如何消除推荐系统中的选择偏差
这个选择偏差(selection bias)主要是以信息流推荐为例来说的。在这里说的是由于展示位置等因素,虽然这个内容用户不一定很喜欢,但是还是点击了。去除选择偏差,就是考虑用户的点击互动行为多大程度是受展示位置的影响。一般来说信息流场景下,第一条的点击率,互动率是要高于之后的位置。统计发现,前三、四条有明显的递减关系,但是中间一段基本差别不大。但是一刷的最后一两条,又会比倒数第三条高。
简而言之,就是说我们在训练模型评价用户对于这些候选item的偏好程度的时候要剔除掉一些会带来选择偏差的因素。
会带来选择偏差的因素有展示位置(比如在这次下发中是第几条),设备id(这个主要是考虑到不同设备的屏幕,分辨率对于内容展示的效果不同),展示延迟,
日期和时间,客户端版本等(参考《计算广告》13.5.4)。
一般推荐系统考虑的是展示位置和设备id(谷歌的论文《Recommending What Video to Watch Next: A Multitask Ranking System》)。
接下来总结下我了解的在rank模型中消除展示偏差的方法。
(1)离线训练模型时候加上这个特征,但是线上设置为0。这种主要是LR模型,用这个相当于加了一个bias。
(2)对于DNN模型来说,这个特征还是和其他进行交叉,这种不能直接置为0。上文提到的论文中的方法就是在额外接一个小的网络训练这个bias。我觉得应该就是给这position和device_id训练个embedding,然后有个全连接层融合一下最后在变成一个数加到多目标网络的最后一层。训练的时候,这个小网络和大网络一起训练,但是线上服务的时候只有大网络。
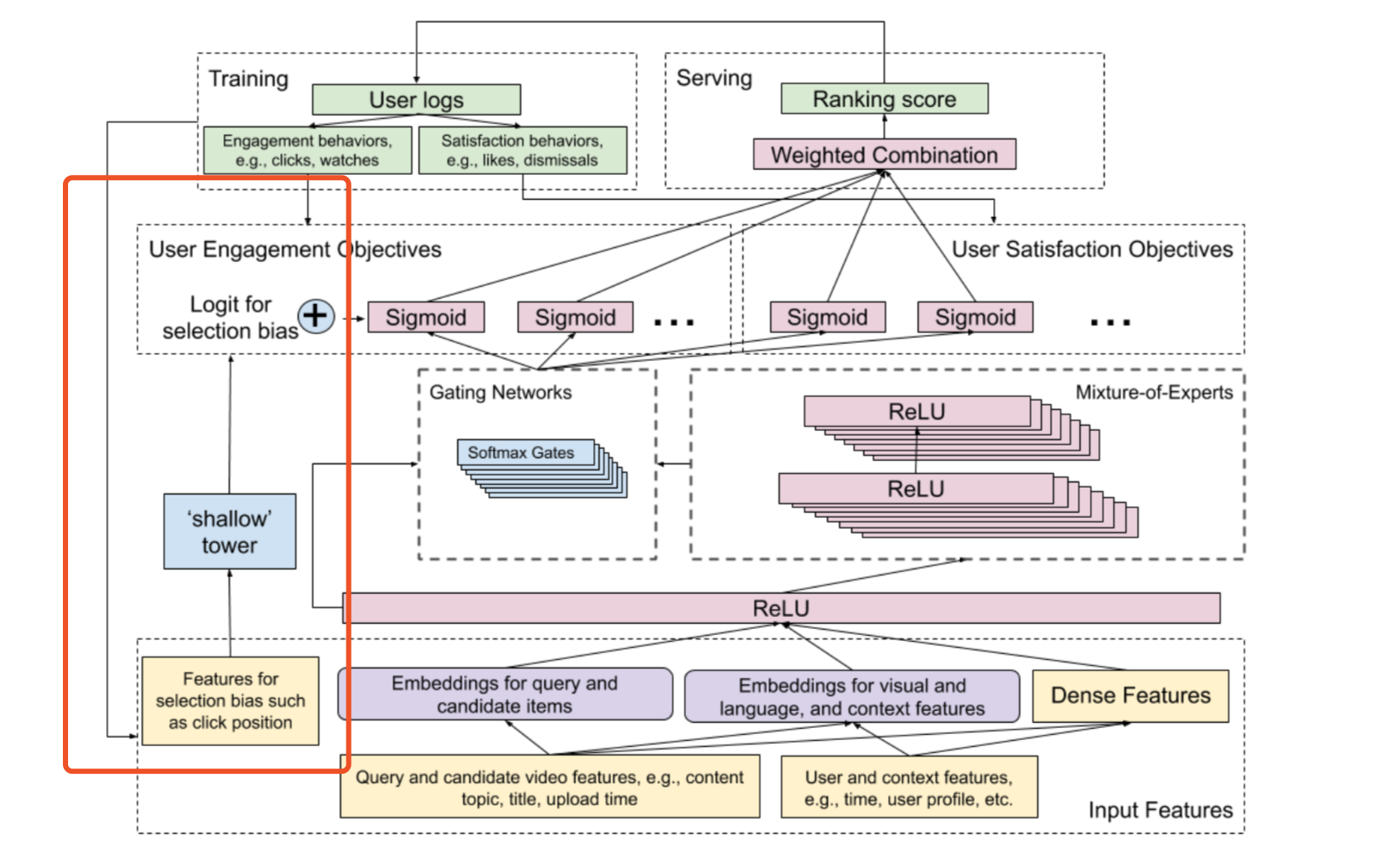
(3)还有一种方法,感觉比较复杂,而且据说实际效果一般。这些偏差特征和其他特征一起训练,但是这部分梯度回传的时候梯度*-1,相当于让模型和这几个特征值做对抗。
好了,说了这么多,那实际效果如何呢。目前从我的尝试结果看来,说的很有道理,实际上线然并卵啊。仔细想来,这部分偏差对于一个成熟的推荐系统来说影响到底有多大呢?
对于信息流这种用户刷刷刷的场景下,展示位置会有影响,但是如果用户刷的比较多,尤其是每次下发的内容用户大部分都能刷出来的情况下,其实这个偏差影响不大。毕竟后面的内容如果用户感兴趣,用户一样会互动,点击。这个和广告,搜索的场景还是不一样的。举个例子,比如用户刷了十刷,如果是不断上滑的话,除了第一条之外,用户对于之后出的内容大部分都看了,而且注意力也并没有衰退很多。所以偏差的影响应该很小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号