Princeton Algorithms, Part I week1 union&find
union & find
首先就是quick union,想法比较简单,首先就是初始化有N个元素的数组,初始化的时候对面的index里面存储的就是index本身,然后比如union 1 和 9 两个点就把他们对应的哪个component里面的所有元素的值都改为一样。优点:在看两个点是否是connect的时候 时间复杂度是1 缺点:union的时候N个元素的时间复杂度是 $O(N^2)$,代码实现如下
1 public class QuickFindUF{ 2 private int [] id; 3 public QuickFindUF(int N){ 4 id = new int[N]; 5 for (int i =0;i<N;i++){ 6 id[i] = i; 7 } 8 } 9 public boolean connected(int p, int q){ 10 return id[p] == return id[q]; 11 12 } 13 public void union(int p, int q){ 14 15 int pid = id[p]; 16 int qid = id [q]; 17 for (int i = 0;i<N;i++){ 18 if (id[i] == pid){ id[i] = qid;} 19 } 20 } 21 22 }
接下来是quickUnion,其基本思想就是做成树的结构,首先初始化N长度的数组,然后对应的数组里面存储的是父节点,union的时候我们只需要一直找下去找到根节点,再把根节点连到另外个点的根节点就行,find的 时候只需要看根节点是否一样就行。优点:union的时间复杂度取决于树的深度 缺点:find的时间复杂度变高了。  下面是java实现
1 public class QuickUnionUF{ 2 private int [] id; 3 public QuickUnionUF(int N){ 4 5 id = new int [N]; 6 for(int i = 0;i < N;i++){ 7 id[i] = i; 8 } 9 10 } 11 public int root(int i){ 12 13 while(id[i] != i){ i = id[i];} 14 return i; 15 } 16 public boolean connected(int p , int q){ 17 int rootP = root(p); 18 int rootQ = root(q); 19 return rootP == rootQ; 20 } 21 22 public void union(int p , int q){ 23 int i = root(p); 24 int j = root(q); 25 id[i] = j; 26 27 } 28 29 }
有两种改进QuickUnionUF的方法
第一种 将更小的树(节点少)连接 到更大的树上(节点多),如下图所示
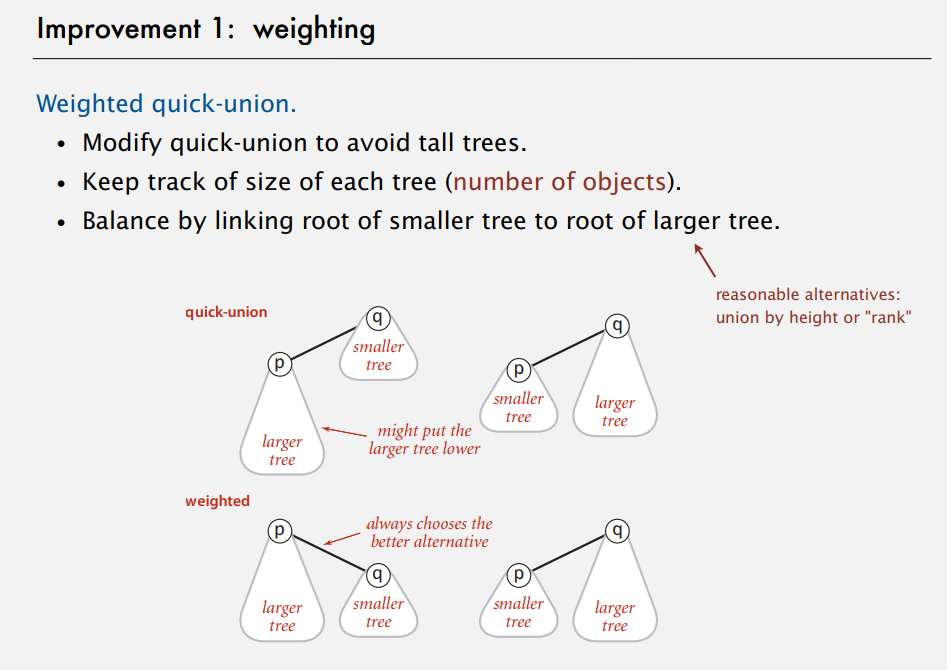
这种叫Weighted quick-union
下面是代码实现,find 和quick-union是一样的,union的代码需要一些修改,需要维护一个sz数组,用于存储树的大小。
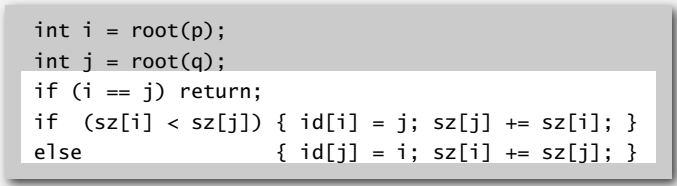
接下来是 Weighted quick-union 的性能分析
find和union操作是和p和q的深度成正比。但是这个算法任何节点x的深度不会超过lg N 这里lg指的是2为底。
proof:含有x节点的树什么时候深度会增加呢?只有当树T1 融合了 T2,而包含了x节点的树想要增加深度,至少整个树的节点就要翻倍因为$ \left| T_1 \right| \geqslant \left| T_2 \right|$, 这样一来含有x的树的节点数最多翻倍lg N次,深度最多就是lg N.
第二种 是通过路径压缩的方法
Quick union with path compression
这种方法就是在计算p节点的根节点的时候,把路径上的所有除根节点以外的节点,连接到根节点上,从而降低树的高度。实现方法有两种,一种是分两步Two-pass implementation,一种是一步直接达成Simpler one-pass variant。代码如下
Two-pass implementation java implementation
public int root(int i ){ int j = i; int root; while(i != id[i]){i = id[i];} root = i; while( j != id[j] ){ int k = j; j = id [j] id[k] = root } return root; }
Simp;er one-pass variant
public int root( int p){ while(i != id[i]){ id[i] = id[id[i]] i = id [i]; } return i; }
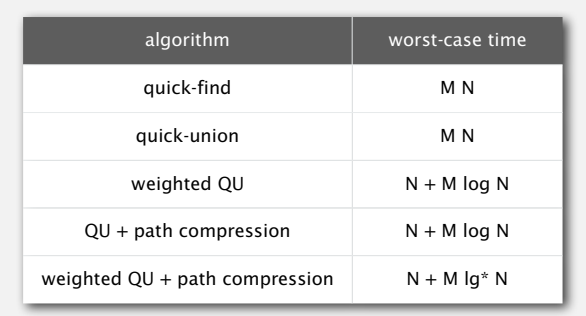
下面是一些性能分析的总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号