python简单爬虫(爬取pornhub特定关键词的items图片集)
请提前搭好梯子,如果没有梯子的话直接403。
1.所用到的包
requests: 和服务器建立连接,请求和接收数据(当然也可以用其他的包,socket之类的,不过requests是最简单好用的)
BeautifulSoup:解析从服务器接收到的数据
urllib: 将网页图片下载到本地
import requests from bs4 import BeautifulSoup import urllib
2.获取指定页面的html内容并解析
我这里选取"blowjob"作为关键字
key_word='blowjob'
url = 'https://www.pornhub.com/video/search?search='+key_word html=requests.get(url) soup=BeautifulSoup(html.content,'html.parser')
3.从html中筛到全部image并进行遍历
使用find_all函数,将所有img区块中包含属性'width':"150"的存储到jpg_data列表中,并对jpg_data列表进行遍历
jpg_data=soup.find_all('img',attrs={'width':"150" }) for cur in jpg_data: pic_src=cur['src']
4.进一步筛选,并找到图片地址进行下载操作
cur['src']为当前图片地址,cur['alt']为当前图片标题,urllib.requests.urlretrieve操作将图片保存到当地,默认地址为本py文件所在目录,如有需要也可自定义保存目录。
for cur in jpg_data:
pic_src=cur['src']
if(".jpg" in pic_src):
filename=cur['alt']+'.jpg'
with open(filename,'wb') as f:
f.write(bytes(pic_src,encoding='utf-8'))
print(filename)
f.close()
完整代码:
import requests from bs4 import BeautifulSoup headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'} url = 'https://www.pornhub.com/video/search?search=blowjob' html=requests.get(url,headers=headers) soup=BeautifulSoup(html.content,'html.parser') jpg_data=soup.find_all('img',attrs={'width':"150" }) for cur in jpg_data: pic_src=cur['src'] if(".jpg" in pic_src): filename=cur['alt']+'.jpg' with open(filename,'wb') as f: f.write(bytes(pic_src,encoding='utf-8')) print(filename) f.close()
以上所作示例仅爬取了keyword关键词搜索下第一页的图片内容,如需要爬取多页,
可在url后加'&page=xx'并进行遍历
for i in range(0,10): url = 'https://www.pornhub.com/video/search?search=blowjob'+'&page='+str(i)
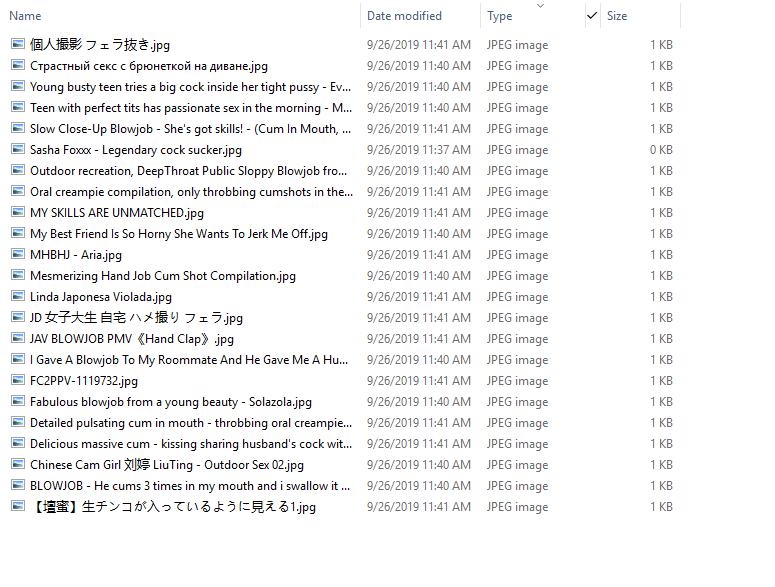
程序运行结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号