
机器学习之决策树模型
一、决策树是什么
决策树是一种监督学习算法,既可以用于分类任务,也可以用于回归任务。其基本思想是通过一系列“是/否”的判断将数据逐步分裂成小的子集,直到每个子集足够“纯净”,即大部分数据属于同一类别。
1、基本概念
(1)节点:树中的每个点称为节点,根节点是树的起点,内部节点是决策点,叶节点是最终的决策结果。
(2)分支:从一个节点到另一个节点的路径称为分支。
(3)分裂:根据某个特征将数据集分成多个子集的过程。
(4)纯度:衡量一个子集中样本的类别是否一致。纯度越高,说明子集中的样本越相似。
2、工作原理
决策树通过递归地将数据集分割成更小的子集来构建树结构。具体步骤如下:
(1)选择最佳特征:根据某种标准(如信息增益,基尼指数等)选择最佳特征进行分割。
(2)分割数据集:根据选定的特征将数据集分成多个子集。
(3)递归构建子树:对每个子集重复上述过程,直到满足停止条件(如所有样本属于同一类别,达到最大深度等)。
(4)生成叶节点:当满足停止条件时,生成叶节点并赋予类别或值。
3、算法流程
决策树的构建过程是一个递归的过程,主要包含以下步骤:
-
初始化:从根节点开始,包含所有训练数据。
-
特征选择:
-
计算当前节点的信息熵
-
遍历所有可用特征
-
计算每个特征的信息增益
-
选择信息增益最大的特征作为当前节点的分裂特征
-
数据集划分:
-
根据选定的特征将数据集分成若干子集
-
为每个子集创建新的子节点
-
递归构建:
-
对每个子节点重复步骤2-3
-
直到满足停止条件:所有样本属于同一类别;没有更多可用特征;达到预设的树深度;节点样本数小于阈值。
-
生成叶节点:
-
当满足停止条件时
-
将当前节点标记为叶节点
-
记录该节点的类别(通常为样本最多的类别)
这个过程自顶向下构建决策树,通过不断选择最优特征来划分数据集,最终形成一个完整的树形结构。
4、优缺点
优点
(1)易于理解和解释:决策树的结构直观,易于理解和解释。
(2)处理多种数据类型:可以处理数值型和类别型数据。
(3)不需要数据标准化:决策树不需要对数据进行标准化或归一化处理。
缺点
(1)容易过拟合:决策树容易过拟合,特别是在数据集较小或树深度较大时。
(2)对噪声敏感:决策树对噪声数据较为敏感,可能导致模型性能下降。
(3)不稳定:数据的小变化可能导致生成完全不同的树。
5、使用场景
(1)医疗诊断:根据患者的症状判断疾病种类。
(2)客户细分:通过客户特征分析市场,进行精准营销。
(3)银行贷款审批:根据申请人的收入、信用记录等因素评估贷款风险。
(4)营销策略:根据用户行为推荐产品或服务。
二、属性划分方法
1、熵
熵是表示随机变量不确定性的度量,简单来说就是物体内部的混乱程度,对于决策树的某个结点而言,它在对样本数据进行分类后,我们希望分类后的结果可以使整个样本集在各自类别中尽可能有序,最大程度地降低样本数据的熵。
随机变量x的熵定义为:
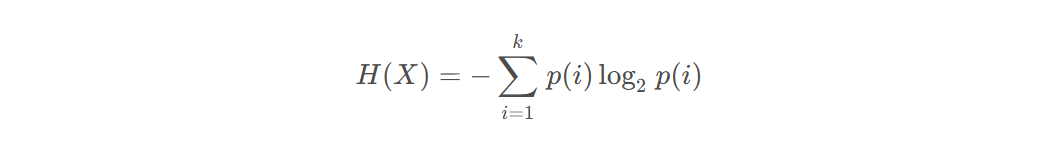
H(X):随机变量X的熵
k:X所有可能取值的类别总数
p(x)是随机变量X取第i个值的概率
2、信息增益:ID3
信息增益g(D,X)表示某特征X使得数据集D的不确定性减少程度,定义为集合D的熵与在给定特征X的条件下的D的条件熵H(D|X)之差,即
g(D,X)=H(D)-H(D|X)
条件熵:在给定X的条件下D的条件概率分布对X的数学期望,即
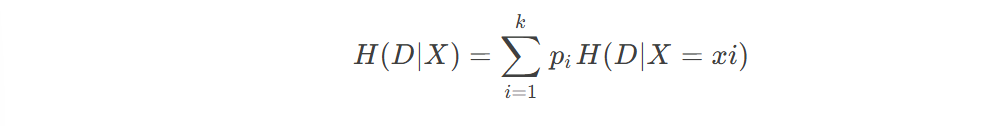
一般而言,信息增益越大,则意味着使用属性a来进行划分所获取的“纯度提升”越大。
3、信息增益率
信息增益率是信息增益的归一化版本,避免偏向取值多的特征
信息增益率公式:
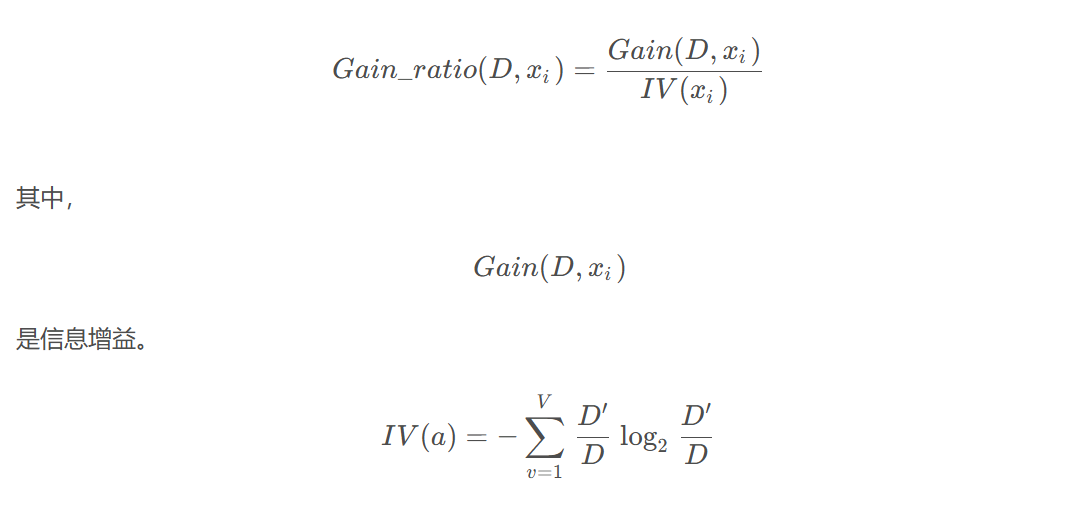
信息增益越大,说明特征既能很好地减少不确定性,又不受取值多少的影响。
4、基尼指数
基尼指数指在分类问题中,假设有K个类,样本点属于第K类的概率为Pk,则概率分布的基尼值定义为
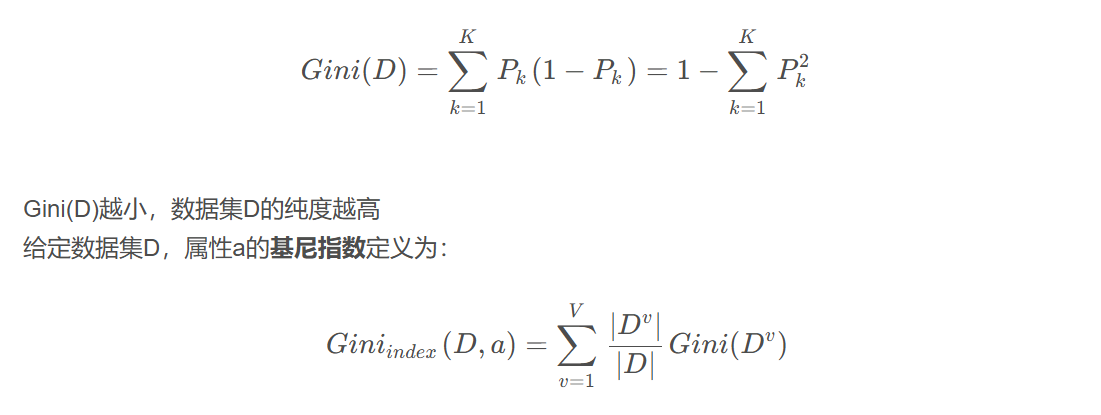
在候选属性集合A中,选择那个使划分后基尼指数最小的属性作为最优划分属性。
三、使用Python实现决策树
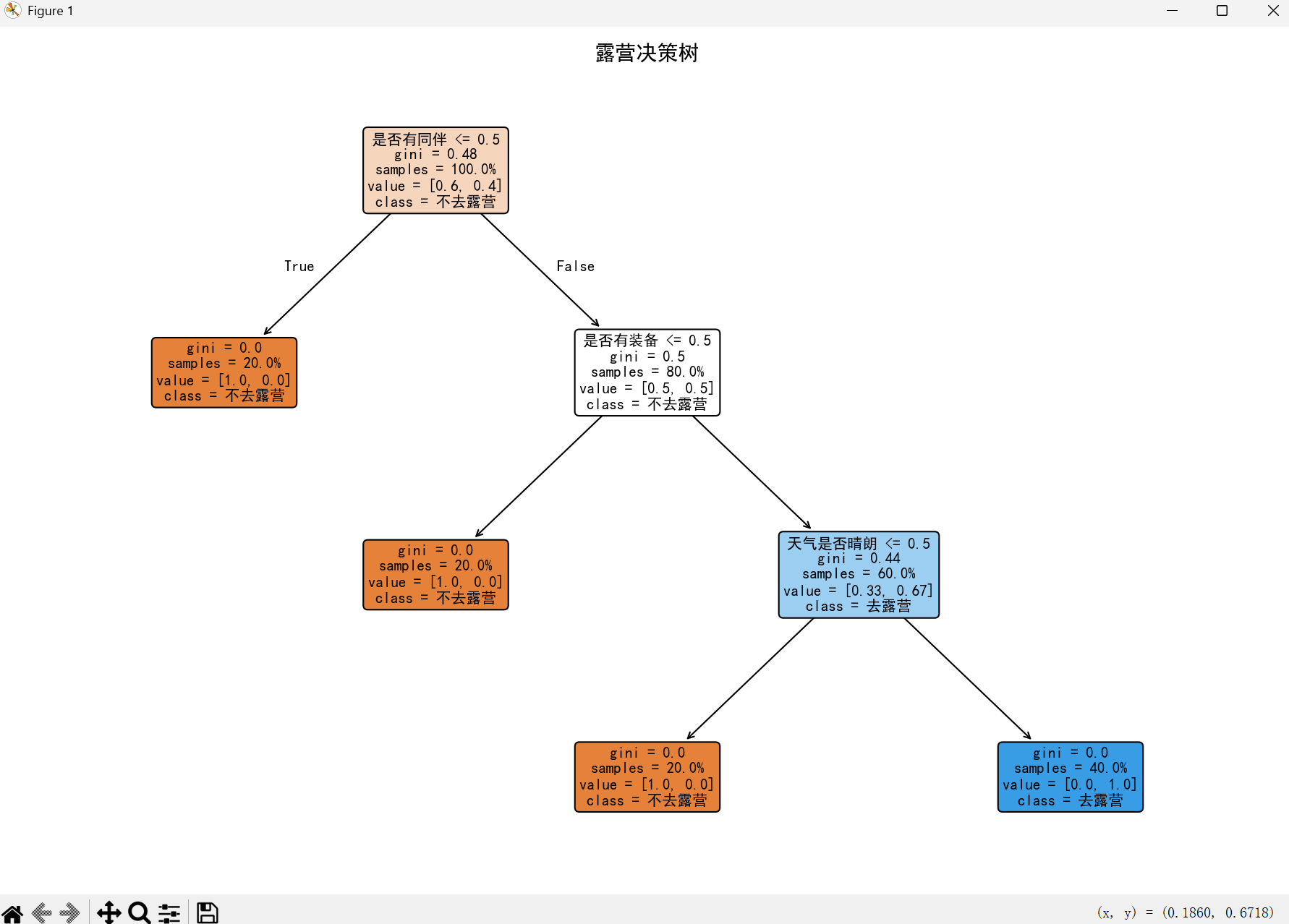
1、预测周末是否去露营
点击查看代码
# 1. 导入需要的库
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# 2. 准备训练数据
data = {
"天气是否晴朗": [1, 1, 0, 1, 1], # 1=是,0=否(5条数据无缺失)
"是否有同伴": [1, 0, 1, 1, 1],
"是否有装备": [1, 1, 1, 0, 1],
"最终是否去露营": [1, 0, 0, 0, 1]
}
df = pd.DataFrame(data)
# 3. 拆分特征和结果
X = df[["天气是否晴朗", "是否有同伴", "是否有装备"]]
y = df["最终是否去露营"]
# 4. 训练模型(保持参数不变,确保逻辑一致)
model = DecisionTreeClassifier(max_depth=3, random_state=42)
model.fit(X, y)
# 5. 画决策树图(重点优化:确保数据完整显示)
plt.figure(figsize=(12, 8)) # 放大图片尺寸(宽12,高8,避免截断)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文显示乱码问题(Windows)
# Mac用户替换成:plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plot_tree(
model,
feature_names=["天气是否晴朗", "是否有同伴", "是否有装备"], # 特征名称(中文正常显示)
class_names=["不去露营", "去露营"], # 类别名称(中文正常显示)
filled=True, # 节点上色(区分纯度)
rounded=True, # 圆角节点
fontsize=10, # 调整字体大小(避免文字重叠)
proportion=True, # 显示样本占比(新增:更直观)
precision=2 # 数值精度(保留2位小数,避免杂乱)
)
plt.title("露营决策树", fontsize=14) # 标题字体放大
plt.tight_layout() # 自动调整布局,防止节点/文字被截断
plt.show()
# 6. 新数据预测(保持不变,验证结果)
new_data = [[1, 1, 0]]
prediction = model.predict(new_data)
result = "去露营" if prediction[0] == 1 else "不去露营"
print(f"新情况预测结果:{result}") # 输出:不去露营
2、结果展示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号