02_Python爬蟲入門遇到的坑__反爬蟲策略02
02. 爬取亞馬遜的商品頁面:
獲取亞馬遜商品頁面的詳細信息: 杀死一只知更鸟(“塑造美国的88部图书”之一,普利策奖、奥斯卡金像奖获奖作品、影响全球5000万家庭的教养圣经,奥巴马、贝克汉姆、奥普拉鼎力推荐) (哈珀·李作品) Kindle电子书
這次我們有了經驗,直接一開始在一開始就加上headers屬性.
import requests # 需要爬取的商品頁面 url = "https://www.amazon.cn/dp/B06VSFXC4C" head = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36" } try: # 請求頁面 r = requests.get(url, headers=head) # 判斷狀態碼, 如果連接狀態不正確, 會自動拋出異常 r.raise_for_status() # 使用備用編碼集 r.encoding = r.apparent_encoding # 查看獲取的源碼 print(r.text) except: # 爬取失敗 print("頁面獲取失敗")
然後你會在輸出結果中看見這麼一段:
<p class="a-last">抱歉,我们只是想确认一下当前访问者并非自动程序。为了达到最佳效果,请确保您浏览器上的 Cookie 已启用。</p>
不要認為有輸出就已經正確了,事實上這句話的意思是你依舊被判定為一個機器人,你需要加上cookies屬性才能正常訪問,所以將代碼修改為如下結果:
import requests # 需要爬取的商品頁面 url = "https://www.amazon.cn/dp/B06VSFXC4C" head = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.149 Safari/537.36", "cookie": '請依據自己的實際情況修改,獲取cookie方法下一步會講解!', } try: # 請求頁面 r = requests.get(url, headers=head) # 判斷狀態碼, 如果連接狀態不正確, 會自動拋出異常 r.raise_for_status() # 使用備用編碼集 r.encoding = r.apparent_encoding # 查看獲取的源碼 # print(r.text) with open("amazon.html", mode="wb") as f: f.write(r.content) f.close() print("成功!") except: # 爬取失敗 print("頁面獲取失敗")
這時候便能獲取到正確的網頁信息.
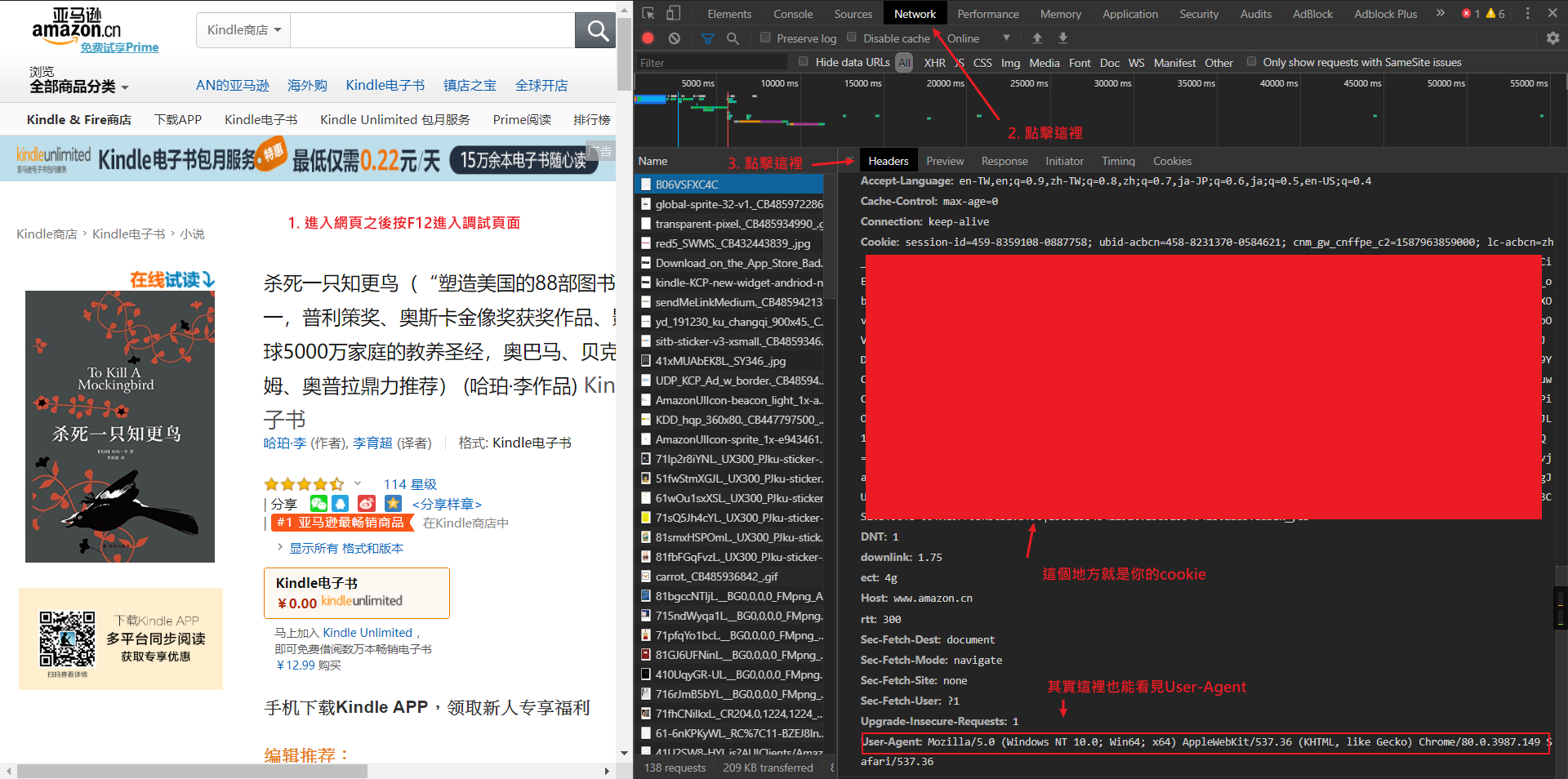
如果獲取自己的cookie:
0. 登錄自己的賬號并進入相關的頁面
1. 按F12進入調試頁面
2. 點擊Network查看詳細信息
3. 在headers中查看自己提交的信息
4. 複製自己的cookie到代碼之中
總結:在必要的時候我們需要加上cookie訪問

 浙公网安备 33010602011771号
浙公网安备 33010602011771号