Zookeeper的基本概念
第一部分: Zookeeper 简介
Zookeeper 是 Google 的 Chubby一个开源的实现,是 Hadoop 的分布式协调服务
自2010年10月升级成Apache Software Foundation(ASF)顶级项目
分布式协调服务,提供以下功能:
-
组管理服务
-
分布式配置服务
-
分布式同步服务
-
分布式命名服务
谁在使用 Zookeeper
开源软件
-
HBase 开源的非关系型分布式数据库
-
Solr Apache Lucene项目的开源企业搜索平台
-
Storm 分布式计算框架
-
Neo4j 高性能的,Nosql图形数据库
-
…
公司
-
Yahoo
-
LinkedIn
-
Twitter
-
Taobao
-
…
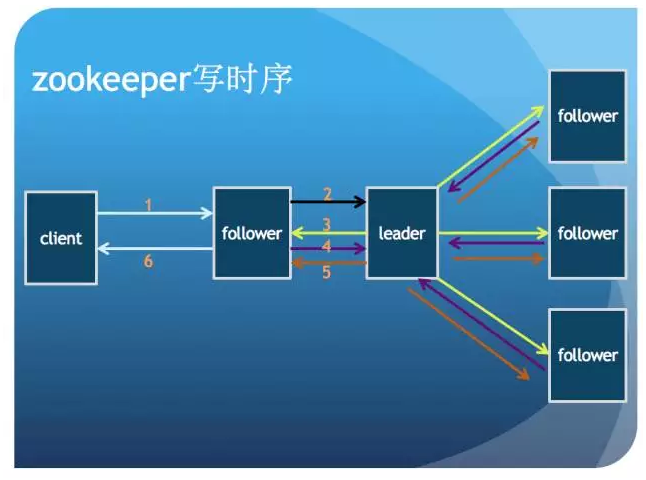
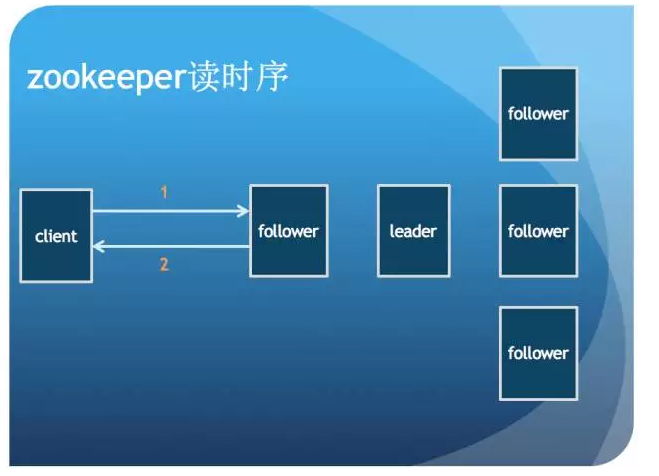
Zookeeper 架构

-
客户端随机连接集群中的任何一台 server
-
集群内所有的 server 基于 Zab(ZooKeeper Atomic Broadcast)协议通信
-
集群内部根据算法自动选举出 leader, 负责向 follower 广播所有变化消息
-
集群中每个follower 都和 leader 通信
-
follower 接收来自 leader 的所有变化消息,保存在自己的内存中
-
follower 转发来自客户端的写请求给 leader
-
客户端的读请求会在 follower 端直接处理,无需转发给 leader
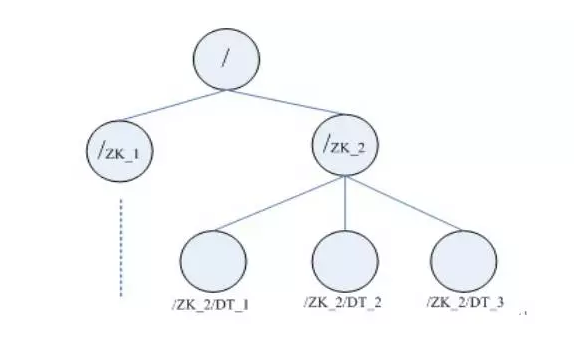
Zookeeper 数据模型
-
基于树形结构的命名空间,与文件系统类似
-
节点(znode)都可以存储数据,可以有子节点
-
节点不支持重命名
-
数据大小不超过1MB(可配置)
-
数据读写保持完整性
Zookeeper 基本 API
Znode 节点类型
-
PERSISTENT
-
PERSISTENT_SEQUENTIAL
-
EPHEMERAL
-
EPHEMERAL_SEQUENTIAL
PERSISTENT(0, false, false),
PERSISTENT_SEQUENTIAL(2, false, true),
EPHEMERAL(1, true, false),
EPHEMERAL_SEQUENTIAL(3, true, true);Sequential/non-sequential节点类型
-
Non-sequential节点不能有重名
-
Sequential节点
-
创建时可重名
-
实际生成节点名末尾自动添加一个10位长度,左边以0填充的单递增数字

Ephemeral/Persistent节点类型
-
Ephemeral节点在客户端session结束或超时后自动删除
-
Persistent节点生命周期和session无关, 只能显式删除

-
注意:EPHEMERAL类型的目录节点不能有子节点目录
ZooKeeper Session
-
客户端和 server 间采用长连接
-
连接建立后, server生成 session id(64位)返还给客户端
-
客户端定期发送 ping 包来检查和保存和 server 的连接
-
一旦 session 结束或超时,所有 ephemeral节点会被删除
-
客户端可根据情况设置合适的 session 超时时间
Zookeeper Watcher
-
Watch 是客户端安装在 server 的事件监听方法
-
当监听的节点发生变化, server 将通知所有注册的客户端
-
客户端使用单线程对所有时间按顺序同步回调
-
触发回调条件:
-
客户端连接,断开连接
-
节点数据发生变化
-
节点本身发生变化
注意:
-
Watch 是单次的,每次触发后会被自动删除
-
如果需要再次监听时间,必须重新安装 Watch
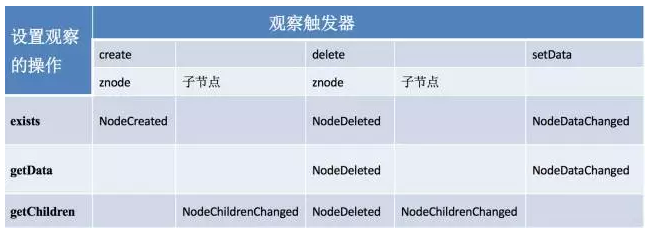
Watch 的创建和触发规则
-
在读操作 exists、getChildren和getData上可以设置观察,这些观察可以被写操作create、delete和setData触发
第二部分:Zooleeper 应用
-
分布式配置管理
-
高可用分布式集群
-
分布式队列
-
分布式锁
分布式配置实现
-
将配置文件信息保存在 Server 某个目录节点中,然后所有需要修改的应用及其监控配置信息的状态
-
一旦配置信息发生变化,每台应用将会收到 server 的通知,然后从 server 获取最新的配置信息到系统中
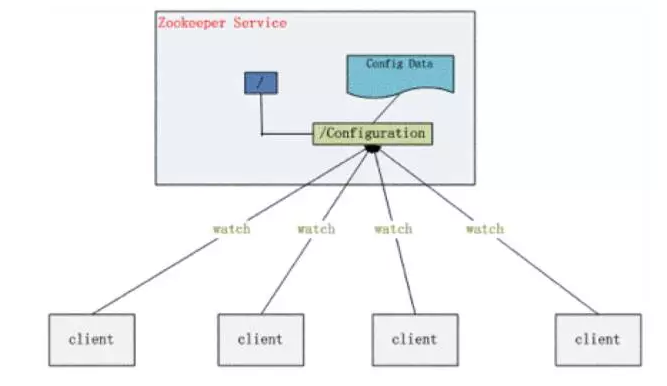
生产配置发布系统解决方案
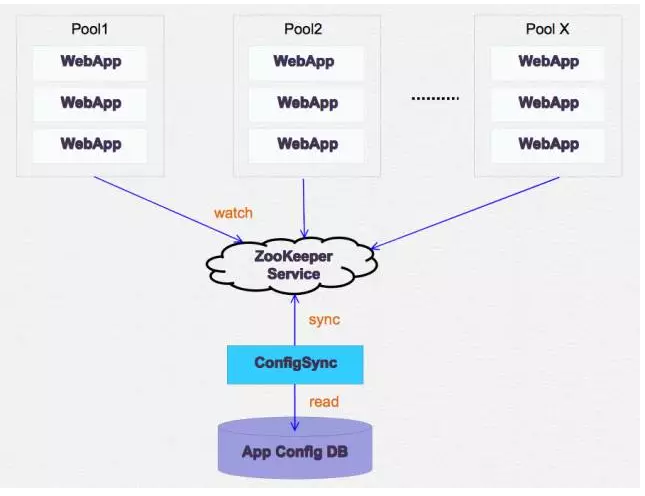
Zookeeper + Dubbo
高可用分布式集群方案(下回分解)

集群管理
数据库宕机检测方案
-
使用定时任务监控 oracle 进程(端口),开机自启动;
-
如果监测到有 oracle 进程,调用 monitor service,退出定时任务;
-
monitor service 负责监听oracle 端口;
-
monitor 依赖于 zookeeperclient service;
-
zookeeperclient service 负责连接 Zookeeper server 创建临时节点;
-
当 oracle 进程退出时,monitor service 停止 zookeeperclient service
-
zookeeperclient service 与 server 断开后,server 自动删除临时节点;
-
monitor service 向管理员邮箱发送数据库宕机邮件,写入日志;
-
当 数据库服务器宕机时,zookeeperclient service与 Server 断开连接,自动删除临时节点
具体实现
zookeeperclient.sh
#!/bin/bash # /etc/init.d/zookeeperclient.sh case "$1" in start) echo "Starting Zookeeper Client" python /home/master/zookeeperclient.py & ;; stop) echo "Stopping Zookeeper Client" #killall zookeeperclient.py kill $(ps aux | grep -m 1 'python /home/master/zookeeperclient.py' | awk '{ print $2 }') ;; *) echo "Usage: service Client start|stop" exit 1 ;; esac exit 0
zookeeperclient.py
#!/usr/local/bin/python3from kazoo.client import KazooClientimport time zk = KazooClient(hosts = '192.168.43.125:2181',connection_retry = True) zk.start() zk.create("/datasource/datasource1", b"DATASOURCE1", None, True, False, True)while True: try: time.sleep(2) except (KeyboardInterrupt, SystemExit): zk.stop()
monitor.sh
#!/bin/bash # /etc/init.d/monitor.sh case "$1" in start) python3 /Users/codeai/Desktop/monitor.py & sleep 2 if [ "$(ps -ef | grep zookeeperclient.py | grep -v grep | awk '{ print $2 }')" = ""] then exit 1 else python3 /Users/codeai/Desktop/zookeeperclient.py & fi ;; stop) kill $(ps -ef | grep zookeeperclient.py | grep -v grep | awk '{ print $2 }') sleep 2 kill $(ps -ef | grep monitor.py | grep -v grep | awk '{ print $2 }') ;; *) echo "Usage: service command start|stop" exit 1 ;; esac exit 0
monitor.py
def socketmronitor(): line = "127.0.0.1 8080" ip = line.split()[0] port = int(line.split()[1]) while True: try: sc = socket.socket(socket.AF_INET, socket.SOCK_STREAM) print(ip, port) sc.settimeout(2) sc.connect((ip, port)) timenow = time.localtime() datenow = time.strftime('%Y-%m-%d %H:%M:%S', timenow) print("%s:%s 连接成功->%s \n" % (ip, port, datenow)) sc.close() time.sleep(3) except Exception as e: file = open("socketmonitor_err.log", "a") timenow = time.localtime() datenow = time.strftime('%Y-%m-%d %H:%M:%S', timenow) file.write("%s:%s 连接失败->%s \n" % (ip, port, datenow)) file.close() send_mail(['348055827@qq.com'], 'Oracle quit', sysinfo()) exit(-1)
server端监听节点变化
Watcher wh = new Watcher() { public void process(WatchedEvent event) { // 如果发生了"/datasource"节点下的子节点变化事件, 更新server列表, 并重新注册监听 if (event.getType() == Event.EventType.NodeChildrenChanged && ("/" + groupNode).equals(event.getPath())) { try { updateServerList(); } catch (Exception e) { e.printStackTrace(); } } } }; zk = new ZooKeeper("127.0.0.1:2181", Integer.MAX_VALUE, wh);
分布式队列
先说一个通俗易懂的例子:
一个老中医每天只看5个病人,当第一个病人已经挂号(向 Service 注册并且创建了一个节点),但是并未达到5个人的要求,所以这个病人就等待,知道第5个人挂号后,这5个人才会到老中医那儿去看病.
这个就可以简单的理解为分布式队列,5个人是不同 client, 他们都必须等到所有人都向 Zookeeper Server 创建了一个节点,(他们通过对节点的监控从而知晓是否达到5个人),当创建了5个节点后,通过 Watcher 创建一个 start 的节点标识,告知所有的 client, 这个队列已经可以使用了.
具体实现
创建一个父目录 /synchronizing,每个成员都监控目录 /synchronizing/start 是否存在,然后每个成员都加入这个队列(创建 /synchronizing/member_i 的临时目录节点),然后每个成员获取 / synchronizing 目录的所有目录节点,判断 i 的值是否已经是成员的个数,如果小于成员个数等待 /synchronizing/start 的出现,如果已经相等就创建 /synchronizing/start
分布式锁
还是先说一个通俗易懂的例子:
有个科室的女医生很漂亮,很多人慕名前来,但是她一次只会给一个人看病,也是有这么5个人,先去挂号(向 Server 注册),然后每个人拿到了P1,P2…P5编号的牌子.护士从小号开始喊,叫到谁谁就去找女医生玩儿(听护士喊话,然后对比自己手上的号拍,如果叫到的跟自己手上的号牌一样,则说明获得了锁),其他人则等待,
当上一个病人看完病离开之后,将手上的号牌扔掉,护士继续喊号,重复上面的过程.
具体实现
Server 创建一个 EPHEMERAL_SEQUENTIAL 目录节点,然后调用 getChildren方法获取当前的目录节点列表中最小的目录节点是不是就是自己创建的目录节点,如果正是自己创建的,那么它就获得了这个锁,如果不是那么它就调用 exists(String path, boolean watch) 方法并监控 Zookeeper 上目录节点列表的变化,一直到自己创建的节点是列表中最小编号的目录节点,从而获得锁,释放锁很简单,只要删除前面它自己所创建的目录节点就行了。
总结
-
文件系统是一个树形的文件系统,但比linux系统简单,不区分文件和文件夹,所有的文件统一称为znode
-
znode的作用:存放数据,但上限是1M ;存放ACL(access control list)访问控制列表
-
数据模型:短暂znode( zkCli.sh 客户端断掉连接之后,就不存在了)和持久znode
-
顺序号:每个znode在创建的时候都会编一个号,按照那他们就会按照创建的时间编号,同样的父节点的znode共用一套编号
-
观察(watch):观察子节点的变化,类似于我们传统关系型数据库中的触发器
-
操作:create delete setData getData exists(znode是否存在并且查询他的data) getACL setACL
-
集群是无中心的,只要有超过一半以上的节点没有down掉就能工作,出于这个原因,我们zookeeper的节点数通常要设置成奇数。
-
在整个集群没有down掉之前,至少有一个节点是最新的状态,这是通过Zap,该zap协议是包括2个无限重复的阶段:
-
选举(选举出一个leader,其他节点就变成了follower)
-
原子广播(所有写请求转发给leader,再由leader广播给各个follower,当半数以上follower将修改持久化后,leader才会提交这个更新,接下来客户端才会收到一个更新成功的响应)
-
应用:
-
配置文件的同步(放一个watch,检测到数据改动后,立刻同步到其他节点,确保配置文件的一致性)
-
锁机制的实现,比如很多客户端访问一个znode的资源,先给这个znode设置一个观察,观察节点的删除,其他客户端进来后,会添加一个对应的短暂znode,因为zookeeper的顺序号机制,给每个要访问资源的客户端对应的znode分配一个顺序号,通过对比顺序号,决定能不能使用这个资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号