数据采集第三次作业
作业①:
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件中,并给出截图。
实践代码:
单线程:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def imageSpider(start_url):
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
images=soup.select("img")
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
count=count+1
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("images\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded"+str(count)+ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
count=0
imageSpider(start_url)
多线程:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
def imageSpider(start_url):
global threads
global count
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,"lxml")
images=soup.select("img")
for image in images:
try:
src=image["src"]
url=urllib.request.urljoin(start_url,src)
if url not in urls:
print(url)
count=count+1
T=threading.Thread(target=download,args=(url,count))
T.setDaemon(False)
T.start()
threads.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url,count):
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("images2\\"+str(count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded"+str(count)+ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers={
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"
}
count=0
threads=[]
imageSpider(start_url)
for t in threads:
t.join()
print("The END")
实践结果:
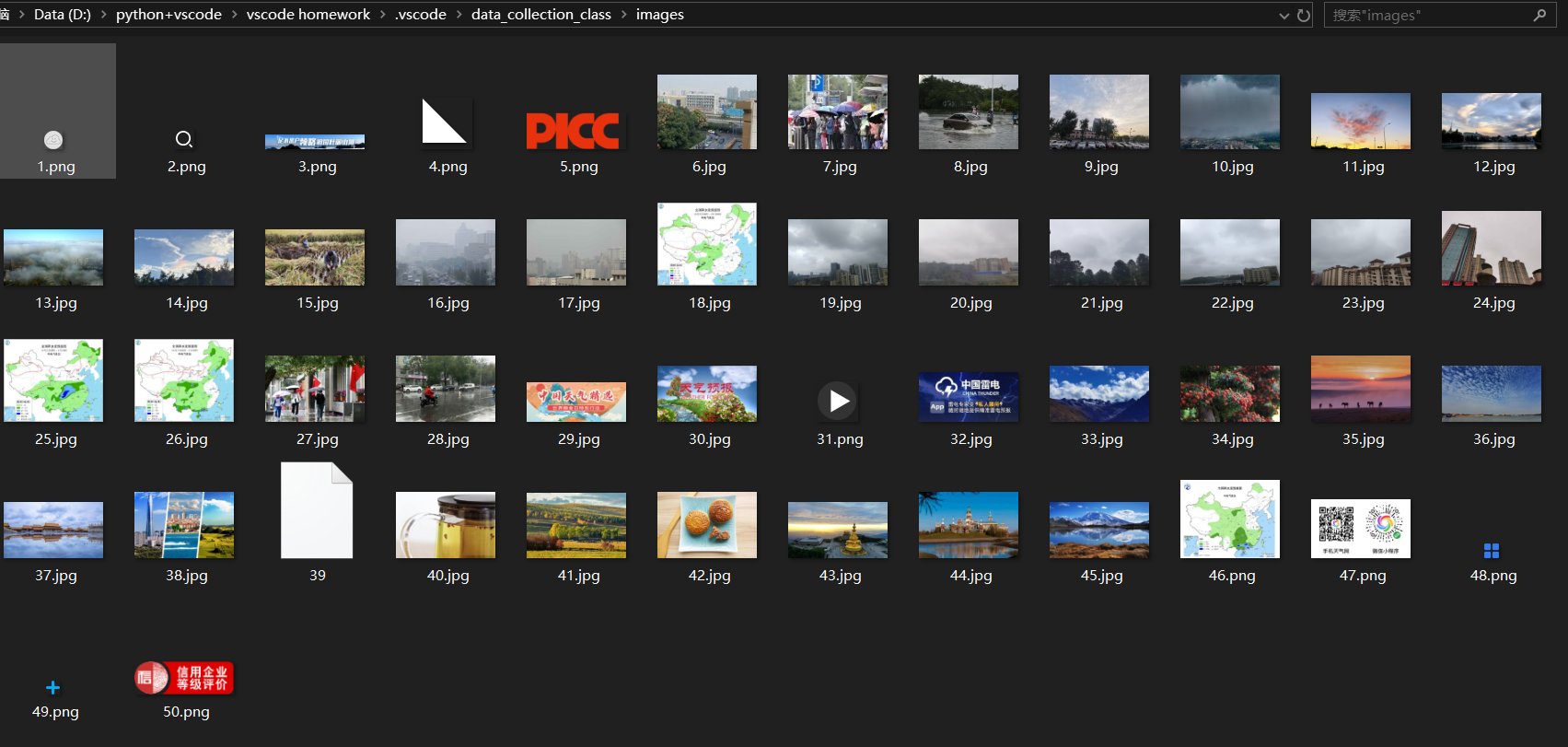
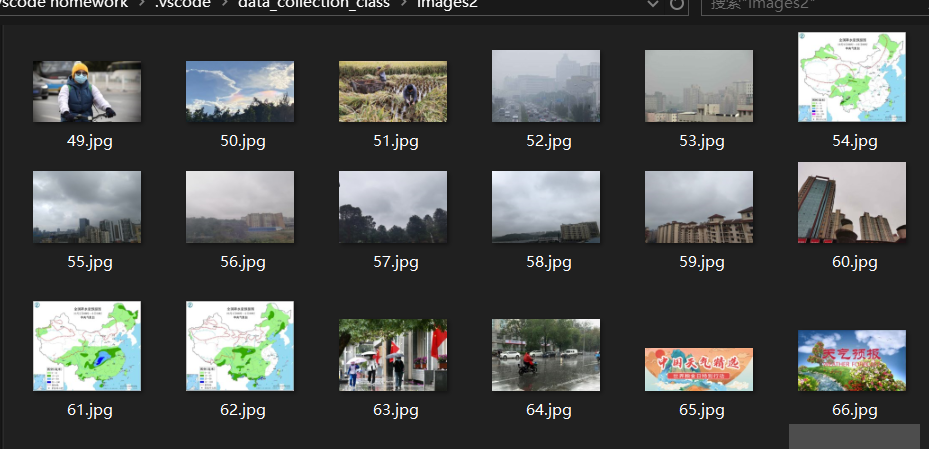
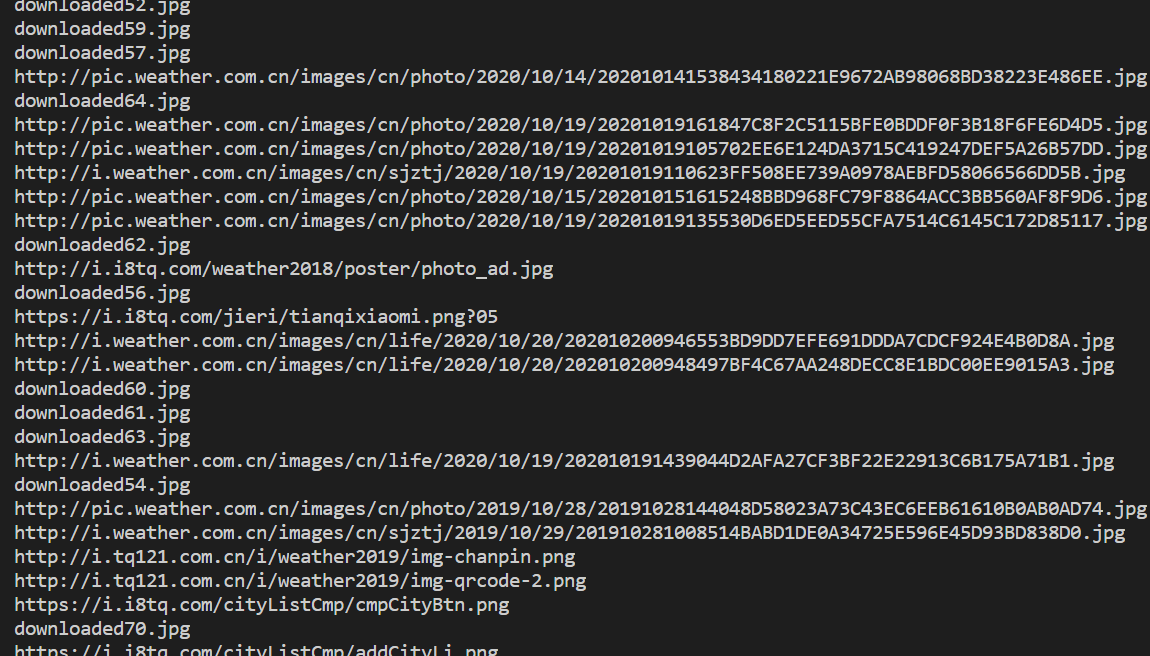
实践心得:
本题是书本单线程多线程的复现,加深了对于单线程和多线程的理解。通常来说,单线程是程序执行时,是顺序的,而多线程可以多个线程同时工作,效率要更高,但是多线程由于多个线程,而需要线程切换,时间代价也是比较高的。
作业②
要求:使用scrapy框架复现作业①。
输出信息:
同作业①
实践代码:
imgsdemo.py:
import scrapy
from imgs.items import ImgsItem
class ImgdemoSpider(scrapy.Spider):
name = 'imgdemo'
start_urls = ['http://www.weather.com.cn/']
def parse(self, response):
data=response.body.decode()
selector=scrapy.Selector(text=data)
urls=selector.xpath("//img/@src").extract()
print(urls)
for url in urls:
item=ImgsItem()
item["src"]=url
yield item
pipelines.py:
from itemadapter import ItemAdapter
import urllib.request
class ImgsPipeline(object):
count=0
def process_item(self, item, spider):
url=item["src"]
ImgsPipeline.count+=1
try:
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
else:
ext=""
req=urllib.request.Request(url)
data=urllib.request.urlopen(req,timeout=100)
data=data.read()
fobj=open("D:/python+vscode/vscode homework/.vscode/data_collection_class/imgs/images1/"+str(ImgsPipeline.count)+ext,"wb")
fobj.write(data)
fobj.close()
print("downloaded"+str(ImgsPipeline.count)+ext)
except Exception as err:
print(err)
return item
settings.py:
ITEM_PIPELINES = {
'imgs.pipelines.ImgsPipeline': 300,
}
实践结果:
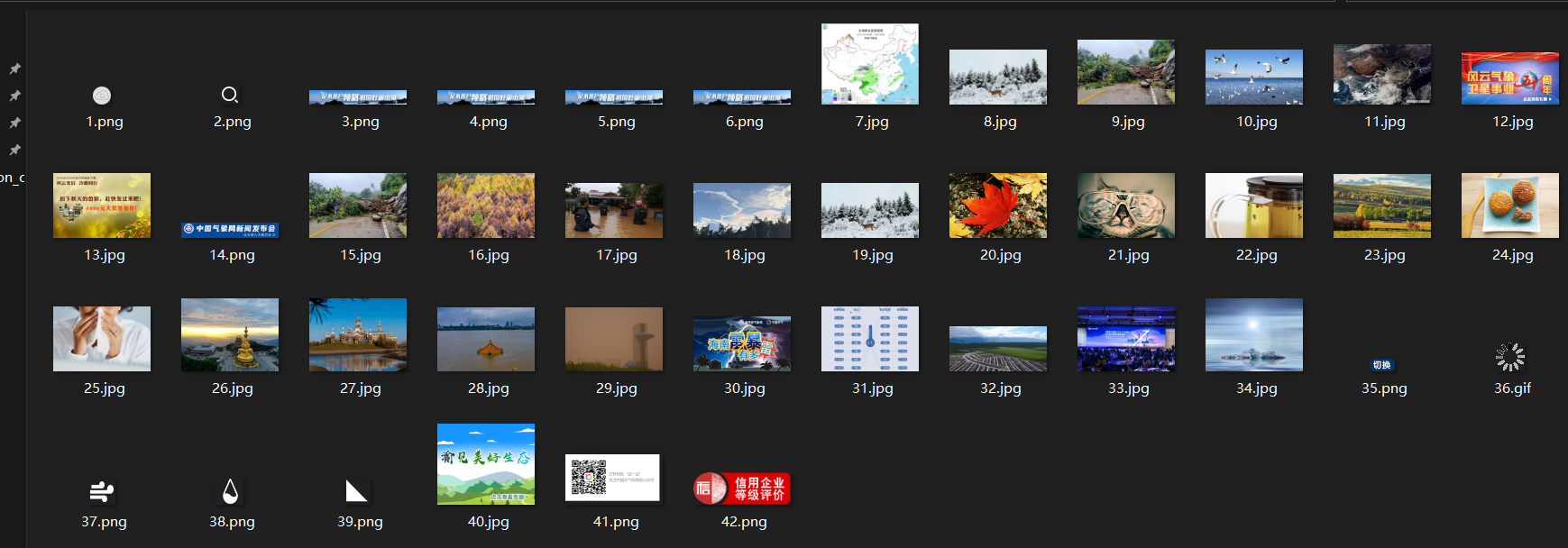
实践心得:
本来对scrapy框架比较模糊,通过练习和书本的研习之后,框架清晰了很多,另外这一题的收获就是xpath查找元素,非常方便。
作业③:
要求:使用scrapy框架爬取股票相关信息。
实践代码:
stocksdemo.py:
# -*- coding = utf-8 -*-
# 031804109
import scrapy
from ..items import StocksItem
import requests
import re
class StocksdemoSpider(scrapy.Spider):
name = 'stocksdemo'
start_urls = ['http://20.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112407443612688541915_1603112547924&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1603112547928']
def parse(self, response):
# url = [
# 'http://20.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112407443612688541915_1603112547924&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:0+t:6,m:0+t:13,m:0+t:80,m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1603112547928']
# headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko"}
#r = requests.get(url, headers=headers).text
r = response.text
pat0 = '"diff":\[\{(.*?)\}\]'
data = re.compile(pat0, re.S).findall(r)
datas = data[0].split('},{')
print("序号\t股票代码\t股票名称\t最新报价\t涨跌幅\t涨跌额\t成交量\t成交额\t振幅\t最高价\t最低价\t今开\t昨开")
for i in range(len(datas)):
item = StocksItem()
str1 = r'"(\w)+":'
stock = re.sub(str1, " ", datas[i])
stock = stock.split(",")
item["Snumber"] = str(i+1)
item["Code"] = stock[11]
item["name"] = stock[13]
item["Latest_price"] = stock[1]
item["UD_range"] = stock[2]
item["UD_price"] = stock[3]
item["Deal_num"] = stock[4]
item["Deal_price"] = stock[5]
item["Amplitude"] = stock[6]
item["Up_est"] = stock[14]
item["Down_est"] = stock[15]
item["Today"] = stock[16]
item["Yesterday"] = stock[17]
print(item["Snumber"]+" "+item["Code"] + ' ' + item["name"] + ' ' + item["Latest_price"] + ' ' + item["UD_range"] + ' ' + item["UD_price"] + ' ' + item["Deal_num"] + ' ' + item["Deal_price"] + ' ' +item["Amplitude"] + ' ' + item["Up_est"] + ' ' + item["Down_est"] + ' ' + item["Today"] + ' ' + item["Yesterday"])
yield item
items.py:
import scrapy
class StocksItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
Snumber=scrapy.Field()
Code=scrapy.Field()
name=scrapy.Field()
Latest_price=scrapy.Field()
UD_range=scrapy.Field()
UD_price=scrapy.Field()
Deal_num=scrapy.Field()
Deal_price=scrapy.Field()
Amplitude=scrapy.Field()#振幅
Up_est=scrapy.Field()
Down_est=scrapy.Field()
Today=scrapy.Field()
Yesterday=scrapy.Field()
settings.py:
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'stocks.pipelines.StocksPipeline': 300,
}
run.py:
from scrapy import cmdline
cmdline.execute("scrapy crawl stocksdemo -s LOG_ENABLED=False".split())
实践结果:

实践心得:
这次这一题耗时挺长的,跟之前题目差不多,但是由于打的时候,把某些变量放错了位置,写错了文件名,而我又处于那种当局者迷的状态,没看出来细节的误差,导致无法运行,耗费了不少时间,还是要细心点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号