<机器学习>无监督学习算法总结
本文仅对常见的无监督学习算法进行了简单讲述,其他的如自动编码器,受限玻尔兹曼机用于无监督学习,神经网络用于无监督学习等未包括。同时虽然整体上分为了聚类和降维两大类,但实际上这两类并非完全正交,很多地方可以相互转化,还有一些变种的算法既有聚类功能又有降维功能,一些新出现的和尚在开发创造中的无监督学习算法正在打破聚类和降维的类别划分。另外因时间原因,可能有个别小错误,如有发现还望指出。
一.聚类(clustering)
1.k-均值聚类(k-means)
这是机器学习领域除了线性回归最简单的算法了。该算法用来对n维空间内的点根据欧式距离远近程度进行分类。
INPUT:
K(number of clusters)
Training set{x1,x2,x3,....xn} (xi belongs to R^n)
OUTPUT:
K个聚类中心
算法工作原理摘要:

自己手写的python实现K—means:
#簇数为k
#数据空间维度为n
#训练集元素数为m
def K_means_demo(k,n,m): clusters=np.random.randint(0,40,size=[k,n]) #随机生成聚类中心 tr_set=np.random.randint(0,40,size=[m,n]) #因为是模拟,所以自己随机生成的数据集for iter in range(0,5): clu_asist=np.zeros(shape=[k,n],dtype=int) for i in range(0,m): #遍历训练集内每个样本 min=9999999 owner=0 for j in range(0,k): #遍历所有聚心找到最近的聚心owner dis=0 for p in range(0,n): abso =tr_set[i][p] - clusters[j][p] dis+=abso*abso #dis为第i个元素和第j个聚心的欧式距离的平方 if dis-min < 0: min=dis owner=j for p in range(0,n): #渐进更新均值 clu_asist[owner][p]+=(tr_set[i][p]-clu_asist[owner][p])//(p+1) clusters=clu_asist
return clusters
在上面的代码中我手动设定了迭代更新次数为5,因为我做的demo规模比较小,迭代几次便收敛了,而在实际使用中一般用( 迭代次数 || EarlyStop )作为迭代终止条件。
动画演示:

通读本算法,可以发现k-means对聚心初始值非常敏感,如果初始情况不好会震荡的。这里可以采取一些措施预判聚心大致要在哪个位置,然后直接将其初始化。
另外,关于收敛的判断,可以采取多种方法。比如使用代价函数,或者F-Measure和信息熵方法。
K-means优缺点分析:
- 优点: 算法简单易实现;
- 缺点: 需要用户事先指定类簇个数; 聚类结果对初始类簇中心的选取较为敏感; 容易陷入局部最优; 只能发现球形类簇。
2.层次聚类(Hierarchical Clustering)
顾名思义,层次聚类就是一层一层地进行聚类。既可以由下向上对小的类别进行聚合(凝聚法),也可以由上向下对大的类别进行分割(分裂法)。在应用中,使用较多的是凝聚法。
INPUT:training_set D,聚类数目或者某个条件(一般是样本距离的阈值)
OUTPUT:聚类结果
凝聚法:
跟竞赛中经常出现的并查集问题略相似,凝聚法指的是先将每个样本当做一个类簇,然后依据某种规则合并这些初始的类簇,直到达到某种条件或者减少到设定的簇数。
在算法迭代中每次均选取类簇距离最小的两个类簇进行合并。关于类簇距离的计算表示方法主要有以下几种:
(1)取两个类中距离最小的两个样本的距离作为两个集合的距离
(2)取两个类中距离最大的两个样本的距离作为两个集合的距离
(3)计算两个集合中每两两点的距离并取平均值,这种方法要略费时
(4)比(3)轻松一些,取这些两两点距的中位数
(5)求每个集合中心点,然后以中心点代表集合来计算集合距离
(6)......
迭代会在簇数减少到设定数量时结束,当然,如果设定了阈值f,那么当存在两个距离小于f的集合时则会继续迭代直到不存在这样的两个集合。
分裂法:
首先将所有样本归类到一个簇,然后依据某种规则逐渐分裂,直到达到某种条件或者增加到设定的簇数。
(手写再拍照真不容易QAQ)

层次聚类和K-means作比较:
(1)K-means时间复杂度为O(N),而层次聚类时间复杂度为O(N^2),所以分层聚类不能很好地处理大批量数据,而k-means可以。
(2)K-means不允许嘈杂数据,而层次聚类可以直接使用嘈杂数据集进行聚类
(3)当聚类形状为超球形(如2D圆形,3D球形)时,k-means聚类效果更好。
3.基于密度聚类Mean Shift
mean shift这种基于核函数估计的爬山算法不仅可以用于聚类,也可用于图像分割与目标跟踪等。这个概念早在1975年就被Fukunaga等人提出,而后1998年Bradski将其用于人脸跟踪则使得其优势大大体现出来。我们这里只谈论作为聚类算法的mean shift。
什么是漂移向量?
给定n维空间内数据点集X与中心点x,并以D表示数据集中与中心点x距离小于半径h的点的集合,则漂移向量Mh表示为: Mh =Exi∈D[xi-x] 。
什么是漂移操作?
计算得到漂移向量后将中心位置更新一下,使得中心位置始终处于力的平衡位置。更新公式为: x ← x + Mh 。
另外,mean shift用于聚类时一般不使用核函数,如果用了核函数,权重改变,就不是“均值”漂移了。
均值飘移算法实现过程:
1.在未被标记的点中随机选取一个点作为起始中心点center;
2.找出以center为中心半径为h的空间内所有的点,记作集合D,认为这些点归属于类簇c。同时将这些点属于这个类的概率加1,这个参数将用于最后步骤的分类;
3.计算D内数据点与中心点center的漂移向量Mh ;
4.进行漂移操作x ← x + Mh ;
5.重复步骤2.3.4直到迭代收敛,记下此时的center位置。在这一过程中遇到的点都归类到簇c;
6.如果收敛时当前簇c的center与其它已存在的簇c‘中心的距离小于阈值,则合并c和c'。否则,把c作为新的聚类,增加1类;
7.重复步骤1-6直到所有的数据点都被标记访问;
8.分类:根据每个类对每个点的访问频率,取频率最大的类作为当前点集的所属类。
shift mean跟k-means作比较,两者都用集合内点的均值进行中心点移动,不同的是shift mean可以自行决定类簇数。
4.基于密度聚类DBSCAN
DBSCAN:“深度学习的神经网络,比你们用了几十年的k-means不知道高到哪里去了,我跟他谈笑风生。” (手动滑稽)DBSCAN可能是聚类领域最迷的算法了,它可以发现任何形状的簇,而且实现简单易懂。至于是谁首先提出的我也不晓得了,就不给各位普及历史了emmm,以下是一段抄来的介绍:DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。 该算法将具有足够密度的区域划分为簇,并在具有噪声的空间数据库中发现任意形状的簇,它将簇定义为密度相连的点的最大集合。
INPUT:Training_set D,半径Eps,密度阈值MinPts
OUTPUT:类簇clusters
DBSCAN需要两个参数即扫描半径Eps与最小包含点数MinPts。扫描半径是最难选定的了,会对结果有较大影响。可以用k距离做大量试验来观察,找到突变点。一般很难一次性选准,还是要做大量实验。MinPts可以理解为标题中的“密度”,一般这个值都是偏小一些,然后进行多次尝试。根据这两个参数可将样本中的点分为三类:
<1>核点(core point) 若样本  的
的  邻域内至少包含了MinPts个样本,即
邻域内至少包含了MinPts个样本,即  ,则称样本点 为核心点。
,则称样本点 为核心点。
<2>边界点(Border point) 若样本 的 邻域内包含的样本数目小于MinPts,但是它在其他核心点的邻域内,则称样本点 为边界点。
<3>噪音点(Noise)。既不是核心点也不是边界点的点。
伪代码:
(这一段copy自他人博客)
(1) 首先将数据集D中的所有对象标记为未处理状态 (2) for(数据集D中每个对象p) do (3) if (p已经归入某个簇或标记为噪声) then (4) continue; (5) else (6) 检查对象p的Eps邻域 NEps(p) ; (7) if (NEps(p)包含的对象数小于MinPts) then (8) 标记对象p为边界点或噪声点; (9) else (10) 标记对象p为核心点,并建立新簇C, 并将p邻域内所有点加入C (11) for (NEps(p)中所有尚未被处理的对象q) do (12) 检查其Eps邻域NEps(q),若NEps(q)包含至少MinPts个对象,则将NEps(q)中未归入任何一个簇的对象加入C; (13) end for (14) end if (15) end if (16) end for
动画演示:

5.高斯混合模型(GMM)与EM
针对GMM,一般采用EM算法进行聚类。这里的“高斯”在二维时便是正态分布,高斯混合模型是对高斯模型进行简单的扩展,GMM使用多个高斯分布的组合来刻画数据分布。因为GMM含有隐变量ak,所以要采用含有隐变量模型参数的极大似然估计法即EM算法。EM比前面所讲算法均要复杂。
直接求解极大似然函数极值对应的参数比较困难,因此采用迭代逐步近似极大似然函数。首先要获得似然函数L(θ)的一个下限,然后逐步极大化这个下限便可近似获得极大似然函数的极值以及对应的参数。
似然函数 ![]() ,其中Z是隐变量
,其中Z是隐变量
根据Jensen不等式L(θ)⩾B(θ,θi) ,获得L(θ)的下限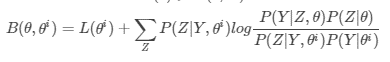
可见,每次迭代时最大化B(θ,θi)即可逐渐逼近似然函数极大值,进一步化简,极大化B(θ,θi)也就是极大化Q(θ,θi)![]()
这里的Q函数便是整个EM算法的核心。其意义是logP(Y,Z|θ)logP(Y,Z|θ)关于P(Z|Y,θi)P(Z|Y,θi)的期望。
结合上面所讲,EM算法可以分为交替进行的两部分:
E-step:计算Q函数
M-step:求Q函数最大值,并得到相应参数θ
为防止落入局部最优,需要多次迭代。
算法流程:

因为没怎么用过这个算法,只是有所了解,所以抱歉没法给出更具体详细的实现与改进历史。有兴趣的话可以自行google

6.基于图论聚类
(没学这个,学完再给补上)
二.降维(demensionality reduction)
1.主成分分析(PCA)
它算是出现最多的降维算法了吧。goodfellow的《深度学习》中对PCA讲解太笼统了,可能很多人看不明白,下面我会尽量直白地说。
PCA在1901年由pearson提出,1933年hotelling对PCA做了改进推广。指的是将n维特征映射到k维上(k<n),通过正交变换将一组可能存在相关性的变量数据转换为一组线性不相关的变量,转换后的变量被称为主成分。PCA可看作一个端到端的算法。
下图是一个f:3D->2D的PCA演示
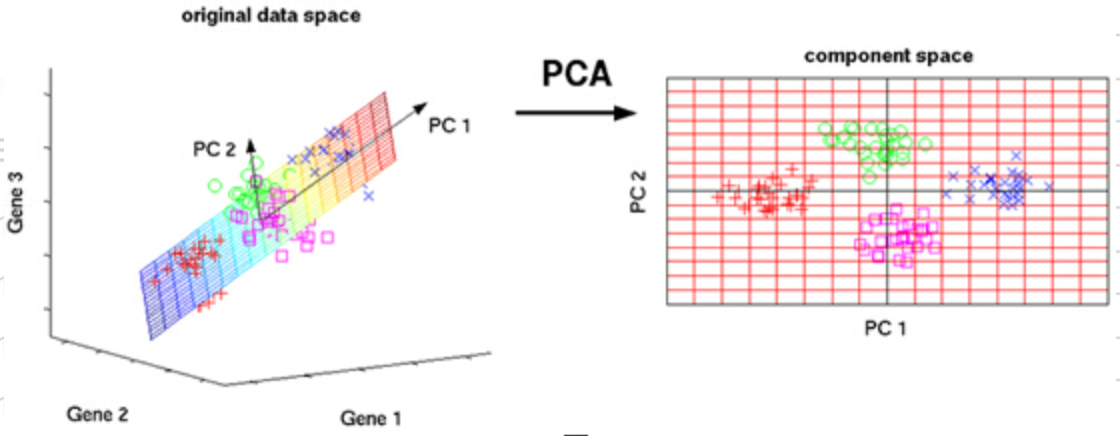
INPUT:原始维度n,目标维度k,无标签训练集D
OUTPUT:转换矩阵M
具体操作时可以采用特征值分解和奇异值分解两种手段,这里选取了特征值分解,奇异值分解下一个算法会讲到。
操作步骤:
<1>数据中心化处理。求D中所有样本的均值xaverage ,并将D中每个样本减去xaverage 得到数据集A
<2>求得A的协方差矩阵C
<3>求取矩阵C的特征值以及对应的特征向量
<4>对特征值按照由大到小顺序排列,选取其中前k大的,然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵E
<5>将样本点投影到目标空间上,Target=ET * A ;ET便是要求的转换矩阵
关于为什么PCA要这样操作,为什么这样操作有效,可以参考以下三个理论:最大方差理论、最小错误理论和坐标轴相关度理论。
讨论与总结:
PCA技术一大优点与特色是:它完全没有参数限制。在PCA的计算过程中完全不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关。
PCA可以用来进行数据压缩,例如100维的向量最后可以用10维来表示,那么压缩率为90%。另外图像处理领域的KL变换使用PCA做图像压缩,人脸检测和匹配。有一个基于PCA实现的特征人脸分析算法,感兴趣的朋友可以查查看。
2.独立成分分析(ICA)
独立成分分析并不算严格意义上的降维算法,但它和PCA有着千丝万缕的联系,所以将它放在了PCA后面简单介绍一下。
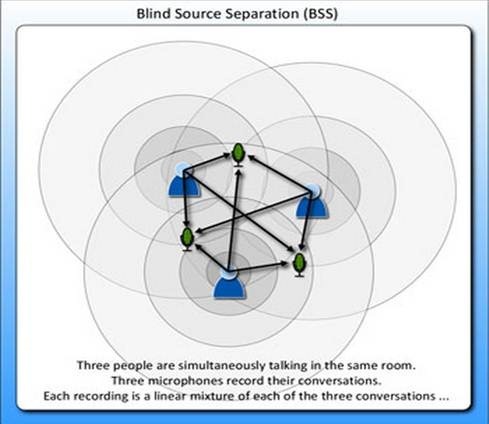
首先看一个经典的鸡尾酒宴会问题(cocktail party problem)。假设在party中有n个人,他们可以同时说话,我们也在房间中一些角落里共放置了n个microphone用来记录声音。宴会过后,我们从n个麦克风中得到了一组数据![]() ,i表示采样的时间顺序,也就是说共采集到了m组n维的样本。我们的目标是单单从这m组采样数据中分辨出每个人说话的信号。
,i表示采样的时间顺序,也就是说共采集到了m组n维的样本。我们的目标是单单从这m组采样数据中分辨出每个人说话的信号。
细化一下,有n个信号源![]() ,
,![]() ,每一维都是一个人的声音信号,每个人发出的声音信号独立。A是一个未知的混合矩阵(mixing matrix),用来组合叠加信号s,那么
,每一维都是一个人的声音信号,每个人发出的声音信号独立。A是一个未知的混合矩阵(mixing matrix),用来组合叠加信号s,那么 ![]() ,其中x 和s均是矩阵而非向量。表示成图就是:
,其中x 和s均是矩阵而非向量。表示成图就是:
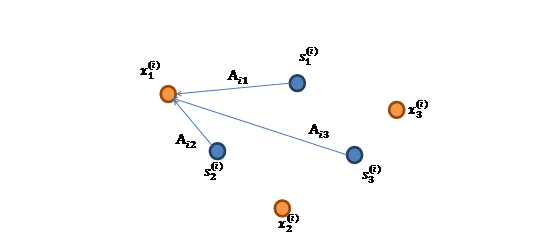
![]() 的每个分量都由
的每个分量都由![]() 的分量线性表示。A和s都是未知的,x是已知的,我们要根据x来推出s。也就是进行盲信号分离。
的分量线性表示。A和s都是未知的,x是已知的,我们要根据x来推出s。也就是进行盲信号分离。
令![]() ,那么
,那么![]()
将W表示成

其中![]() ,其实就是将
,其实就是将![]() 写成行向量形式。那么得到:
写成行向量形式。那么得到:
![]()
迭代求出W,便可得到![]() 来还原出原始信号。
来还原出原始信号。
下面是一个实例:


信号还原结果:
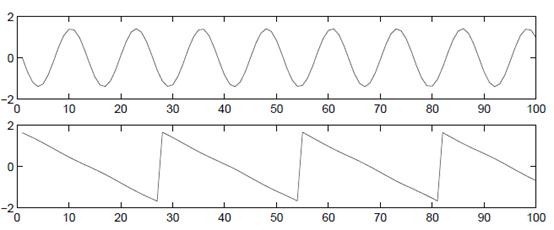
3.奇异值分解(SVD)
4.t-分布领域嵌入式算法(t-SNE)
第一次见到是在斯坦福cs231的课上,当时那位前辈语速奇快,跟《社交网络》里扎克伯格语速有得一拼。。。。
t-SNE的前身是2002年提出的SNE算法,2008年Laurens van der Maaten 和 Geoffrey Hinton在SNE基础上又提出t-SNE算法。作为一种非线性降维算法,非常适用于高维数据降到2-3维,进行可视化。日常工作中,涉及到数据可视化的时候一般都会想到去使用这个工具,因此在图像领域应用较多。另外在NLP,基因组数据和语音处理领域也应用广泛。 t-SNE太强了QAQ(再次手动滑稽) 。时间复杂度为O(N^2)。
t-SNE首先将距离转换为条件概率来表达点与点之间的相似度,距离通过欧式距离算得,S( ,
)表示求
之间的欧式距离。计算高维原始数据与降维后数据的公式如下:
![]()
计算完X数据之间的的概率P( )和Z数据之间的概率Q(
|
)之后,接下来就是我们 的目的就是P和Q连个分布尽可能的接近,也就是要是如下公式的KL散度尽可能小:
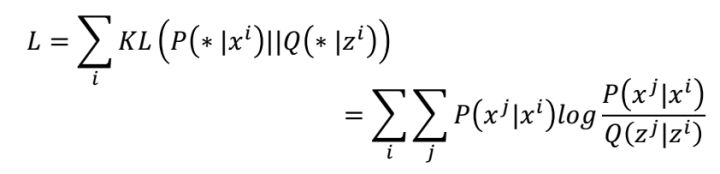
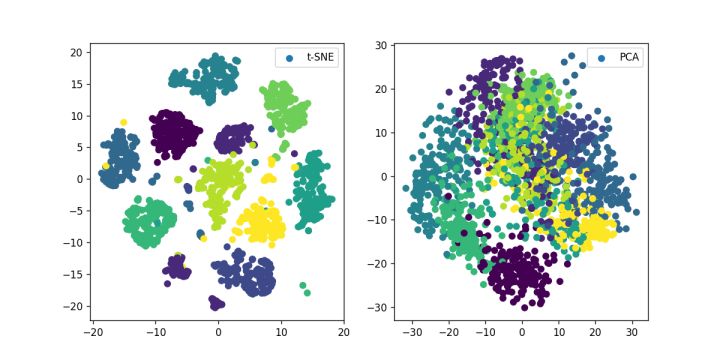
t-SNE和PCA的简单比较:(以下摘自gaotihong的文章)
from sklearn.manifold import TSNE from sklearn.datasets import load_iris,load_digits from sklearn.decomposition import PCA import matplotlib.pyplot as plt import os digits = load_digits() X_tsne = TSNE(n_components=2,random_state=33).fit_transform(digits.data) X_pca = PCA(n_components=2).fit_transform(digits.data) ckpt_dir="images" if not os.path.exists(ckpt_dir): os.makedirs(ckpt_dir) plt.figure(figsize=(10, 5)) plt.subplot(121) plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=digits.target,label="t-SNE") plt.legend() plt.subplot(122) plt.scatter(X_pca[:, 0], X_pca[:, 1], c=digits.target,label="PCA") plt.legend() plt.savefig('images/digits_tsne-pca.png', dpi=120) plt.show()
实验结果:
若想进一步研究t-SNE,可参考:
(1)http://www.datakit.cn/blog/2017/02/05/t_sne_full.html#11%E5%9F%BA%E6%9C%AC%E5%8E%9F%E7%90%86
(2)Visualizing data using t-SNE, by Van Der Maaten L,Hinton G

 浙公网安备 33010602011771号
浙公网安备 33010602011771号