
Scalable Evaluation of Multi-Agent Reinforcement Learning with Melting Pot
提出的问题:
- 现有的对多智能体强化学习的评估工具没有将多智能体强化学习泛化的新情况评估作为主要目标。
- 传统的监督学习和受益于明确的实验环境和存在的评价基准,能够较为简单的进行评估,但是对于强化学习来说,生成一组测试环境比标记一组测试数据所需要的资源消耗是要更多的。
解决方案及创新:
- 提出了名为Melting Pot的评估工具包括一种评估方法和一套特定的测试环境,填补了上述的评估方面的空白能够在使用强化学习的基础上耗费较少的资源对多智能体强化学习进行评估,揭示一些在训练性能中无法发现的弱点。专注于为多智能体强化学习泛化提供一个基准。
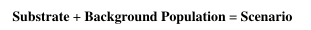
-
Substrate:世界的物理部分即地图布局、物体分布、移动方式、物理规则
-
Background:代表部分模拟部分具有智能体的仿真场景
-
利用多智能体之间的交互创建大量的泛化测试集,具体来说就是预训练智能体的“背景群体”用作后续的评估,不作为训练数据。
-
Melting Pot相关定义:
- substrate:指代部分可观察的马尔科夫博弈,在游戏状态中每个代理不知道游戏规则,必须探索才能得到。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号