
数据库
关系型数据库主要考点
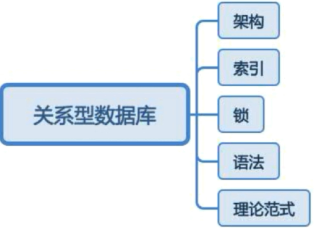
一个面试题引发出来套路
——>>如何设计一个关系型数据库?
设计
RDBMS关系数据库管理系统(Relational Database Management System)分为:
- 程序实例(存储管理、缓存机制、sql解析、日志管理、权限划分、容灾机制、索引管理、锁管理)
- 存储(文件系统)——>>机械硬盘、SSD固态硬盘
索引模块
为什么要使用索引?
——>>避免全表扫描,快速查询数据
什么样的信息能成为索引?
——>>主键、唯一键、普通键
索引的数据结构
- 生成索引,建立二叉查找树进行二分查找
- 生成索引,建立B-Tree结构进行查找
- 生成索引,建立B+-Tree结构进行查找
- 生成索引,建立Hash结构进行查找
二叉查找树
特点:
- 二叉树任意节点的左节点不为空,则左节点的值均小于它的根节点
- 二叉树任意节点的右节点不为空,则有节点的值均大于它的根节
- 任意节点的左右节点也为二叉树
- 没有键值相等的节点
平衡二叉树
它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
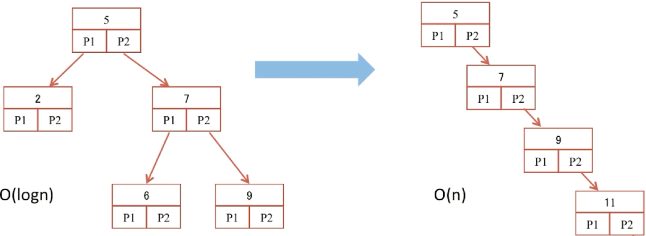
由上图,左图的查询时间复杂度为O(logn),但若面临增加和删除
删除节点2和6, 新增了节点为11,根据二叉树的特点,会插入到9的右节点中,此时就会变成一颗线性的二叉树
此时右图的查询时间复杂度为O(n),大大的降低了查询效率
利用树的旋转特性,来保证这棵树为平衡二叉树,此时查询时间复杂度为O(logn),但是依然存在问题——>>IO
首先令这些索引块都在磁盘中,去查询节点6
- 会发生一次IO,将根的数据5放入内存中
- 再发生一次IO,将节点7读入进来
- 又发生一次IO,检索到节点6
检索深度每增加1,就会发生一次IO,不管是平衡二叉树还是红黑树,每个节点最多只允许有两个孩子,而数据块会非常多,为了组织这些数据块,树就会很深很深,IO次数也会很多,那么检索性能也会比全表扫描慢的多,无法满足优化查询的需求
那么如何降低查询时间的复杂度,又降低IO次数?主要是让树变的矮一些,每个节点所储蓄的数据多一些
——>>B-Tree
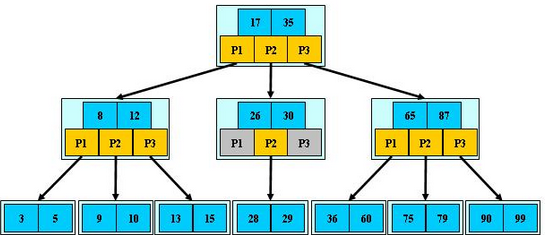
B-Tree
- 根节点至少包括两个孩子
- 树中每个节点最多含有m个孩子(m>=2)
- 除根节点和叶节点外,其他每个节点至少有ceil(m/2)个孩子
- 所有叶子节点都位于同一层
锁模块
MyISAM和InnDB关于所方面的区别是什么?
- MyISAM默认用的是表级锁,不支持行级锁
- InnoDB默认用的是行级锁,也支持表级锁
表级锁和行级锁
表级锁:表级,直接锁定整张表,在锁定期间,其它进程无法对该表进行写操作。如果是写锁,则其它进程则读也不允许
行级锁:行级一种排他锁,防止其他事务修改此行,仅对指定的记录进行加锁,这样其它进程还是可以对同一个表中的其它记录进行操作
MyISAM:
- 不支持事务,但是每次查询都是原子的;
- 支持表级锁,即每次操作是对整个表加锁;
- 存储表的总行数;
- 一个MYISAM表有三个文件:索引文件、表结构文件、数据文件;
- 采用菲聚集索引,索引文件的数据域存储指向数据文件的指针。辅索引与主索引基本一致,但是辅索引不用保证唯一性。
InnoDb:
- 支持ACID的事务,支持事务的四种隔离级别;
- 支持行级锁及外键约束:因此可以支持写并发;
- 不存储总行数;
- 一个InnoDb引擎存储在一个文件空间(共享表空间,表大小不受操作系统控制,一个表可能分布在多个文件里),也有可能为多个(设置为独立表空,表大小受操作系统文件大小限制,一般为2G),受操作系统文件大小的限制;
- 主键索引采用聚集索引(索引的数据域存储数据文件本身),辅索引的数据域存储主键的值;因此从辅索引查找数据,需要先通过辅索引找到主键值,再访问辅索引;最好使用自增主键,防止插入数据时,为维持B+树结构,文件的大调整。
本文转发整合:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号