从“字符”到“实体”:藏文识别技术在档案内容挖掘中的融合应用
 随着信息技术飞速发展,档案管理工作正经历从实体保管向数字化、智能化的深刻变革。对于存有大量珍贵藏文历史文献的档案馆、图书馆及研究机构而言,如何高效、准确地将这些文化遗产转化为可检索、可分析的数字化资源,是一项紧迫而重要的任务。藏文识别技术的成熟与应用,为这一难题提供了关键性的解决方案。
随着信息技术飞速发展,档案管理工作正经历从实体保管向数字化、智能化的深刻变革。对于存有大量珍贵藏文历史文献的档案馆、图书馆及研究机构而言,如何高效、准确地将这些文化遗产转化为可检索、可分析的数字化资源,是一项紧迫而重要的任务。藏文识别技术的成熟与应用,为这一难题提供了关键性的解决方案。
随着信息技术飞速发展,档案管理工作正经历从实体保管向数字化、智能化的深刻变革。对于存有大量珍贵藏文历史文献的档案馆、图书馆及研究机构而言,如何高效、准确地将这些文化遗产转化为可检索、可分析的数字化资源,是一项紧迫而重要的任务。藏文识别技术的成熟与应用,为这一难题提供了关键性的解决方案。
背景与意义:为何要应用藏文识别技术?
- 文化遗产保护的迫切性:大量藏文档案,如经卷、典籍、历史文书、地方政府档案等,年代久远,材质脆弱,面临着物理损毁、字迹褪色的风险。数字化是永久保存这些文化遗产的唯一途径。
- 提升管理效率与利用价值:传统的档案查阅完全依赖人工,效率低下,且容易对原件造成二次损害。数字化后,档案内容可实现全文检索,极大提升查阅速度和研究的深度与广度。
- 深入挖掘与知识发现:沉睡在档案中的信息是研究历史、宗教、语言、社会经济的宝贵资料。通过识别技术将其转化为结构化数据,可以利用大数据分析、数据可视化等手段,发现隐藏的知识关联和规律。
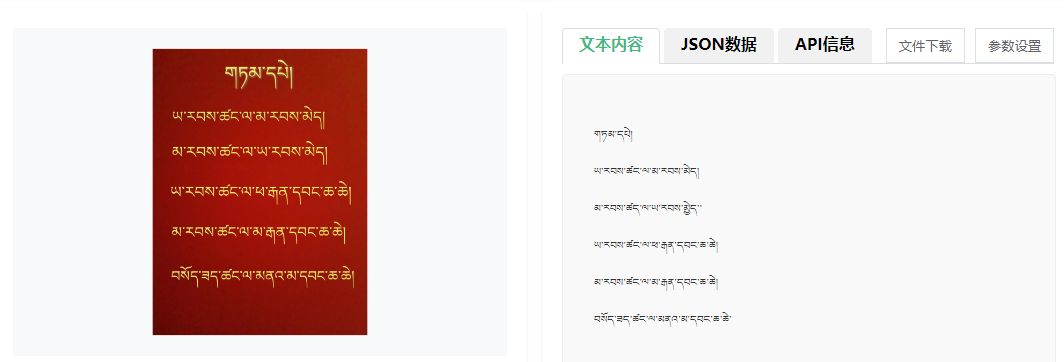
核心技术:藏文识别(OCR)技术简介
藏文识别属于复杂文字识别范畴,其主要技术流程包括:
1.图像预处理:
- 降噪与二值化:清除扫描过程中产生的污点、划痕和背景干扰,将彩色或灰度图像转换为黑白图像,突出文字信息。
- 倾斜校正:自动检测并修正因扫描或拍摄造成的图像倾斜,确保文字行水平。
- 版面分析:识别并分割出文档中的段落、行、列(藏文多为从左至右的列结构)以及图像、表*等非文字区域。
2.文字识别核心:
- 深度学习方法:采用基于CNN(卷积神经网络)和RNN(循环神经网络,如LSTM)的端到端模型。该模型能自动学习藏文字符的复杂特征(如上加字、下加字、元音符号等垂直叠加结构),对字体变化、轻微模糊的文本具有极强的鲁棒性。
3.后处理与校对:
- 语言模型纠错:利用藏文语法和词频统计模型,对识别结果进行智能纠错。例如,纠正“་”(音节分隔符)的缺失或错位。
- 人工校对平台:提供便捷的人机交互界面,让专家对机器识别有疑问或错误的部分进行快速标注和修正,并将修正结果反馈给模型,实现持续优化。
应用场景:藏文识别技术在档案管理中的具体落地
档案数字化加工中心:
- 流程:珍贵档案 → 高精度扫描仪 → 图像预处理 → 藏文OCR识别 → 人工校对 → 生成双层PDF(上层为可检索的识别文本,下层为原始图像)或结构化文本数据库。
- 成果:建立高质量的藏文数字档案库。
智能检索与知识图谱构建:
- 全文检索:用户不再仅能通过标题或关键词检索,而是可以直接搜索档案正文中的任意词汇或句子,秒级定位所需信息。
- 实体识别与关联:在OCR输出的文本基础上,应用命名实体识别技术,自动抽取出人名、地名、寺庙名、佛经名、时间等关键实体。进而构建知识图谱,可视化地展示实体间的复杂关系(如某位高僧曾在哪些寺庙活动,与哪些人物有过交集)。
专题档案数据库建设:
- 针对特定主题(如《****传》版本、某教派传承史料),利用藏文识别技术快速从海量档案中提取相关内容,自动归类、标引,形成系统化的专题数据库,服务于专项研究。
数字人文研究与展示:
- 公众教育与展示:将识别后的文本与数字博物馆、线上展览结合,为公众提供生动、可交互的藏文化教育内容,如点击图片上的文字即可显示翻译或注解。
藏文识别技术是连接历史档案与数字未来的关键桥梁。它的应用,不仅是对珍贵藏文文献的抢救性保护,更是对其内在知识价值的“唤醒”与“激活”。通过系统化的实施方案,档案管理机构能够从根本上提升工作效率和服务能力,使尘封的故纸堆转变为涌动着智慧与生机的数据宝藏,为学术研究、文化传承与创新发展提供不竭的动力。
未来,随着多模态技术(结合图像、文本)和预训练大模型的发展,藏文识别技术将更加精准和智能,甚至能够理解档案的语义和情感,最终帮助我们以前所未有的方式,解读和传承博大精深的藏族文化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号