

python中多线程相关
基础知识
进程:进程就是一个程序在一个数据集上的一次动态执行过程
数据集:程序执行过程中需要的资源
进程控制块:完成状态保存的单元
线程:线程是寄托在进程之上,为了提高系统的并发性
线程是进程的实体
进程是一个资源管理单元、线程是最小的执行单元
注意:
- 一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
- 资源分配给进程,同一进程的所有线程共享该进程的所有资源。
- CPU分给线程,即真正在CPU上运行的是线程。
线程切换:遇到i/o操作、优先级等
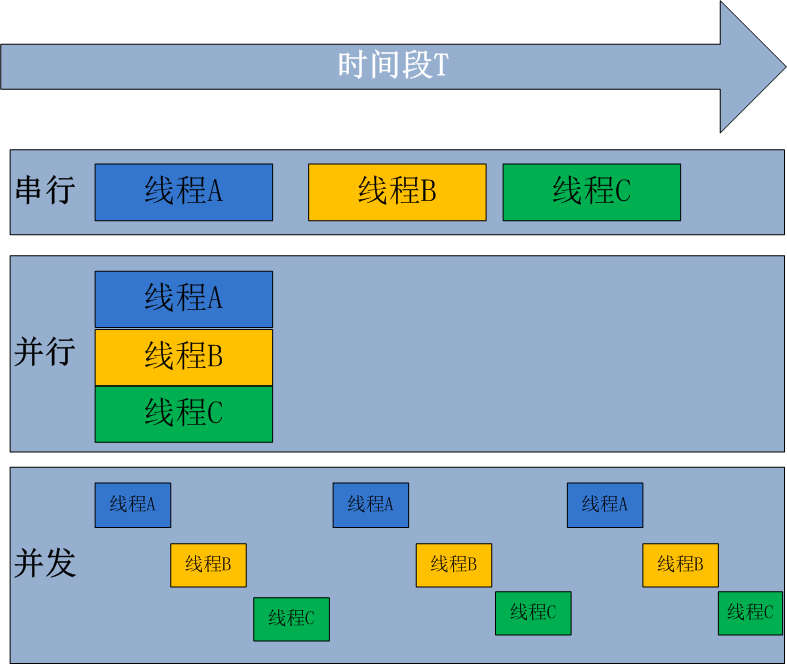
并发:在同一个时间段里,能够执行多个程序。
并行:多个cpu,在同一时刻能够执行多个程序。
切换:即任务状态的保存,状态的恢复,是并发的条件,注:为了共用数据集,线程进行切换,且线程切换开销远小于进程切换开销
同步:同步指一个进程在执行某个请求的时候,若该请求需要一段时间才能返回信息,那么这个进程将会一直等待下去,直到收到返回信息才能继续执行下去
异步:异步指进程不需要一直等待下去,而是继续执行下面的操作,不管其他进程的状态。当有消息返回时系统会通知进程进行处理,这样提高效率
线程的使用场景:
- 把长时间占据内存的程序中的任务放到后台管理
- 同时执行多段程序,以达成更好的用户体验,如用户界面弹出执行另外一段程序等
- 加速程序运行,效率更高
- 在I/O操作时,合理释放资源,如释放内存占用等
线程和进程执行中的区别:进程有程序运行的入口、顺序执行序列、程序运行的出口,但线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。
每个线程都有他自己的一组CPU寄存器,称为线程的上下文,该上下文反映了线程上次运行该线程的CPU寄存器的状态。
指令指针和堆栈指针寄存器是线程上下文中两个最重要的寄存器,线程总是在进程得到上下文中运行的,这些地址都用于标志拥有线程的进程地址空间中的内存。
- 线程可以被抢占(中断)。
- 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) -- 这就是线程的退让。
python中的GIL(全局解释器锁)
GIL并不是python的特性,是在实现python解析器(CPython)时所引入的一个概念,是为了实现不同线程对共享资源访问的互斥,才引入了GIL。
在CPython解释器中,同一个进程下开启的多线程,同一时刻只能有一个线程执行,无法利用多核优势
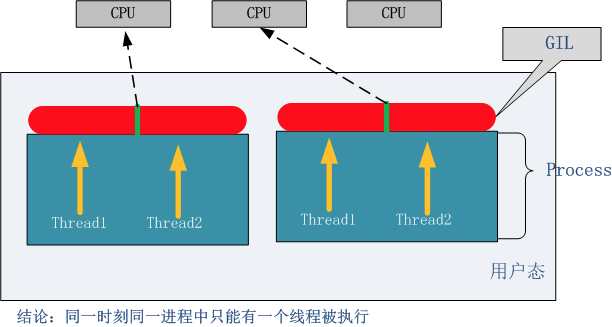
python对于计算密集型的任务开多线程的效率甚至不如串行(没有大量切换),但对于IO密集型的任务效率还是有显著提升的。
计算密集型:
import time import threading def test(): global count temp = count count = temp + 1 time.sleep(2) count = 0 l = [] for _ in range(100): t = threading.Thread(target=test, args=()) t.start() l.append(t) for t in l: t.join() print(count) # 最终结果一定是100
IO密集型:
import time import threading def test(): global count temp = count time.sleep(0.001) # 模拟大量io操作 count = temp + 1 time.sleep(2) count = 0 l = [] for _ in range(100): t = threading.Thread(target=test, args=()) t.start() l.append(t) for t in l: t.join() print(count) # 输出值不一定
计算密集型每次start结果已经出来了,第二个线程是通过调用第一个线程的count值进行计算。
io密集型,因为中间阻塞了0.001秒,已有start多个线程,所以导致大多数的线程调用count值还是0,仅少数线程完成了count=temp+1的操作,所以最后结果不一定。
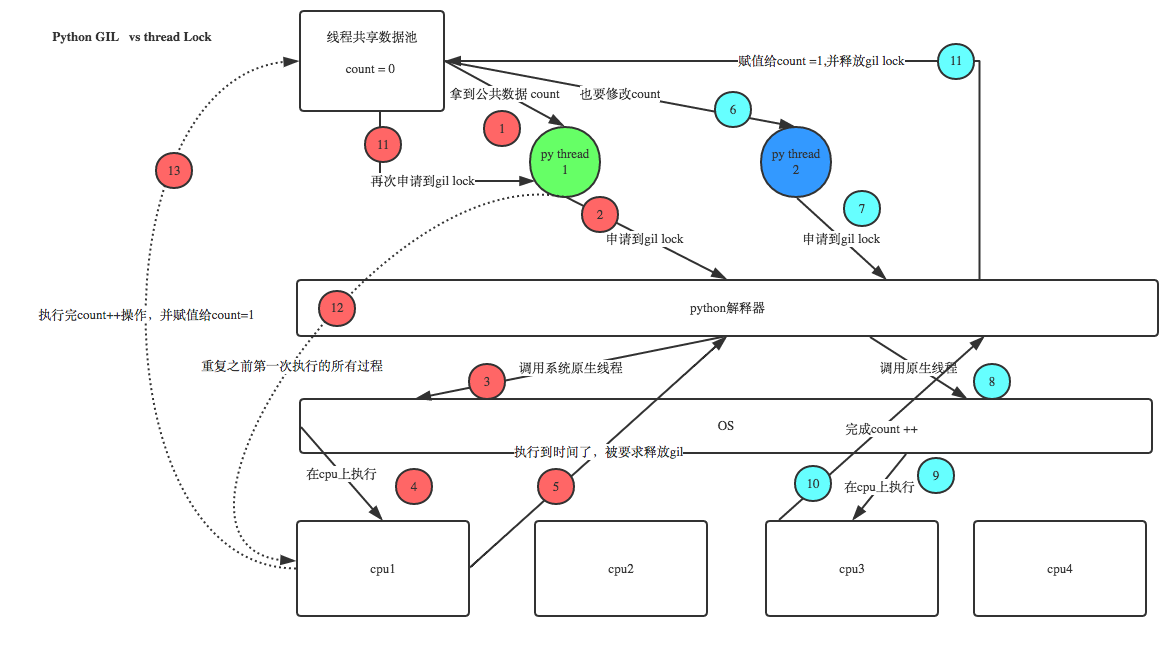
python中操作线程
python中使用线程有两种方式:函数或者用类来包装线程对象。
函数:调用thread模块中的start_new_thread()函数来产生新线程。
thread.start_new_thread ( function, args[, kwargs] )
参数说明:
- function - 线程函数。
- args - 传递给线程函数的参数,他必须是个tuple类型。
- kwargs - 可选参数。
线程的结束一般依靠线程函数的自然结束,也可以在线程函数中通过调用thread.exit(),抛出SystemExit exception,达到退出线程的目的。
线程模块
python通过两个标准库对线程操作:thread和threading。其中thread提供了低级别的、原始的线程以及一个简单的锁。
threading模块则提供了很多接口:
- threading.currentThread(): 返回当前的线程变量。
- threading.enumerate(): 返回一个包含正在运行的线程的list。不包括启动前和终止后的线程。
- threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
- Thread类:
- run(): 用以表示线程活动的方法。
- start():启动线程活动。
- join([time]): 等待至线程中止。这阻塞调用线程直至线程的join()方法被调用中止:正常退出或者抛出未处理的异常或者是可选的超时发生。
- isAlive(): 返回线程是否活动的。
- getName(): 返回线程名。
- setName(): 设置线程名。
import treading class myThread(treading.Thread): def __init__(self, threadID, name, counter): # threading.Thread.__init__(self) super(myTread, self).__init__(*args, **kwargs) self.threadID = threadID self.name = name self.counter = counter def run(self): # 线程在创建后会直接执行此方法 print(1) pass # 创建新线程 thread1 = myThread(1, 'Thread-1', 1) thread2 = myThread(2, 'Thread-2', 2) # 开启新线程 thread1.start() thread2.start()
线程同步
如果多个线程共同对某个数据修改,会造成不可预料的结果,为了保证数据的正确性,需对多个线程进行同步,可加锁实现。
使用Tread对象Lock和Rlock可是实现简单的线程同步,这两个对象都有acquire方法和release方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到acquire和release方法之间。
多线程同时运行多个任务,当线程需要共享数据时,可能存在数据不同步的问题,比如一个线程从前往后读取一个序列,一个线程从前往后更改一个序列,最终的结果可能就是前一半输出更改前的,后一半输出更改后的。
解决上述问题通过锁定线程的方式,锁的两个状态锁定和未锁定。当上述负责读取的线程访问共享数据时,必须获得锁定,如果已有别的线程锁定,那就暂停读取线程,即同步阻塞,等别的线程释放锁后再继续读取。这样的结果就是读取所有旧数据或者所有新数据。
import treading class myThread(treading.Thread): def __init__(self, threadID, name, counter): super(myTread, self).__init__(*args, **kwargs) self.threadID = threadID self.name = name self.counter = counter def run(self): # 线程在创建后会直接执行此方法 threadLock.acquire() # 获得锁成功返回True,可选参数timeout不填时将阻塞到获得锁定为止,超时返回False print(1) threadLock.release() # 释放锁 threadLock = threading.Lock() # 把锁内的代码串行化 # 线程列表 threads = [] # 创建新线程 thread1 = myThread(1, 'Thread-1', 1) thread2 = myThread(2, 'Thread-2', 2) # 开启新线程 thread1.start() thread2.start() threads.append(thread1) threads.append(thread2) # 等待所有线程完成 for t in threads: t.join()
python多线程的缺点
在Python中,有一个GIL,即全局解释锁,该锁的存在保证在同一个时间只能有一个线程执行任务,也就是多线程并不是真正的并发,只是交替得执行。假如有10个线程在10核CPU上,当前工作的也只能是一个CPU上的线程。
python多线程的优势
在I/O密集型执行期间大部分是时间都用在I/O上,如数据库I/O,较少时间用在CPU计算上。因此该应用场景可以使用Python多线程,当一个任务阻塞在IO操作上时,我们可以立即切换执行其他线程上执行其他IO操作请求。
即Python多线程在IO密集型任务中还是很有用处的,而对于计算密集型任务,应该使用Python多进程。
锁
互斥锁(同步锁):用来解决诸如io密集型场景产生的计算错误,即目的是为了保护共享的数据,同一时间只能有一个线程修改共享的数据。
其过程:第一个线程如果申请到锁,会在执行公共数据的过程中持续阻塞后续线程,即后续第二个或其他线程依次来了发现已经上锁,只能等待第一个线程释放锁,当第一个线程将锁释放,后续的线程会进行争抢。
代码类似上述线程同步不再赘述。
死锁:保护不同的数据应该加不同的锁,所以当有多个互斥锁存在时,会导致死锁
import threading import time def test1(): lockA.acquire() print('func test1 ClockA lock') lockB.acquire() print('func test1 ClockB lock') lockB.release() lockA.release() def test2(): lockB.acquire() print('func test2 ClockB lock') time.sleep(2) lockA.acquire() print('func test2 ClockA lock') lockB.release() lockA.release() def run(): test1() test2() lockA=threading.Lock() lockB=threading.Lock() for i in range(10): t=threading.Thread(target=run,args=()) t.start() # 输出结果只有四行,因为产生了死锁阻断了
test2中sleep(2)模拟io或者其他操作,但第一个线程执行到这,因为阻塞,lockA会被第二个进程占用。所以第一个进程无法进行后续操作,只能等待lockA锁的释放,导致死锁。
解锁死锁问题除了合理释放锁之外可以使用下述的递归锁。
递归锁:解决死锁
import threading import time def test1(): rlock.acquire() print('func test1 ClockA lock') rlock.acquire() print('func test1 ClockB lock') rlock.release() rlock.release() def test2(): rlock.acquire() print('func test2 ClockB lock') time.sleep(2) rlock.acquire() print('func test2 ClockA lock') rlock.release() rlock.release() def run(): test1() test2() rlock=threading.RLock() for i in range(10): t=threading.Thread(target=run,args=()) t.start()
RLock本身有一个计数器,如果碰到acquire,那么计数器+1,如果计数器大于0,那么其他线程无法查收,如果碰到release,计数器-1
Semaphore(信号量):实际上也是一种锁,该锁用于限制线程的并发量
import threading import time sem = threading.Semaphore(5) def test(): sem.acquire() time.sleep(2) print('ok') sem.release() for i in range(100): t = threading.Thread(target=test,args=()) t.start()
上述结果把并发量设置为5,即每sleep两秒,打印5个ok,直至结束
如果不设置则会在两秒后打印出100个ok

 浙公网安备 33010602011771号
浙公网安备 33010602011771号