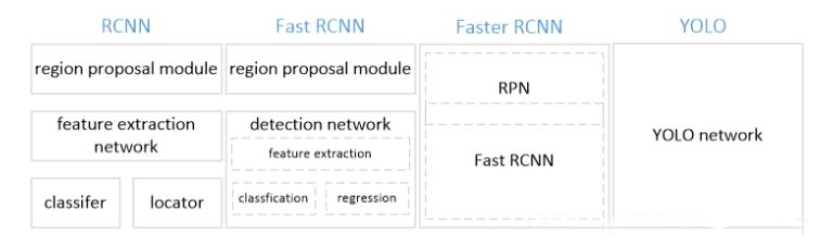
CNN之yolo目标检测算法笔记
本文并不是详细介绍yolo工作原理以及改进发展的文章,只用做作者本人回想与提纲。
1.yolo是什么
输入一张图片,输出图片中检测到的目标和位置(目标的边框)
yolo名字含义:you only look once
对于yolo这个神经网络:
(Assume s*s栅格, n类可能对象, anchor box数量为B)
Input 448*448*3
Output s*s*(5 * B +n)的tensor
2.CNN目标检测之yolo
在目标检测领域,DPM方法采用滑动窗口检测法将原图片切出一小块一小块,先选区再卷积提取特征,先整张图卷积提取特征再选区,然后投入神经网络进行图像分类操作处理。RCNN方法采用region proposal来生成整张图像中可能包含待检测对象的可能的bounding boxes然后用分类器评估这些boxes,再post processing来改善bounding box并消除重复的目标,最后基于整个场景中其他物体重新对boxes打分(这些环节都是分开训练)。其实都是把目标检测问题转化成了一个分类问题。2015年yolo论文公开,提出了一种新思路,将目标检测问题转化成了一个regression problem。Yolo 从输入的图像,仅仅经过一个神经网络直接得到bounding box和每个bounding box所属类别的概率。正因为整个过程下来只有一个神经网络,所以它可以进行端到端的优化。
Yolo优缺点:速度极快;在背景上预测出不存在物体的概率要低;能够学习抽象的特征,可用于艺术画像等。但定位偶尔出现错误。

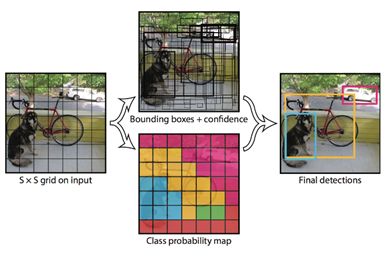
3.Unified Detection
先分s*s个栅格;
每一个栅格预测B个bounding boxes以及每个bboxes的confidence score。
Confidence score =P(Object) * IOUtruth_pred
若bbox包含物体,则P(Object)=1,否则为0
每一个栅格预测n个条件类别概率P(Classi|Object)——在一个栅格包含一个Object的前提下它属于某个类的概率。为每一个栅格预测一组类概率。
在测试的非极大值抑制阶段,对于每个栅格:将每个bbox的置信度和类概率相乘,
class-specific confidence scores=Confidence * P(Classi|Object) = P(classi) * IOU,
结果既包含了类别信息又包含了对bbox值的准确度。然后设置一个阈值,把低分的滤掉,剩下的投给非极大值抑制,然后得到最终标定框。
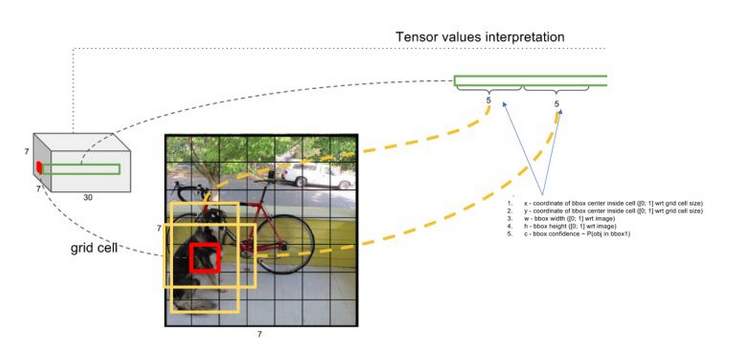
4.模型训练
首先预训练一个分类网络。在 ImageNet 1000-class competition dataset上预训练一个分类网络,这个网络是Figure3中的前20个卷机网络+average-pooling layer(平均池化层)+ fully connected layer(全连接层) (此时网络输入是224*224)。
然后训练我们的检测网络。转换模型去执行检测任务,《Object detection networks on convolutional feature maps》提到说在预训练网络中增加卷积和全链接层可以改善性能。在作者的例子基础上添加4个卷积层和2个全链接层,随机初始化权重。检测要求细粒度的视觉信息,所以把网络输入把224*224变成448*448。
5.损失函数
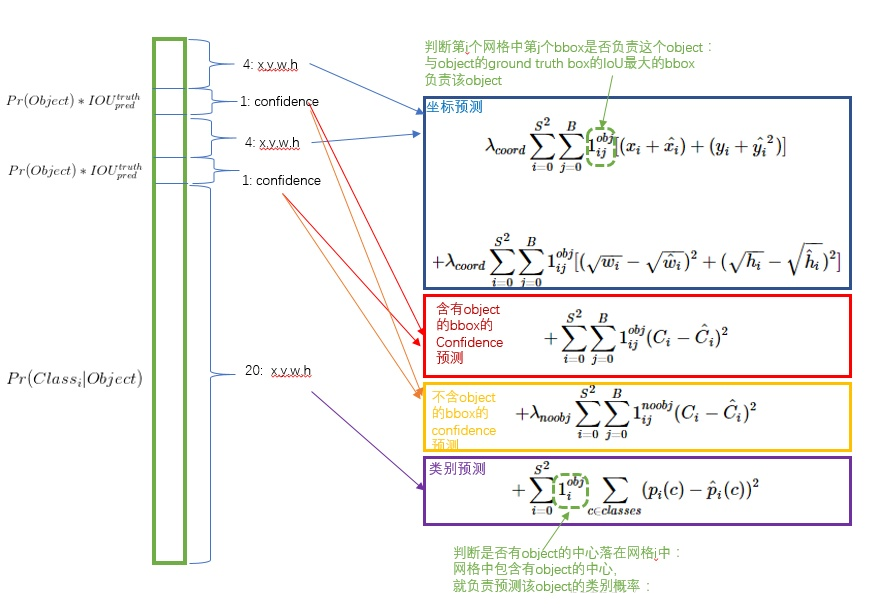

 浙公网安备 33010602011771号
浙公网安备 33010602011771号