
《Adaptive Mechanism Design: Learning to Promote Cooperation》 2017-arxiv
背景及问题:
外部代理如何在观察学习智能体的基础上分配额外的奖惩促进学习者之间的合作。
创新及问题解决:
- 提出一条规则:通过考虑智能体预期的参数更新来自动学习创建正确的激励措施(等同于创建一种自适应社会奖惩机制)
- 证明了在某些环境下,措施在一定时间后关闭合作结果也是稳定的,而有些游戏则需要持续性的干预,但是需要的干预也会逐渐减少
核心工作:
- 实验环境及模型设置:
- 采用策略梯度方法在矩阵博弈游戏中进行实验
- 设置一个计划代理,其具有额外动作空间对代理进行奖励或者惩罚
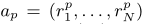
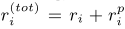
- θ代表代理的策略参数
为了将代理的学习过程和计划代理赋予的额外奖励和惩罚联系起来,用梯度上升的方法如下:
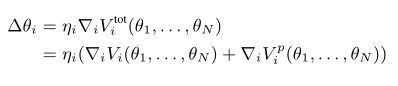
- Results:
- 主要针对以下几个问题进行验证:
- 计划代理的引入是否成功促进了社会困境中更高水平的合作
- 保持学习和保持合作需要的额外奖励或惩罚数量
- 在哪些环境中计划代理仅存在一段时间,最终社会合作也能实现并稳定
- 环境主要包括囚徒困境、懦夫困境以及猎鹿博弈

图(a)表示计划代理很好得学习了如何进行额外的奖励和惩罚,代理达到很好得合作效果
图(b)是显示计划代理根据四种动作进行奖励的变化情况
图(c)代表社会困境的衡量指标很快降低,直至不再是一个社会困境问题
图(d)代表合作达到一定程度后计划代理逐渐减少奖励行为直至0
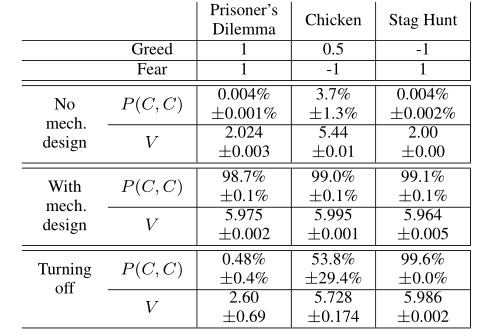
Greed = T- R fear = P - S
表中显示,计划代理存在显著促进了合作概率,而不同的困境博弈中,一定时间后关闭代理会有不同的结果,主要是由于其本身困境倾向的动作组合不同。 - 最后在设置N=10条件下对合作概率进行验证
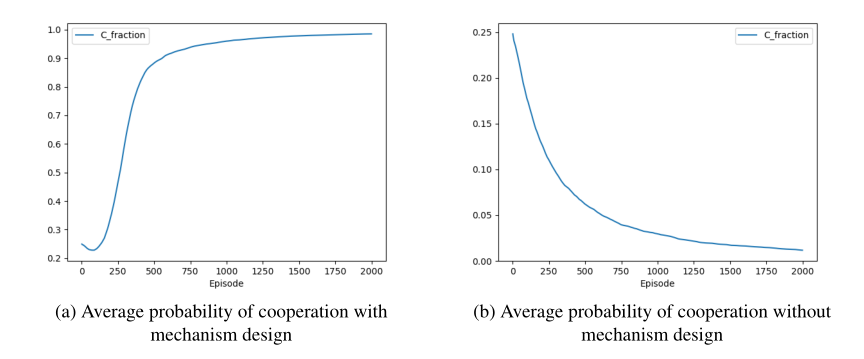
- 主要针对以下几个问题进行验证:
结论:
- 计划代理在困境博弈中很好得促进了合作,并且对于一些环境,即使在一段时间后关闭代理也能保持合作状态
- 缺点在于实验环境的代理数量比较少,环境比较单一不够复杂

 浙公网安备 33010602011771号
浙公网安备 33010602011771号