
react无效渲染优化--工具篇

壹 ❀ 引
本文属于我在公司的一篇技术分享文章,它在我之前 React性能优化,六个小技巧教你减少组件无效渲染一文的基础上进行了拓展,增加了工具篇以及部分更详细的解释,所以内容上会存在部分重复,以下是分享的原文。
在过去一段时间,好像每次代码走读大家都对于useMemo、useCallback以及memo的使用都会存在部分疑惑,比较巧的是这几个API都与性能优化相挂钩;可以想象性能优化这一块一定会属于未来前端团队挑战之一,所以掌握部分优化技巧是很有必要的。那么这一次我想聚焦在react组件渲染优化上,为大家分享无效渲染常见排查手段以及避坑经验,通过本文大家将收获如下几个知识点:
- 造成无效渲染的主要原因
- 五种减少无效渲染的小技巧
- 三种无效渲染排查手段
- 聊聊
useMemo、memo、useCallback,什么时候该用什么时候不该用? useSelector每次都会执行吗?聊聊store更新机制- 常见缓存策略以及缓存利弊(缓存都有代价)
- 如何在项目中发现无效渲染严重的组件
贰 ❀ 理解无效渲染
其实在之前我一直在强调我们需要减少的是无效渲染,而不是渲染;对于一个组件而言,状态如果发生了改变,组件自身再次渲染这非常合理,但如何组件状态或数据未改变,那此刻的渲染就是无效渲染。
回归到无效渲染,我将无效渲染的原因分为两类:
- 组件状态设计藕合,组件之间相互响应
- 组件
prop不稳定
关于第一点不难理解,比如现在需要开发一个相对复杂的功能,这个功能包含A B C三个子功能,正常来说我应该为三个功能定义三个组件,以及对应的三个状态,但假设有同学就是让这三个组件共用了一个状态,那此刻不管你动了谁,另外两个组件都得跟着渲染。
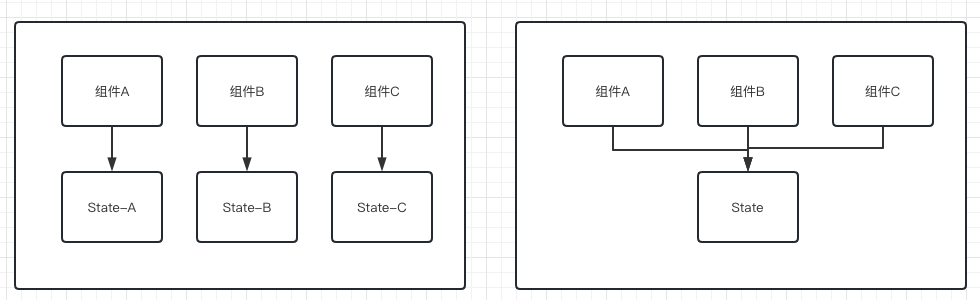
这类问题其实不仅存在state定义上,对于store的接口封装同样会有相同的问题,比如公司项目里存在如下类似的代码:

我之前疑惑,为什么这里不是直接一句useSelector取出user对象,然后直接解构出五个属性,而不是要写五遍useSelector一个一个的取。在沟通后了解到,这么做就是为了避免其它地方的组件改动了user里的某个属性,而这里直接取user的话因为引用一定会变从而导致重新渲染,所以单点取的好处就是你外面改了这里五个属性之外的其它属性,我这里因为没用到,所以就不会重新渲染。
回到user的数据设计上,如果user的数据结构包含万物,它能被使用的组件越多,那么它被影响的可能性自然就越大,所以尽可能保证数据设计的简洁以及合理性很有必要。
造成无效渲染的第二大原因就是引用数据类型引用不稳定所导致,举个最简单的例子,组件A渲染前后都接受了一个空数组,且两次数组的引用都不同,这对于组件而言因为引用不同所以是新数据自然得再次渲染,但对于研发而言,我们心里其实是知道这是无意义的,所以如何保证其引用的稳定性就是解决无效渲染的核心了。
说到这里有同学可能就会想,那是不是组件内只要产生新引用数据的行为就不对呢?其实并不是,当数据本身就应该更新时,它在这一刻产生一个全新的引用很合情合理,不然我们项目里什么filter、map之类的岂不是都用不了了。你也可以想想react自身的setState更新,我们更新state时本身也是得传入一个全新的对象而不是直接修改,所以要更新时产生新对象非常合理。
const App = () => {
const [state, setState] = useState({ name: "听风", age: 29 });
const handleClick = () => {
// 错误做法,直接修改 state, 不会更新
// state.name = '行星飞行';
// 正确做法就得重新赋予一个全新的对象,不然 state 不会更新
setState({ ...state, name: '行星飞行' });
}
return (
<div>
<div>{state.name}</div>
<div>{state.age}</div>
<button onClick={handleClick}>change name</button>
</div>
)
};
叁 ❀ 如何减少无效渲染
叁 ❀ 合理使用memo
我们知道class组件的PureComponent以及函数组件的memo都具有浅比较的作用,所谓浅比较就是直接比较前后两份数据是否相等,比如:
const a = [];
const b = a;
// 因为 a b 引用和值都相同,所以相等
a === b; // true
const c = [];
// 虽然 c 也是空数组,但是引用不同所以不相等
a === c; // false
那么加memo到底解决了什么问题?我们假设组件前后都接收了一个空数组,且它们引用也相同,那么此时如果我们组件套用了memo,那么组件就不会因为这个完全相同的数据重复渲染。这里我写了一个在线的memo例子方便大家理解效果,大家可以点击按钮查看控制台,直接对比加与不加memo的差异。
在这个例子中,我在组件外层定义了一份引用始终相同的数据user,之后通过点击按钮故意改变父组件P的状态让其渲染,以此带动子组件C1 C2渲染,可见加了memo的C2除了初次渲染之后并不会跟随父组件重复渲染,这就是memo的作用。
当然,假设我们的user每次都是重新创建的新对象,那我们加了memo也没任何作用,毕竟引用不同浅比较判断为false,还是会重复渲染。
另外,请合理使用memo,并不是所有场景都需要这么做,这会增加内存开销,假设你的组件的数据流足够简单甚至没有props,你完全没必要在组件外层套一层memo。
那么接下来的建议,也都是基于子组件加了memo展开的,不然你即便保证父组件每一个数据引用都不变,父组件渲染时子组件还是一样会渲染(默认行为)。
叁 ❀ 贰 不稳定的默认值
正常来说,比如子组件的userList属性规定类型是数组,而在父组件加工数据时提供默认值是非常好的习惯,大家可能经常看到这样的写法:
const App = (props) => {
// 假定userList是接口提供,接口没回来取不到
const userList = props.userList || [];
return (
<Child userList={userList} />
)
};
那这就造成一个问题,当接口没响应完成,只要App发生渲染,此刻userList都会不断被重新赋值空数组,对于Child而言,因为每次引用不同,自然Child也都要跟着渲染,所以正确的做法是将默认值提到组件外:
const emptyArr = [];
const App = (props) => {
const userList = props.userList || emptyArr;
return (
<Child userList={userList} />
)
};
叁 ❀ 叁 props直接传递新对象
这一种也是最直接也最容易看出来的一种不规范写法,一般存在于对于react不太了解的新人或者一些老旧代码中,比如:
const App = () => {
return (
// 这里每次都会传递一个新的空数组过去,导致Child每次都会渲染,加了 memo 都救不了
<Child userList={[]} />
)
};
当然,它也可能不是一个空数组,但注定每次都是一个全新引用的数据:
const App = (props) => {
return (
<Child style={{color : red}} />
)
};
再或者使用了产生新数组的方法,比如:
const App = (props) => {
const getUserList = ()=>{
return props.userlist.map((e) => e.name)
}
return (
<Child userList={getUserList()} />
)
};
叁 ❀ 肆 合理使用useMemo与useCallback
我们知道useMemo与useCallback都能起到缓存的作用,比如下面这个例子:
// 只要 App 自身重复渲染,此时 handleClick 与 user 都会重新创建,导致引用不同,所以 C 即便加了 memo 还是会重复渲染
const App = (props)=> {
const handleClick = () => {};
const fn = () => {}
const list = [];
const user = userList.filter();
return <C onClick={handleClick} list={list} user={user} />
}
只要组件App自身重复渲染,组件内的这些属性方法本质上会被重新创建一遍,这就导致子组件C即便添加memo也无济于事,所以对于函数组件而言,一般要往下传递的数据我们可以通过useMemo与useCallback包裹,保证其引用稳定性。当然,如果一份数据只是App组件自己用,那就没必要特意包裹了:
// 常量提到外层,保证引用唯一
const list = [];
const App = ()=> {
// 使用 useCallback 缓存函数
const handleClick = useCallback(() => {});
// 只是自己使用,不作为props传递时,没必要使用 useCallback 嵌套
const handleOther = () => {}
// 使用 useMemo 缓存结果
const user = useMemo(()=>{
return userList.filter();
},[userList])
return <C onClick={handleClick} list={list} user={user} />
}
比如上述代码中的handleOther就是组件自身用,它不作为props往下层传递,那就根本没必要给这个函数做缓存。
另外问大家一个问题,不管是 useCallback 还是 ahooks 的 useMemoizedFn ,假设有下面这段代码:
const add = (a,b) => a + b;
const add_ = useMemoizedFn(add);
// 或者
// const add_ = useCallback(add, []);
add_(1,2);
add_(1,2);
请问第二次执行 add_ 时, a + b 这段逻辑会走吗?
会,因为useCallback 缓存的是函数本身,它不会帮你缓存函数的结果,它的作用就是帮你保证函数引用不变,仅此而已。
总结来说,useMemo、useCallback这些与memo一定一定是配合使用的,如果下层组件加了memo,那么你上层组件就应该尽可能保证作为props数据引用的稳定性;如果上层组件加了useCallback,那么你的子组件就一定得配合的加memo,不然函数缓存啥的其实都白加了。
叁 ❀ 伍 更稳定的useSelector
我们可以使用useSelector监听全局store的变化并从中取出我们想要的数据,而相同的数据获取如果是在class组件中则应该写在mapStateToProps中,但不管哪种写法,当我们从state中获取数据后就应该注意保持数据的稳定性,来看个例子:
const userList = useSelector((state) => {
const users = state.userList;
return users.filter((user) => user.age > 18);
});
在上述例子中,我们从state中获取了userList,之后又进行了数据加工过滤出年龄大于18的用户,这个写法看似没什么问题,但事实上全局state的状态并没有我们的想的那么稳定,所以useSelector执行的次数要比你想的要多,此时只要useSelector执行一次,我们都会从state中获取数据,并通过filter加工成一个全新的数组。
如何改善呢?其实很简单,将加工的行为提到外部即可,比如:
const users = useSelector((state) => {
return state.userList;
});
const userList = useMemo(() => {
return users.filter(user => user.age > 18);
}, [users])
PS:每次store变化,每一个useSelector都会执行吗?
问大家一个问题,每次store变化时,是不是所有生命周期内组件的useSelector都会执行一遍?如果执行那像上述代码返回的state.userList是不是每次都是一个全新的对象?那useMemo会不会每次都执行,导致userList每次都是全新的数组吗?其实并不是。
我们可以将全局store理解成一棵大树,不同组件的数据都是这棵树的树枝,请求也好更新也好,一定只是更新这棵树的不同树枝,这棵树从来就没变过(store引用不变)。打个比方,假设A组件更新了树枝a(a引用变了),B组件依赖的是树枝b,那么A组件的更新会导致B组件重复渲染吗?其实不会,这个过程可以简化为如下代码(如果你能不假思索的回答正确,那说明你对于store更新以及引用关系很清晰了):
// 初始化store,这是一棵大树
const store = {
o1: {// 树枝o1
num: 1,
},
o2: {// 树枝o2
num: 2,
},
};
// 保存第一份数据
const a = store.o1;
const b = store.o2;
// 假定后端返回新数据,局部更新store中的树枝 o1
store.o1 = {
num: 3,
};
// 再次取值
const a_ = store.o1;
const b_ = store.o2;
// 此刻这两个相等吗?
console.log(a === a_);
console.log(b === b_);
当B组件通过useSelector取出引用没变化的树枝b时,因为就没变化,它不会无效渲染。
对于redux而言,我们可以将整个react app的store理解成一颗巨大的树,而树有很多分支的树根,每一枝树根都可以理解成某个组件所依赖的state,那么请问假设A组件的树根被更新了,它会对store的其它树根的引用造成影响吗?此时树还是这颗树啊,而那些没变的树根依旧是之前的树根。
所以回到上文的代码,假设state中关于state.userList就没有变化,那么前后不管取多少次,因为引用相同,useMemo除了初始化会执行一次之外,之后都不会重新执行,这就能让userList彻底稳定下来。
而假设我们因为成员接口让state.userList进行了更新,正常来说应该在reducer中重新生成一个新数组再赋予给store,那么在下次useSelector执行时,我们也能拿到全新引用的users,而监听users的useMemo就能按照正确的预期再度更新了。
肆 ❀ 聊聊什么时候该用useMemo
好像代码走读大家对于使用useMemo都存在部分争议,其实理解这个问题很简单,useMemo到底是用来干嘛的?它的本意是对特别复杂的逻辑的结果进行缓存,比如一段代码需要跑很久,有性能损耗,我们通过deps监听变化再决定useMemo的回调是否需要再次执行。因为缓存所以值没变,因为值不变所以引用不变,因为引用不变所以减少了无效渲染。
那么什么时候推荐用,什么时候不推荐用:
- 一段代码的逻辑比较复杂,我不希望每次都执行,所以需要缓存,这种一定要用。
- 一段代码可能不是很复杂,但是返回的值是引用类型,我想保证其引用不变,这种可以用。
- 一段代码本身简单,返回值是基本类型,这种完全没必要用。
deps因不可抗拒力无法稳定,此时useMemo每次都会执行,这种加了也没太大意义。
为什么说第三种完全没必要用,首先基本类型不存在引用变化,值变了就是变了,那就应该渲染;值没变组件自身也不会渲染,外加上逻辑又特别简单,这种就完全没缓存的必要,可以说完全是负优化,比如这种:

大家要注意,缓存不是零代价,useMemo、useCallback与memo的执行都会做一次浅比较,也就是它会拿前后deps监听的数据一一做===的对比,如果引用变了或者值变了它就会执行,所以对比也需要时间啊,然后你还浪费内存,得不偿失。
关于第四点,其实我们加了useMemo是有义务在测试阶段自测其稳定性的,如果你监听的deps完全就是一个无法稳定的数据,此刻你要么想办法将上层数据先稳定下来,要么就先别加useMemo,不然做的都是无效功。(确实会存在无法稳定的数据)
伍 ❀ 三种无效渲染排查手段
聊完了常见的可以避免无效渲染的写法,有同学可能就要说了,从头开始写我可以注意,那假设现在要我优化一个已经写好的无效渲染比较严重的组件,那我怎么下手呢?单看代码我也不知道它引用是否稳定,我们来科普三种方式。
伍 ❀ 壹 why-did-you-render
why-did-you-render是一个专门用来帮你检查无效渲染的库,安装和使用非常简单,这里简单说下:
首先项目安装why-did-you-render:
npm install @welldone-software/why-did-you-render --save-dev
在你的应用根目录,比如app.tsx顶部引入配置:
import whyDidYouRender from '@welldone-software/why-did-you-render';
// 一般只在开发环境启用
if (process.env.NODE_ENV === 'development') {
whyDidYouRender(React);
}
之后找到你想监听的组件,比如我想监听SidebarMenu组件,那么在文件底部添加如下代码:
SidebarMenu.whyDidYouRender = true;
之后刷新页面,如果该组件有无效渲染,那么就会有对应的理由,比如:
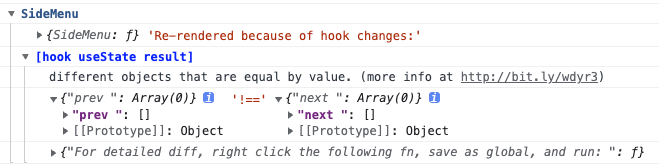
意思是说,有一个useState的结果,前后两次都是空数组且引用不同,所以造成了无效渲染。
注意,对于why-did-you-render而言,它一定是只帮你找出无效渲染,且理由都是上面这种引用数据前后完全一样,只是单纯的引用不同,如何保证引用那么又回到了上文提到的减少无效渲染的手段,如果一个组件一个无效渲染提示都没有,那说明这个组件非常健康。
但需要注意的是,why-did-you-render的感知更多是每次刷新页面的初次渲染,它无法感知hover这种带来的无效渲染,比如notta的侧边栏,可以看到hover时明明一直在渲染,但是控制台一个提示都没有,那怎么办?别急,快去西天请useWhyDidYouUpdate。
伍 ❀ 贰 useWhyDidYouUpdate
useWhyDidYouUpdate是ahooks提供的一个专门用来查看组件update原因的hook,我们直接上官方例子,它的用法也非常简单:
// 传入你想在控制台的名字,方便区分,以及你觉得可疑的数据
useWhyDidYouUpdate(componentName, props);
比如官方例子:
useWhyDidYouUpdate('useWhyDidYouUpdateComponent', { ...props, randomNum });
这里的useWhyDidYouUpdateComponent只是你希望在控制台输出的名字,叫啥都行,阿猫阿狗也行,而后面的接收的是一个对象,比如你只想监听props那就直接传递props即可:
const App = (props)=>{
useWhyDidYouUpdate('哈哈哈哈哈', props);
return null;
}
如果你除了props还想监听其它的,你就可以自定义传递一个解构的对象,比如:
const App = (props)=>{
const userList = useSelector( state => state.userList);
const [num,setNum] = useState(1);
// 后面参数是一个对象,你要监听多个就解构组合成一个对象就好了
useWhyDidYouUpdate('哈哈哈哈哈', {...props, num, userList});
return null;
}
需要注意的是,useWhyDidYouUpdate会告诉你你监听数据中所有变化的数据,不管它是不是无效的更新,所以相对于why-did-you-render它更加全,缺点是需要你自己来区分识别。
伍 ❀ 叁 profiler
profiler属于React Developer Tools的一部分,所以如果你要使用它,记得先安装此插件,之后打开控制台,你就能看到profiler的选项了,记得勾选记录组件渲染原因的选项。
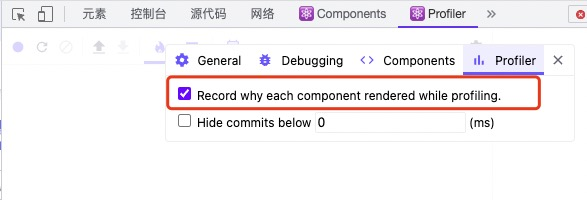
之后跟performance录制的操作一样,点击录制,此时你可以尽情操作你的组件,再点击暂停,你就能看到profiler会帮你记录刚才所有有发生渲染组件的火焰图数据。一般情况下我们只需要关注橙色的组件,比如:
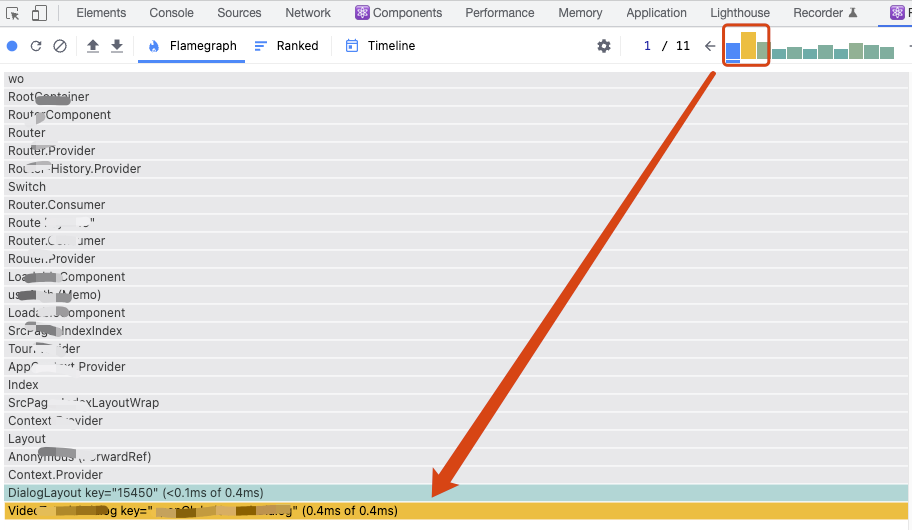

如果是state或者props变化,它会直接告诉你变量名,但如果是hooks变化,它只能告诉你这是第几个,其实这个就很难对应,所以到头来你还是得结合上面的两个工具,综合来判断到底是哪些数据不稳定,造成的组件的多次渲染。
我们来总结下这三个工具:
- why-did-you-render:智能帮你找出组件的无效渲染原因,一定是无效渲染才会在控制台输出。
- useWhyDidYouUpdate:你给什么数据它就帮你监听什么,且只要是变化了它都会输出,至于是不是无效变更需要你自行判断。
- profiler:官方组件性能分析工具,可以直接宏观帮你找出那些橙色的,渲染有问题的组件,然后具体原因你可以结合上述工具一起使用。
所以聊下来你会发现,这个三个工具并不是相许取代关系,而是配合使用的关系。
陆 ❀ 常见的缓存策略(缓存有代价)
在很多情况下,大家都会在心里潜意识认为缓存是无代价的,所以本能会想到只要是生成一个数据,我都给它加上useMemo或者其它的缓存,但事实上所有的缓存都是空间换时间,你想下次取缓存结果,那你之前的结果就一定得保存,要保存就得占用内存空间,这里做个科普,介绍下市面上常见的两种缓存策略。
陆 ❀ 壹 按key缓存
这种缓存原理很简单,建立一个map,然后利用你的传参作为key,只要你下次执行时key能在map中找到值,那就默认返回结果不用重新再次执行逻辑,反之找不到,那就再次执行结果,并结合此刻的key进行新的缓存,一个大致的实现就是:
const getterCache = (fn) => {
const cache = new Map();
return (...args) => {
const [uuid] = args;
// 这里的时间复杂度是O(1)
let data = cache.get(uuid);
if (data === undefined) {
// 没有缓存
data = fn.apply(this, args); // 执行原函数获取值
cache.set(uuid, data);
}
return data;
};
};
市面上使用这种思想的缓存库比如memoizee,但是这个库对于缓存的策略不是使用的map或者对象,而是数组,所以当数量达到十万级别,且你的缓存函数定义的问题没生效,这就导致每次执行都会在十万级的数组中查找目标,然后没找到再计算出一个存入数组,导致额外的性能问题。
比如:
import memoize from 'memoizee'
const fn = function (a) {
return a * a;
};
// 使用缓存
console.time('使用缓存');
const memoizeFn = memoize(fn);
for (let i = 0; i < 100000; i++) {
memoizeFn(i);
}
memoizeFn(90000);
console.timeEnd('使用缓存');
// 不使用缓存
console.time('不使用缓存');
for (let i = 0; i < 100000; i++) {
// 单纯执行,啥也不缓存
fn(i);
}
fn(90000);
console.timeEnd('不使用缓存');

那你会说,什么辣鸡库,用了反而更慢,其实不是库的问题,而是使用者的问题;还记得缓存函数的初衷吗,对于执行比较耗时的逻辑进行缓存以提升性能。而这个例子演示证明了一个问题,一个标准的缓存库,它内部一定也定义了缓存逻辑,跑这段逻辑是需要时间的,而假设你需要缓存的逻辑非常简单,比如上述代码就是数字相乘,你会发现不使用缓存的时间直接秒杀缓存,一个函数需要执行上万次且逻辑简单,你缓存它干嘛??
记住,缓存都是有代价的,缓存代码执行耗时,内存占用,这些都是你需要考虑的,不要为了缓存而缓存,这是我想表达的观点。
陆 ❀ 贰 只记最新参数与结果
与上面的缓存不同,这种缓存策略的不是一个缓存多次结果的对象,而是永远是最新参数的结果,比如 memoize-one。
import memoizeOne from 'memoize-one';
function add(a, b) {
return a + b;
}
const memoizedAdd = memoizeOne(add);
// 第一次执行,结果是3
memoizedAdd(1, 2);
// 第二次执行,因为参数还是1和2,直接走换乘
memoizedAdd(1, 2);
// 第三次执行,因为参数变了,重新执行得到结果5
memoizedAdd(2, 3);
// 第四次执行,参数还是2和3,走缓存
memoizedAdd(2, 3);
这里我简单看了下源码:
function memoized(
this: ThisParameterType<TFunc>,
...newArgs: Parameters<TFunc>
): ReturnType<TFunc> {
// 只有当需要缓存,且this相同,且新旧入参相同时才会返回缓存的结果
if (cache && cache.lastThis === this && isEqual(newArgs, cache.lastArgs)) {
return cache.lastResult;
}
// 删除无意义的部分
}
function isEqual(first: unknown, second: unknown): boolean {
// 真正的对比其实用的是 ===
if (first === second) {
return true;
}
// 删除部分NaN的对比
return false;
}
export default function areInputsEqual(
newInputs: readonly unknown[],
lastInputs: readonly unknown[],
): boolean {
// 先判断入参的长度是否相同,参数长度都不同直接返回false
if (newInputs.length !== lastInputs.length) {
return false;
}
for (let i = 0; i < newInputs.length; i++) {
// 遍历,一次拿新旧参数进行对比
if (!isEqual(newInputs[i], lastInputs[i])) {
return false;
}
}
return true;
}
其次就是每次执行看结果是不是空,以及前后参数进行浅比较看是否相等,如果都相等就直接返回cache,如果不是就重新计算更新cache。这种策略是不是让你想到memo、useMemo了?没错,react的这些方法也是这个策略,这也是为什么解决无效渲染需要保证引用数据稳定性的原因,因为浅比较就是最简单的===。
综合两种策略,你会发现第一种的好处是,它会尽可能帮你把没见过的参数以及结果都缓存起来,便于下次你再执行时直接使用,但弊端就是执行次数越多,你的内存占用越大。第二种策略不会有内存占用的烦恼,但如果你的参数变化特别频繁,你会发现你的缓存起不到什么作用。事实上这两种缓存使用场景不同,不具备可比性,在合适的场景使用就好了。
柒 ❀ 怎么发现项目中存在无效渲染的组件
聊到最后,我们介绍了避免无效渲染的常规写法,以及如何排查一个组件无效渲染的原因,有同学可能就要问了,那一个项目那么大,我怎么知道哪些组件需要优化呢?
两种办法,第一种使用profiler交互页面,关注橙色组件即可。第二种办法还是使用React Developer Tools,勾选如下渲染,这些刷新页面你就能看到每个组件的渲染情况。
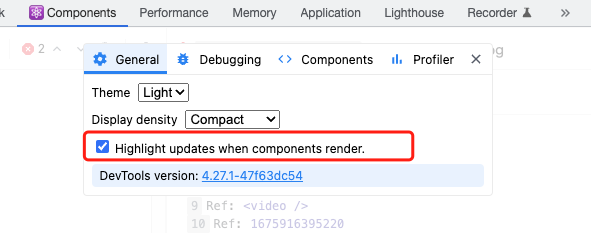
主要关注颜色深度,绿色到黄色,越偏黄色表示渲染越多,那么接下来进入提问环节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号