
Python作业2:scrapy爬取链家+数据预处理
Python作业2:scrapy爬取链家+数据预处理
一、爬取数据并预处理
1、要求
作业1:通过爬虫爬取链家的新房数据,并进行预处理。
-
最终的csv文件,应包括以下字段:名称,地理位置(3个字段分别存储),房型(只保留最小房型),面积(按照最小值),总价(万元,整数),均价(万元,保留小数点后4位);
-
对于所有字符串字段,要求去掉所有的前后空格;
-
如果有缺失数据,不用填充。
-
找出总价最贵和最便宜的房子,以及总价的中位数
-
找出单价最贵和最便宜的房子,以及单价的中位数
2、实验过程
准备阶段
- 通过查看网页源代码,找出页面对应元素所在的结构xpath,作为爬虫爬取数据的入口。如下图:
- xpath可以直接复制得到,如下图:
- 由[2],同上一次作业,我们需要爬取的元素有:名称,地理位置(3个字段分别存储),房型(只保留最小房型),面积(按照最小值),总价(万元,整数),均价(万元,保留小数点后4位)
代码编写
- item.py:
import scrapy
class NewhouseItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
name = scrapy.Field() # 名称
location1 = scrapy.Field() # 地址1
location2 = scrapy.Field() # 地址2
locationDetail = scrapy.Field() # 详细地址
houseType = scrapy.Field() # 房型
area = scrapy.Field() # 面积(取最小值)
TTprice = scrapy.Field() # 总价
averagePrice = scrapy.Field() # 均价
- setting.py只需加入下面一句:
ITEM_PIPELINES =
- 最后是spider.py,我将新房页面19页的数据都爬取下来,因为要从其中最贵和最便宜的等待;由于要进行之后的数据分析,所以这里我尽量将面积、总价和单价作为仅有数字的字符串保存而非列表:
import scrapy
from newHouse.items import NewhouseItem
import csv
import re
class MySpider(scrapy.Spider):
name = 'newHouse'
allowed_domains = ['bj.lianjia.com']
start_urls = ['https://bj.fang.lianjia.com/loupan/']
start_urls = []
for page in range(1, 19):
"""爬取19页数据"""
url = 'https://bj.fang.lianjia.com/loupan/pg{}'.format(page)
start_urls.append(url)
def parse(self, response):
item = NewhouseItem()
for each in response.xpath("//div[4]/ul[2]/*"):
"""爬取该路径下的房区信息"""
"""楼盘名称"""
item['name'] = each.xpath("./div[1]/div[1]/a[1]/text()").extract()
"""楼盘地理位置,分三段"""
item['location1'] = each.xpath("./div[1]/div[2]/span[1]/text()").extract()
item['location2'] = each.xpath("./div[1]/div[2]/span[2]/text()").extract()
item['locationDetail'] = each.xpath("./div[1]/div[2]/a[1]/text()").extract()
"""楼盘房型(取最小房型)"""
item['houseType'] = each.xpath("./div[1]/a[1]/span[1]/text()").extract()
"""楼盘面积(取最小值)"""
Area = each.xpath("./div[1]/div[3]/span/text()").extract()[0].split('-')[0].split()[1]
number = ''
for i in str(Area):
"""取出其中的数字"""
if i.isdigit():
number += i
item['area'] = number
"""楼盘均价"""
item['averagePrice'] = float(each.xpath("./div[1]/div[6]/div[1]/span[1]/text()").extract()[0]) / 10000
"""楼盘总价"""
ttprice = each.xpath("./div[1]/div[6]/div[2]/text()").extract()
number = ''
for i in str(ttprice):
"""取出其中的数字"""
if i.isdigit():
number += i
item['TTprice'] = number
if (item['name'] and item['area'] and item['TTprice'] and item['averagePrice']):
"""去除空值"""
yield(item) # 将item返回到pipeline模块
else:
print('-----------ERROR-------------', item['name'])
3、爬取结果
19页数据,共190组左右

4、数据预处理
代码编写
使用pandas和numpy库函数,比较简单,源代码如下:
import numpy as np
import pandas as pd
filename = 'newHouse.csv' # 文件名
data_df = pd.read_csv(filename, encoding = 'utf-8', dtype = str)
# 去掉所有字符串的前后空行
data_df['name'] = data_df['name'].str.strip()
data_df['location1'] = data_df['location1'].str.strip()
data_df['location2'] = data_df['location2'].str.strip()
data_df['locationDetail'] = data_df['locationDetail'].str.strip()
data_df['houseType'] = data_df['houseType'].str.strip()
# 将面积和价格改为浮点型
data_df['TTprice/万元'] = data_df['TTprice/万元'].astype(np.float)
data_df['averagePrice/万元'] = data_df['averagePrice/万元'].astype(np.float)
data_df['area/m2'] = data_df['area/m2'].astype(np.float)
# 找出总价最贵和最便宜的房子,以及总价的中位数
print('总价最贵的房子:')
msg = data_df['TTprice/万元']
print(data_df.iloc[msg.idxmax()])
print('**********************************************************')
print('总价最便宜的房子:')
print(data_df.iloc[msg.idxmin()])
print('**********************************************************')
print('总价的中位数:')
print(msg.median())
print('**********************************************************')
print('\n----------------------------------------------------------\n')
# 找出单价最贵和最便宜的房子,以及单价的中位数
print('单价最贵的房子:')
msg = data_df['averagePrice/万元']
print(data_df.iloc[msg.idxmax()])
print('**********************************************************')
print('单价最便宜的房子:')
print(data_df.iloc[msg.idxmin()])
print('**********************************************************')
print('单价的中位数:')
print(msg.median())
print('**********************************************************\n')
预处理结果
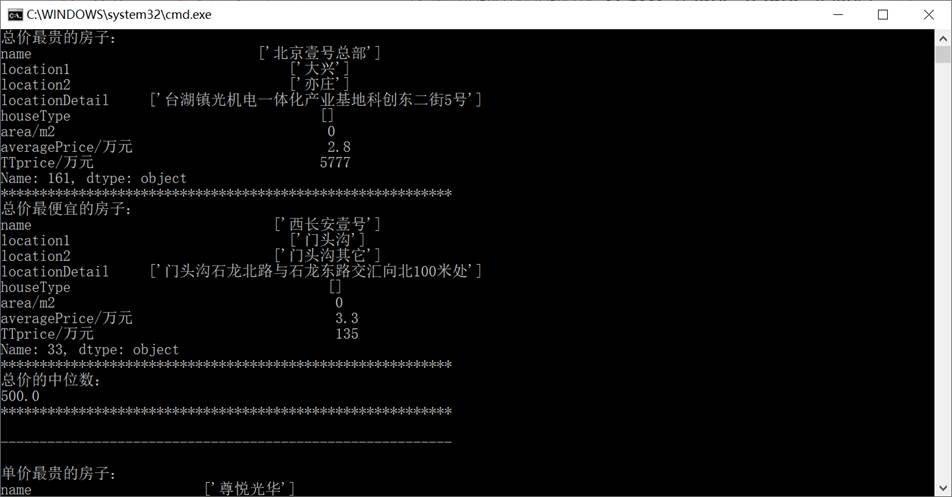
- 总价最贵和最便宜的房子,以及总价的中位数:
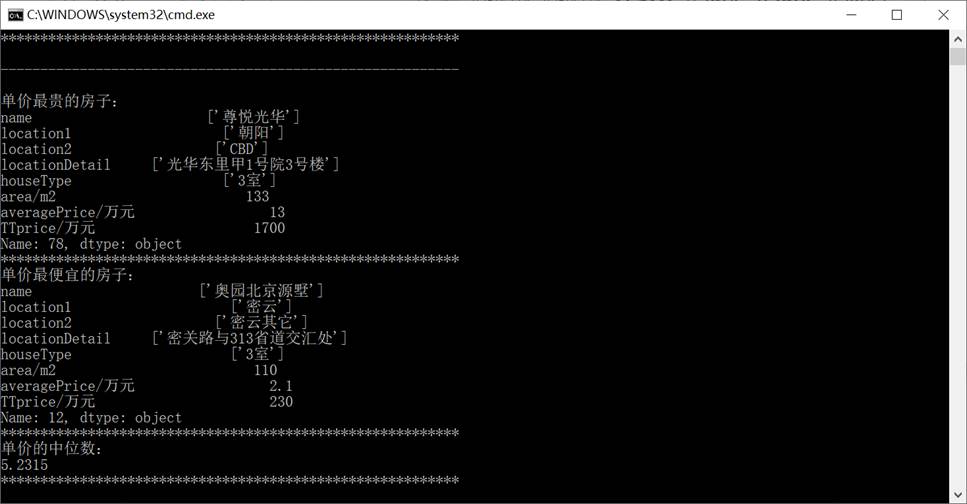
- 单价的最贵和最便宜的房子,以及单价的中位数:
二、计算北京空气质量数据
1、作业要求
作业2:计算北京空气质量数据
-
汇总计算PM指数年平均值的变化情况
-
汇总计算10-15年PM指数和温度月平均数据的变化情况
2、代码编写
使用numpy和pandas库函数可以很简单地实现本次作业的汇总,关键代码:
aveY_df = df.groupby('year').mean()
aveM_df = df.groupby(['year', 'month']).mean()
第一句是将数据按照年将其汇总;第二句是将数据按照[年,月]将其汇总。
所有代码如下:
import numpy as np
import pandas as pd
from pandas import DataFrame
# 读取文件
filename = 'BeijingPM20100101_20151231.csv'
df = pd.read_csv(filename, encoding = 'utf-8')
# 删除有空PM值的行
df.dropna(axis=0, how='all', subset=['PM_Dongsi','PM_Dongsihuan','PM_Nongzhanguan', 'PM_US Post'], inplace=True)
# 计算PM平均值
df['PMsum'] = df[['PM_Dongsi','PM_Dongsihuan','PM_Nongzhanguan', 'PM_US Post']].sum(axis=1)
df['PMcount'] = df[['PM_Dongsi','PM_Dongsihuan','PM_Nongzhanguan', 'PM_US Post']].count(axis=1)
df['PMave']=round(df['PMsum']/df['PMcount'],2)
aveY_df = df.groupby('year').mean()
aveM_df = df.groupby(['year', 'month']).mean()
# PM年平均值输出到文件
aveY_df.to_csv('PMyearAve.csv')
# PM和TEMP月平均值输出到文件
aveM_df.to_csv('PM_TEMP_monthAve.csv')
# 输出PM年平均值
print(df.groupby('year').mean())
print('------------------------------------------')
# 输出PM和TEMP月平均值
print(df.groupby(['year', 'month']).mean())
3、预处理结果:
PM按年分析

即如下:
|
year |
PMave |
|
2010 |
104.0457 |
|
2011 |
99.09324 |
|
2012 |
90.53877 |
|
2013 |
98.40268 |
|
2014 |
93.91771 |
|
2015 |
85.85894 |
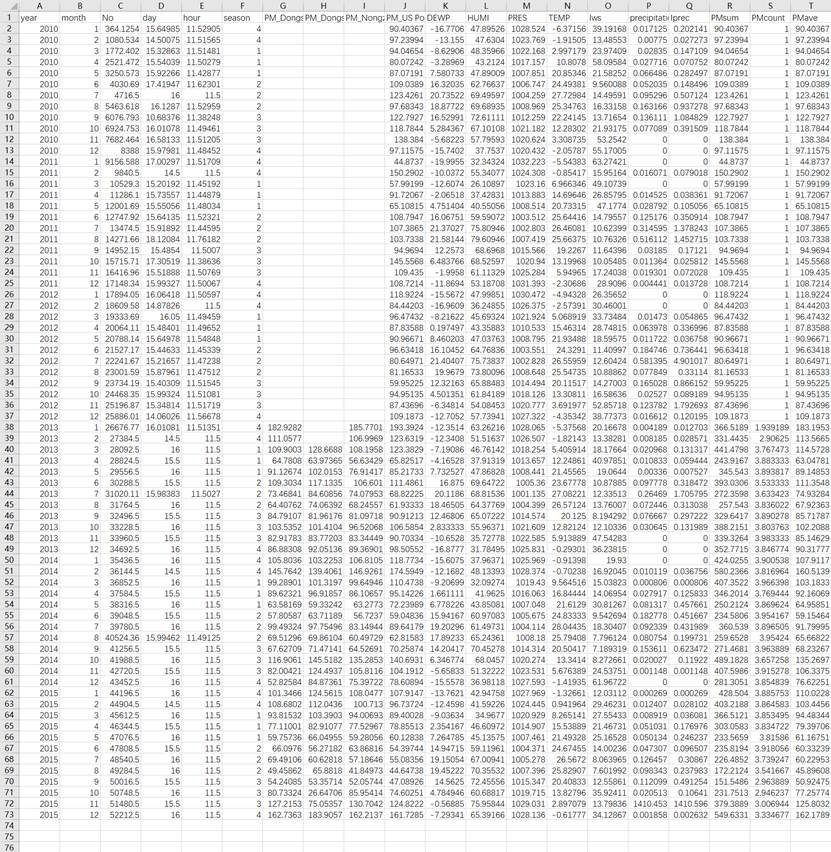
制表如下:
|
year |
month |
TEMP |
PMave |
|
2010 |
1 |
-6.37156 |
90.40367 |
|
2010 |
2 |
-1.91505 |
97.23994 |
|
2010 |
3 |
2.997179 |
94.04654 |
|
2010 |
4 |
10.8078 |
80.07242 |
|
2010 |
5 |
20.85346 |
87.07191 |
|
2010 |
6 |
24.49381 |
109.0389 |
|
2010 |
7 |
27.72984 |
123.4261 |
|
2010 |
8 |
25.34763 |
97.68343 |
|
2010 |
9 |
22.24145 |
122.7927 |
|
2010 |
10 |
12.28302 |
118.7844 |
|
2010 |
11 |
3.308735 |
138.384 |
|
2010 |
12 |
-2.05787 |
97.11575 |
|
2011 |
1 |
-5.54383 |
44.8737 |
|
2011 |
2 |
-0.85417 |
150.2902 |
|
2011 |
3 |
6.966346 |
57.99199 |
|
2011 |
4 |
14.69646 |
91.72067 |
|
2011 |
5 |
20.73315 |
65.10815 |
|
2011 |
6 |
25.64416 |
108.7947 |
|
2011 |
7 |
26.46081 |
107.3865 |
|
2011 |
8 |
25.66375 |
103.7338 |
|
2011 |
9 |
19.2267 |
94.9694 |
|
2011 |
10 |
13.19968 |
145.5568 |
|
2011 |
11 |
5.94965 |
109.435 |
|
2011 |
12 |
-2.30686 |
108.7214 |
|
2012 |
1 |
-4.94328 |
118.9224 |
|
2012 |
2 |
-2.57391 |
84.44203 |
|
2012 |
3 |
5.068919 |
96.47432 |
|
2012 |
4 |
15.46314 |
87.83588 |
|
2012 |
5 |
21.93488 |
90.96671 |
|
2012 |
6 |
24.3291 |
96.63418 |
|
2012 |
7 |
26.55959 |
80.64971 |
|
2012 |
8 |
25.54735 |
81.16533 |
|
2012 |
9 |
20.11517 |
59.95225 |
|
2012 |
10 |
13.30811 |
94.95135 |
|
2012 |
11 |
3.691977 |
87.43696 |
|
2012 |
12 |
-4.35342 |
109.1873 |
|
2013 |
1 |
-5.37568 |
183.1953 |
|
2013 |
2 |
-1.82143 |
113.5665 |
|
2013 |
3 |
5.405914 |
114.5728 |
|
2013 |
4 |
12.24861 |
63.04781 |
|
2013 |
5 |
21.45565 |
89.14853 |
|
2013 |
6 |
23.67778 |
111.3548 |
|
2013 |
7 |
27.08221 |
74.93284 |
|
2013 |
8 |
26.57124 |
67.92363 |
|
2013 |
9 |
20.125 |
85.71787 |
|
2013 |
10 |
12.82124 |
102.2088 |
|
2013 |
11 |
5.913889 |
85.14629 |
|
2013 |
12 |
-0.29301 |
90.31777 |
|
2014 |
1 |
-0.91398 |
107.9117 |
|
2014 |
2 |
-0.70238 |
160.5139 |
|
2014 |
3 |
9.564516 |
103.1833 |
|
2014 |
4 |
16.84444 |
92.16069 |
|
2014 |
5 |
21.6129 |
64.95851 |
|
2014 |
6 |
24.83333 |
59.15464 |
|
2014 |
7 |
28.04435 |
91.79995 |
|
2014 |
8 |
25.79408 |
65.66822 |
|
2014 |
9 |
20.50417 |
68.23267 |
|
2014 |
10 |
13.3414 |
135.2697 |
|
2014 |
11 |
5.676389 |
106.3375 |
|
2014 |
12 |
-1.41935 |
76.62251 |
|
2015 |
1 |
-1.32661 |
110.0228 |
|
2015 |
2 |
0.941964 |
103.4456 |
|
2015 |
3 |
8.265141 |
94.48344 |
|
2015 |
4 |
15.53889 |
79.39706 |
|
2015 |
5 |
21.49328 |
61.16751 |
|
2015 |
6 |
24.67455 |
60.33239 |
|
2015 |
7 |
26.5672 |
60.22953 |
|
2015 |
8 |
25.82907 |
45.89608 |
|
2015 |
9 |
20.40833 |
50.92475 |
|
2015 |
10 |
13.82796 |
77.25774 |
|
2015 |
11 |
2.897079 |
125.8032 |
|
2015 |
12 |
-0.61777 |
162.1789 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号