
Gifting in Multi-Agent Reinforcement Learning
背景:
现有的多智能体强化学习都是从单智能体强化学习发展而来的,其中智能体奖励都是由环境定义。在此基础上,文章提出了一种智能体之间的奖励机制,期望其能够对学习过程有所帮助,并优化训练过程,文章证明了这种机制可以改善资源占用环境中的学习进度,并对学习过程进行了分析。
创新点:
在现有的多智能体强化学习基础上,提出了多智能体之间的互相奖励机制,有利于学习进度。
论文核心工作:
同伴间奖励由环境驱动,个体之间无法沟通,文中提出了三种馈赠机制:
- Zero-Sum:赠送奖励次数不限,但是一旦送出A的礼物则会立即收到-A的惩罚,因此智能体的平均收益是不变的。持续惩罚即不鼓励该行为。
- Fixed Budget:设置预算B,只要预算没有被耗尽,智能体就可以不断从中选取进行奖励动作,直至耗尽动作空间则没有奖励这个动作。
- Replenishable Budget:预算初始B = 0,智能体从环境中获取奖励时,预算可以增长。模拟个人能力与其产生影响的场景。
实验:
- 环境设置为Harvest,十个智能体竞争收集apple,获取则收获1的奖励(之前的代理通过激光束调节竞争过程,但是会导致“公地悲剧”即资源会快速耗尽,每个智能体汇报较小)

-
增加馈赠光束,B= 40,每收集两个苹果预算增加1,每个智能体由深度Q网络控制。代理奖励由环境和同伴奖励组成。四个评价指标分别为:代理平均回报R、可持续性S衡量收集环境奖励的平均时间,和P衡量在任意地点未标记代理的平均数量,E由基尼不平等指数给出。

-
实验结果:
-
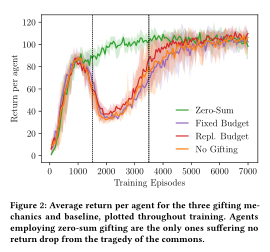
-
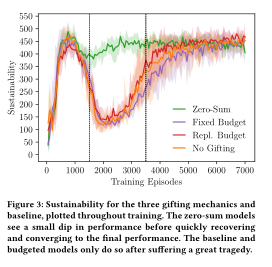
-
验证零和机制的优势,遇到公地悲剧时,所有代理都会增加设计频率。验证得到主要是零和机制智能体所需要学习的东西更少即只需要掌握什么时候调整奖励,而相对来说预算机制还需要考虑环境反馈的预算调整之类的东西:

-
最终结论就是零和机制会调节智能体的贪婪程度,使得环境资源被耗尽的速度减小,增加了可持续时长同时也避免了公地悲剧的出现。
-
结论:
- 多智能体在学习过程中包括公地悲剧等多个阶段,且行为差异较大
- 零和机制被证明在文章提到的智能体之间的奖励机制里面最有效的一种方法,甚至可以避免公地悲剧,在harvest环境中的实验也印证了这一点

 浙公网安备 33010602011771号
浙公网安备 33010602011771号