
《A multi-agent reinforcement learning model of common-pool resource appropriation》2017-NIPS
背景及问题:
- 过去有关公共池资源占用的问题上通常采用非合作博弈论的抽象预测模型仅仅考虑个人利益,往往无法找到比较好的社会均衡结果,并且仅仅考虑了占用多少这个维度
- 现在的该类问题向空间和时间资源动态扩展,非合作博弈论不再适用该种问题
创新及问题的解决:
- 论文采用深度强化学习的方法替代了原有的非合作博弈论方法并进行实验验证
- 提出了一个以学习为中心的公共资源占用模型:
- 包含一个时间和空间动态的公共资源占用环境
- 以及一个由N个独立的self-interseted的深度强化学习代理组成的多代理系统,每个代理通过环境奖励自适应调节,是一个不断试错的过程
核心工作:
- 致力于开发用来分析各种社会结果出现的方法
- 开发一种N玩家经典博弈论分析,将该新模型与非合作博弈论联系起来,确定经典的博弈论属性例如纳什均衡等
- 模型的目标仅仅是为了提出一些相对于传统博弈论方法被忽略的方面,以及证明试错机制是一种有利于促进公共池资源可持续的机制
- 定义的模型:
- 采用传统的具有N个代理部分可观察马尔科夫博弈,每个代理的目标都是最大化个人奖励

- 每个代理通过深度强化学习独自学习,目的是观察每个代理在其他智能体存在时学习过程中出现的行为(Q-learning)
- 社会结果评价指标:
- 收集效率
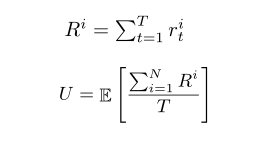
- 基尼系数(收益差距)
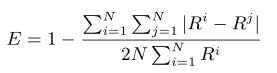
- 可持续性(每个智能体收集时长)
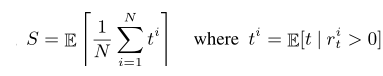
- 和平指标(平均未被标记数)
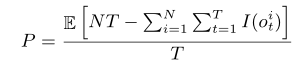
- 收集效率
- 采用传统的具有N个代理部分可观察马尔科夫博弈,每个代理的目标都是最大化个人奖励
- Results
-
单一智能体的可持续探索(单个智能体不断地探索,没有竞争,奖励总是随着时间增长的)
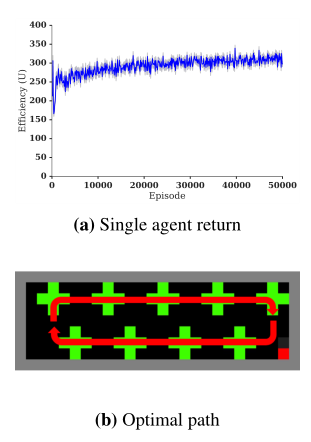
-
多智能体下的几个社会指标
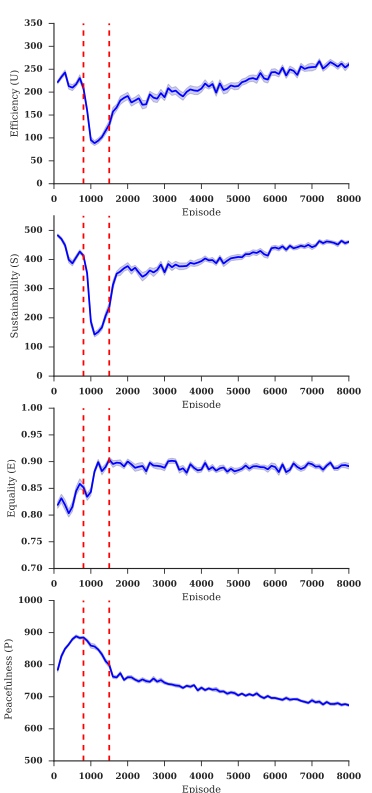
一开始整体苹果密度较大,一直到900时间节点,智能体都能够不断探索获取奖励。之后智能体发现标记他人没有效果并且浪费了收集时间,因此放弃标记此时和平指标P在900-1500时间段内上升,此时产生了公地悲剧资源耗尽,收益效率U急剧下降。最后由于资源稀缺,冲突就会变多,智能体开始采取措施将其他人标记,此时和平指标P下降,之后收益效率以及基尼系数趋于平衡。 -
多智能体之间排斥以及可持续性的出现:假设了地图中的一个领地为一个智能体占有,并排除其他智能体,因此将该智能体赋予标记功能,其与则没有
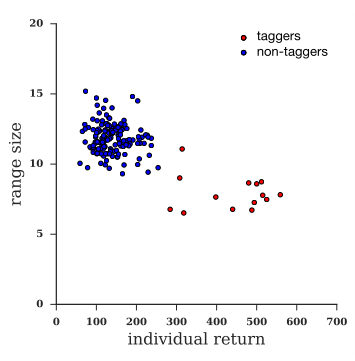
可以看到具有标记功能的智能体占有一方领地,并具有更高的回报,没有标记功能的智能体无法自我调节到最佳策略状态从而收益较低并且耗尽了领地资源。
-
结论:
- 模型内生排斥,可存在将其他人排除在领地外获得高收益
- 尽管所有智能体都是各自训练,但都在不断提高收集能力向自己有利的方向发展。能力过强的代理人可能耗尽公地资源,几个社会结果评价指标能更好的发现这一情况
- 在代理没有与人类相同的高认知调整能力条件下,不断试错的机制可以有效的在该社会困境下发挥作用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号