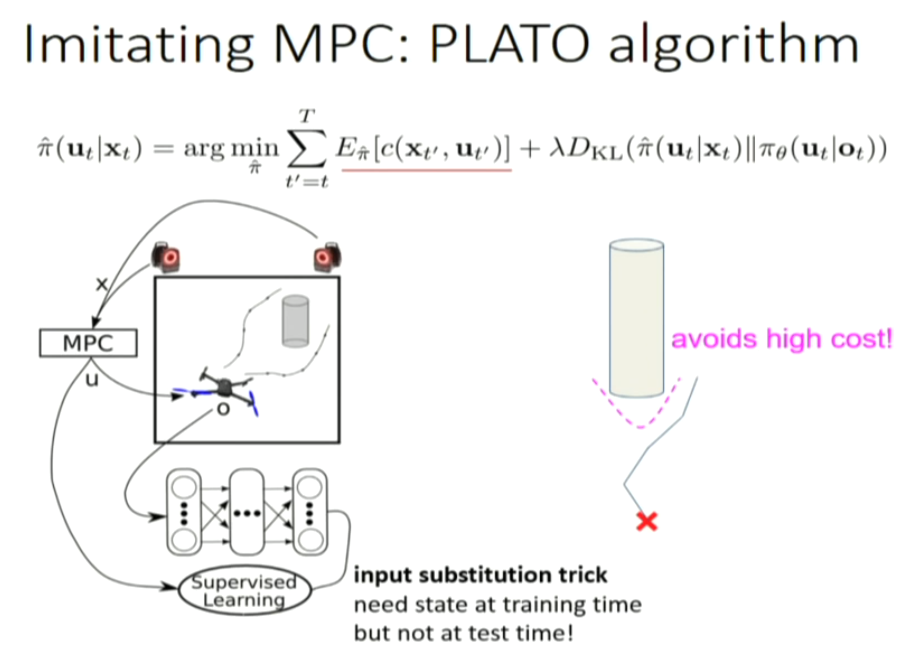
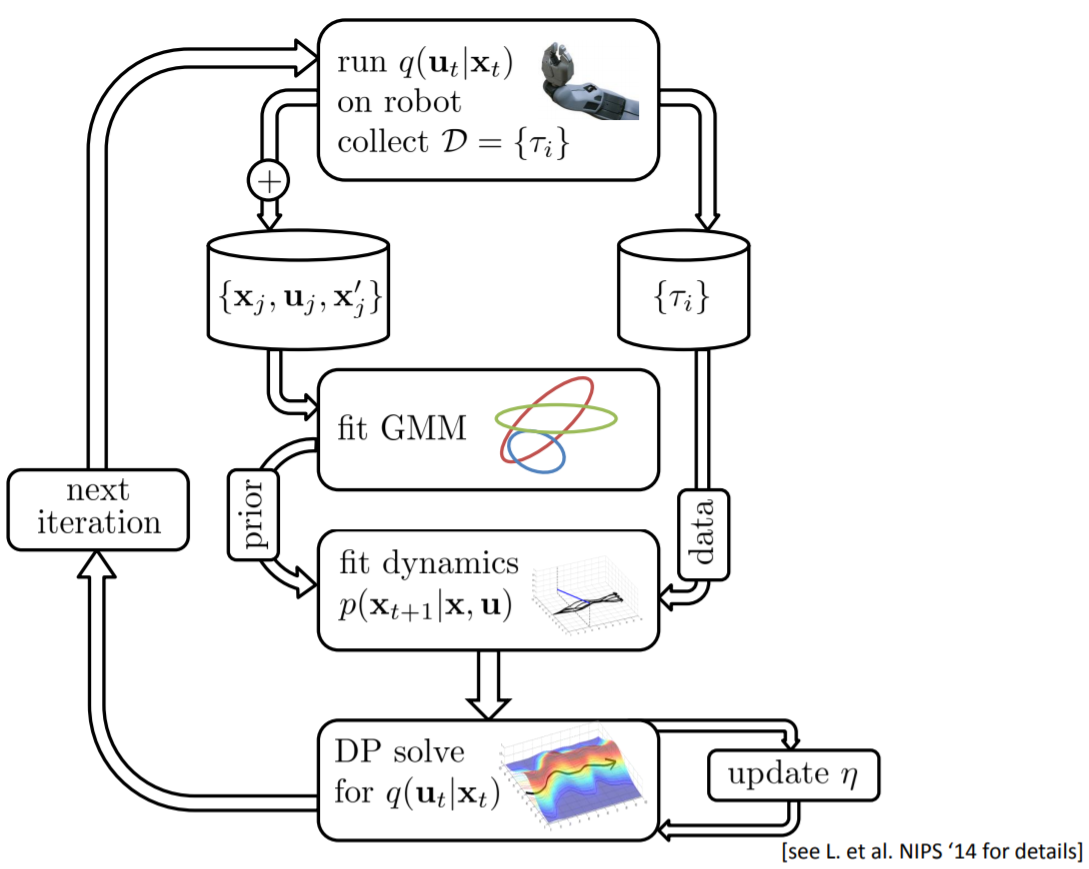
GPS: guided policy search
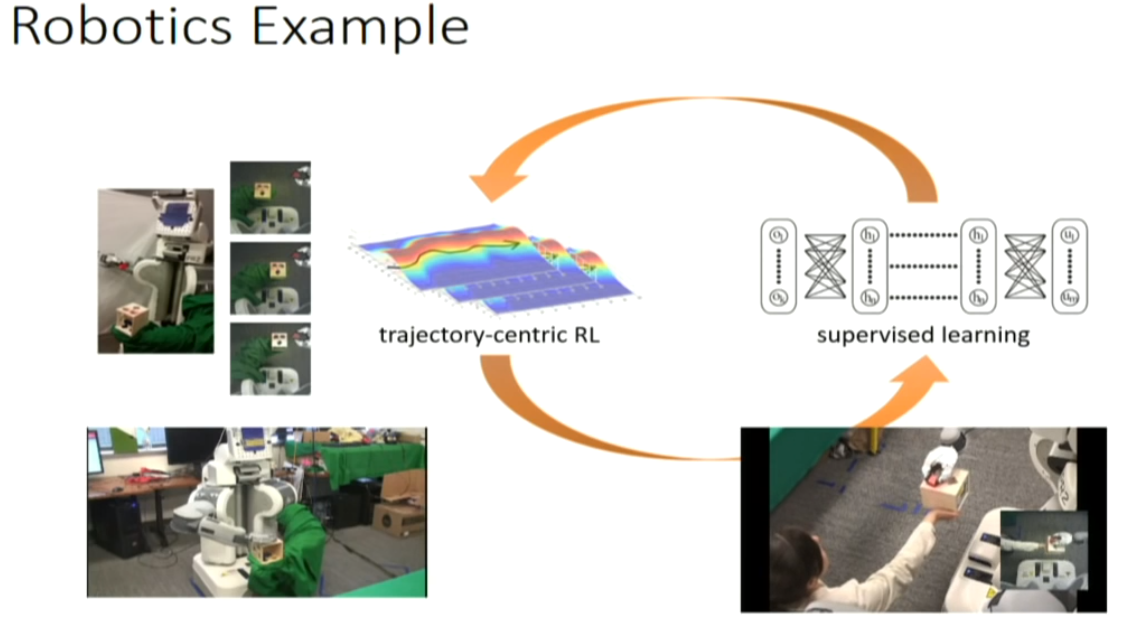
in this case, ot is from the camera and the joint velocity















https://katefvision.github.io/katefSlides/imitate_controlers_katef.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号