[Operating System] {ud923} P3L1: Scheduling

- Fedorova, Alexandra, et. al.
"Chip Multithreading Systems Need a New Operating System Scheduler".
Proceedings of the 11th workshop on ACM SIGOPS European workshop (EW 11). ACM, New York, NY, 2004.
Visual Metaphor

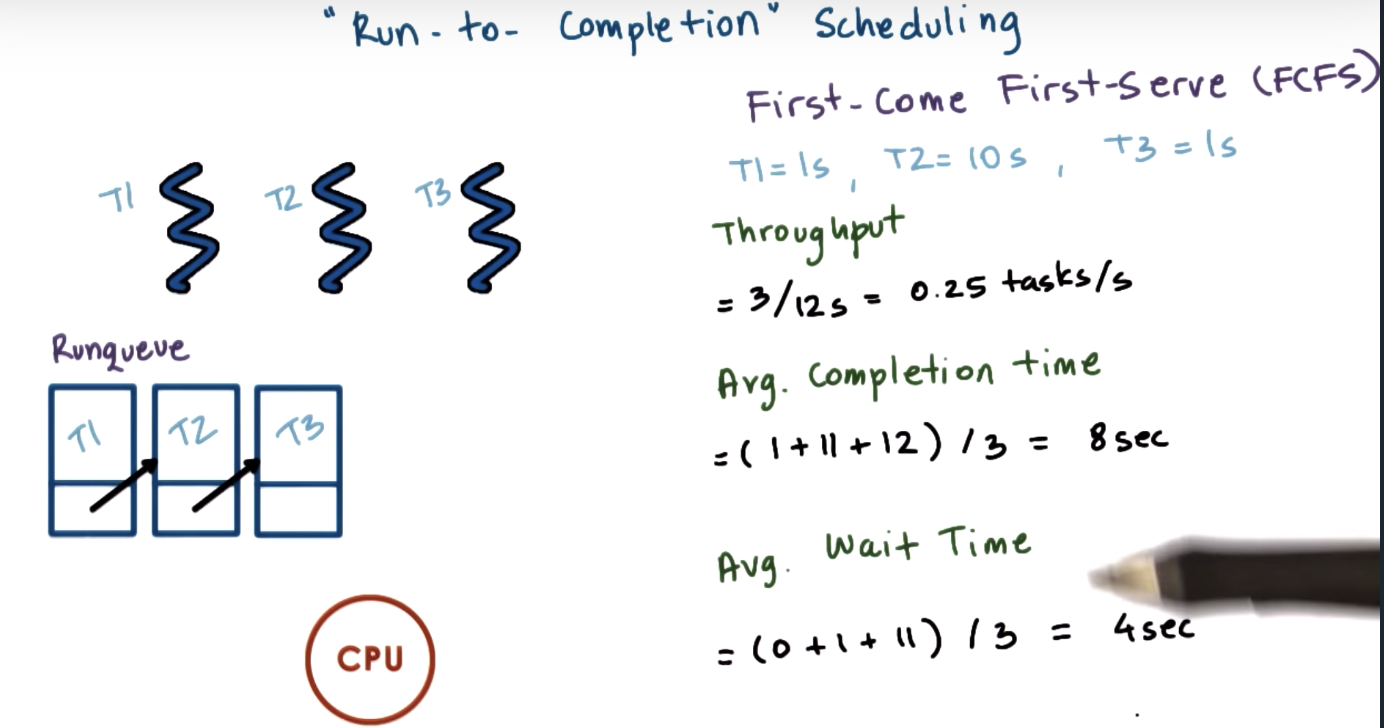
FIFO first in first out
FCFS first come first serve
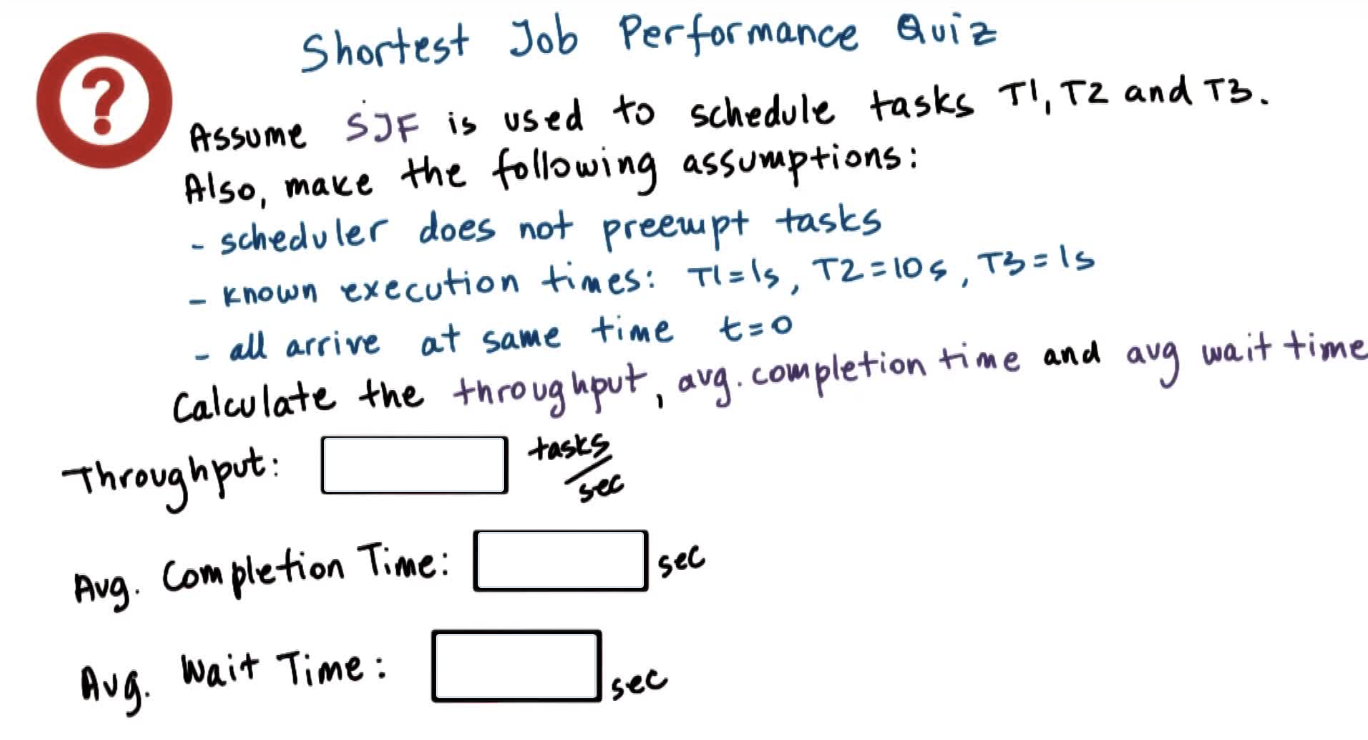
SJF: shortest job first
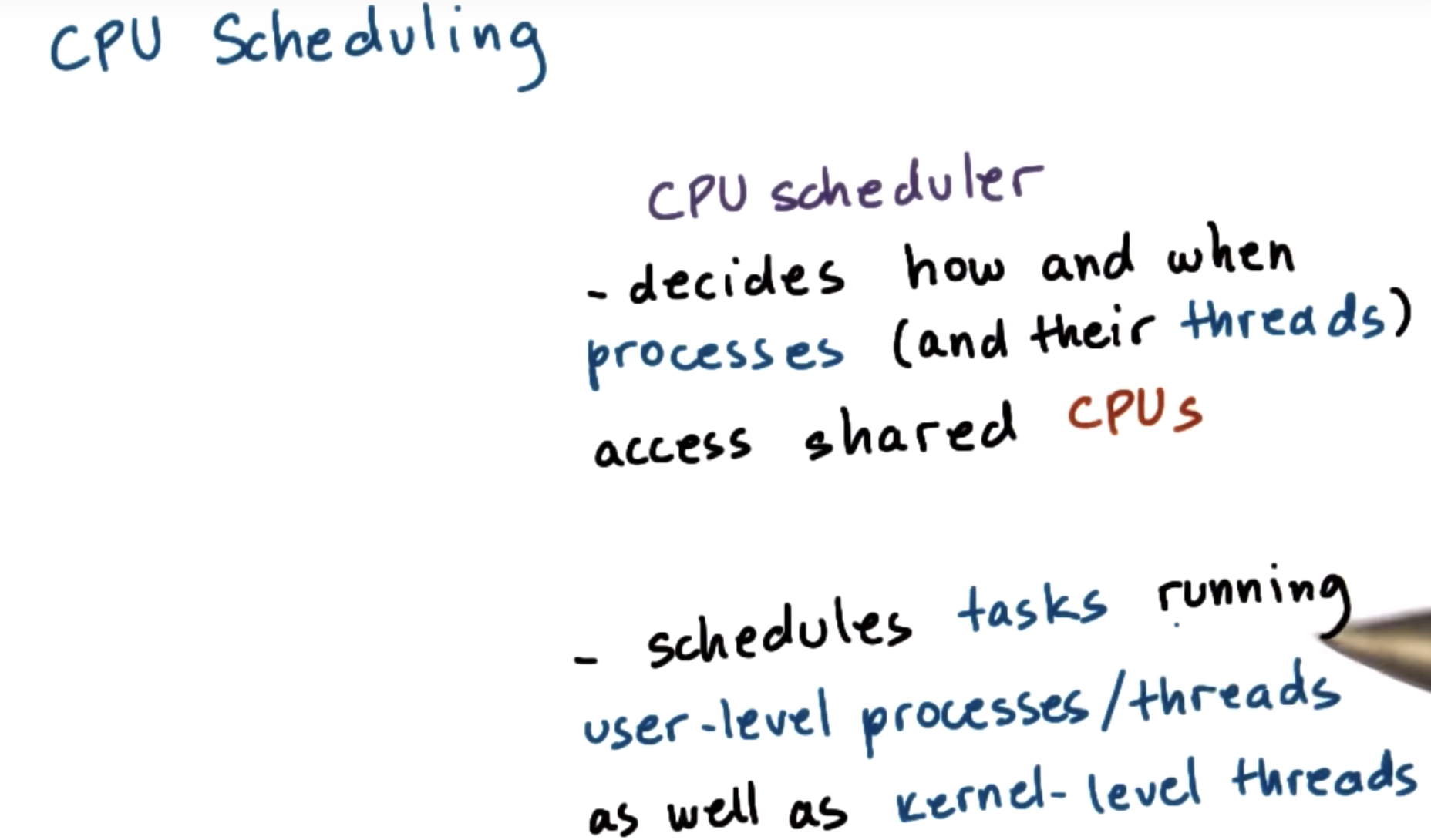
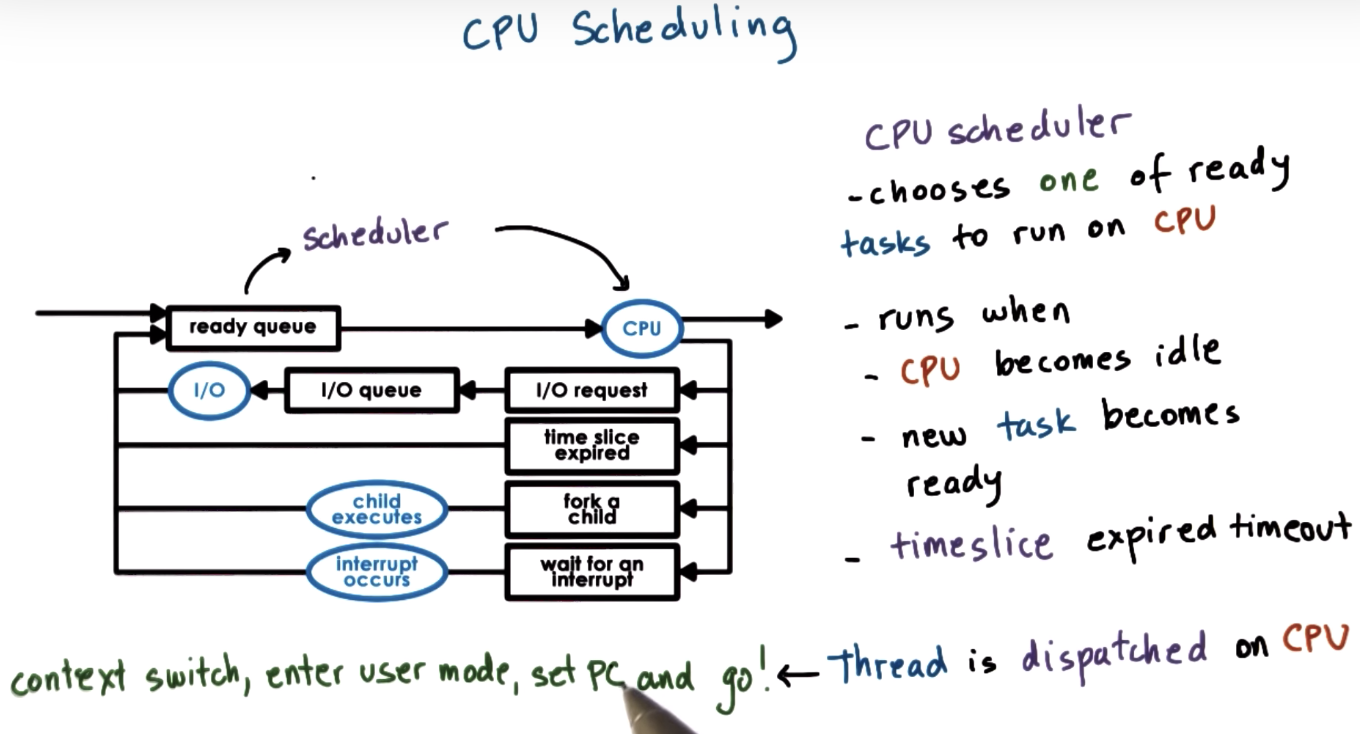
Scheduling Overview
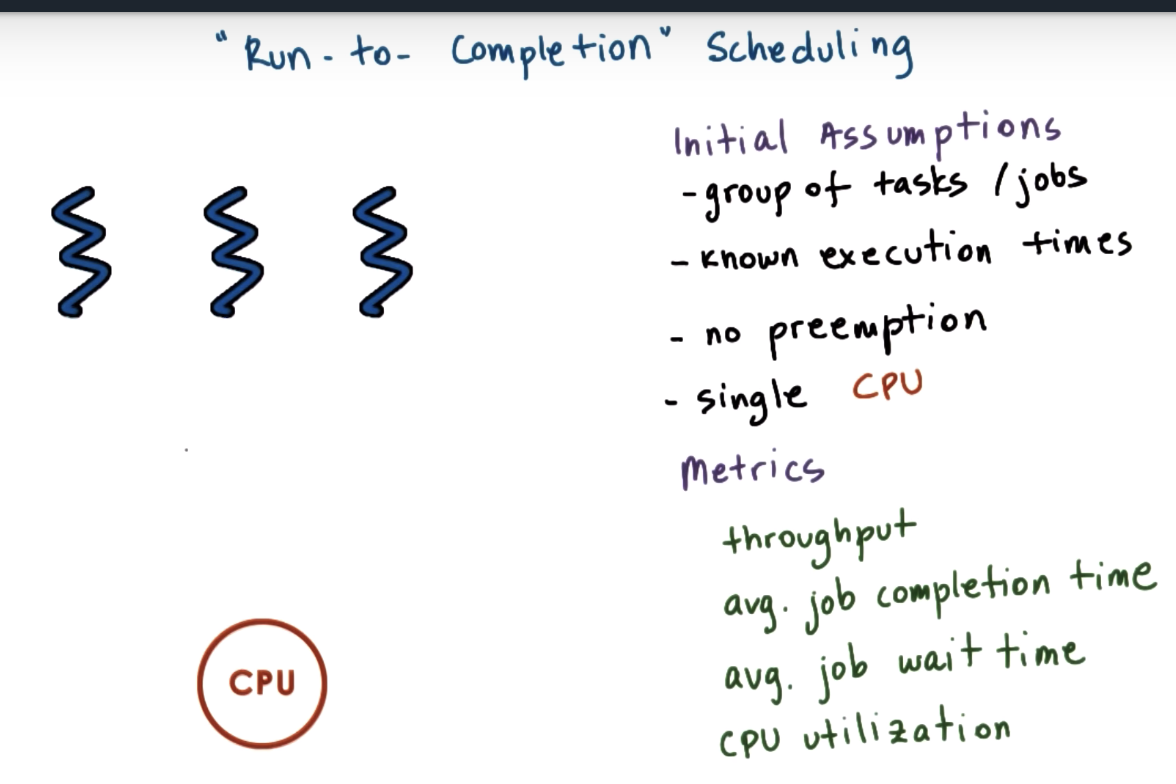
Run To Completion Scheduling



std::priority_queue??
0.25;
5;
1;
Throughput Formula:
- jobs_completed / time_to_complete_all_job
Avg. Completion Time Formula:
- sum_of_times_to_complete_each_job / jobs_completed
Avg. Wait Time Formula:
- (t1_wait_time + t2_wait_time + t3_wait_time) / jobs_completed
You do not have to include units in your answers. Also, for decimal answers, please round to the hundredths.
- time_to_complete_all_job / jobs_completed
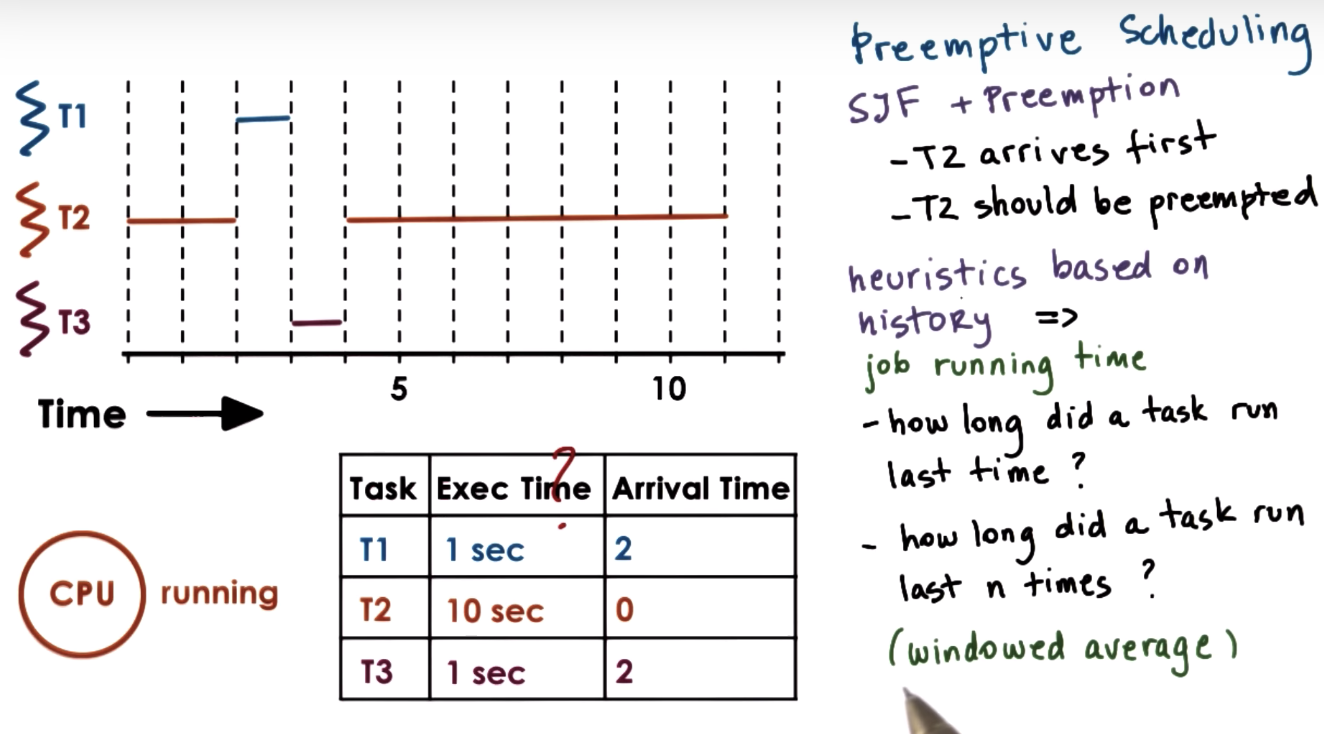
Preemptive Scheduling: SJF + Preempt
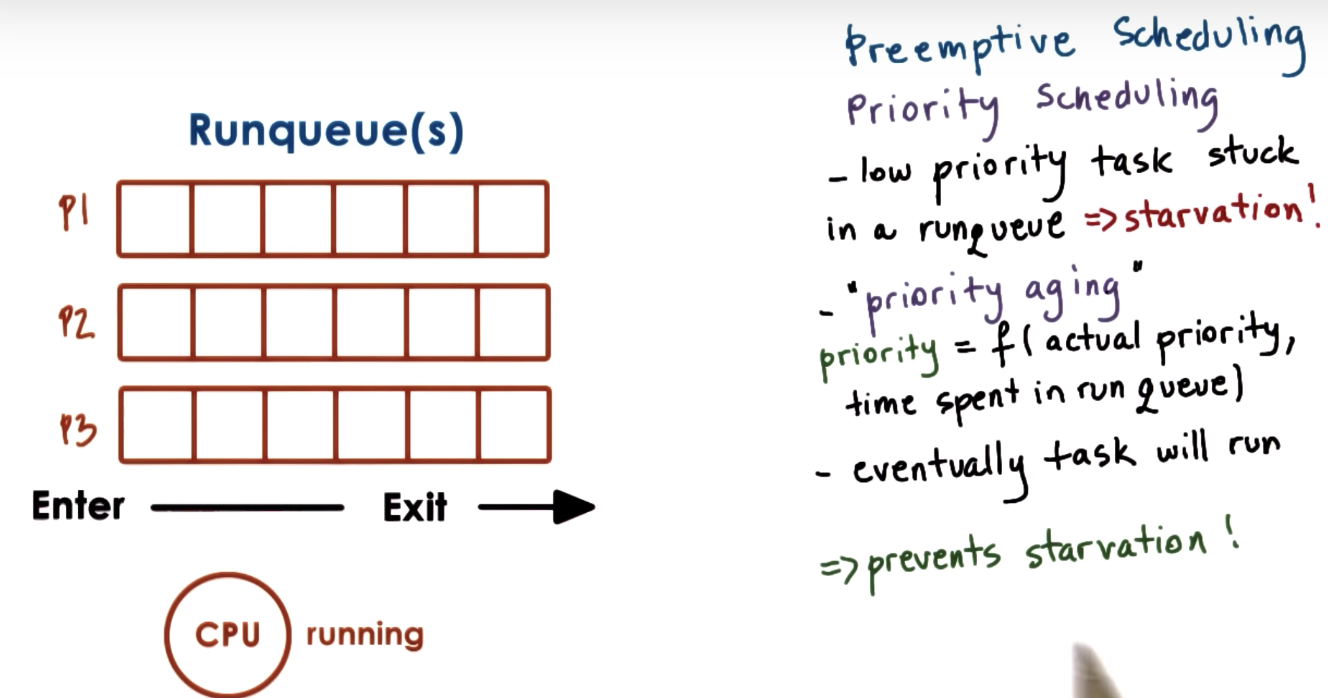
Preemptive Scheduling: Priority



8;10;11
Priority Inversion
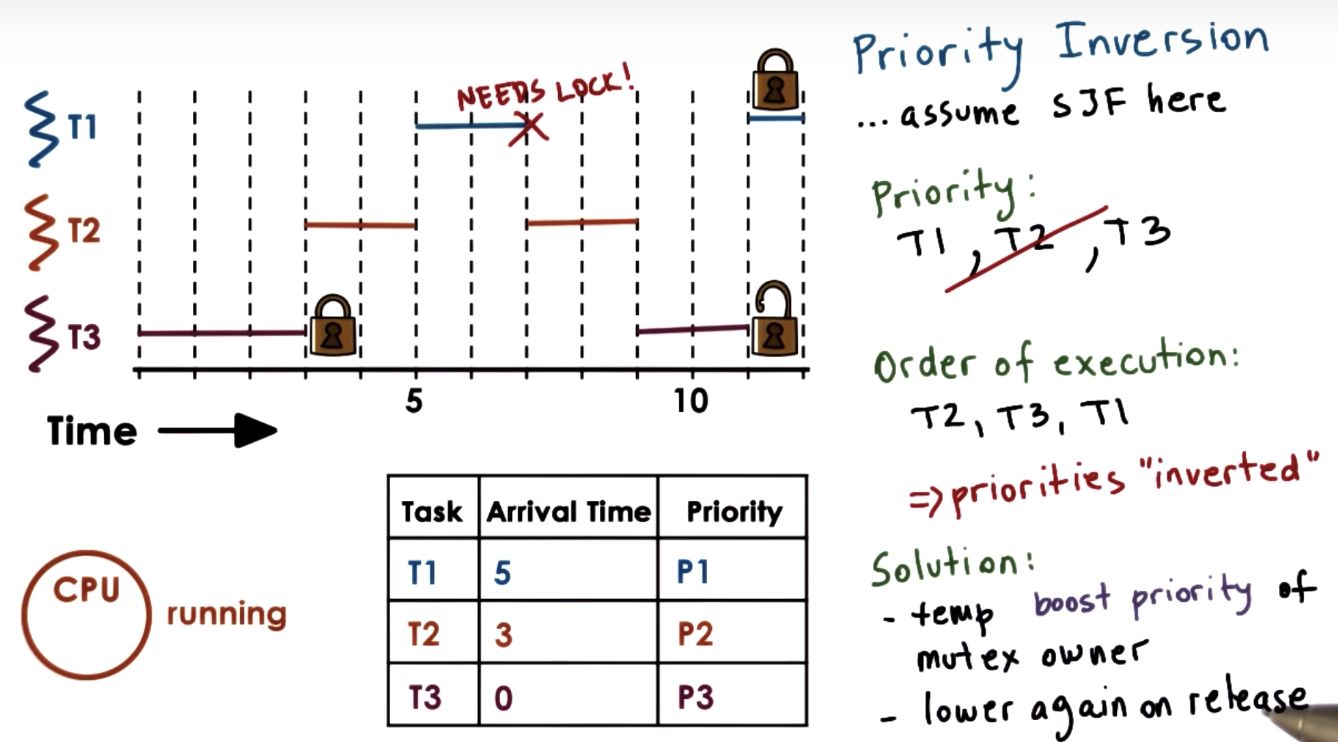
boost T3 to T1 priority temporarily, so that the lock will be released before T2 gets finished.
Round Robin Scheduling

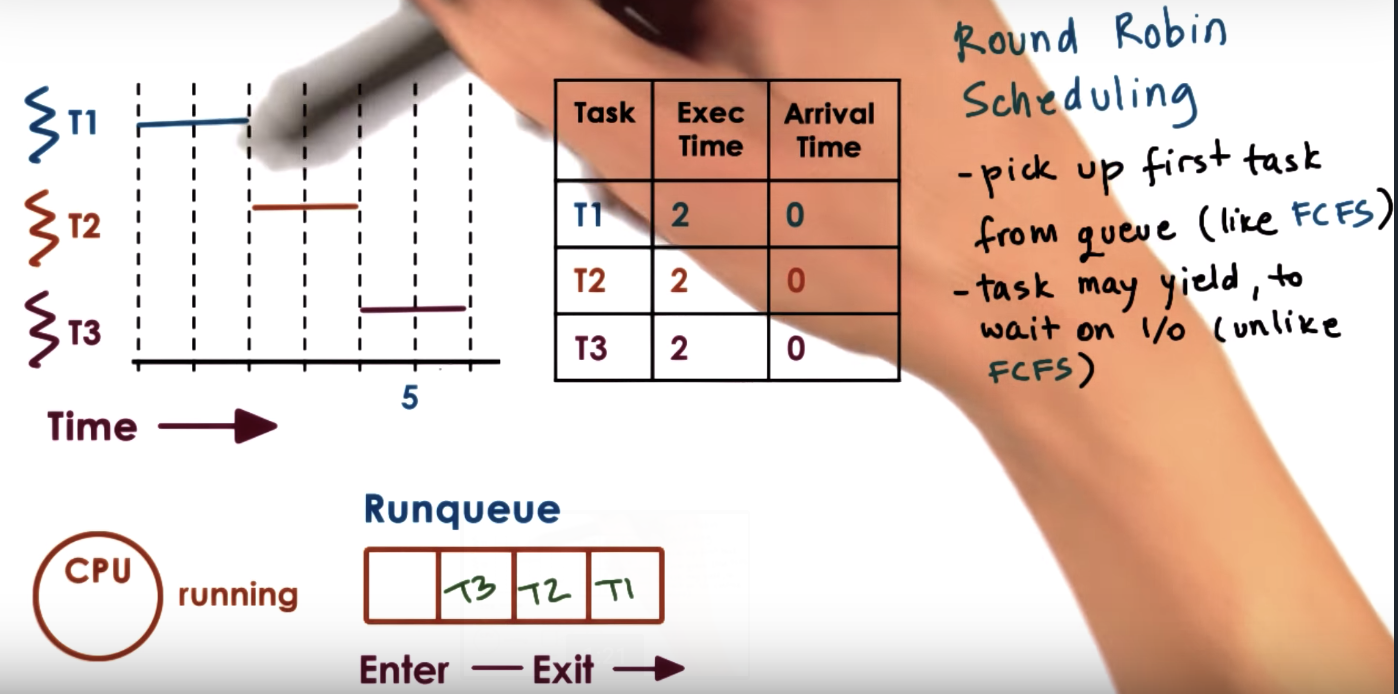
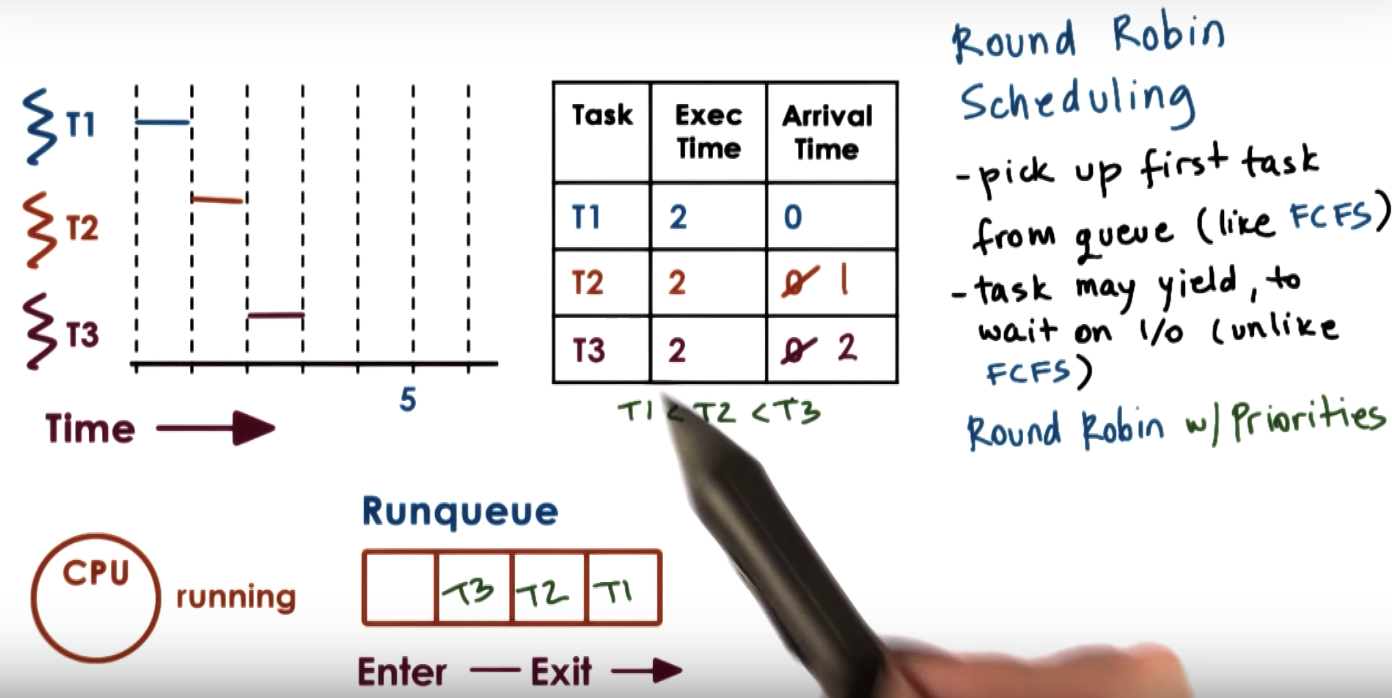
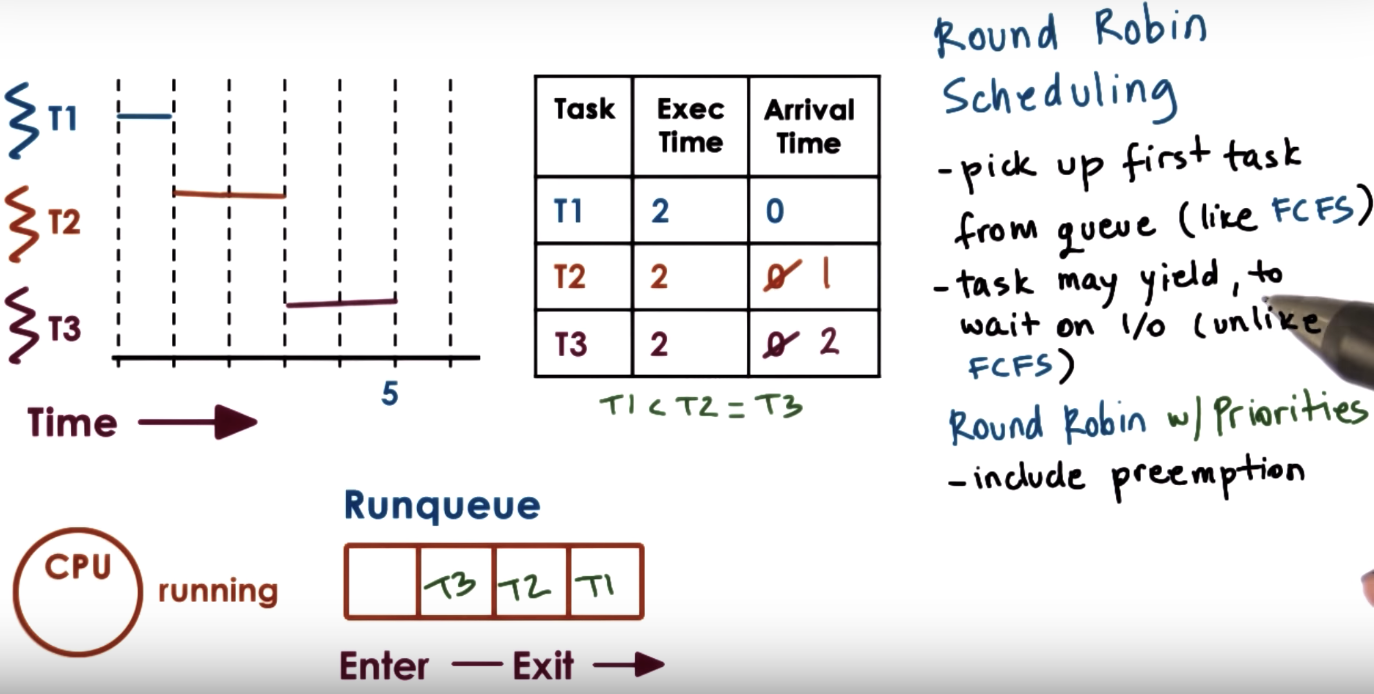
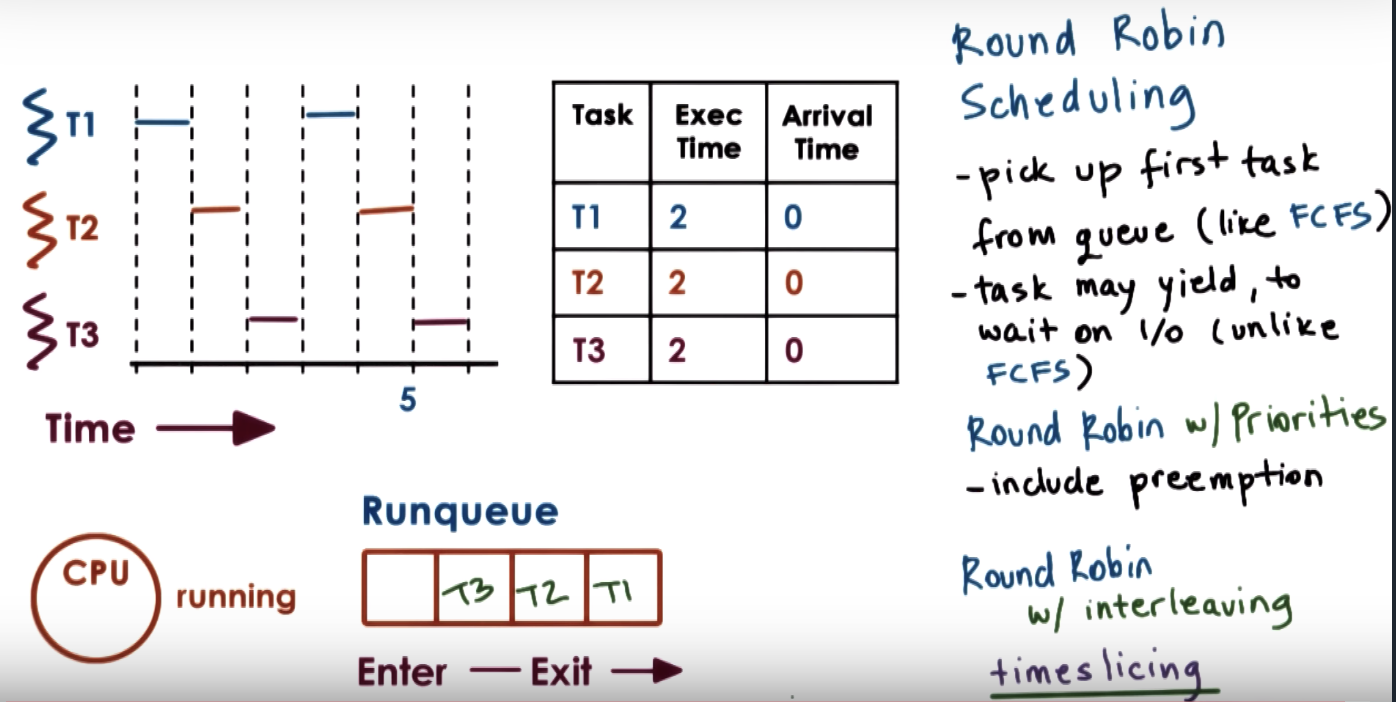
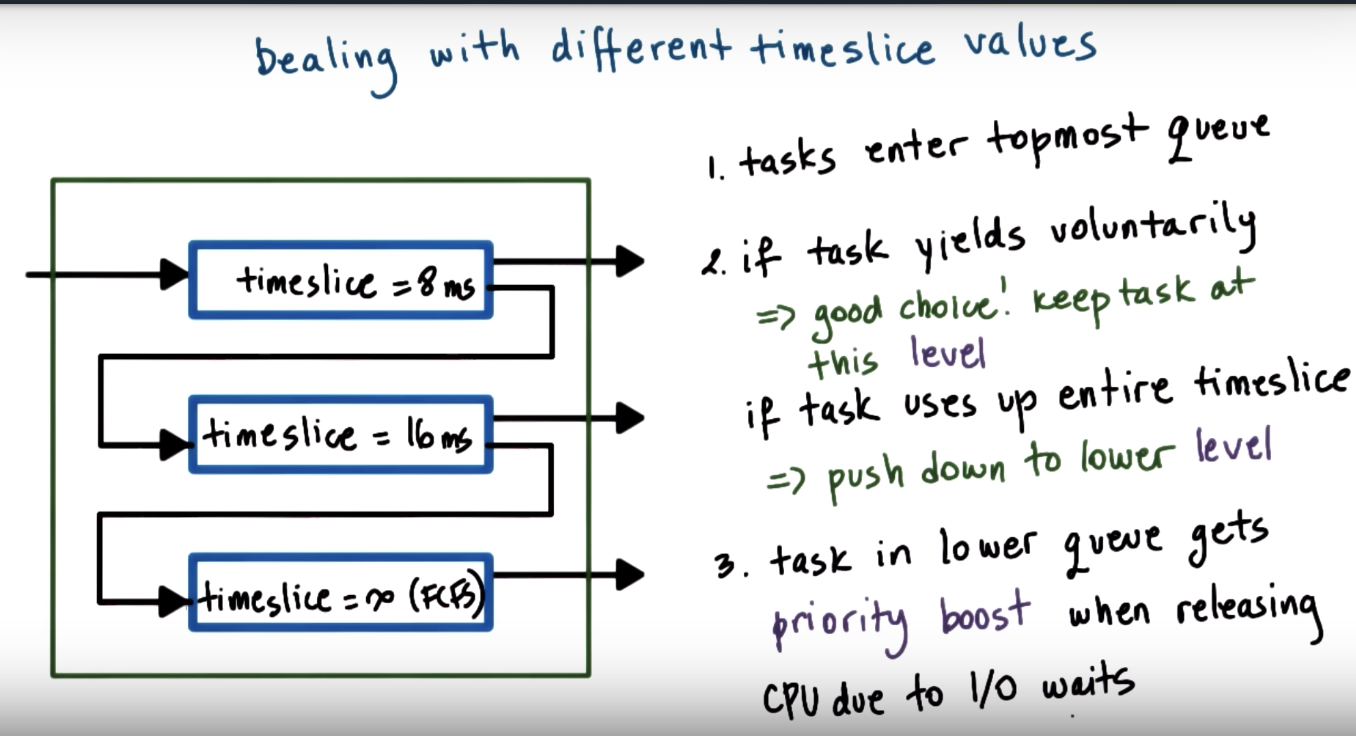
Timesharing and Timeslices

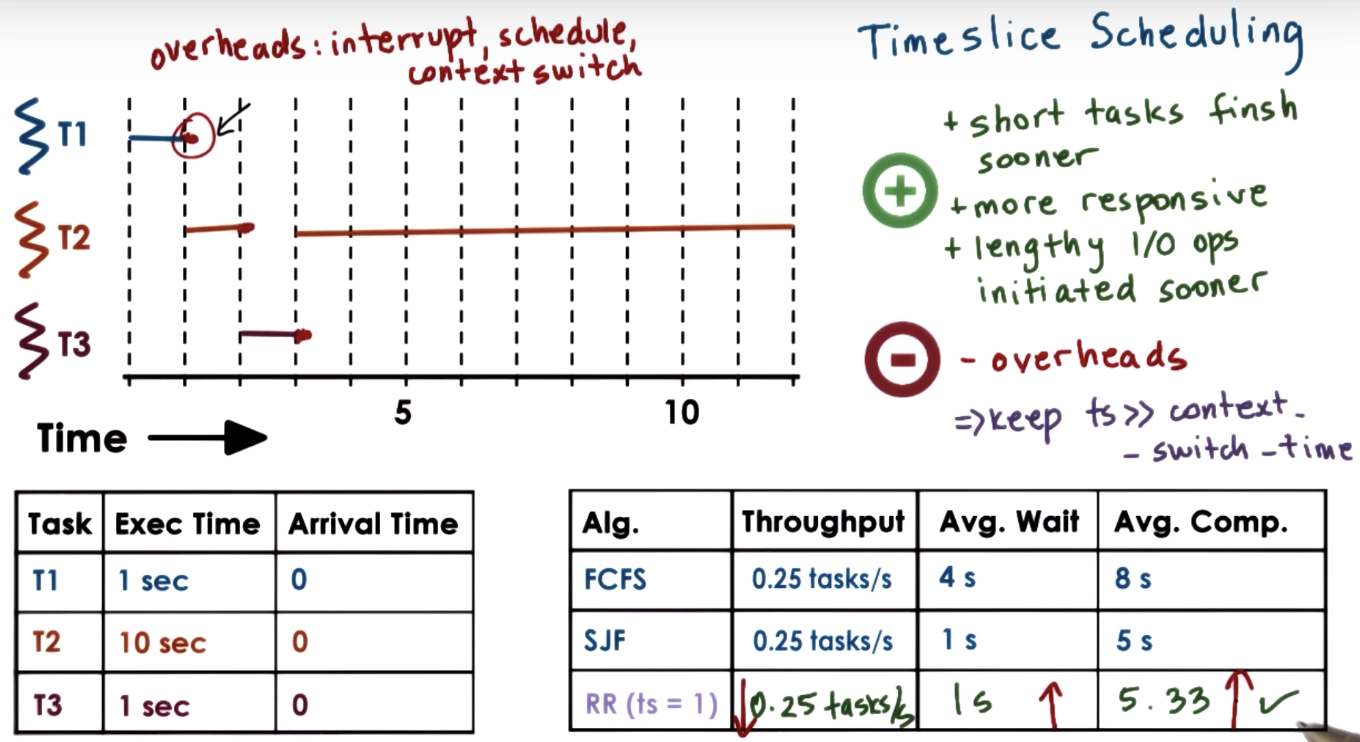
no prior knowledge about the completion time for tasks is needed.
How Long Should a Timeslice Be

CPU Bound Timeslice Length
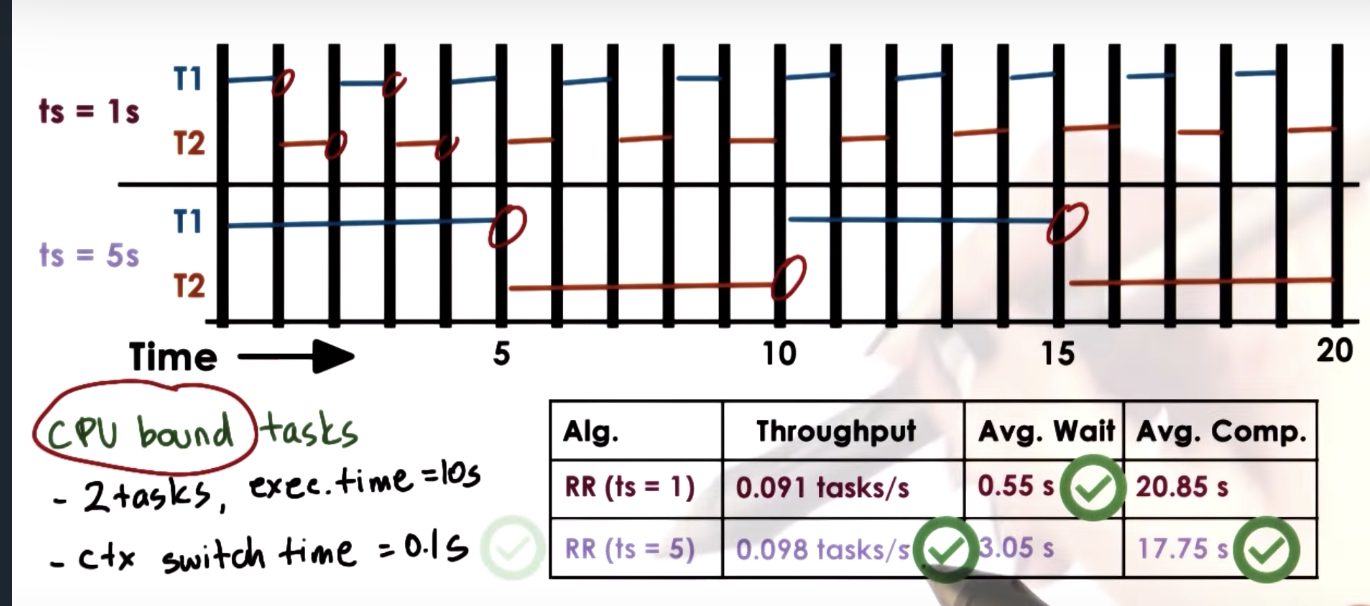
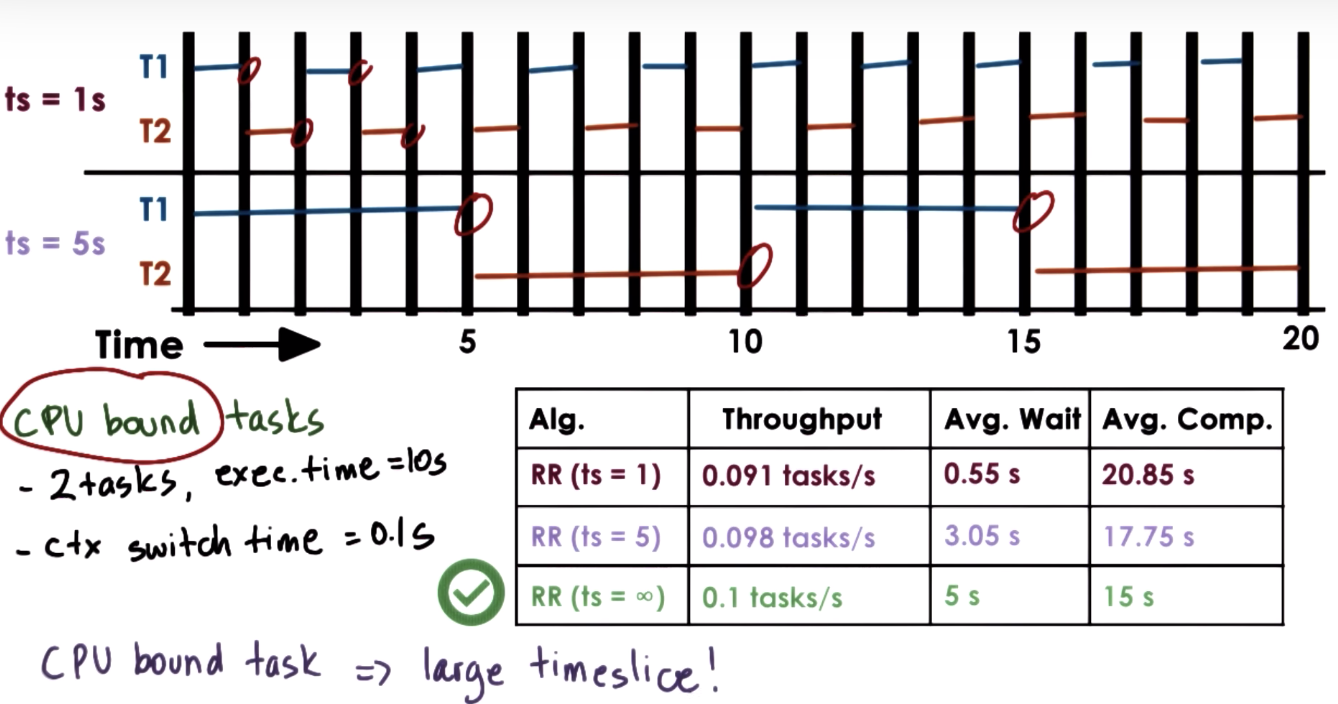
Full Calculations + ERRATA (for avg. wait time)
- Timeslice = 1 second
- throughput = 2 / (10 + 10 + 19*0.1) = 0.091 tasks/second
- avg. wait time = (0 + (1+0.1)) / 2 = 0.55 seconds
- avg. comp. time = 21.35 seconds
- Timeslice = 5 seconds
- throughput = 2 / (10 + 10 + 3*0.1) = 0.098 tasks/second
- avg. wait time = (0 + (5+0.1)) / 2 = 3.05 seconds
- avg. comp. time = 17.75 seconds
- Timeslice = ∞
- throughput = 2 / (10 + 10) = 0.1 tasks/second
- avg. wait time = (0 + (10)) / 2 = 5 seconds
- avg. comp. time = (10 + 20)/2 = 15 seconds
I/O Bound Timeslice Length
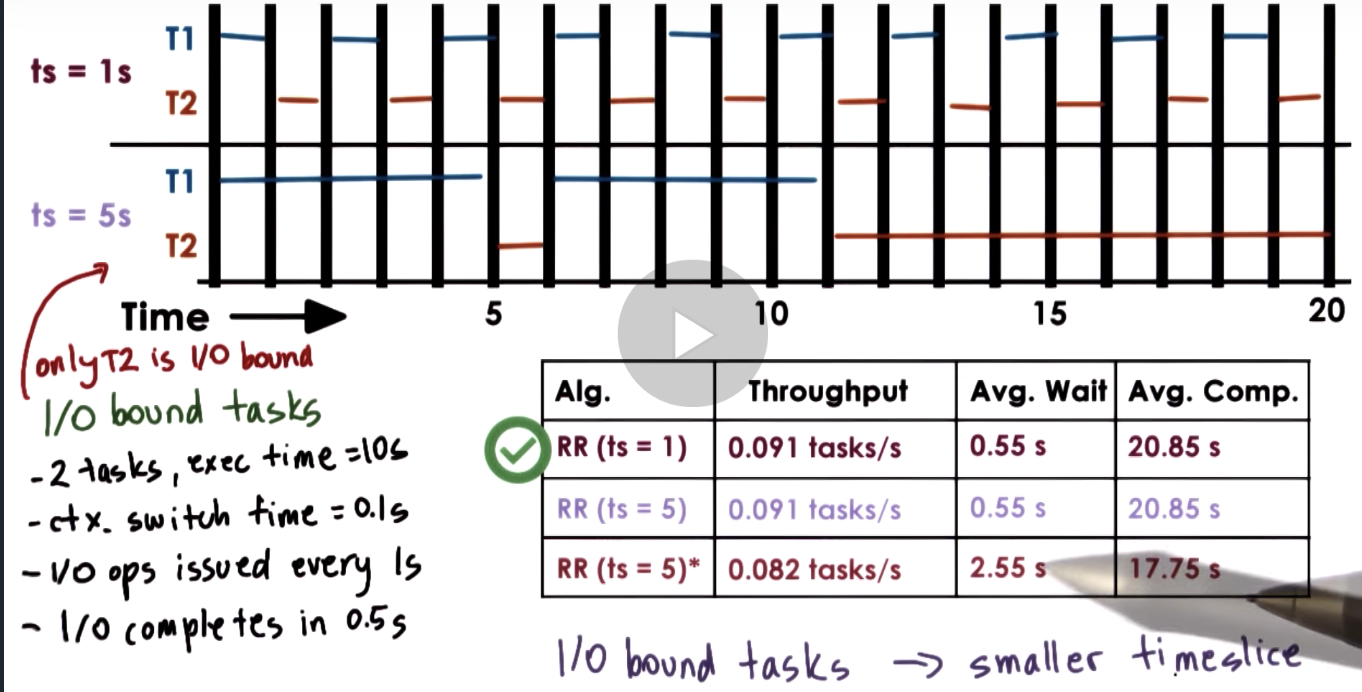
Full Calculation + ERRATA
- for Timeslice = 1sec
- avg. comp. time = (21.9 + 20.8) / 2 = 21.35
- Timeslice = 5 second*
- throughput = 2 / 24.3 = 0.082 tasks/second
- avg. wait time = 5.1 / 2 = 2.55 seconds
- avg. comp. time = (11.2 + 24.3) / 2 = 17.75 seconds
Summarizing Timeslice Length


![]()
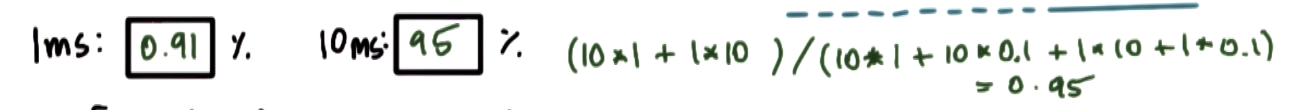
For the case when we have a round robin scheduler with a 10 ms timeslice, as we're going through the 10 I/O bound tasks,
every single one of them will run just for 1ms and then we will have to stop because of issuing an I/O request, so we'll have them context switch in that case.
From CPU utilization perspective, having a large timeslice that favors the CPU bound task is better.
Quiz Help
CPU Utilization Formula:
- [cpu_running_time / (cpu_running_time + context_switching_overheads)] * 100
- The cpu_running_time and context_switching_overheads should be calculated over a consistent, recurring interval
Helpful Steps to Solve:
- Determine a consistent, recurring interval
- In the interval, each task should be given an opportunity to run
- During that interval, how much time is spent computing? This is the cpu_running_time
- During that interval, how much time is spent context switching? This is the context_switching_overheads
- Calculate!
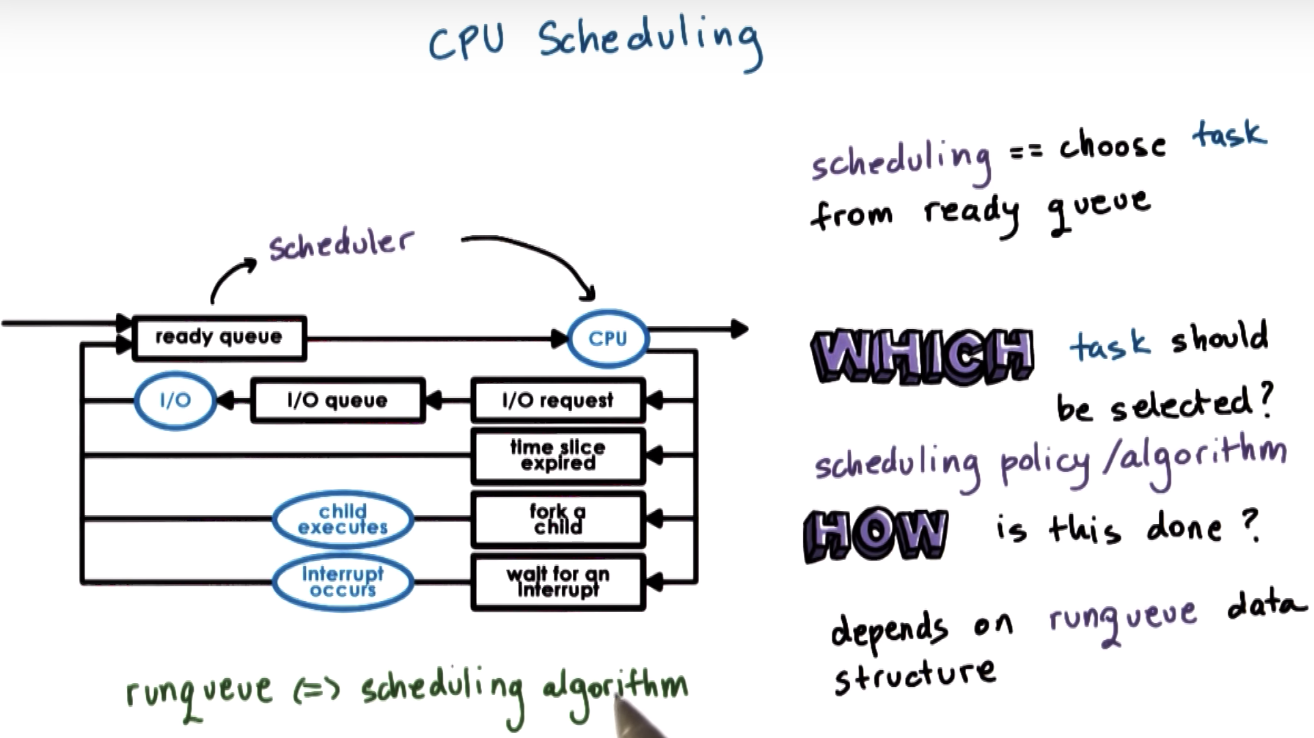
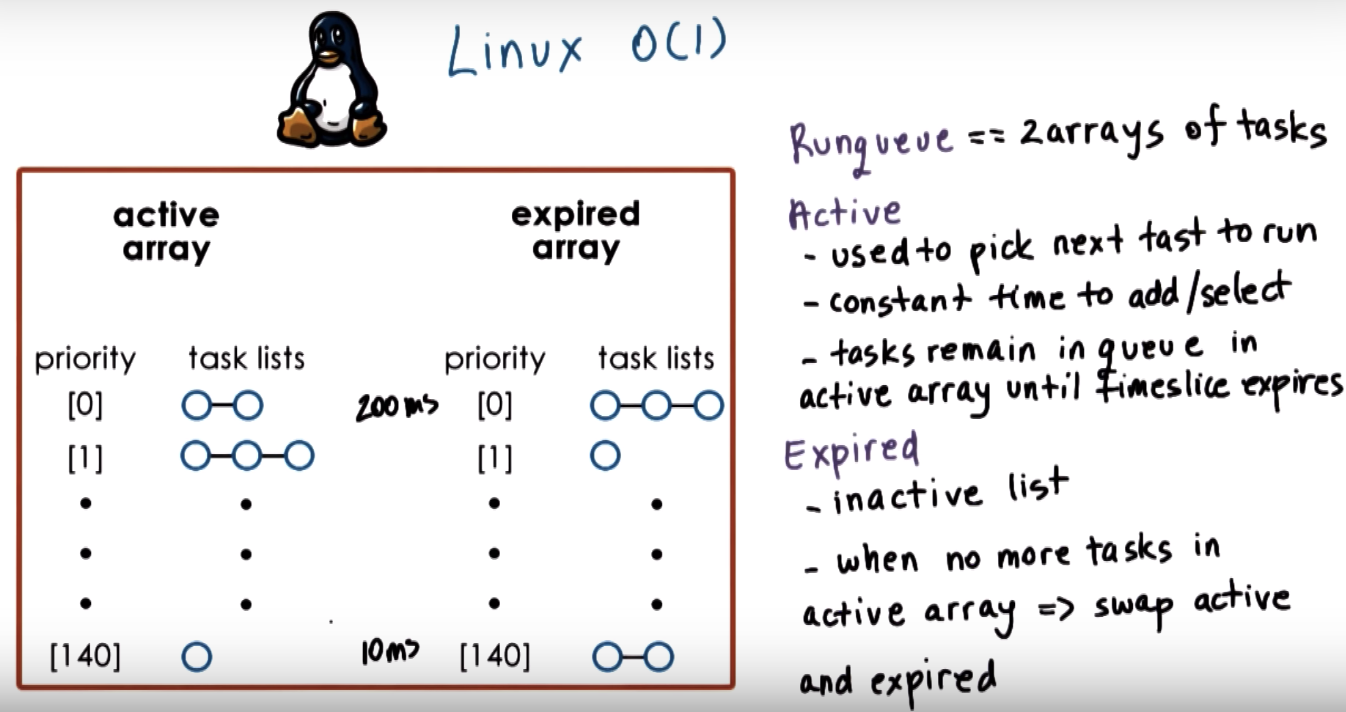
Runqueue Data Structure
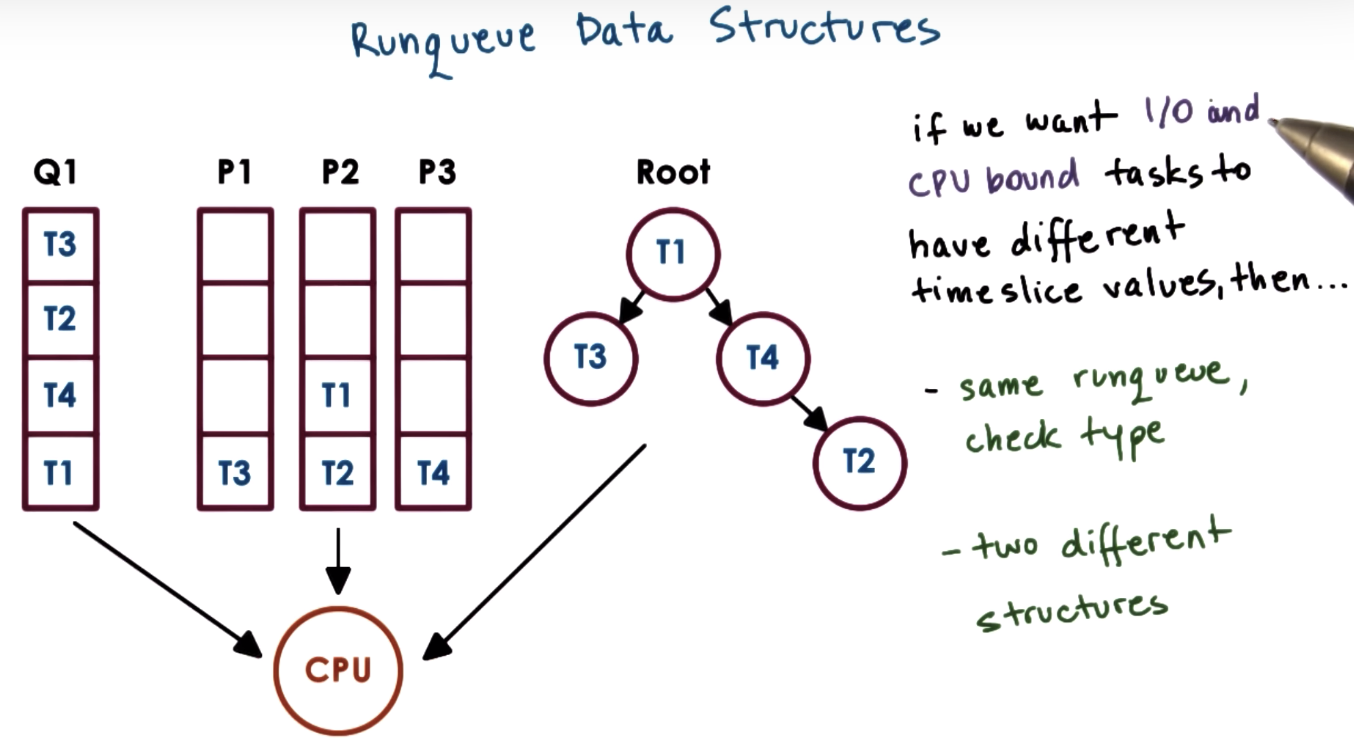
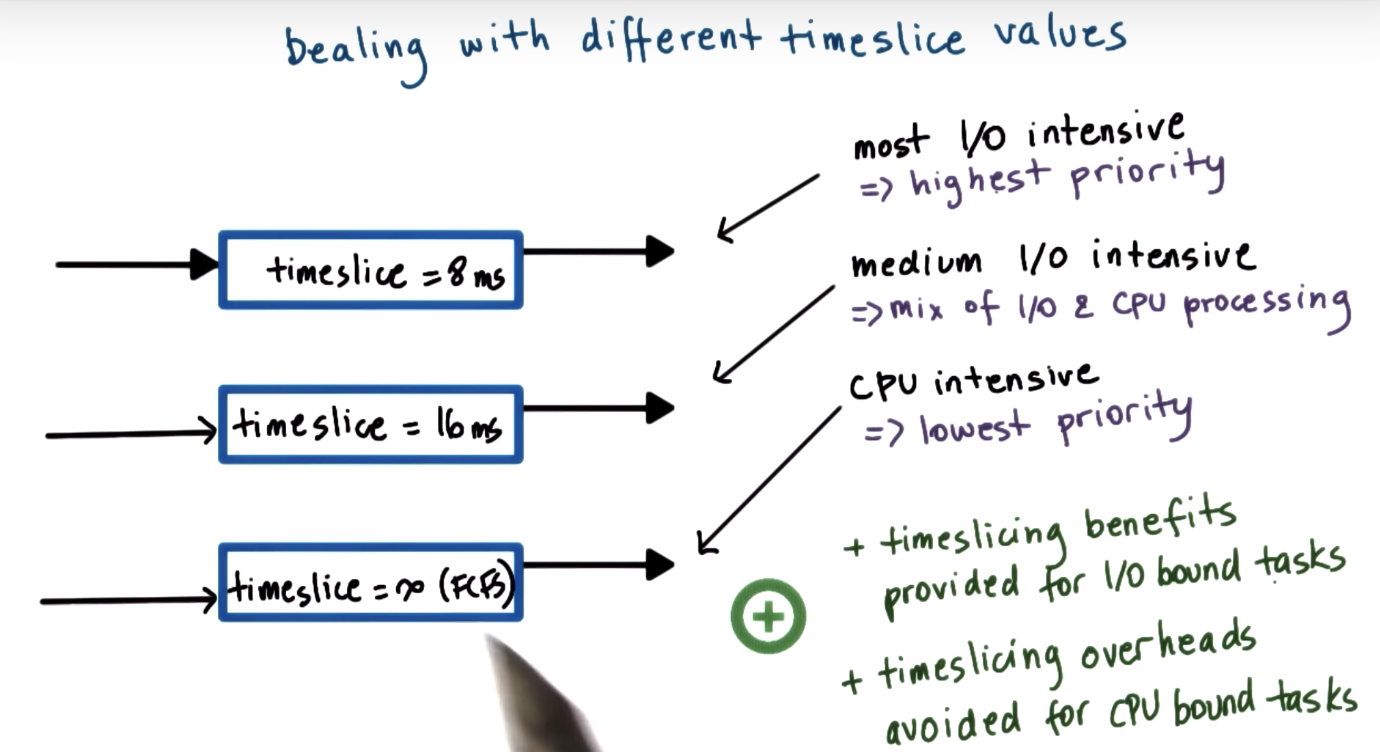

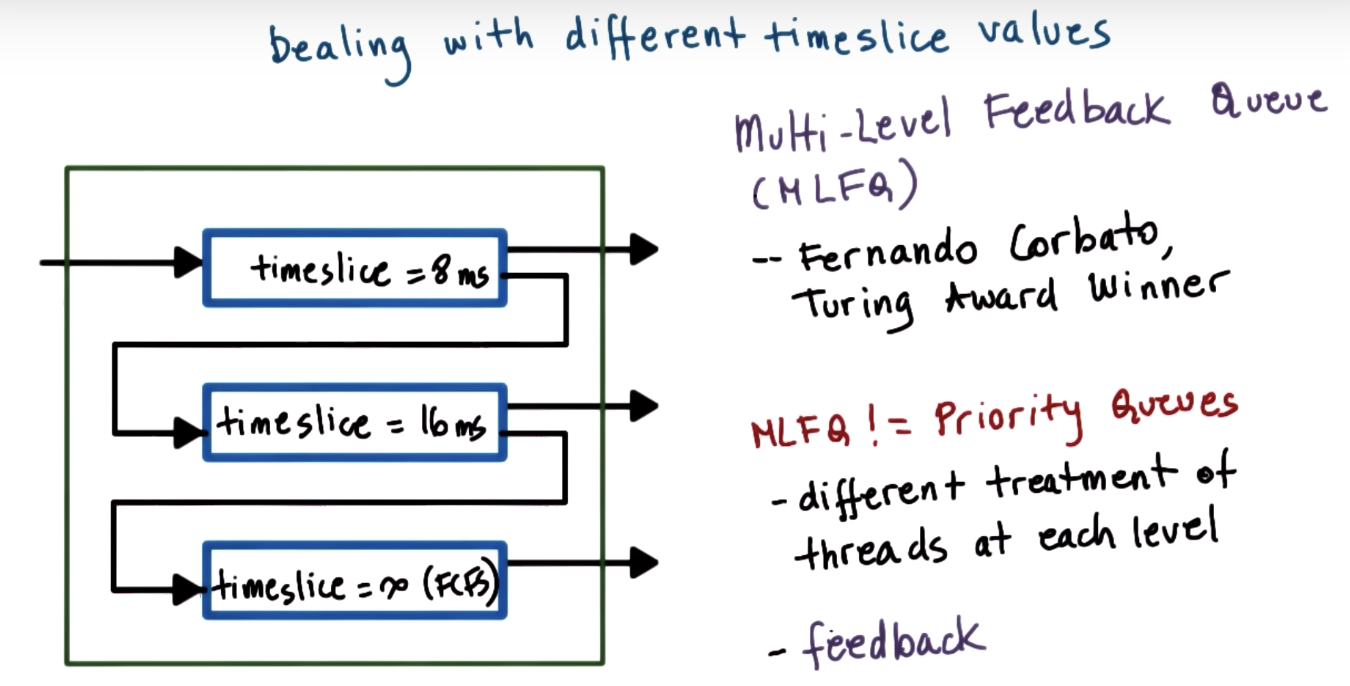
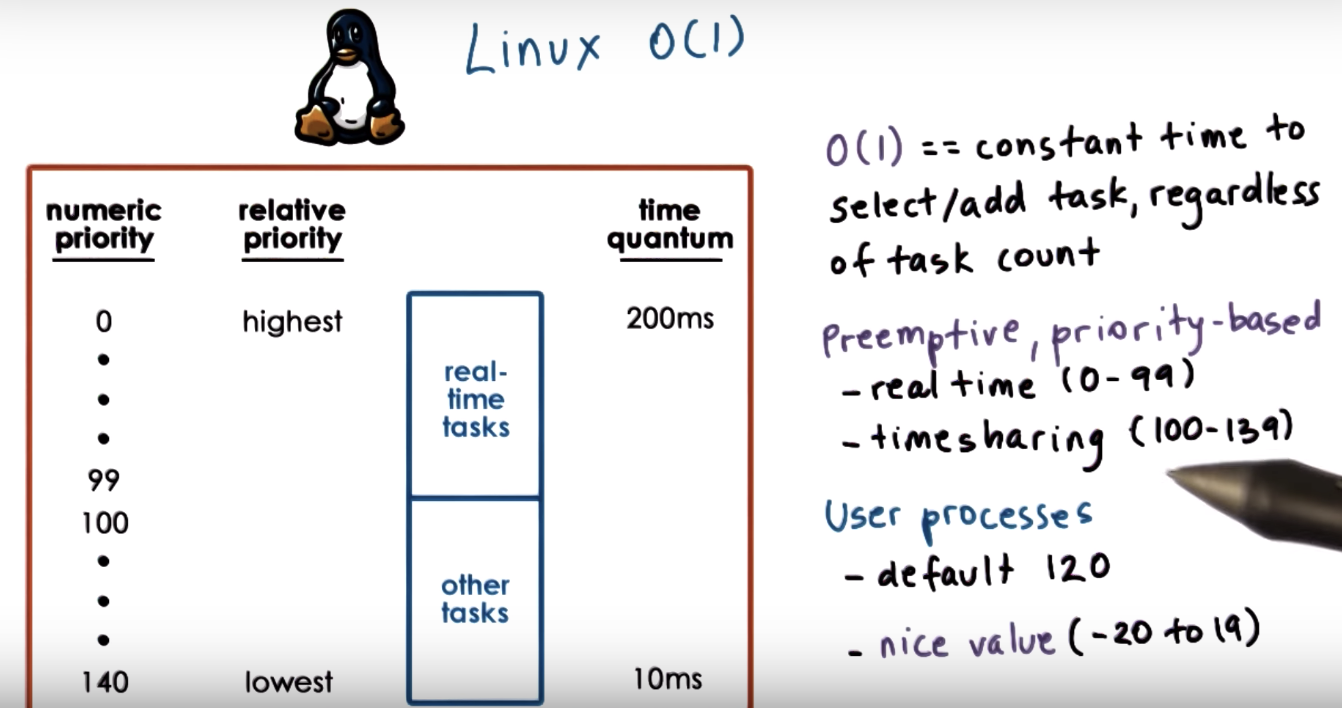
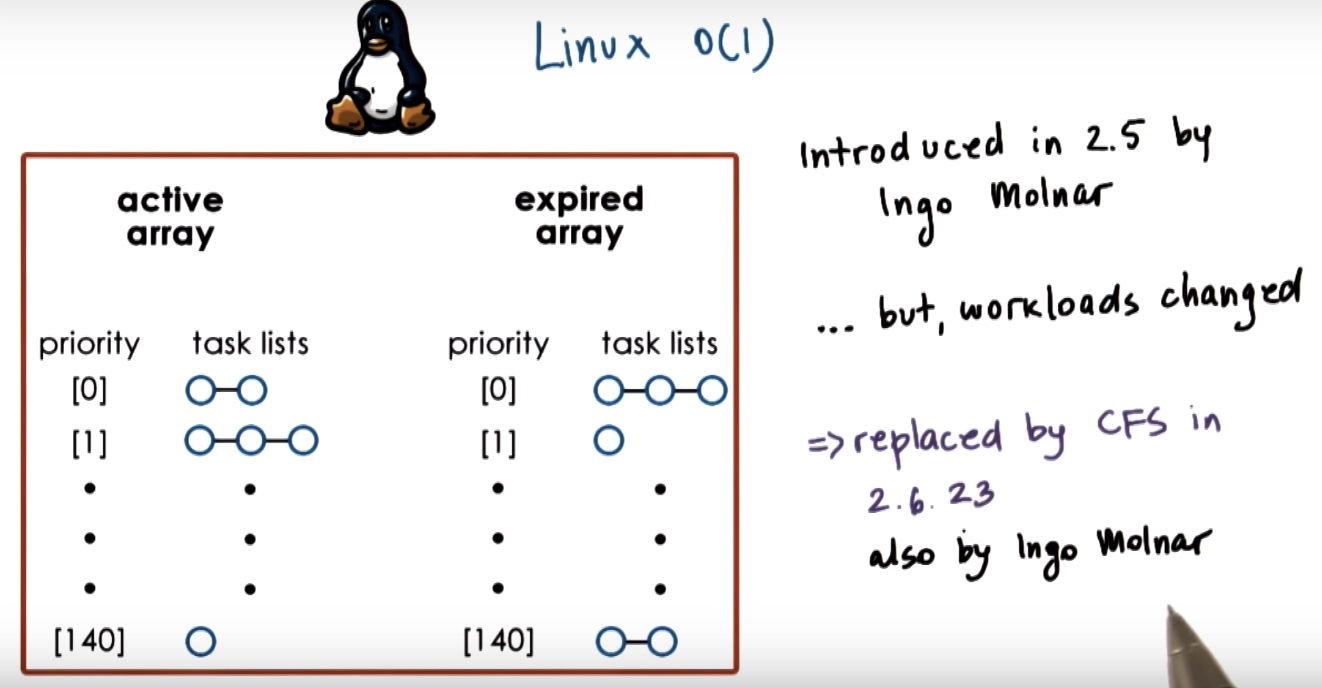
Linux O(1) Scheduler

cfs: Completely Fair Scheduler
Linux CFS Scheduler


CFS is the default scheduler for non-realtime tasks (=> so there's a realtime scheduler.)



If you need more information about the red-black tree data structure, then see this red-black tree explanation.

The first statement is not correct. Linux O(1) scheduler takes constant amount of time to select and schedule a task regardless of the load.
The second statement is sort of correct inthe sense that as long as there were continuously arriving higher priority tasks, it was possible for low priority tasks to keep waiting an unpredictable amount of time.
But this is not the main reason for O(1) scheduler to be replaced.
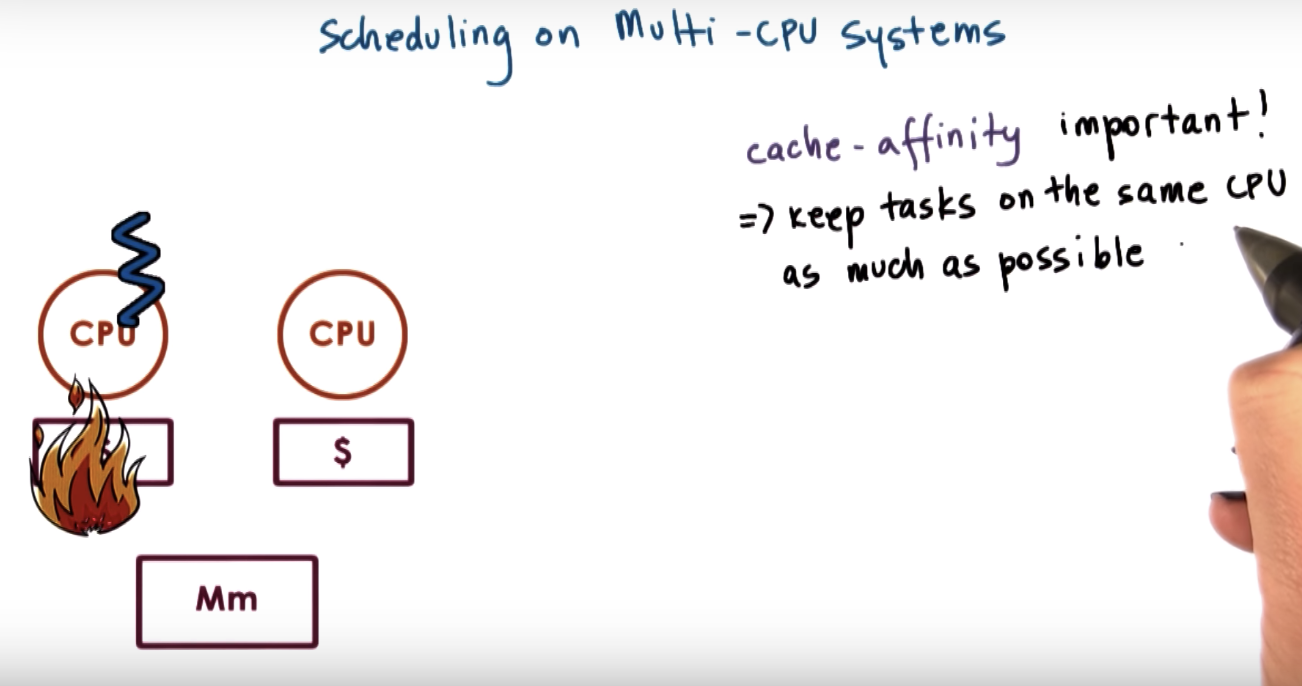
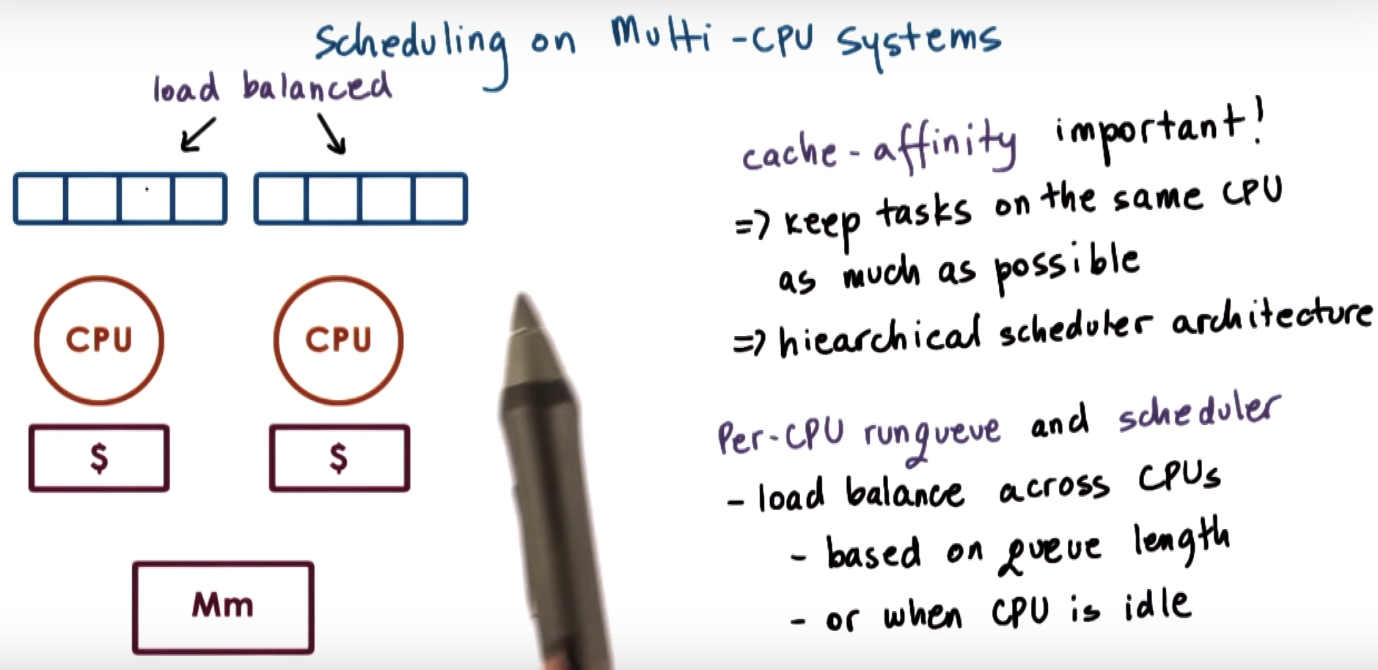
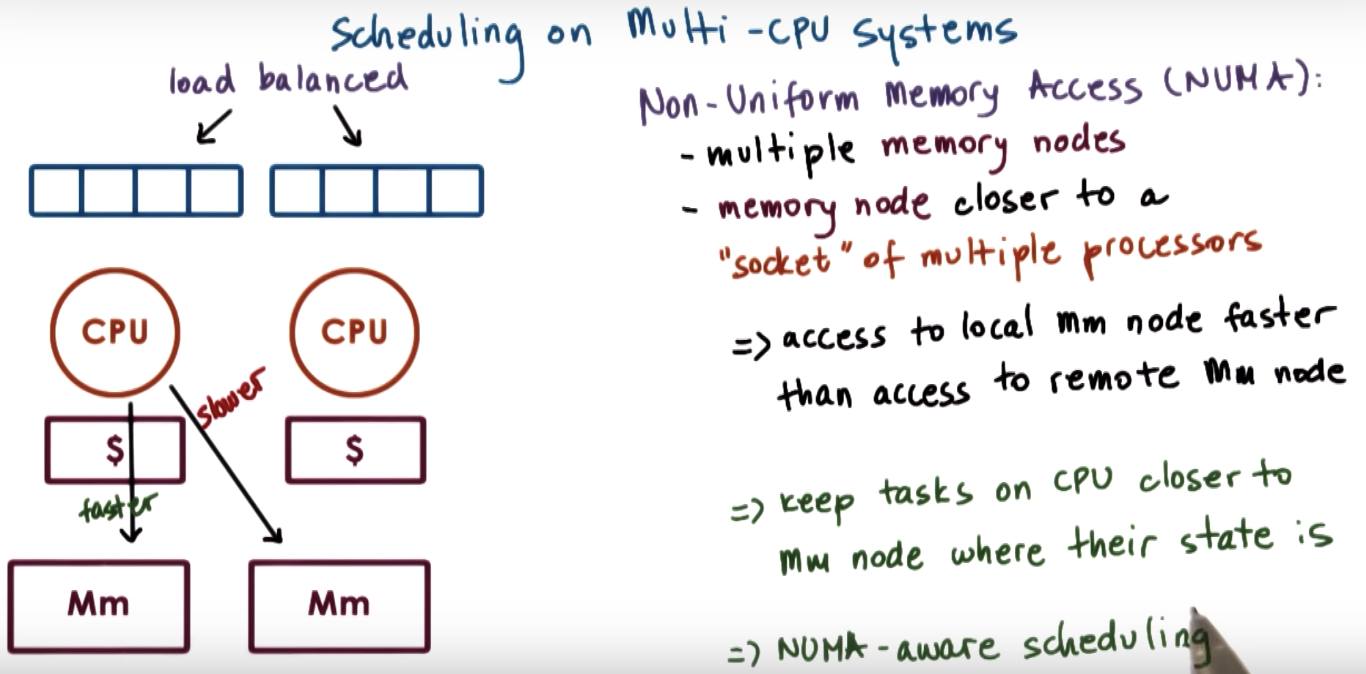
Scheduling on Multiprocessors

LLC: last level cache
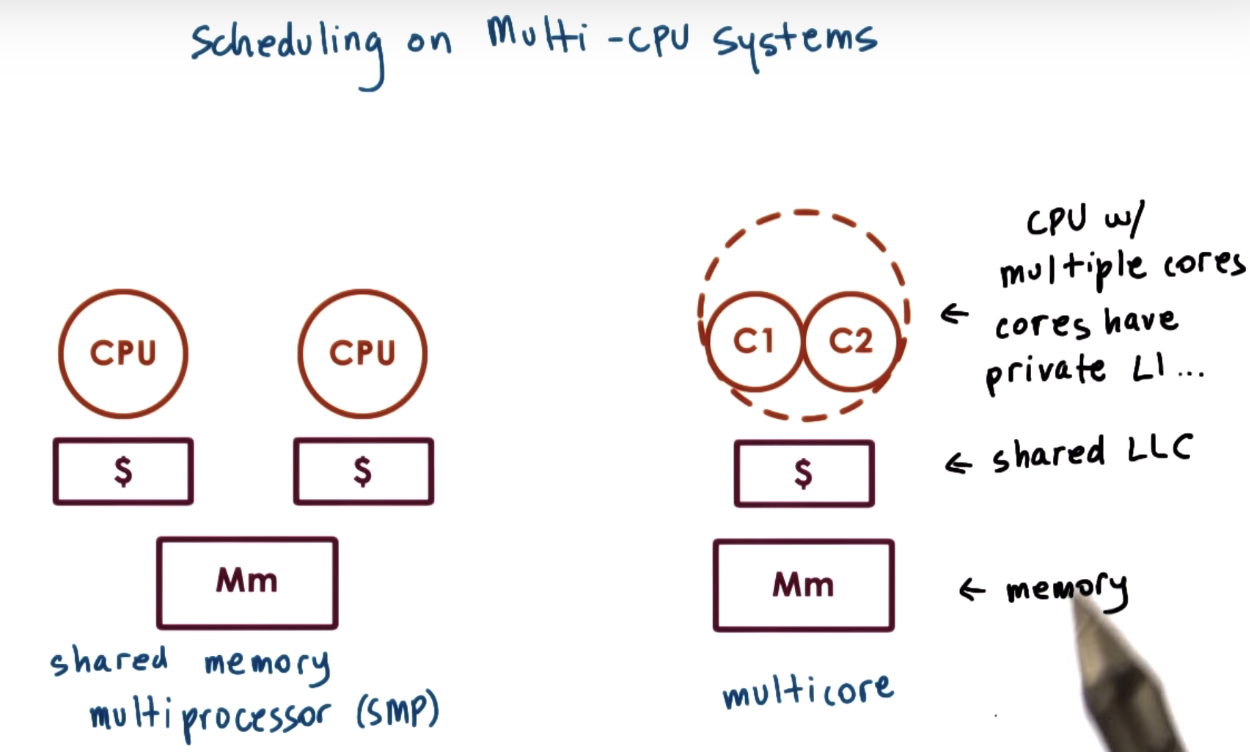
right one is more common on PC

Hyperthreading

other names of SMT in purple


- Fedorova, Alexandra, et. al.
"Chip Multithreading Systems Need a New Operating System Scheduler".
Proceedings of the 11th workshop on ACM SIGOPS European workshop (EW 11). ACM, New York, NY, 2004.
Scheduling for Hyperthreading Platforms
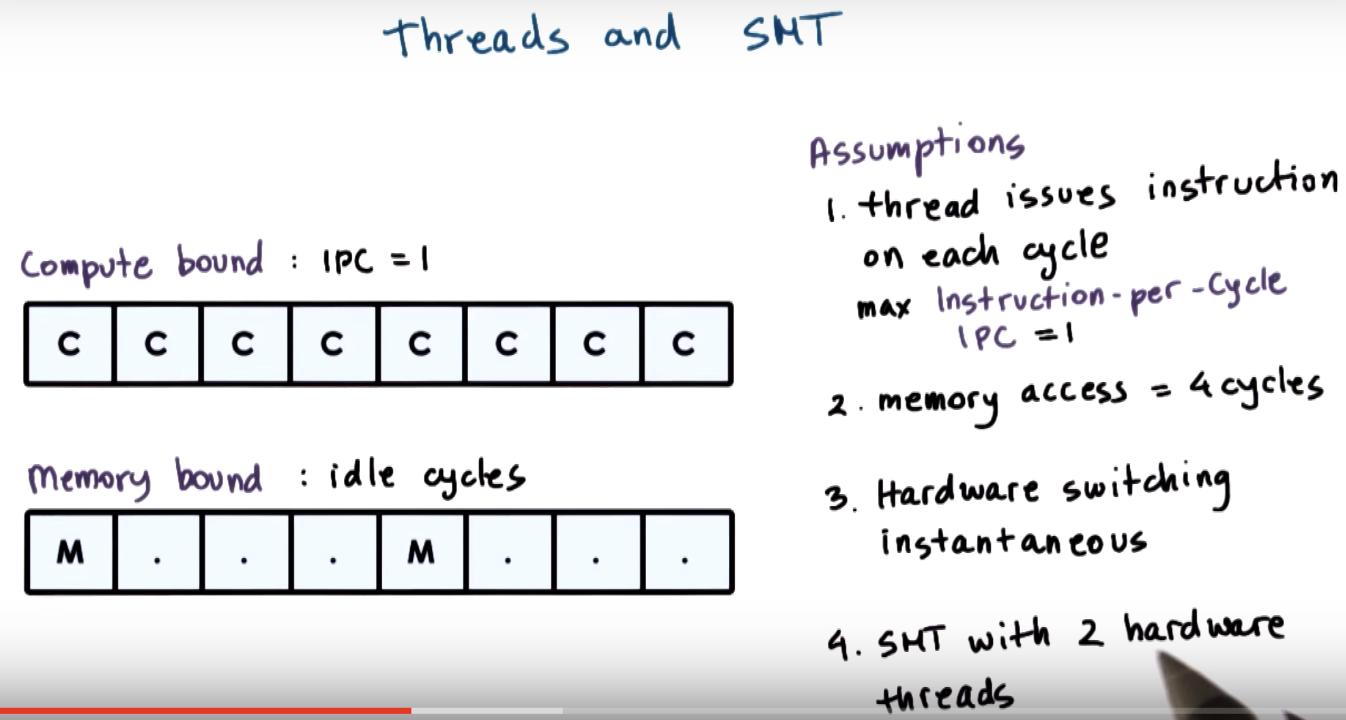
IPC: instructions per cycle
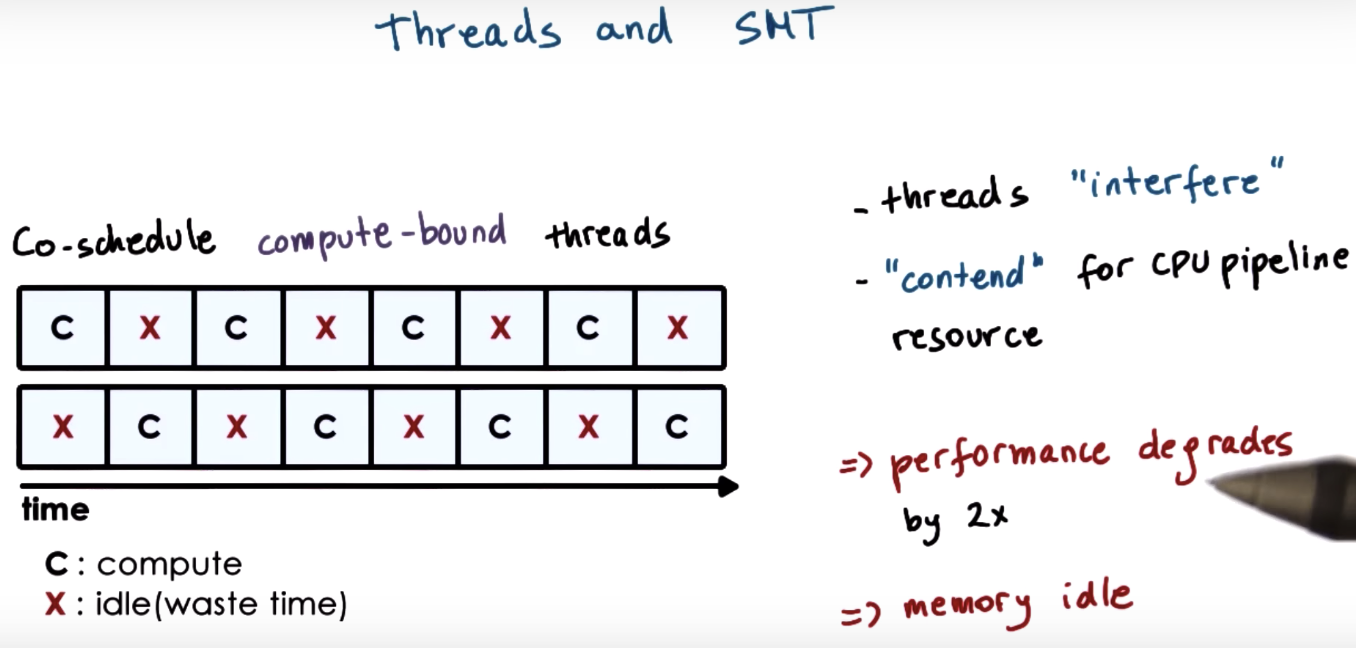
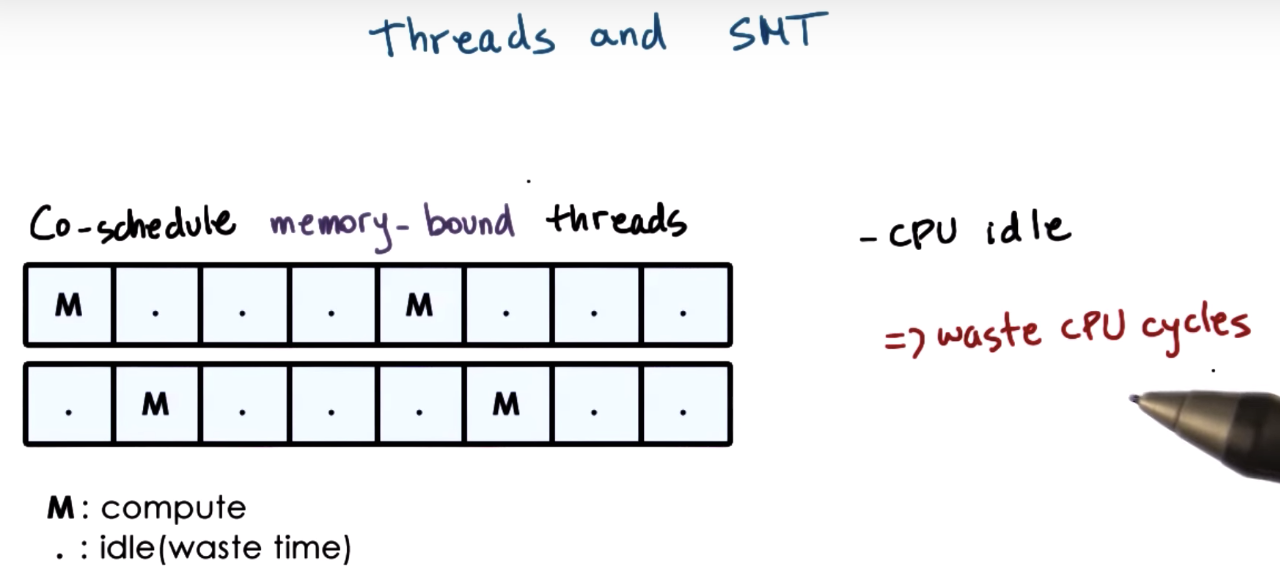
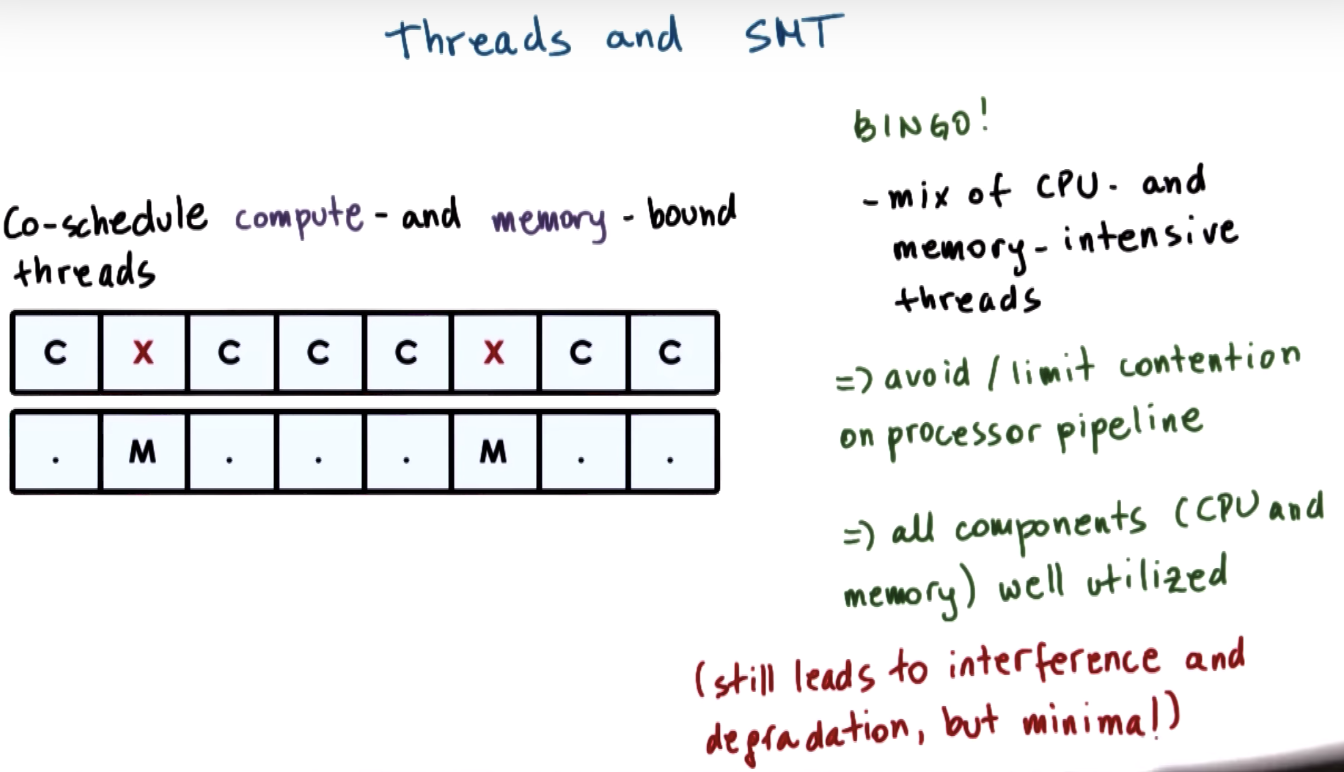
CPU Bound or Memory Bound

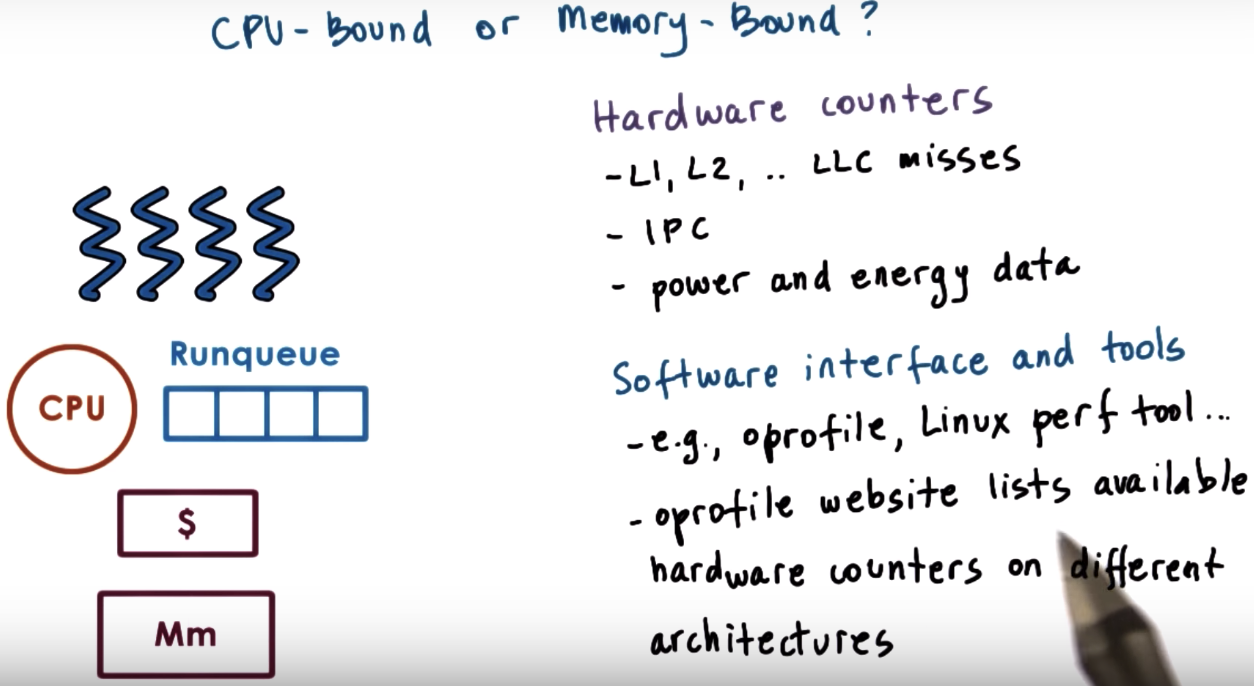

Scheduling with Hardware Counters


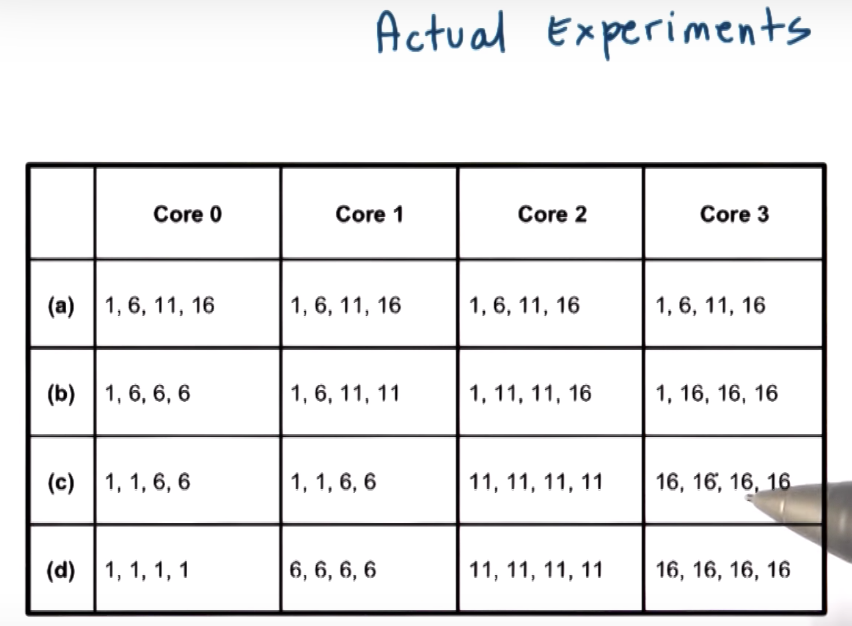
CPI Experiment Results
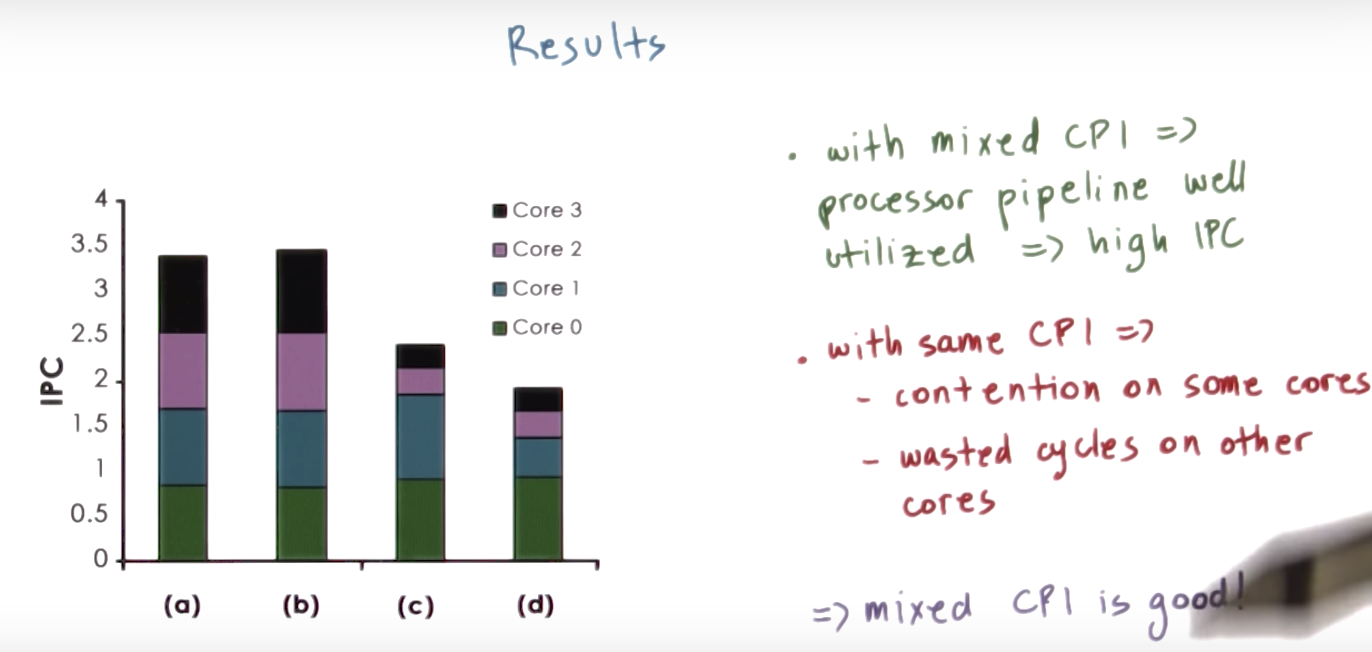
Quiz Help
For analyzing the graph, it might be helpful to use the full experiment chart.
Core 0
- (a) 1, 6, 11, 16
- (b) 1, 6, 6, 6
- (c) 1, 1, 6, 6
- (d) 1, 1, 1, 1
Core 1
- (a) 1, 6, 11, 16
- (b) 1, 6, 11, 11
- (c) 1, 1, 6, 6
- (d) 6, 6, 6, 6
Core 2
- (a) 1, 6, 11, 16
- (b) 1, 11, 11, 16
- (c) 11, 11, 11, 11
- (d) 11, 11, 11, 11
Core 3
- (a) 1, 6, 11, 16
- (b) 1, 16, 16, 16
- (c) 16, 16, 16, 16
- (d) 16, 16, 16, 16

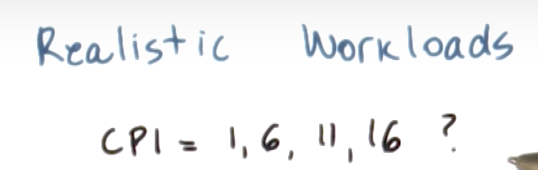



 浙公网安备 33010602011771号
浙公网安备 33010602011771号