
Python 作业5:数据可视化2
一、散点图
1、作业一
(1) 作业要求
使用IRIS数据集,在一个figure中绘制出下方的16个子图。 分别使用花瓣长度、花瓣宽度、花萼长度和花萼宽度这四种数据,两两组合,形成散点。
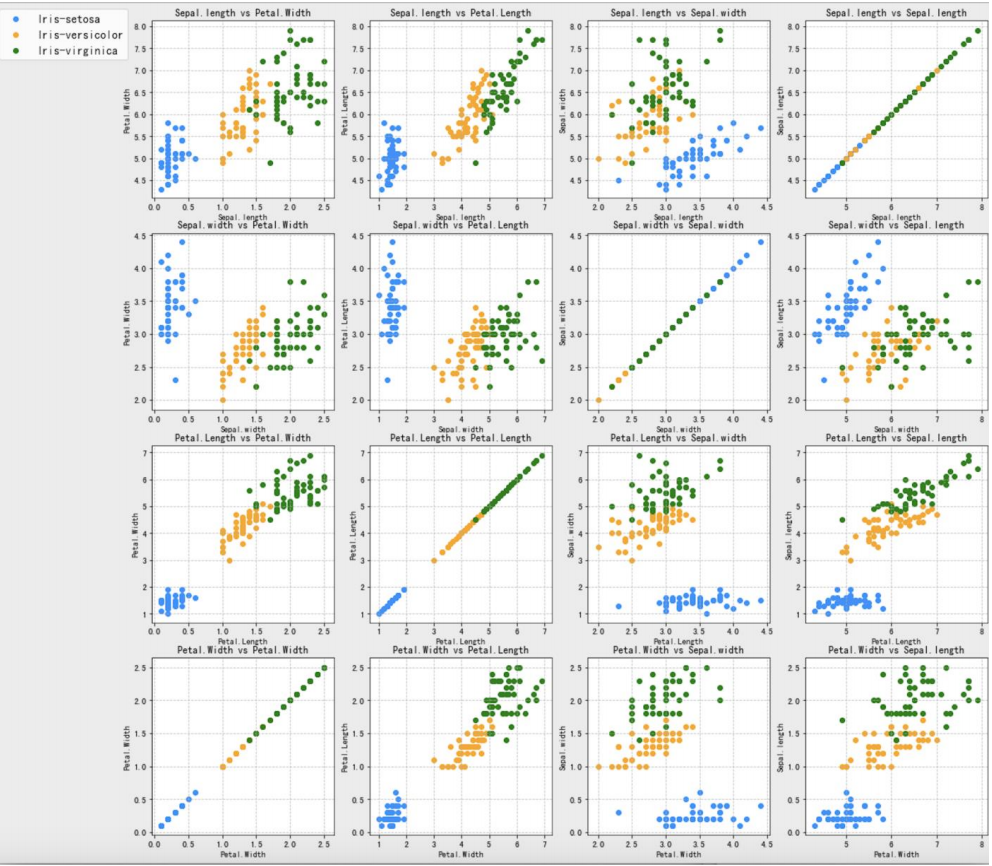
(2) 作业分析与代码实现
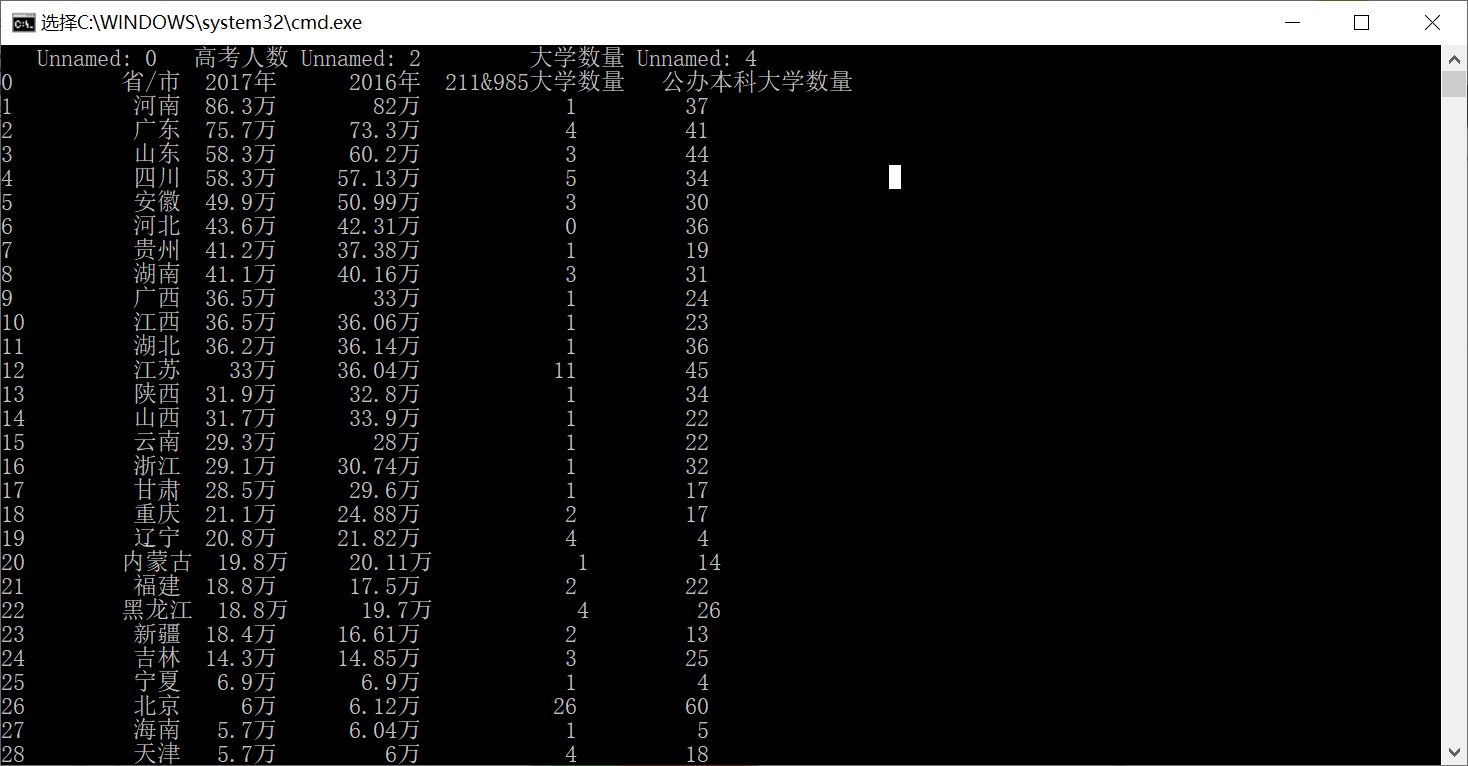
- 使用IRIS数据集,需要引用pandas库对数据集读入分析;同时注意观察图中16个子图的横纵坐标,使用正确的数据作为每个子图的横纵坐标轴刻度;数据集概述如下:
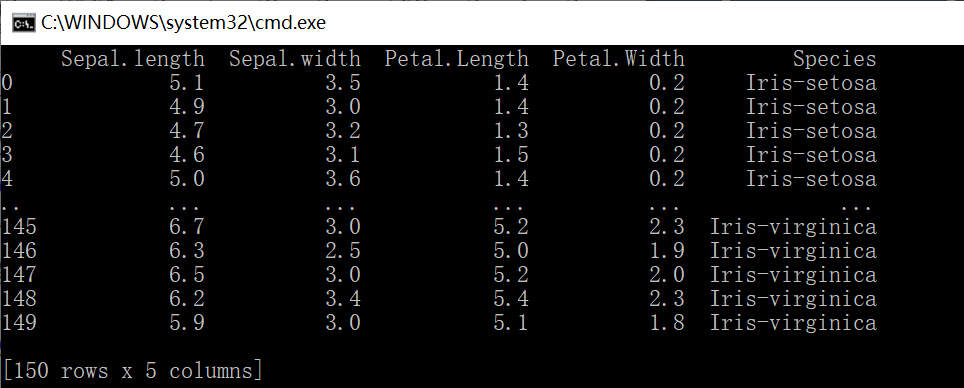
-
注意对类别去重,三种散点颜色分别为:绿:Iris-virginica;黄:Iris-versicolor;蓝:Iris-setosa;两两搭配可得横纵坐标轴分别为:
['Sepal.length', 'Sepal.width', 'Petal.Length', 'Petal.Width']、['Petal.Width', 'Petal.Length', 'Sepal.width', 'Sepal.length']; -
得到横纵坐标轴的列表,便可用两重for循环将其两两组合,通过列表元素得到数据集的对应数据(dataframe类型变量:iris存储);
-
使用subplot绘制子图,注意参数为(4, 4, n),n为子图编号,每轮循环进行自加;
-
对图添加轴标签和标题
plt.title、plt.xlabel、plt.ylabel; -
以上便可得到大致图像,如下:
- 可以看到子图标题和x轴标签重合的现象,同时还未绘制图例;并且y轴坐标跨度过于大,无法清晰显现散点的集群;
- 任务:子图间距、图例(要求中只有一个图例,在整个画布的左上方)、y轴坐标刻度间距:
# 1、设置子图之间距离:wspace为左右距离,hspace为上下间距
plt.subplots_adjust(left = 0.125, bottom = 0.1, right = 0.9, top = 0.9, wspace = 0.2, hspace = 0.8)
# 2、图例
if cnt == 1:
""" 设置legend的位置,将其放在图外,并且只有第一幅子图时才绘制 """
plt.legend(loc = 'upper left', bbox_to_anchor = (-0.75, 1.12), borderaxespad = 0.)
# 3、y轴坐标刻度
y_major_locator=MultipleLocator(1)
ax=plt.gca()
ax.yaxis.set_major_locator(y_major_locator)
- 综合上述思路,可编写代码如下:
"""数据可视化:散点图1"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
fig = plt.figure(dpi=80)
# 读取数据
colors = ['b', 'y', 'g'] # 定义三种散点的颜色
iris = pd.read_csv('iris.csv')
species = iris.Species.unique() # 对类别去重,三种类别
attributes1 = ['Sepal.length', 'Sepal.width', 'Petal.Length', 'Petal.Width']
attributes2 = ['Petal.Width', 'Petal.Length', 'Sepal.width', 'Sepal.length']
# 循环绘图,attributes中的搭配
cnt = 1
for i in range(len(attributes1)):
for j in range(len(attributes2)):
plt.subplot(4, 4, cnt) # 设置子图16个,一行4列,画第cnt个
for k in range(len(species)):
plt.scatter(iris.loc[iris.Species == species[k], attributes2[j]],
iris.loc[iris.Species == species[k], attributes1[i]],
s = 15, c = colors[k], label = species[k])
# 添加轴标签和标题
plt.title(attributes1[i].split('.')[1] + ' vs ' + attributes2[j].split('.')[1])
plt.xlabel(attributes2[j])
plt.ylabel(attributes1[i])
plt.grid(True, linestyle = '--', alpha = 0.8) # 设置网格线
# 设置坐标刻度
y_major_locator=MultipleLocator(1)
ax=plt.gca()
ax.yaxis.set_major_locator(y_major_locator)
if cnt == 1:
""" 设置legend的位置,将其放在图外 """
plt.legend(loc = 'upper left', bbox_to_anchor = (-0.75, 1.12), borderaxespad = 0.)
# 该子图绘图结束要绘制下一个子图
cnt = cnt + 1
# 设置子图之间距离:wspace为左右距离,hspace为上下间距
plt.subplots_adjust(left = 0.125, bottom = 0.1, right = 0.9, top = 0.9, wspace = 0.2, hspace = 0.8)
plt.show()
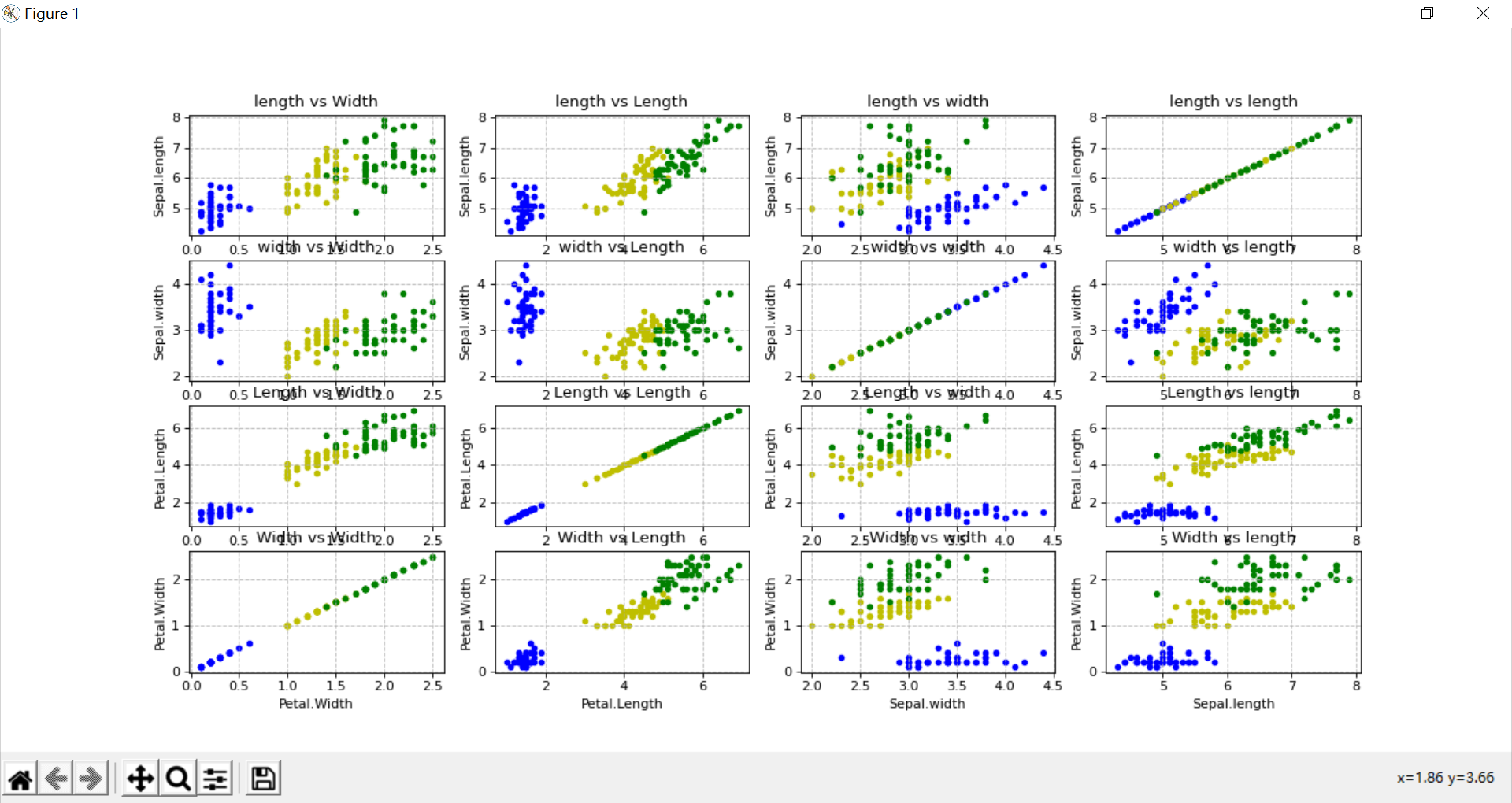
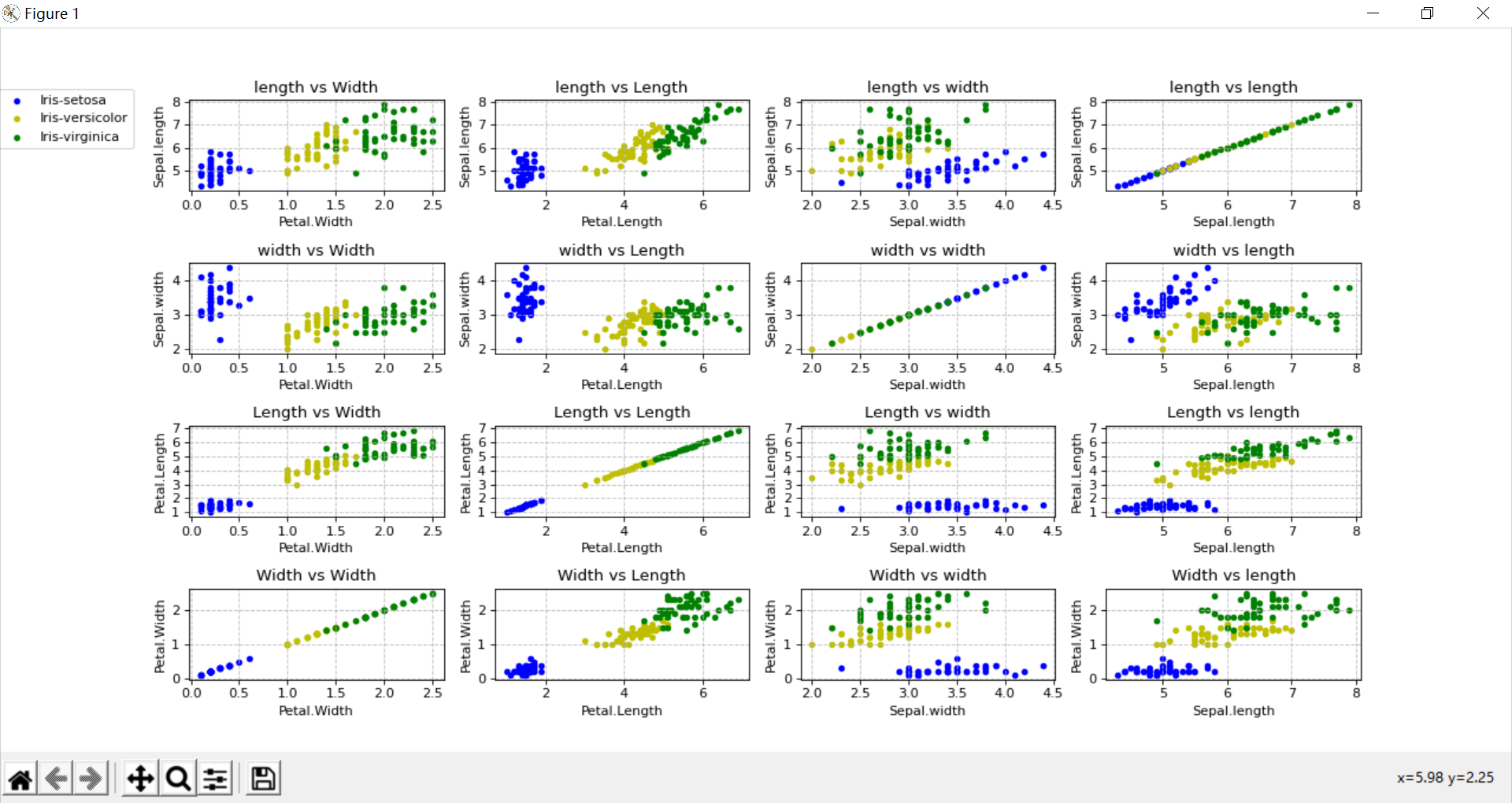
(3) 效果演示
说明:遗憾的是,以我目前的水平没有办法指定子图长宽尺寸,所以子图都是长条状,y轴较短,美观上无法与示例图相比
二、饼图
2、作业二
(1) 作业要求
- 找一组自己感兴趣的真实数据,绘制出饼图。并看看数据的项数在什么范围比较合适在饼图中展示;
- 调整数据的顺序或角度,使得第一个扇区在12点方向开始;
- 调整字体的大小、标签的位置等参数。
(2) 作业分析与代码实现
- 我选择作业给定的中国大学数量csv文件:“中国大学数量.csv”中的2017年高考人数来绘制饼图;
- 观察csv文件的数据,可以看到2017年高考人数对应的索引是:“高考人数”,而2016年对应的是空索引(比较神奇);
- 要得到可用于计算的人数,要对提取的数据进行预处理(str方法);
- 由于要判断:数据的项数在什么范围比较合适在饼图中展示、调整字体的大小、标签的位置等参数,我的解决方法:打印未处理过数据的饼图和处理过数据的饼图进行对比、打印使用多种数据项数的子图饼图(从2->10)对比判断;
- 通过以上思路,编写代码如下:
"""数据可视化:饼图"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
from matplotlib import font_manager as fm
import copy
# 读取中国大学数量csv文件,用其中的2017年高考人数制作饼图
df = pd.read_csv('中国大学数量.csv', encoding = 'utf-8')
ls = df.高考人数.tolist()
ls.pop(0)
for i in range(len(ls)):
"""此时ls中的数据均以万为单位,所以要删除'万'字符"""
ls[i] = float(ls[i].replace('万', ''))
total = 0
for emp in ls:
"""计算高考总人数"""
total += emp
def setSize(ls, l):
"""计算各区间省份数"""
upper = max(ls)
step = (upper + 10) // l # 设置划分区间步长
dic = [i for i in range(l)]
for emp in ls:
section = int(emp // step)
dic[section] = dic[section] + 1
return dic
""" 打印最原始的饼图,与之后调整后的饼图对比 """
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] #支持中文的细黑体
label = ["优惠模式", "普通模式", "困难模式", "噩梦模式", "地狱模式"] # 设置标签
explode = [0, 0, 0, 0, 0.1]
size = setSize(ls, len(label))
plt.pie(size, explode = explode, labels = label, labeldistance = 1.1, autopct = "%1.1f%%",
shadow = True, startangle = 0, pctdistance = 0.6)
""" 显示多个子图,判断数据项数合适范围 """
label2 = ["困难模式", "噩梦模式", "地狱模式", '地狱模式1', '地狱模式2', '地狱模式3', '地狱模式4', '地狱模式5'] # 标签2
label3 = copy.deepcopy(label[0 : 2])
explode2 = [0, 0, 0.1, 0, 0, 0, 0, 0.1]
explode3 = copy.deepcopy(explode[0 : 2])
fig1 = plt.figure() # 新的画布
for i in range(9):
explode_list = copy.deepcopy(explode3)
label_list = copy.deepcopy(label3)
explode_list += explode2[0 : i]
label_list += label2[0 : i]
size = setSize(ls, len(label_list))
plt.subplot(3, 3, i + 1) # 设置九个子图
print(label_list, explode_list)
plt.pie(size, explode = explode_list, labels = label_list, labeldistance = 1.1, autopct = "%1.1f%%",
shadow = True, startangle = 0, pctdistance = 0.6)
""" 调整数据,使饼图从12点钟方向开始;并调整字体大小、标签位置;
打印作为对比 """
fig2 = plt.figure() # 新的画布,绘制调整后的饼图
size = setSize(ls, len(label))
size[0] -= 34 * 0.030 # 更改数据使饼图从12点钟方向开始
# labeldistance : label绘制位置,相对于半径的比例, 如<1则绘制在饼图内侧,默认值为1.1;改变该参数便可改变标签位置
patches, texts, autotexts = plt.pie(size, explode = explode, labels = label, labeldistance = 0.8,
autopct = "%1.1f%%", shadow = True, startangle = 0, pctdistance = 0.6)
# 调整字体大小
proptease = fm.FontProperties()
proptease.set_size('15')
# font size include: 'xx-small',x-small','small','medium','large','x-large','xx-large' or number, e.g. '12'
plt.setp(texts, fontproperties = proptease)
plt.setp(autotexts, fontproperties = proptease)
plt.show()
(3) 效果演示及结果分析
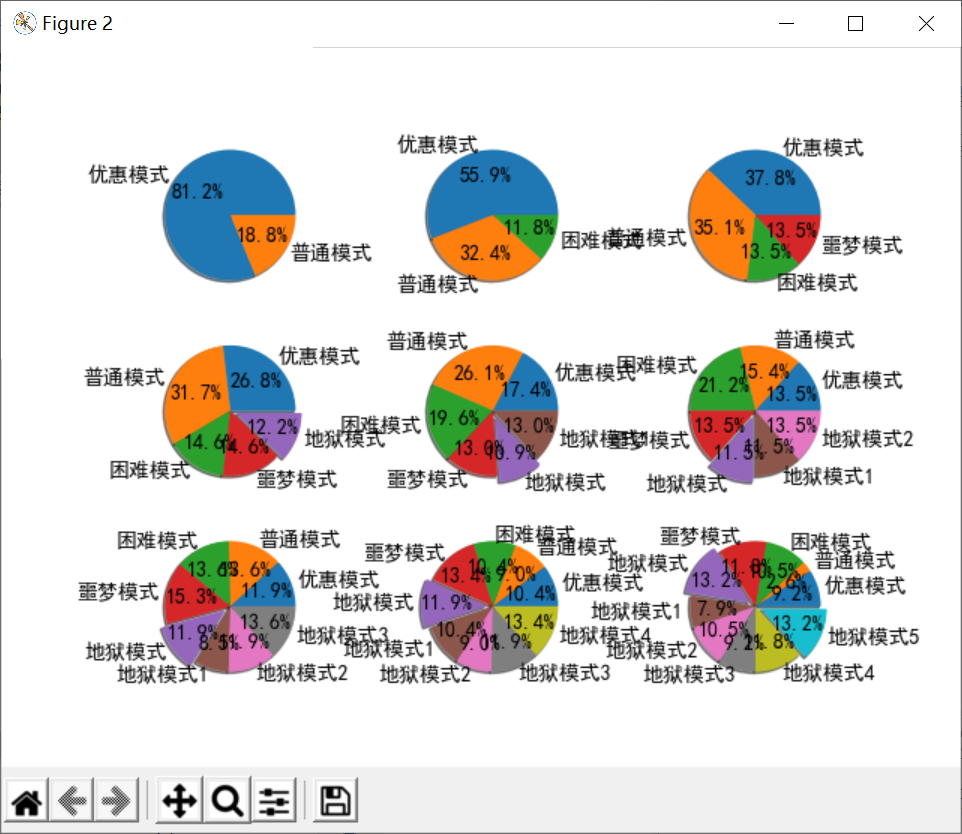
- 原始饼图:

- 调整数据和图上元素后的饼图,可以看到第一扇区是从12点钟开始的,我是调小了属于优惠模式的数据,使得其能呈现这一状态:
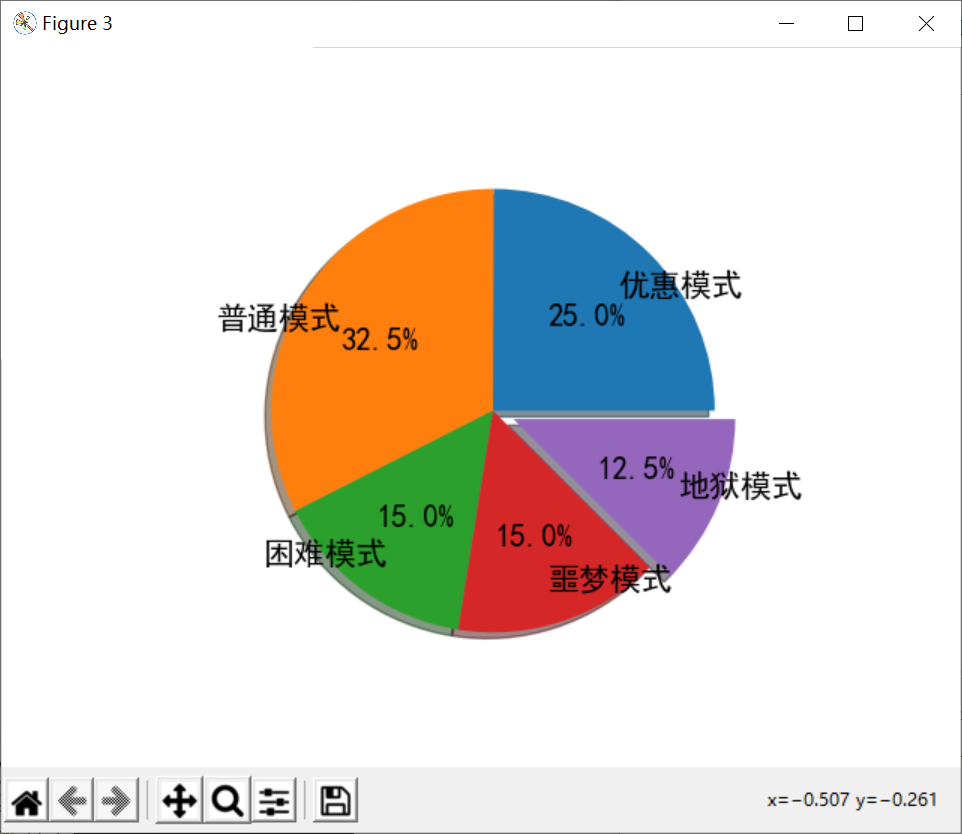
- 数据项数(2->10)子图对比:
- 可以看到,对这个数据段来说:
- 如果数据项数只有2、3项,则太不平衡,无法展示出数据的多样性和复杂性;
- 数据项数在4->7项是比较合理的,既能展示出数据的细节、又不会太过臃肿和冗余;
- 数据项数大于7之后就不适合了,因为饼图分得太多区块反而不利于数据分析,显得太过臃肿。
三、地图
3、 作业三
(1) 作业要求
在中国地图上展示每个省的高考人数或大学数量
(2) 作业分析与代码实现
- 同作业二,我选择各省的高考人数进行分析,文件:“中国大学数量.csv”;
- 在作业二中的打印已经让我对其中的数据有些印象,特别是2016年没有索引的数据,首先考虑如何获得2016年的数据,这里可以使用pandas函数iloc进行按列取数:
"""iloc:基于行索引和列索引(index,columns)都是从 0 开始"""
# iloc先行后列,中间用逗号(,)分割,例如取 a 和 A 对应的数据
frame.iloc[0,0]
# 取前两行对应数据
frame.iloc[0:2,:]
# 取前两列对应数据
frame.iloc[:,0:2]
- 同时注意,取出来的数据还是以“万”结尾的字符串,所以要对其进行预处理去除“万”同时转为float;
- 得到高考人数后,接下来就是比较简单的绘图了,从pyecharts引入options包和map包,用于绘制中国地图;
- 对着老师的代码照虎画猫(●ˇ∀ˇ●),贴一下核心代码:
def map_visualmap() -> map:
global i
c = (
Map()
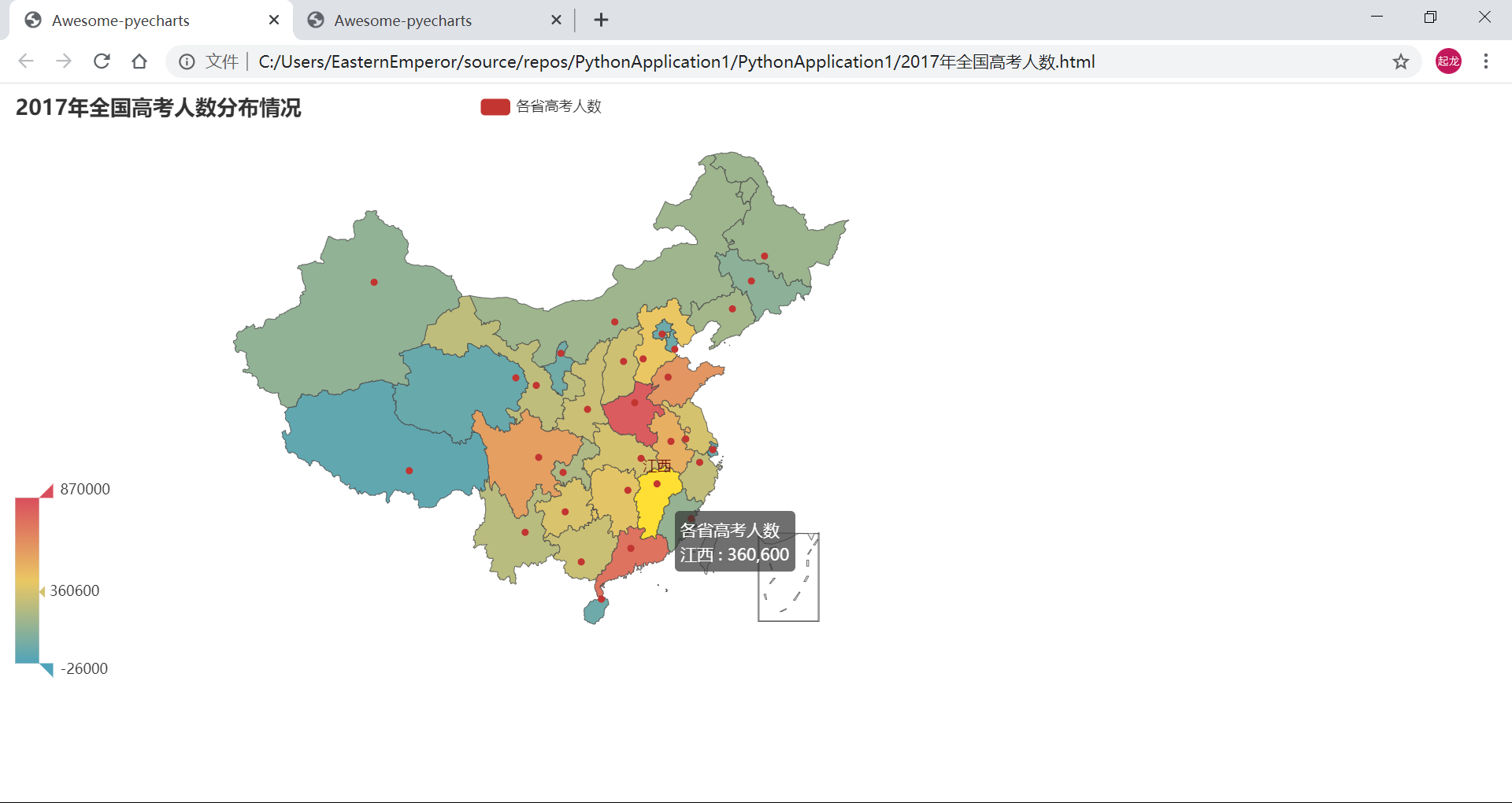
.add("各省高考人数", [list(z) for z in zip(province, people[i])], "china")
.set_global_opts(
title_opts = opts.TitleOpts(title = "Map-VisualMap(连续型)"),
visualmap_opts = opts.VisualMapOpts(min_ = min(people[i]) - 50000, max_ = max(people[i]) + 50000))
.set_series_opts(label_opts = opts.LabelOpts(is_show = False))
)
return c
- 通过以上思路,可得最终代码如下:
""" 数据可视化:地图1"""
import pandas as pd
import numpy as np
from pyecharts import options as opts
from pyecharts.charts import Map
import random
# 读取中国大学数量csv文件,用其中的2017、2016年高考人数制作饼图
people = []
df = pd.read_csv('中国大学数量.csv', encoding = 'utf-8')
people.append(df.高考人数.tolist())
people[0].pop(0) # 第一个元素是'2017年',删除
people.append(df.iloc[: , 2].tolist())
people[1].pop(0) # 第一个元素是'2016年',删除
province = df.iloc[: , 0].tolist()
province.pop(0) # 第一个元素是'省/市',删除
for j in range(2):
"""将读出数据转换为float"""
for i in range(len(people[j])):
"""此时ls中的数据均以万为单位,所以要删除'万'字符"""
people[j][i] = float(people[j][i].replace('万', ''))
people[j][i] = people[j][i] * 10000
def map_visualmap() -> map:
global i
c = (
Map()
.add("各省高考人数", [list(z) for z in zip(province, people[i])], "china")
.set_global_opts(
title_opts = opts.TitleOpts(title = str(i + 2016) + "年全国高考人数分布情况"),
visualmap_opts = opts.VisualMapOpts(min_ = min(people[i]) - 50000, max_ = max(people[i]) + 50000))
.set_series_opts(label_opts = opts.LabelOpts(is_show = False))
)
return c
for i in range(2):
map_visualmap().render(str(i + 2016) + "年全国高考人数" + ".html")
print('Done!')
(3) 效果演示
- 2016年:
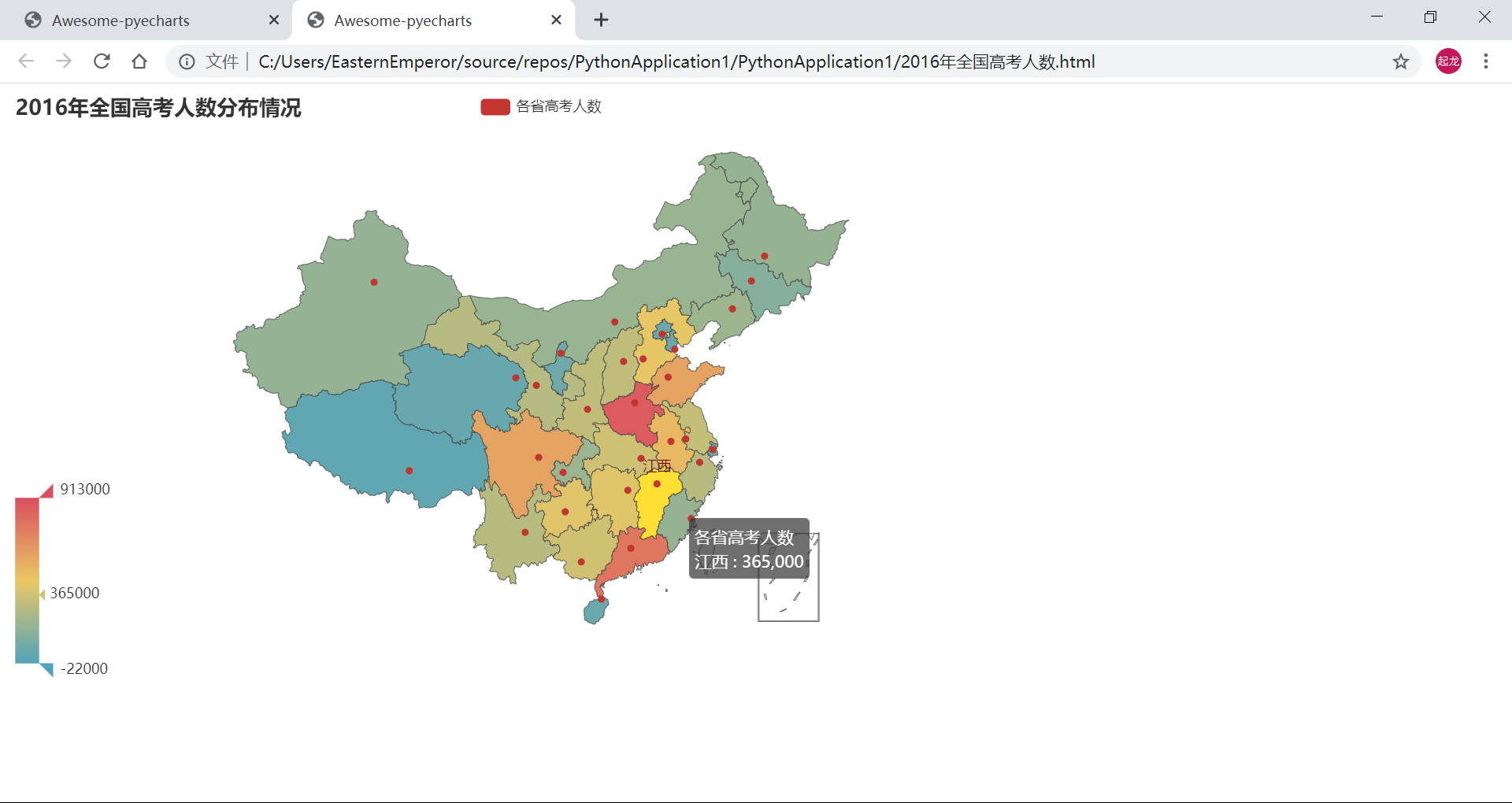
- 2017年:
4、作业四
(1) 作业要求
展示自己家乡所在城市的温度变化热力图,要求至少有10天的数据。
(2) 作业分析及代码实现
- 所谓题目越短,难度越大。这题我觉得是7题中最难的题,包罗了爬虫、数据处理、数据可视化、地理历史等等知识点(诶好像混进去一个不对劲的东西);
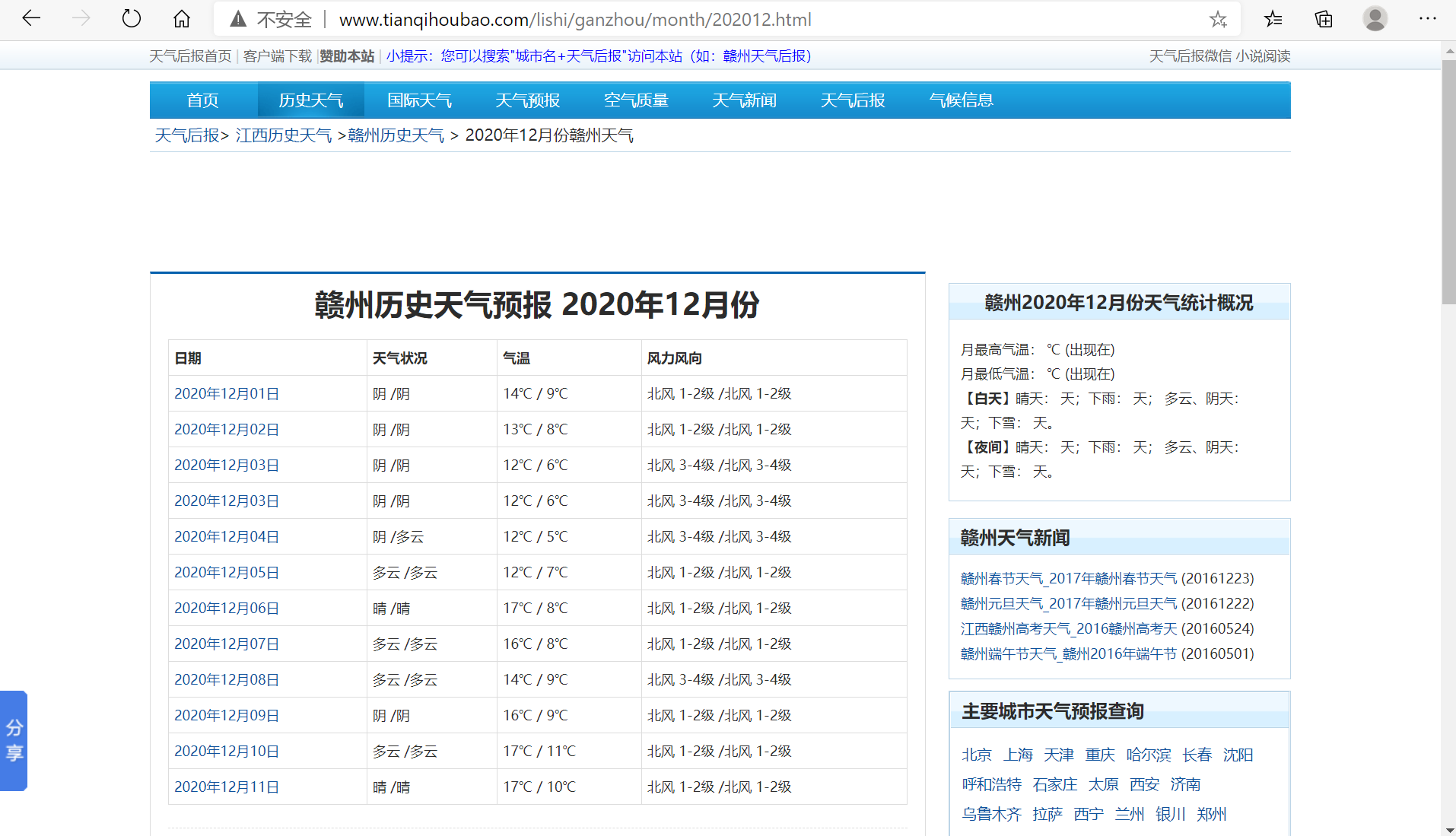
- 这里先展示一下我要爬取的网站:http://www.tianqihoubao.com/lishi/ganzhou/month/202012.html:
- 查询过赣州市行政区划再开始动手(没错,我到现在才知道赣州市完整的行政区划),查看网页源代码:
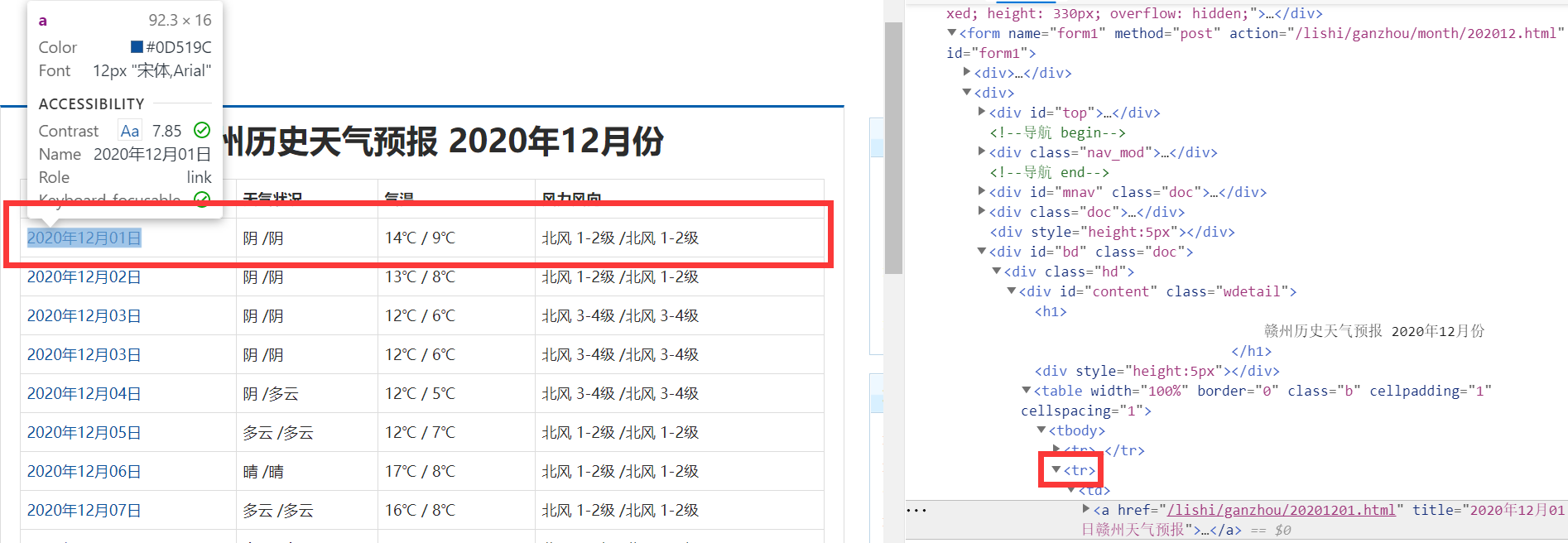
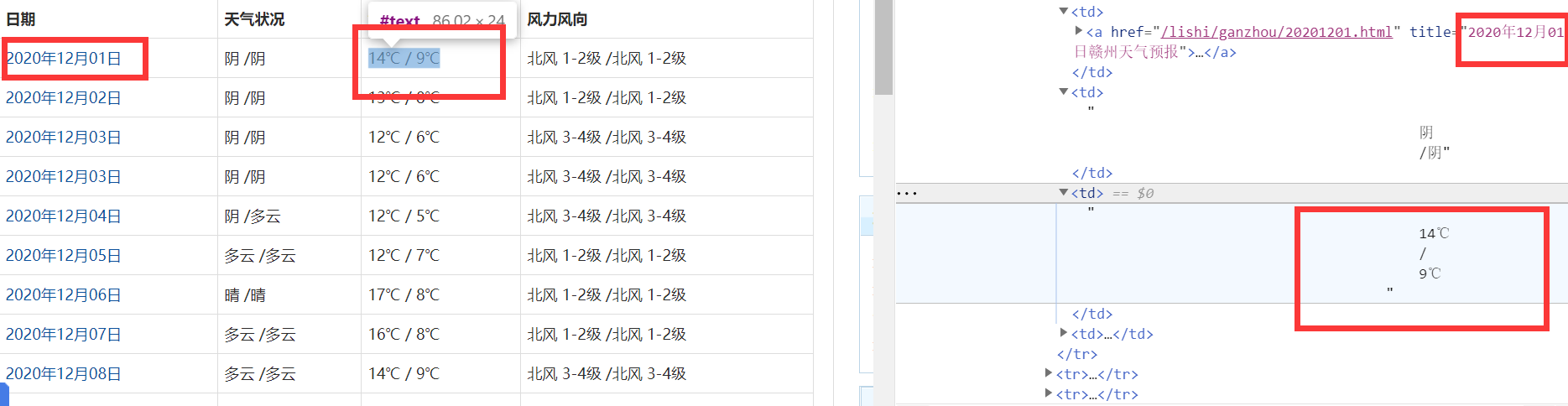
- 了解到该网页把日期和气温都保存在
<tr>下,这里直接通过接口爬取整个页面中的<tr>数据(也只有这一个表格),再从中挑选出我们需要的日期和气温,核心代码如下:
#数据提取
soup = BeautifulSoup(html, 'html.parser')
tr_list = soup.find_all('tr')
dates, temp = [], []
for data in tr_list[1:]:
sub_data = data.text.split()
dates.append(sub_data[0])
temp.append(''.join(sub_data[3:6])) # 气温被split分成三块,下标3:5
- 爬取赣州市17个区县从12月1日到12月10日的天气情况,分别储存在csv文件中,方便后续处理;
- 得到数据接着还要对其进行处理,因为气温不是我们要的格式,去除"℃"符号,得到当日最高温highs和最低温lows,取平均温度mid = (highs + lows) / 2作为绘图数据;
- 这里由于要陆续处理并绘制17个区县,所以定义了两个函数,简化代码方便运行:processing和geo_ganzhou;
- 生成png图片的代码和老师的大同小异,主要是使用到snapshot_phantomjs库里的snapshot函数,并不困难;麻烦的是配置环境,因为光是导入snapshot_phantomjs包还不够,得下载辅助运行的phantomjs.exe文件,该文件较大,并且还有可能出现不适配的情况(所幸我没遇到);下载完毕后将phantomjs.exe复制或剪切到存放python项目代码的目录下即可;
- 最后就是将生成的十张图片组合成gif了,要引入新的库:imageio,使用其中的imread和mimsave函数,可以很方便的绘制出gif图;
- 最终,综合上述,编写代码如下:
a、爬虫文件:homeWeather.py
"""爬虫:爬取天气数据"""
import requests
import pandas as pd
from bs4 import BeautifulSoup
def mySpider(position):
#目标url
url = 'http://www.tianqihoubao.com/lishi/{}/month/202012.html'.format(position)
#获取网页源代码
resp = requests.get(url)
html = resp.content.decode('gbk')
#数据提取
soup = BeautifulSoup(html, 'html.parser')
tr_list = soup.find_all('tr')
dates, temp = [],[]
for data in tr_list[1:]:
sub_data = data.text.split()
dates.append(sub_data[0])
temp.append(''.join(sub_data[3:6])) # 气温被split分成三块,下标3:5
_data = pd.DataFrame()
_data['日期'] = dates
_data['气温'] = temp
_data.to_csv('{}.csv'.format(position), index = False, encoding = 'gbk') #去掉索引以及避免乱码
ganzhou = ['ganzhou', 'nankang', 'jxxinfeng', 'dayu', 'shangyou', 'chongyi',
'anyuan', 'jxlongnan', 'dingnan', 'quannan', 'ningdu', 'yudu', 'xingguo',
'huichang', 'xunwu', 'shicheng', 'ruijin']
for i in range(len(ganzhou)):
mySpider(ganzhou[i])
print('%s Compelte!' % ganzhou[i])
b、数据处理+数据可视化生成png文件:weatherMap.py
""" 数据可视化:地图2"""
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.globals import ChartType
import random
from pyecharts.render import make_snapshot
from snapshot_phantomjs import snapshot
import csv
import pandas as pd
import numpy as np
Ganzhou = ["赣州市区", "南康区", "信丰县", "大余县", "上犹县", "崇义县", "安远县",
"龙南市", "定南县", "全南县", "宁都县", "于都县", "兴国县", "会昌县", "寻乌县", "石城县", "瑞金市"]
ganzhou = ['ganzhou', 'nankang', 'jxxinfeng', 'dayu', 'shangyou', 'chongyi',
'anyuan', 'jxlongnan', 'dingnan', 'quannan', 'ningdu', 'yudu', 'xingguo',
'huichang', 'xunwu', 'shicheng', 'ruijin']
# 创建字典对象存储天气
weather = {}
for i in range(len(ganzhou)):
df = pd.read_csv('{}.csv'.format(ganzhou[i]), encoding = 'gbk')
weather[ganzhou[i]] = df
def processing(data):
""" 取出温度数据 """
#数据处理
data['最高气温'] = data['气温'].str.split('/',expand=True)[0]
data['最低气温'] = data['气温'].str.split('/',expand=True)[1]
data['最高气温'] = data['最高气温'].map(lambda x:int(x.replace('℃','')))
data['最低气温'] = data['最低气温'].map(lambda x:int(x.replace('℃','')))
dates = data['日期']
highs = data['最高气温']
lows = data['最低气温']
print(dates)
print(highs)
print(lows)
mid = (highs + lows) / 2 # 取平均气温
print('%s temprature:' % (ganzhou[i]))
print('平均气温\n', mid)
return mid
temp = []
for i in range(len(ganzhou)):
""" csv数据存储到temp列表中 """
data = weather[ganzhou[i]]
temp.append(processing(data).tolist())
dayTemp = []
for i in range(len(temp[0])):
""" 将每天每个城市的气温放到一个列表 """
everyTemp = [] # 第i天每个城市的温度
for j in range(len(ganzhou)):
everyTemp.append(temp[j][i])
dayTemp.append(everyTemp) # 爬取的天数里每个城市的温度
def geo_ganzhou(title) -> Geo:
global i
c = (
Geo()
.add_schema(maptype = "赣州")
.add(
title,
[list(z) for z in zip(Ganzhou, dayTemp[i])],
type_=ChartType.HEATMAP,
)
.set_global_opts(
visualmap_opts = opts.VisualMapOpts(min_ = 0, max_ = max(temp[i]) + 5),
title_opts = opts.TitleOpts(title = "江西省赣州市12月份各区县温度变化情况"), )
)
return c
for i in range(10):
str_date="12月" + str(i + 1) + "日"
print(str_date)
make_snapshot(snapshot, geo_ganzhou(str_date).render(),
str(i + 1) + ".png", pixel_ratio = 1)
print('Done!')
c、生成gif图片文件:toGIF.py
"""生成gif"""
import imageio
outfilename = "ThermalChange.gif" # 转化的GIF图片名称
filenames = []
for i in range(1, 11):
""" 加入图片 """
filename = '{}.png'.format(str(i))
filenames.append(filename)
gif_images = []
for pic in filenames:
gif_images.append(imageio.imread(pic))
imageio.mimsave("test.gif", gif_images, fps = 1) # fps越小图片变换越慢
(3) 效果演示
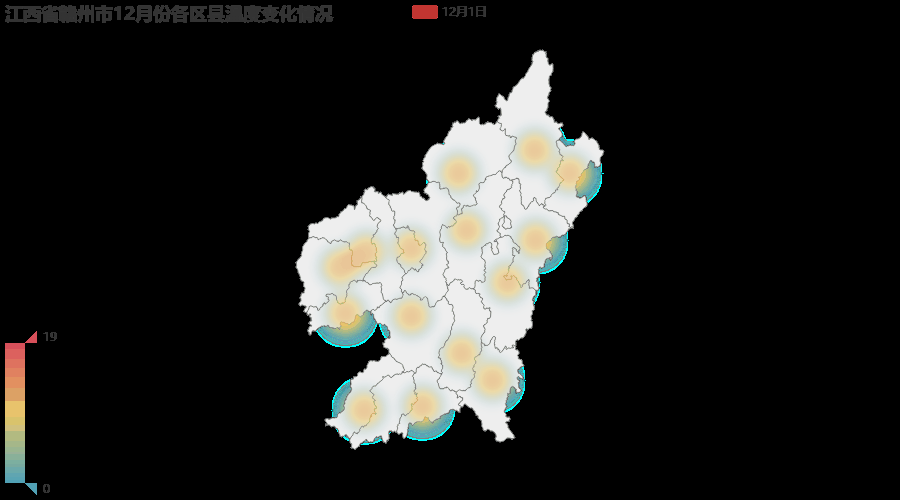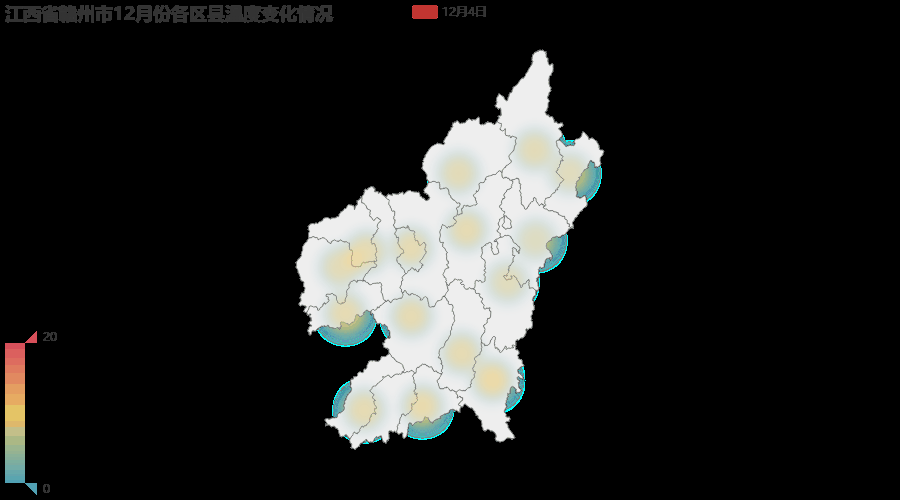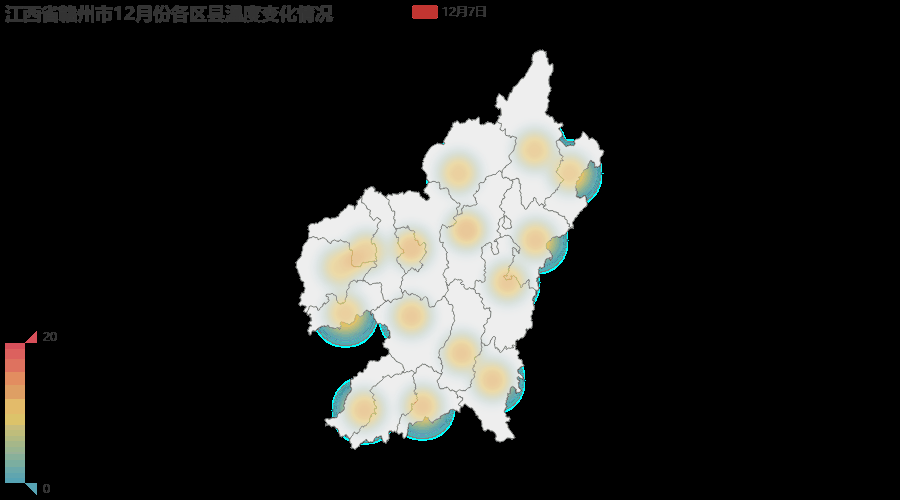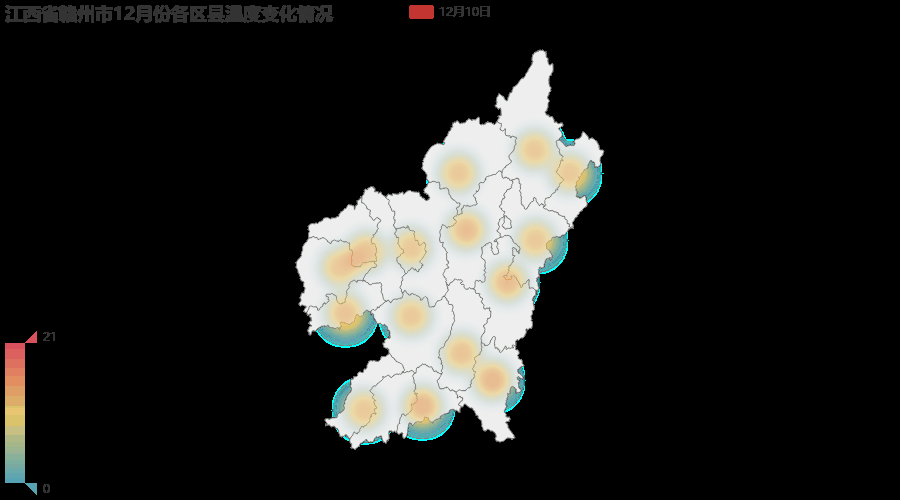
注:由于12月1日到12月10日赣州地区气温变化并不大,所以gif图变化效果并不明显,得仔细看才能看到变动的地方。
四、3D绘图
5、作业五
(1) 作业要求
生成一个直方图,有25根直方柱。要求直方柱的最小值是1,最大值是25,要求沿着边缘,从外到内逐步增大
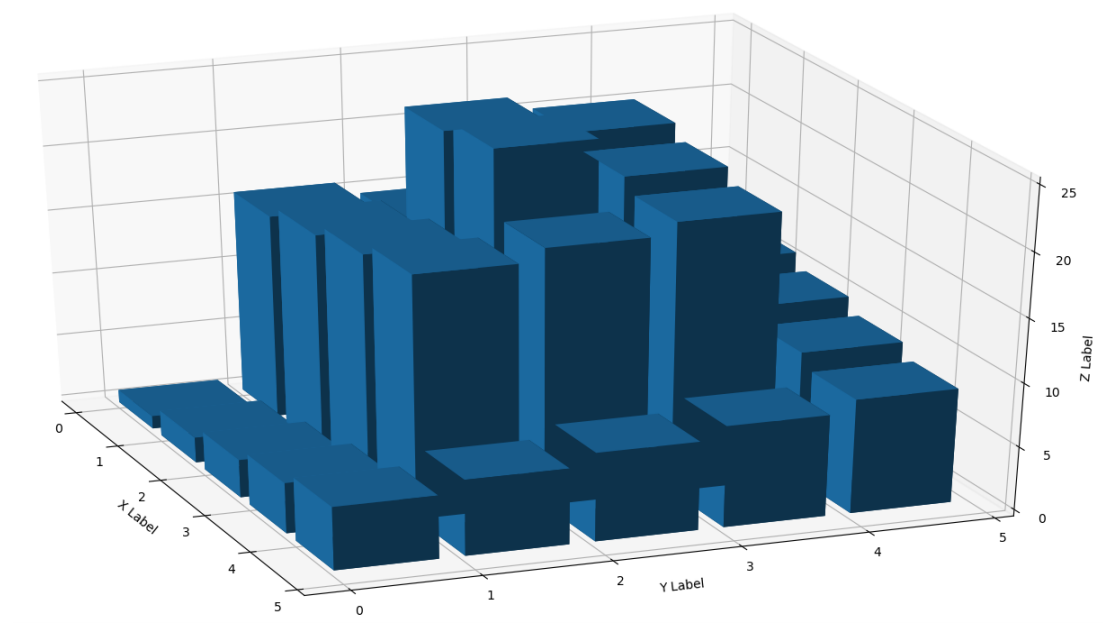
(2) 作业分析及代码实现
- 本题比较简单,算是熟练一下3D绘图工具吧,基本模板:
# meshgrid把X和Y变成平方长度,比如原来都是5,经过meshgrid和ravel之后,长度都变成了25,因为网格点是25个
xx, yy = np.meshgrid(X, Y) # 网格化坐标
X, Y = xx.ravel(), yy.ravel() # 矩阵扁平化
# 设置柱子Z属性
Z = Z.ravel() # 矩阵扁平化,即将二维Z转化为一维
bottom = np.zeros_like(Z) # 新建全0数组,shape和Z相同,即图中底部的位置
# width, depth, bottom
ax.bar3d(X, Y, bottom, width, depth, Z, color = c, shade = True)
- 这里有一点,刚开始我想直接导入mpl_toolkits包,但是提示没有合适的该包,百度了一下找到解决办法,即:
pip install --upgrade matplotlib
- 主要是实现要求:柱高要沿着边缘,从外到内逐步增大,Z坐标如图:
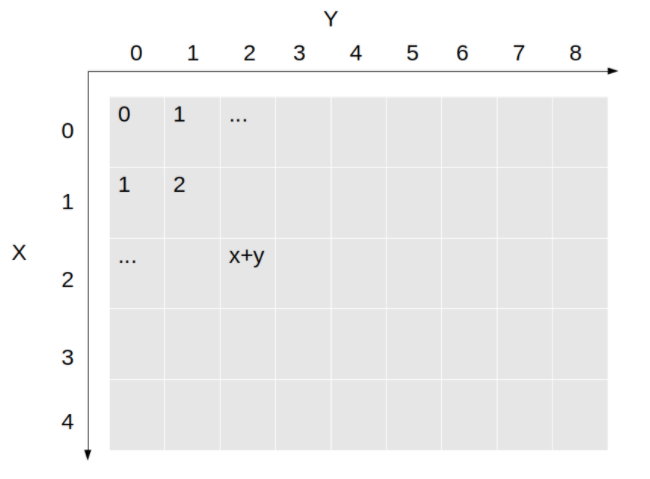
- 这里我没有想到简便的方法,所以直接按照坐标给Z赋值来实现效果了:
Z = np.zeros(shape = (5, 5))
Z[0] = [1, 2, 3, 4, 5]
Z[1] = [16, 17, 18, 19, 6]
Z[2] = [15, 24, 25, 20, 7]
Z[3] = [14, 23, 22, 21, 8]
Z[4] = [13, 12, 11, 10, 9]
- 综上所述,程序代码如下:
"""3D绘图:直方图"""
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 绘图设置
fig = plt.figure()
ax = fig.gca(projection = '3d') # 三维坐标轴
"""数据设置"""
# X和Y的个数要相同
X = np.arange(0, 5, step = 1) # X轴的坐标
Y = np.arange(0, 5, step = 1) # Y轴的坐标
Z = np.zeros(shape = (5, 5))
Z[0] = [1, 2, 3, 4, 5]
Z[1] = [16, 17, 18, 19, 6]
Z[2] = [15, 24, 25, 20, 7]
Z[3] = [14, 23, 22, 21, 8]
Z[4] = [13, 12, 11, 10, 9]
# meshgrid把X和Y变成平方长度,比如原来都是5,经过meshgrid和ravel之后,长度都变成了25,因为网格点是25个
xx, yy = np.meshgrid(X, Y) # 网格化坐标
X, Y = xx.ravel(), yy.ravel() # 矩阵扁平化
# 设置柱子属性
Z = Z.ravel() # 矩阵扁平化,即将二维Z转化为一维
bottom = np.zeros_like(Z) # 新建全0数组,shape和Z相同,即图中底部的位置
width = depth = 0.8 # 柱子的长和宽
# 坐标轴设置
c = ['b'] * len(Z) # 颜色数组,长度和Z一致
# 开始画图:本来的顺序是X, Y, Z, width, depth, bottom,但是那样会导致不能形成柱子,只有柱子顶端薄片,所以Z和bottom要互换
ax.bar3d(X, Y, bottom, width, depth, Z, color = c, shade = True) # width, depth, bottom
ax.set_xlabel('XLabel')
ax.set_ylabel('YLabel')
ax.set_zlabel('ZLabel')
plt.show()
(3) 效果演示
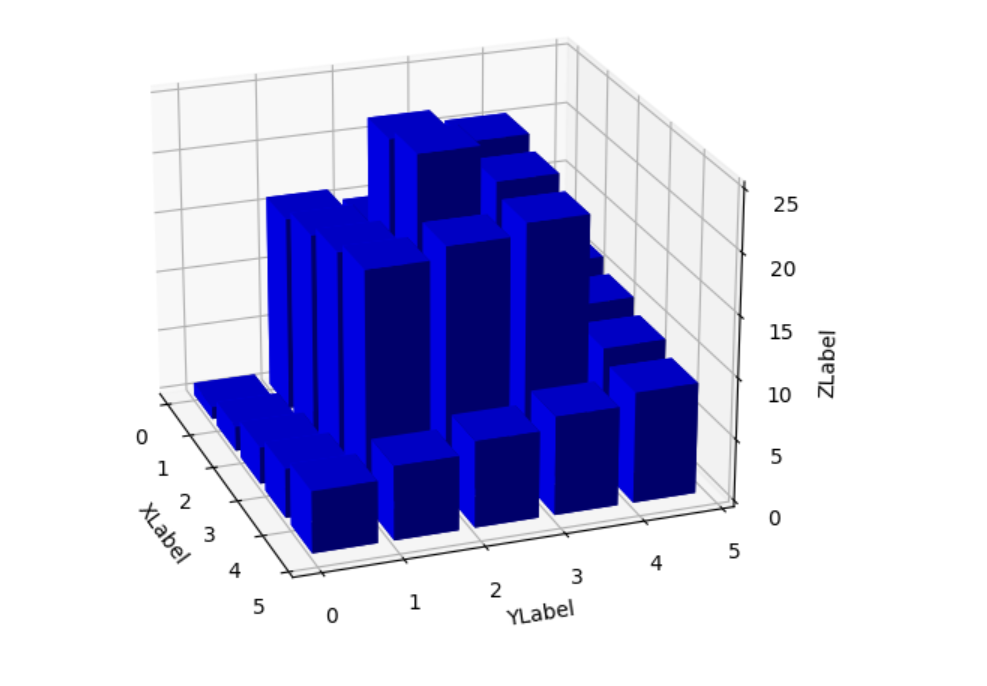
怎么说呢,感觉效果总比老师的差一点
6、作业六
(1) 作业要求
- 生成一个金字塔的线图
- 生成一上一下两个金字塔,叠放在一起

(2) 作业分析及代码实现
- 这题不难,只是有点繁琐,要对照每根线构造X、Y和Z的关系;譬如左边子图,共8条线段,每条线段的表达式都不一样,所以要分开画;
- 右边子图是左边子图叠放在左边子图的倒置图上,所以只要找到左边子图8条线段的表达式,右边子图的绘制也迎刃而解(改成负的就行了);
- 综上,实现代码如下:
"""3D绘图:线图"""
import numpy as np
import matplotlib.pyplot as plt
import math
from mpl_toolkits.mplot3d import Axes3D
# 1.生成fig对象和ax对象
fig = plt.figure()
ax1 = fig.add_subplot(121, projection = '3d')
ax2 = fig.add_subplot(122, projection = '3d')
ax1.set_xlabel('X Label')
ax1.set_ylabel('Y Label')
ax1.set_zlabel('Z Label')
ax2.set_xlabel('X Label')
ax2.set_ylabel('Y Label')
ax2.set_zlabel('Z Label')
# 2.生成数据
""" 子图1:金字塔的数据 """
x1 = np.arange(-1, 1.1, step = 0.25) # 生成x轴的数据
y1 = np.arange(-1, 1.1, step = 0.25) # 生成y轴的数据
z1 = 0
x2 = np.arange(-1, 0.1, step = 0.25)
z2 = x2 + 1
x3 = np.arange(-1, 0.1, step = 0.25)
z3 = x2 + 1
y4 = np.arange(-1, 0.1, step = 0.25)
z4 = y4 + 1
y5 = np.arange(0, 1.1, step = 0.25)
z5 = -y5 + 1
# 3.调用plot,画3D的线图
""" 子图1:金字塔 """
# 底
ax1.plot(np.array([-1 for x in range(9)]), y1, z1, "r")
ax1.plot(np.array([1 for x in range(9)]), y1, z1, "r")
ax1.plot(x1, np.array([-1 for x in range(9)]), z1, "r")
ax1.plot(x1, np.array([1 for x in range(9)]), z1, "r")
# 侧边
ax1.plot(x2, np.arange(-1, 0.1, step = 0.25), z2, "r")
ax1.plot(x3, np.arange(0, 1.1, step = 0.25)[::-1], z3, "r")
ax1.plot(np.arange(0, 1.1, step = 0.25)[::-1], y4, z4, "r")
ax1.plot(np.arange(0, 1.1, step = 0.25), y5, z5, "r")
""" 子图2:叠放金字塔 """
""" 上半部与子图1相同 """
# 底
ax2.plot(np.array([-1 for x in range(9)]), y1, z1, "r")
ax2.plot(np.array([1 for x in range(9)]), y1, z1, "r")
ax2.plot(x1, np.array([-1 for x in range(9)]), z1, "r")
ax2.plot(x1, np.array([1 for x in range(9)]), z1, "r")
# 侧边
ax2.plot(x2, np.arange(-1, 0.1, step = 0.25), z2, "r")
ax2.plot(x3, np.arange(0, 1.1, step = 0.25)[::-1], z3, "r")
ax2.plot(np.arange(0, 1.1, step = 0.25)[::-1], y4, z4, "r")
ax2.plot(np.arange(0, 1.1, step = 0.25), y5, z5, "r")
""" 下半部 """
x6 = np.arange(-1, 0.1, step = 0.25)
z6 = -x2 - 1
x7 = np.arange(-1, 0.1, step = 0.25)
z7 = -x2 - 1
y8 = np.arange(-1, 0.1, step = 0.25)
z8 = -y4 - 1
y9 = np.arange(0, 1.1, step = 0.25)
z9 = y5 - 1
# 侧边
ax2.plot(x6, np.arange(-1, 0.1, step = 0.25), z6, "b")
ax2.plot(x7, np.arange(0, 1.1, step = 0.25)[::-1], z7, "b")
ax2.plot(np.arange(0, 1.1, step = 0.25)[::-1], y8, z8, "b")
ax2.plot(np.arange(0, 1.1, step = 0.25), y9, z9, "b")
# 4.显示图形
plt.show()
(3) 效果演示
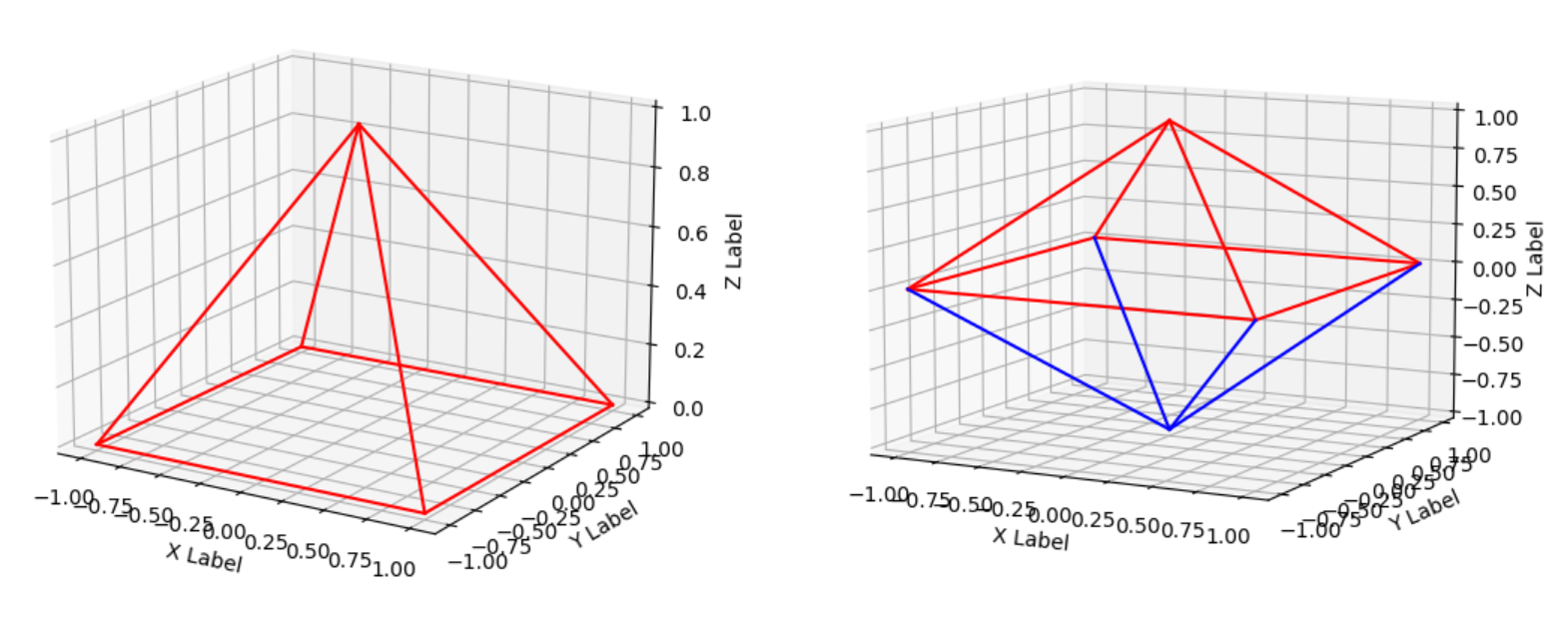
7、作业七
(1) 作业要求
生成一个散点图,如下图所示。z=x2+y2
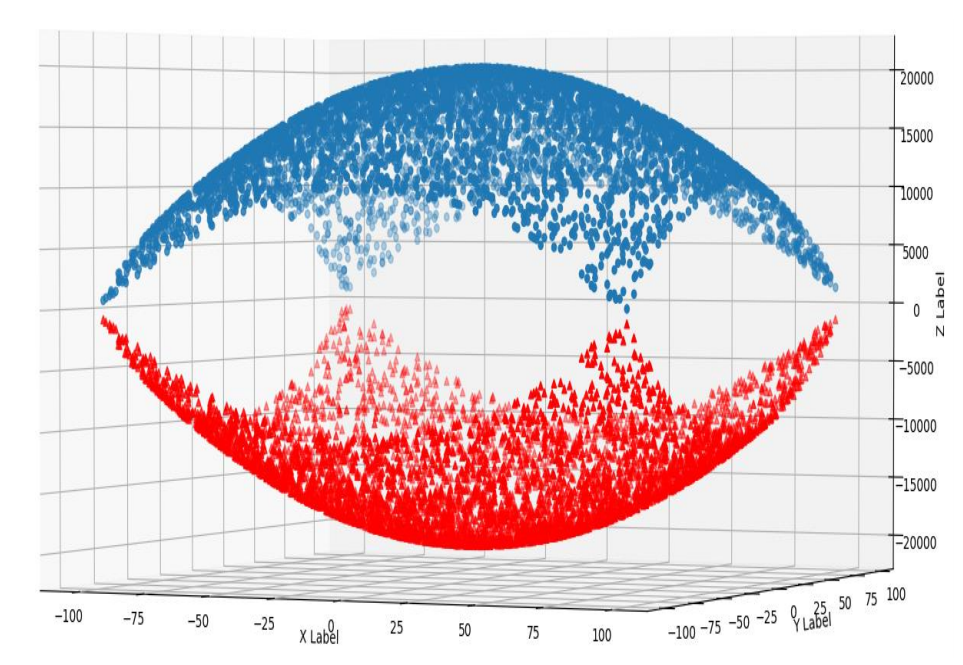
(2) 作业分析及代码实现
-
图中上下两个形状都是由f(x, y) = z=x2+y2变化而来;
-
上面的:f1(x, y) = - f(x, y) + 20000;
-
下面的:f2(x, y) = f(x, y) - 20000;
-
注意散点的大小、形状和数量:上圆点,下三角点;我这里设置了点大小s = 10;共生成了2000个点(太多没有例图的效果,例图真的好看)
-
由上述,可编写代码如下:
""" 3D绘图:散点图 """
import numpy as np
import matplotlib.pyplot as plt
import math
from mpl_toolkits.mplot3d import Axes3D
# 1.生成fig对象和ax对象
fig = plt.figure()
ax = fig.add_subplot(projection = '3d')
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
# 2.生成数据
# 3.调用scatter,画3D散点图
x1 = np.random.randint(-100, 100, 2000) # x轴,生成2000个在-100到100之间的整数
y1 = np.random.randint(-100, 100, 2000) # y轴,生成2000个在-100到100之间的整数
z1 = -x1 ** 2 - y1 ** 2 + 20000 # 生成z轴的数据
ax.scatter(x1, y1, z1, zdir = 'z', s = 10, c = 'b', marker = 'o',depthshade = True)
x2=np.random.randint(-100, 100, 2000) # x轴,生成2000个在-100到100之间的整数
y2=np.random.randint(-100, 100, 2000) # y轴,生成2000个在-100到100之间的整数
z2 = x2 ** 2 + y2 ** 2 - 20000 # 生成z轴的数据
ax.scatter(x2, y2, z2, zdir = 'z', s = 10, c = 'r', marker = '^',depthshade = True)
#4.显示图形
plt.show()
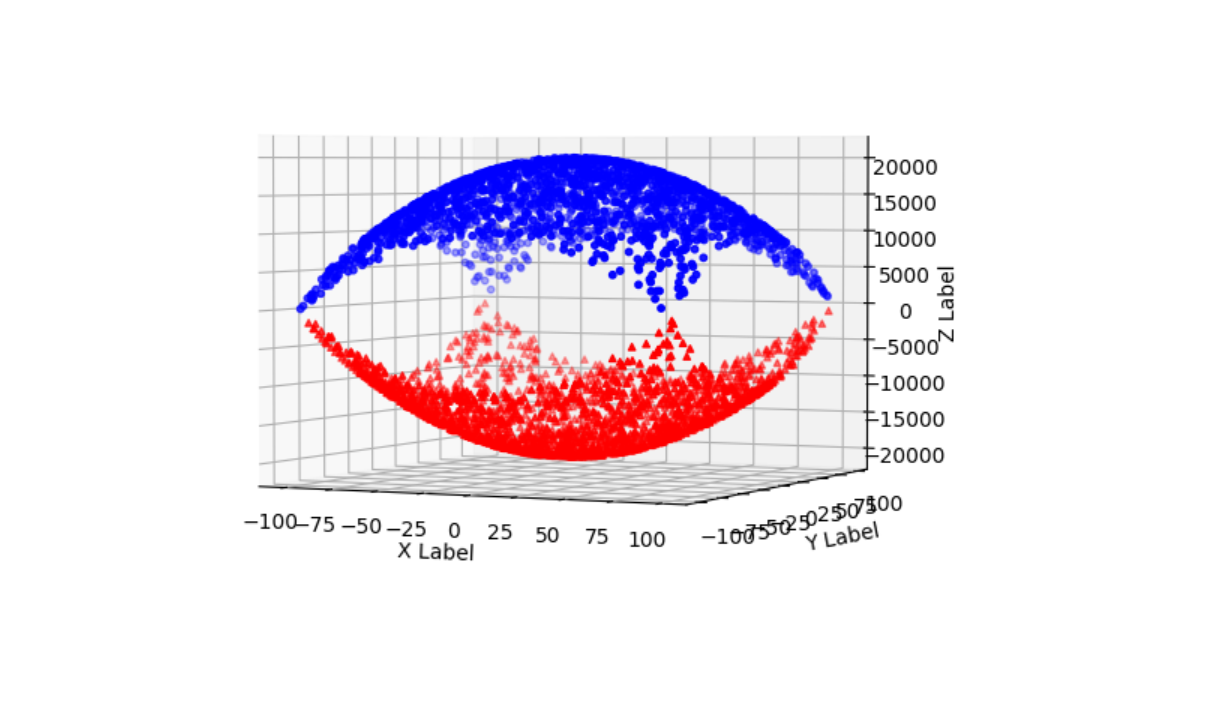
(3) 效果演示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号