Django框架(六)
正反向查询进阶操作
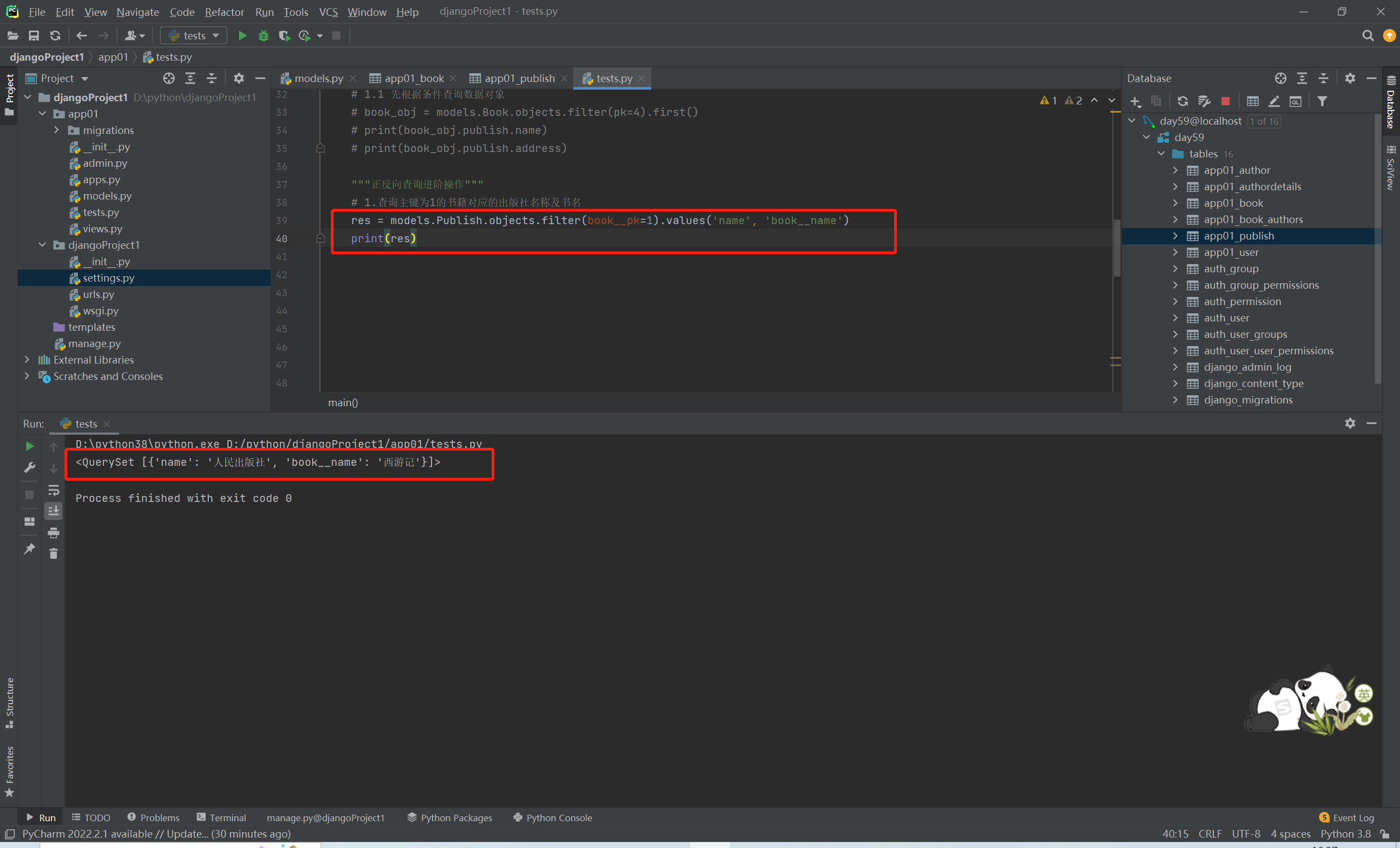
# 1.查询主键为1的书籍对应的出版社名称及书名
res = models.Publish.objects.filter(book__pk=1).values('name','book__name')
# print(res)
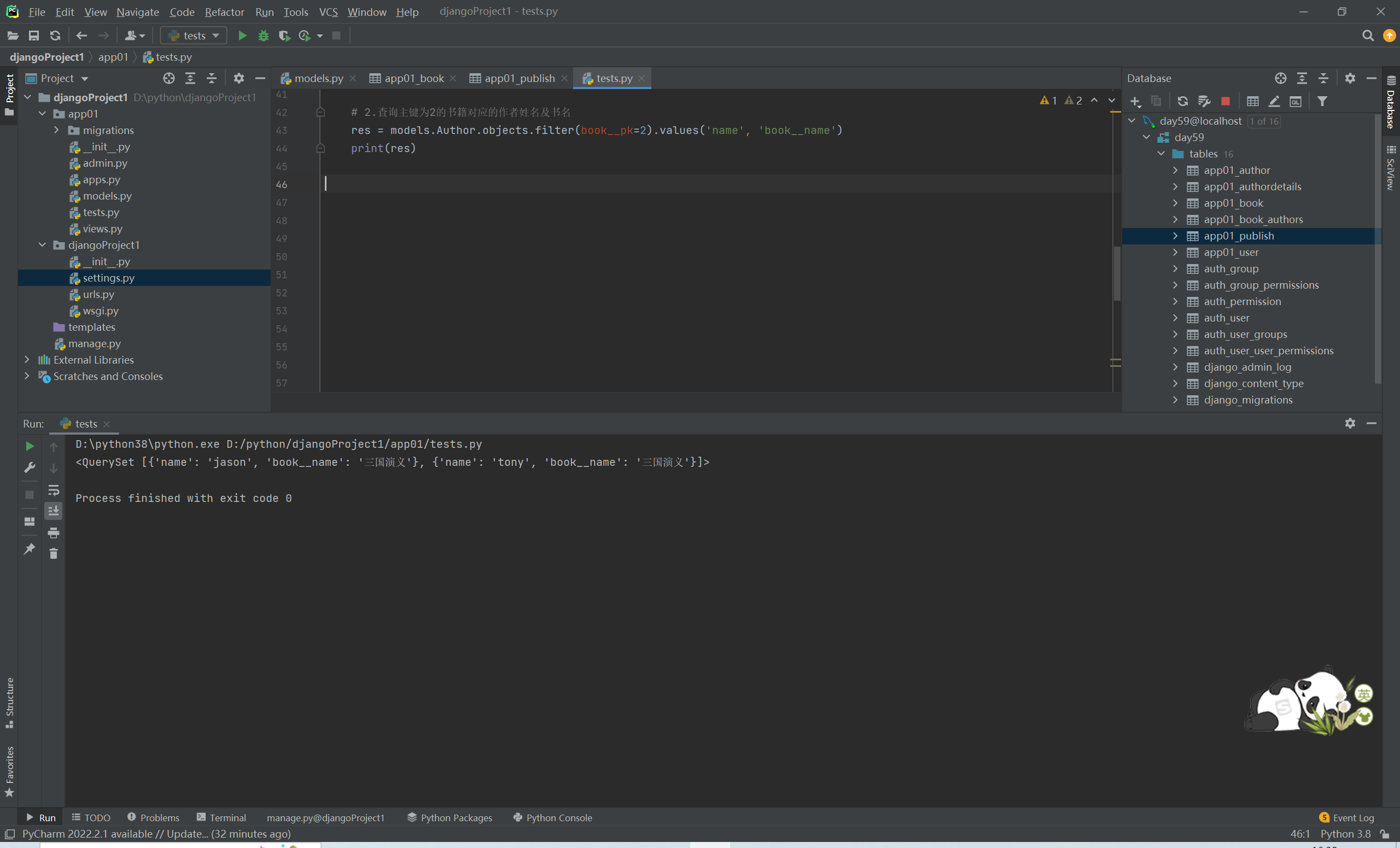
# 2.查询主键为3的书籍对应的作者姓名及书名
res = models.Author.objects.filter(book__pk=1).values('name', 'book__title')
# print(res)
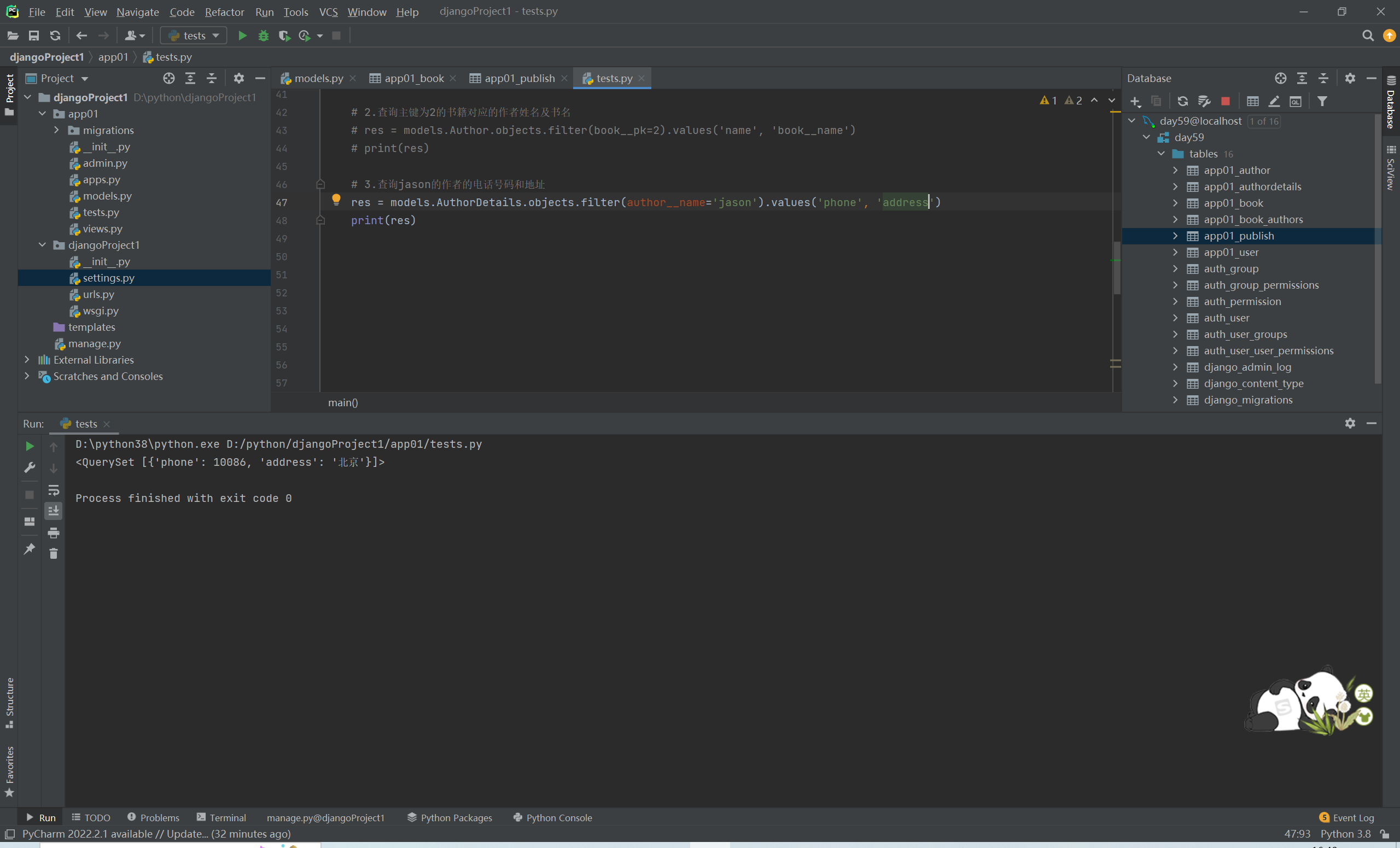
# 3.查询jason的作者的电话号码和地址
res = models.AuthorDetail.objects.filter(author__name='jason').values('phone','addr')
# print(res)
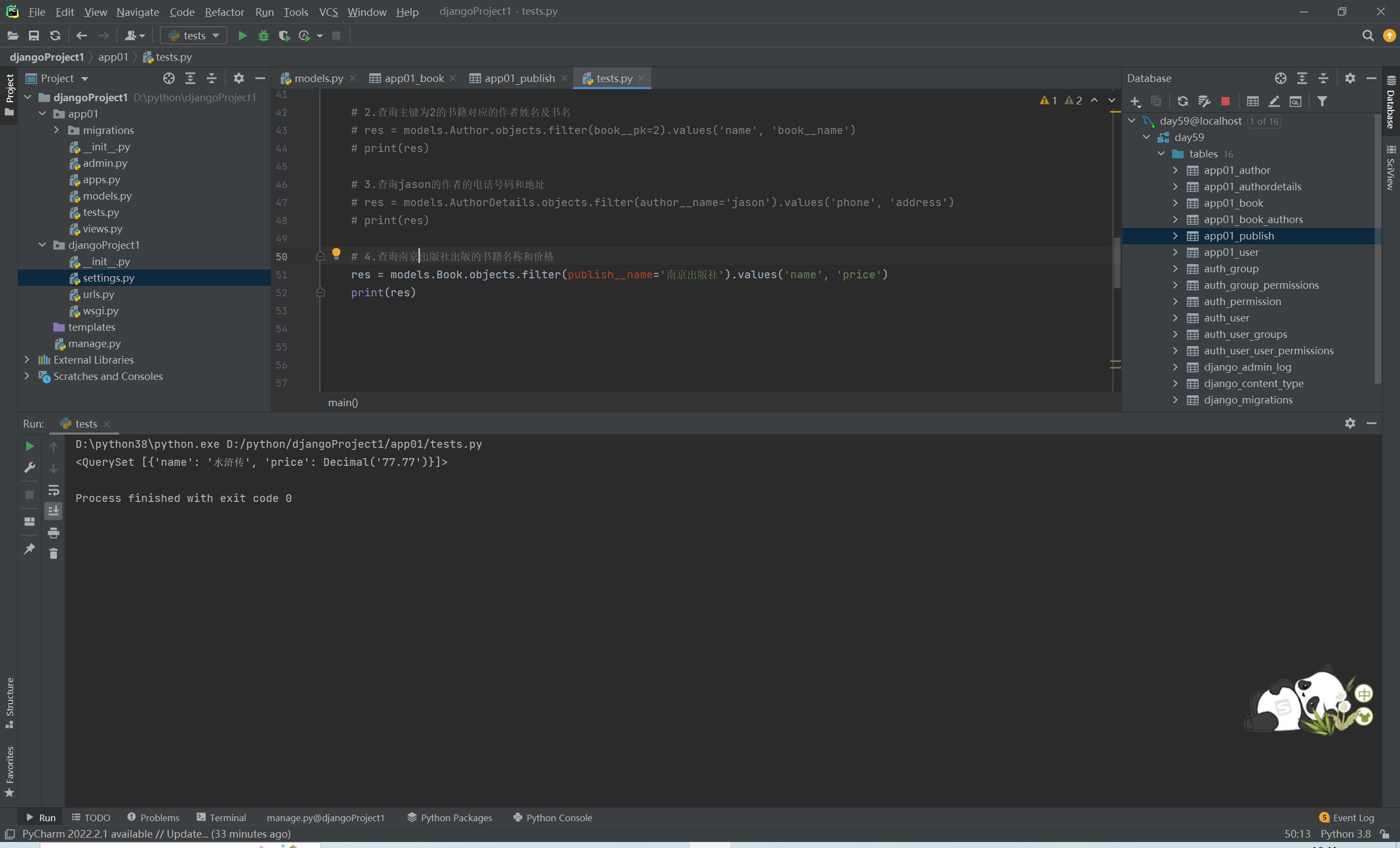
# 4.查询南方出版社出版的书籍名称和价格
res = models.Book.objects.filter(publish__name='南方出版社').values('title','price')
# print(res)
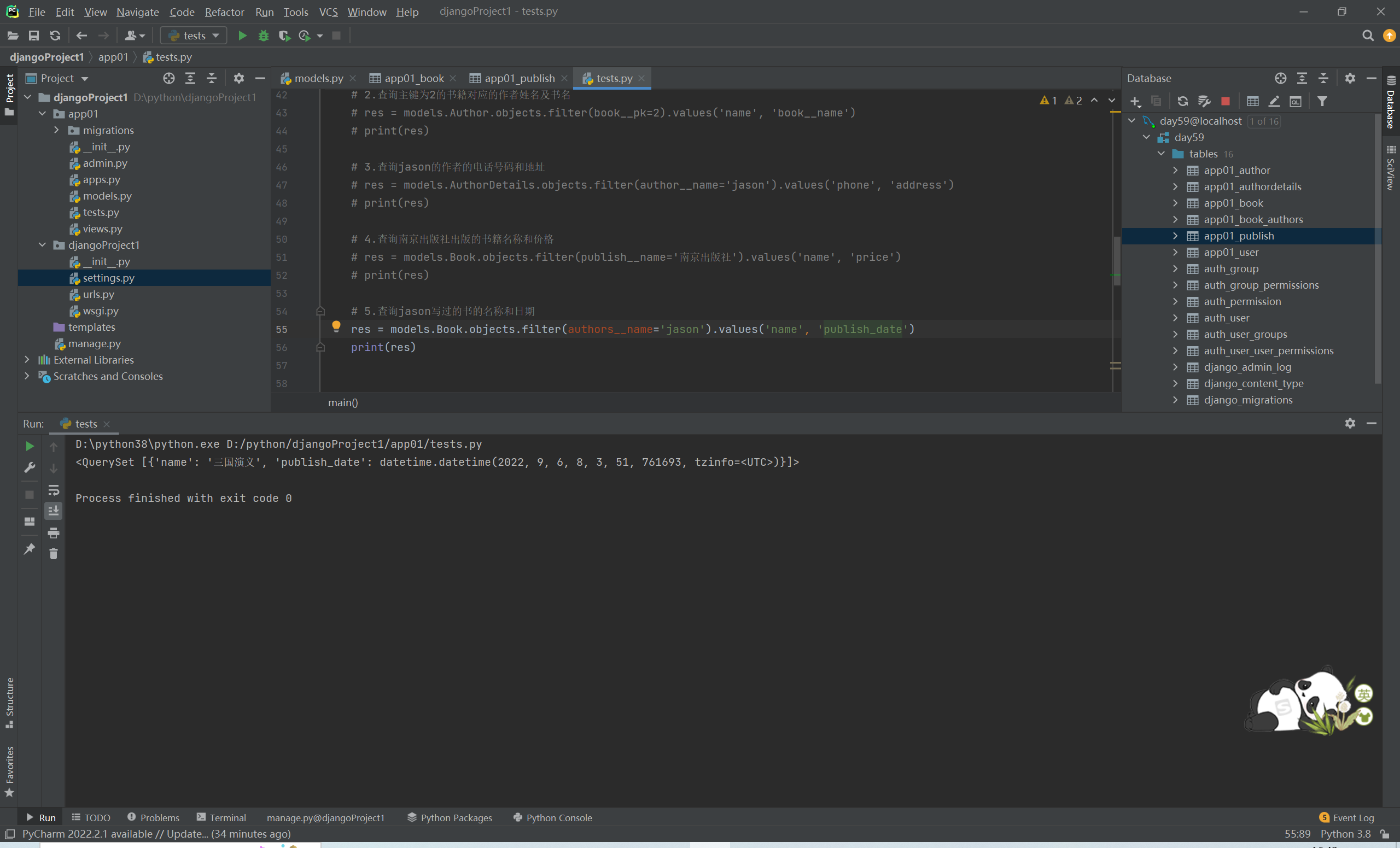
# 5.查询jason写过的书的名称和日期
res = models.Book.objects.filter(authors__name='jason').values('title','publish_time')
# print(res)
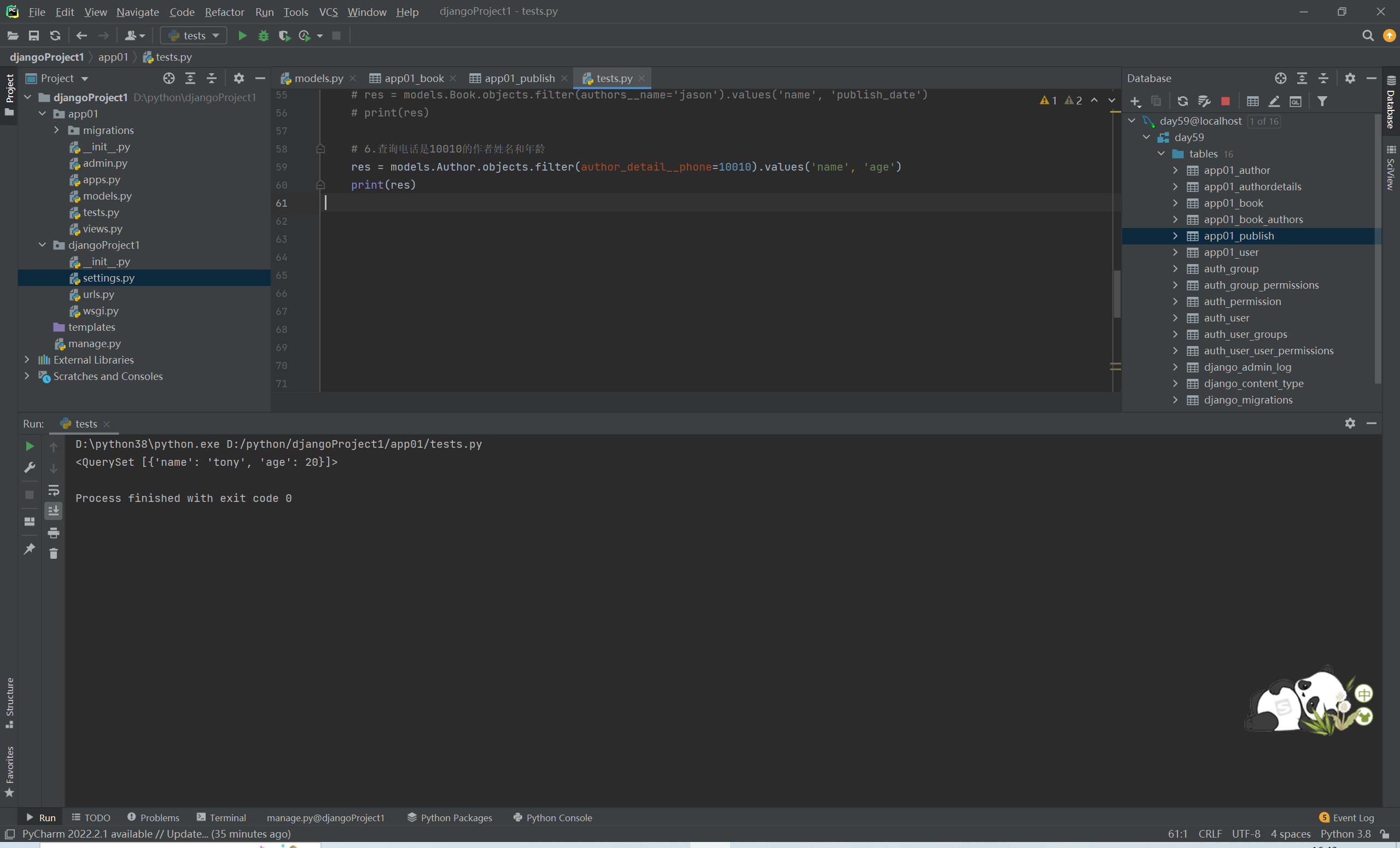
# 6.查询电话是110的作者姓名和年龄
res = models.Author.objects.filter(author_detail__phone=110).values('name','age')
# print(res)
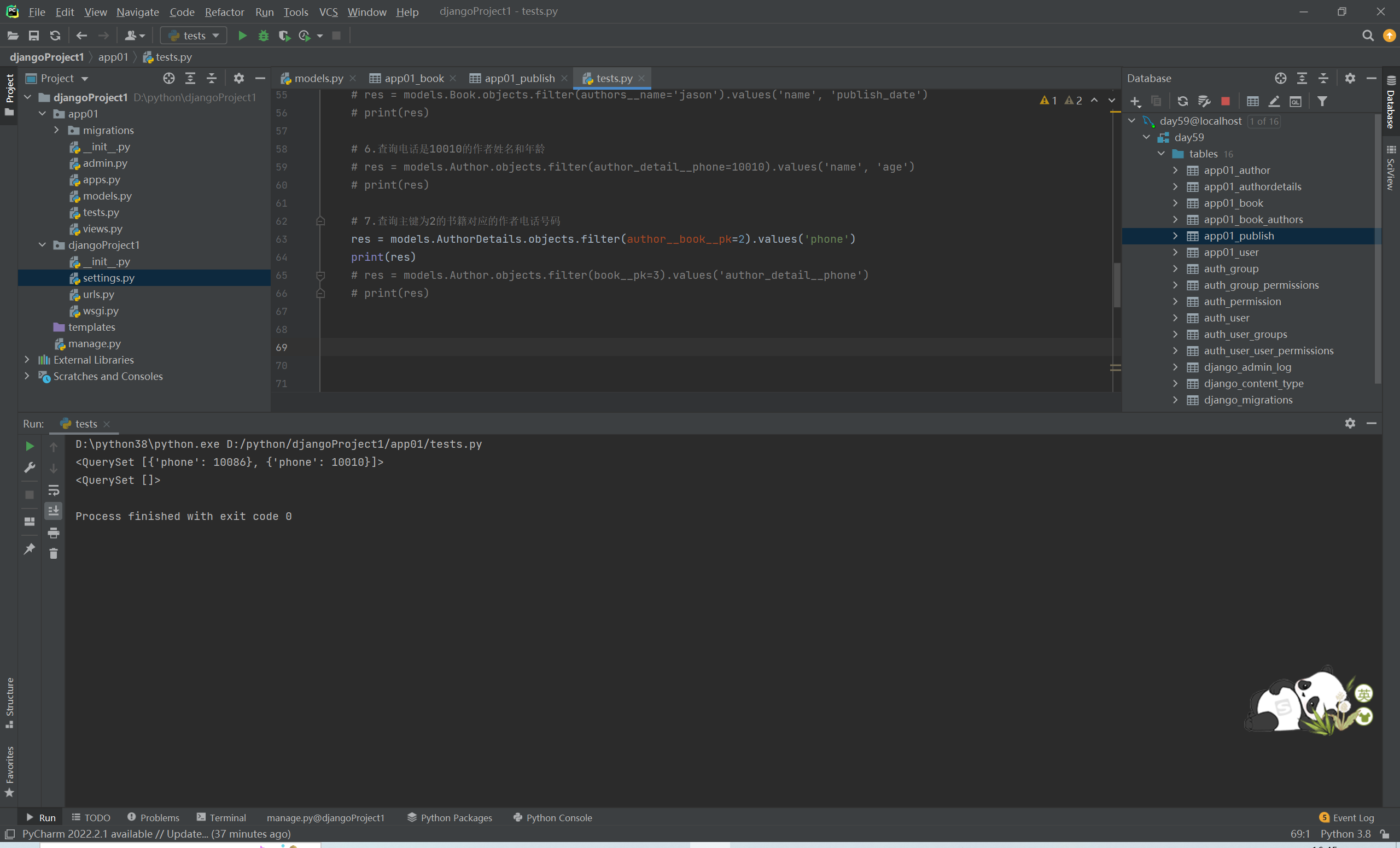
# 7.查询主键为1的书籍对应的作者电话号码
res = models.AuthorDetail.objects.filter(author__book__pk=1).values('phone')
# print(res)
res = models.Author.objects.filter(book__pk=1).values('author_detail__phone')
print(res)
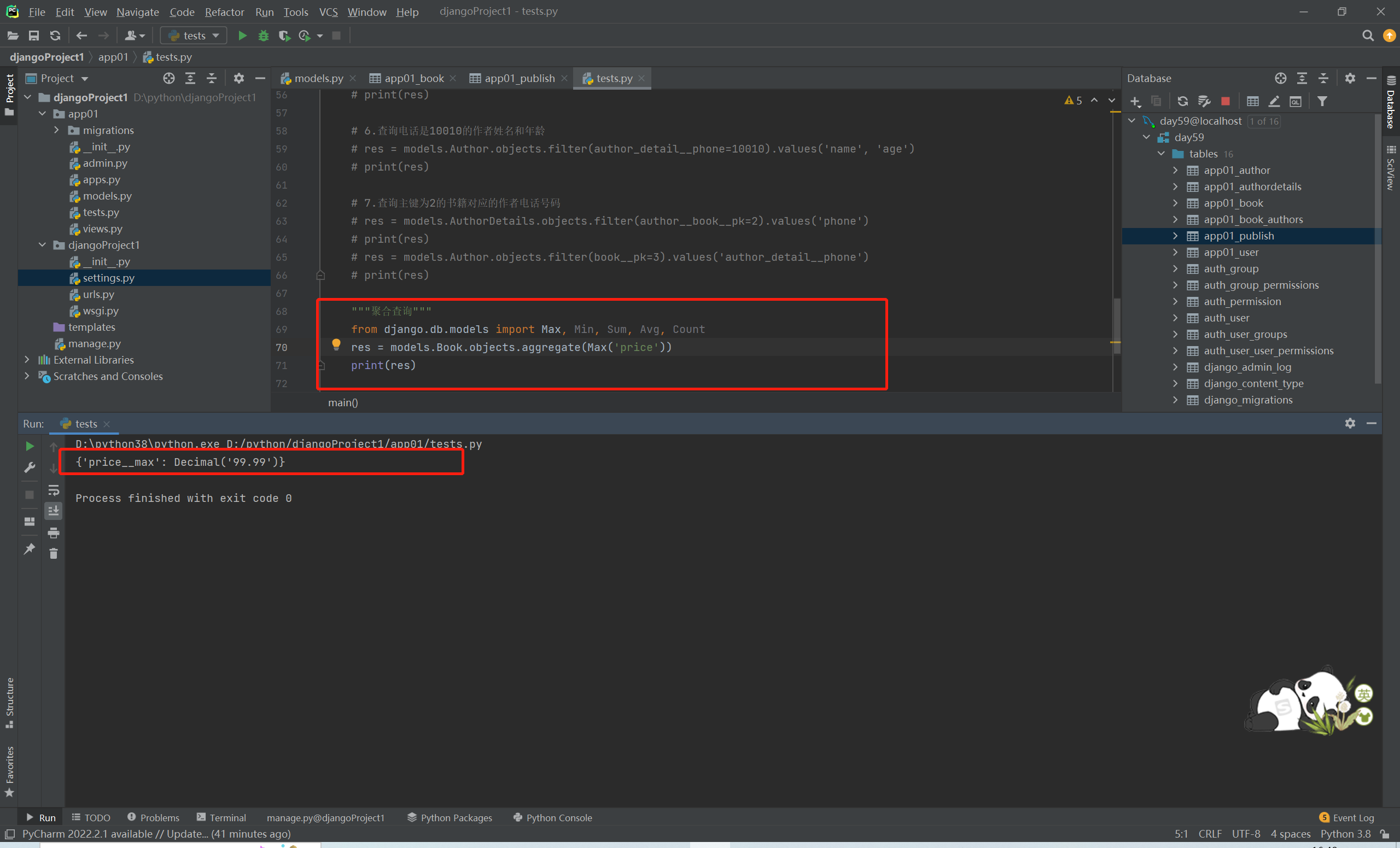
ORM聚合查询
聚合函数:max、min、sum、avg、count
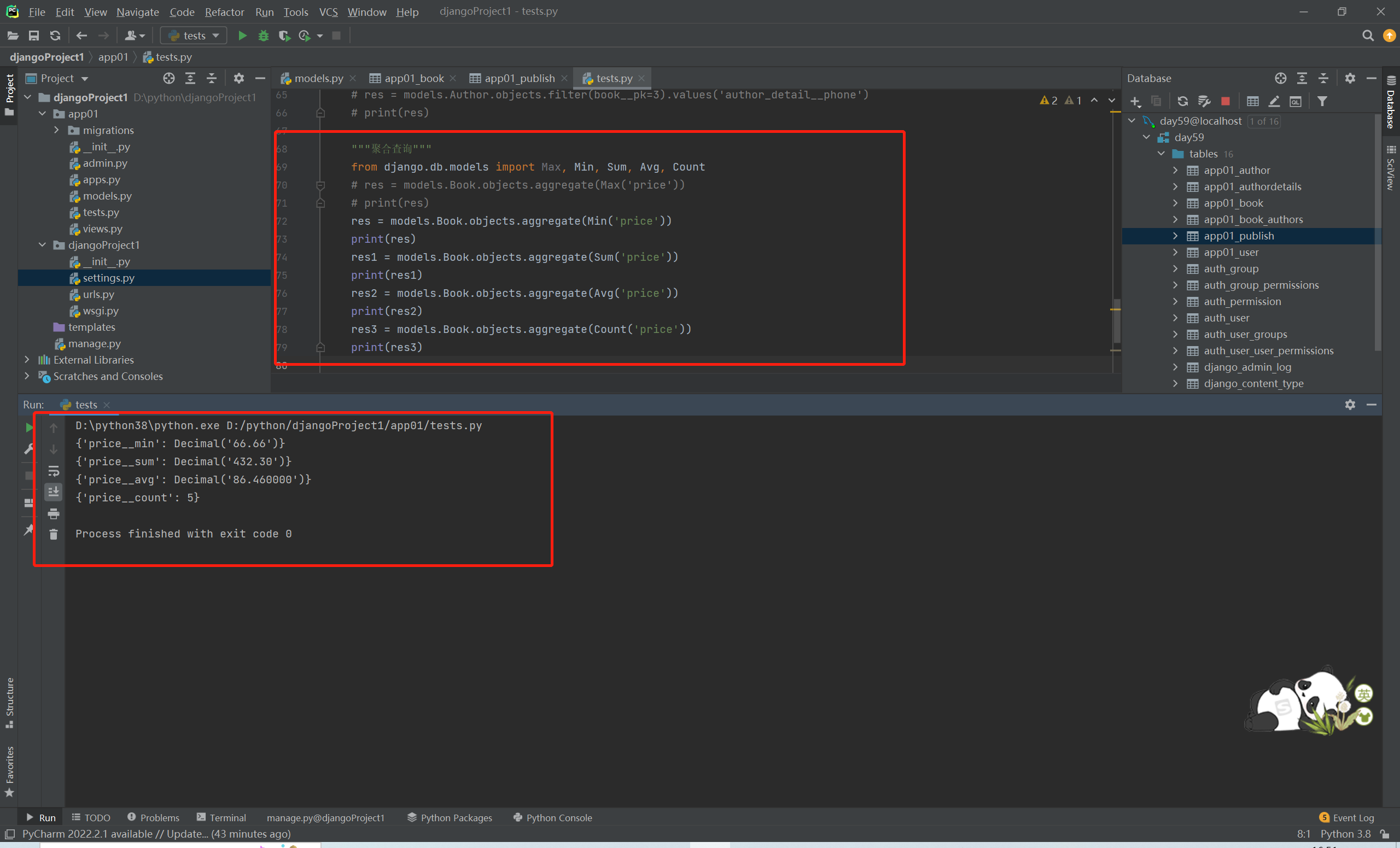
'''聚合查询'''
from django.db.models import Max, Min, Sum, Avg, Count
没有分组之前如果单纯的时候聚合函数 需要关键字aggregate
res = models.Book.objects.aggregate(Max('price'), Min('price'), Sum('price'), Avg('price'), Count('pk'))
print(res)
ORM分组查询
# 关键字:annotate()
# models后面(.)什么就是按什么分组
eg:models.Book.objects.annotate() # 这里就是按照书籍表每本书来分组
示例:
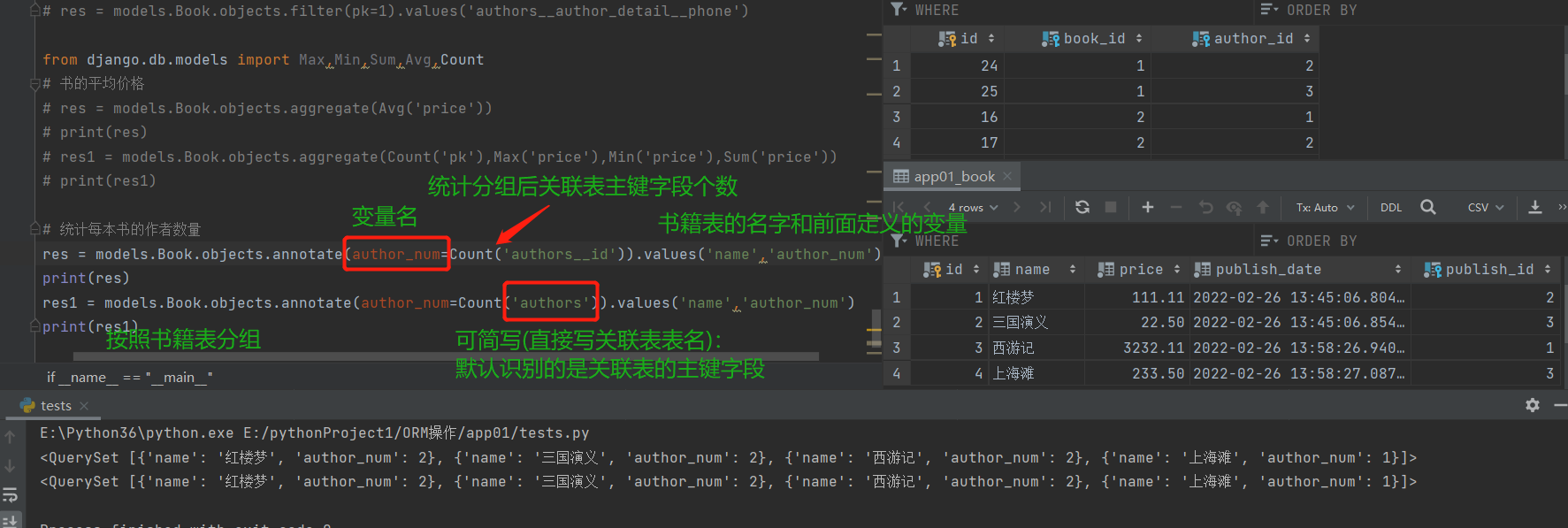
# 统计每本书的作者数量
res = models.Book.objects.annotate(author_num=Count('authors__id')).values('name','author_num')
print(res) # 按照书籍表分组,统计外键字段对应作者表的id
# 简写
res1 = models.Book.objects.annotate(author_num=Count('authors')).values('name','author_num')
print(res1)
# author_num为我们自己定义的字段,用来存储统计出来的每本书对应的作者个数
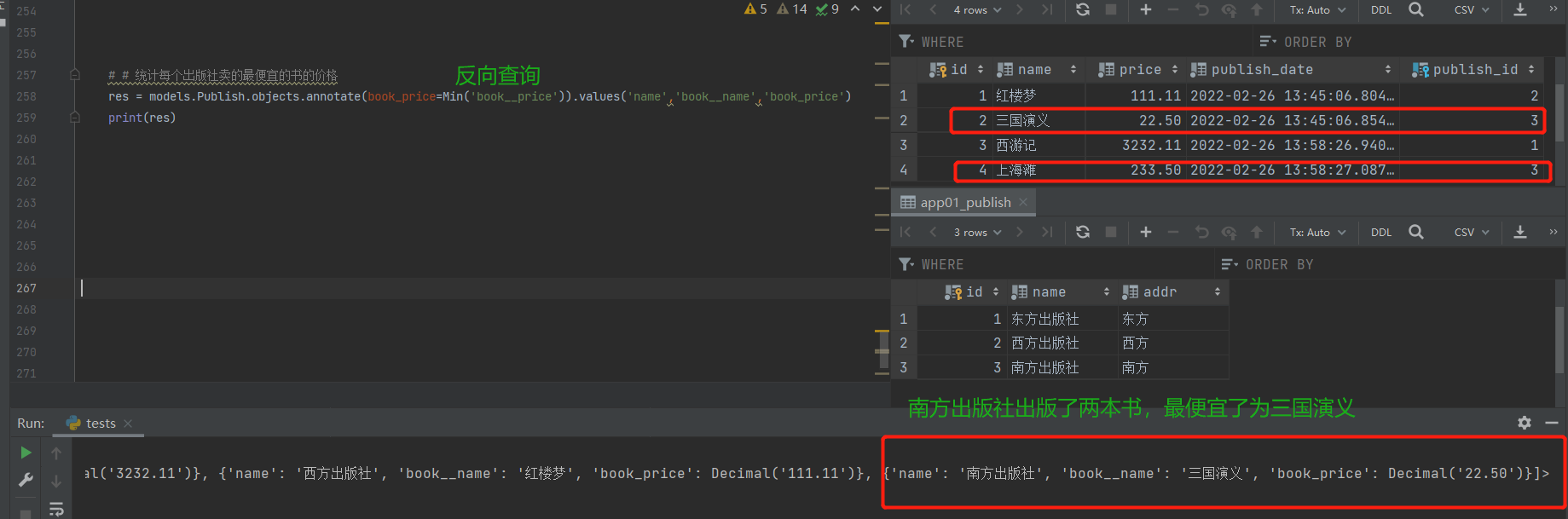
# 统计每个出版社卖的最便宜的书的价格
res = models.Publish.objects.annotate(book_price=Min('book__price')).values('name','book__name','book_price')
print(res)
# 解析:先按出版社分组,然后再统计最便宜书的价格就是用到Min聚合查询,反向查询用表名的小写book,然后要用到书表的价格字段book__price,再通过values方法查找的对应的数据
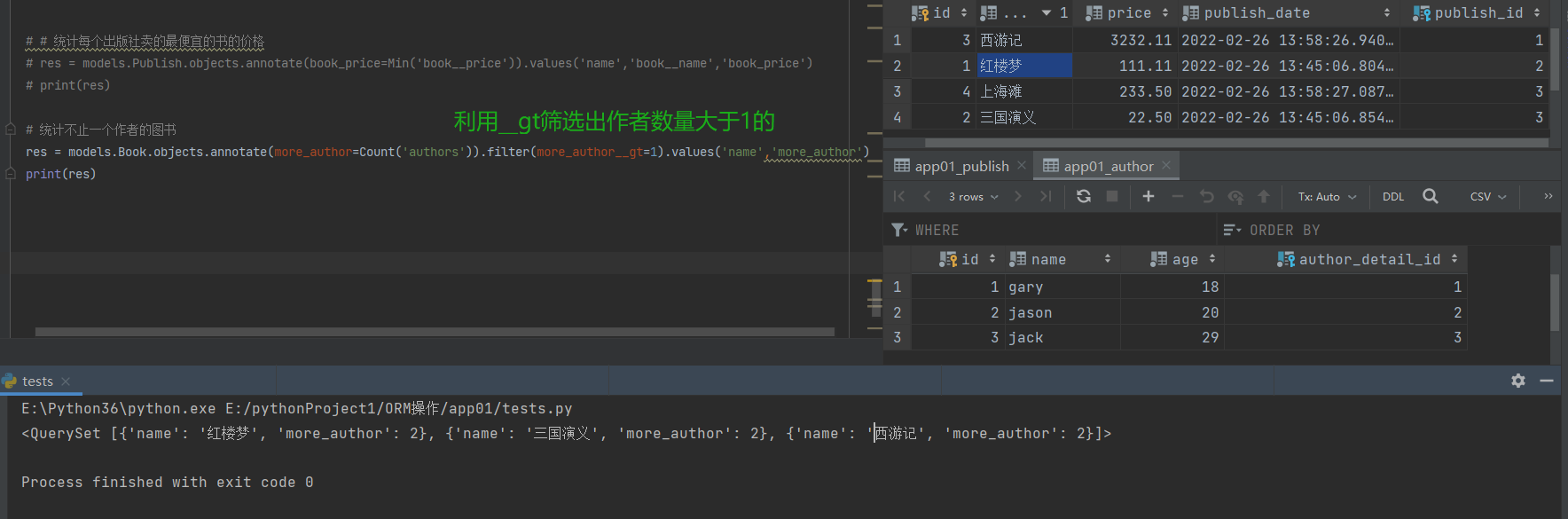
# 统计不止一个作者的图书
res = models.Book.objects.annotate(more_author=Count('authors')).filter(more_author__gt=1).values('name','more_author')
print(res)
# 补充:只要orm语句得出的结果是一个queryset对象,那么它就可以继续无限制的点queryset对象封装的方法。
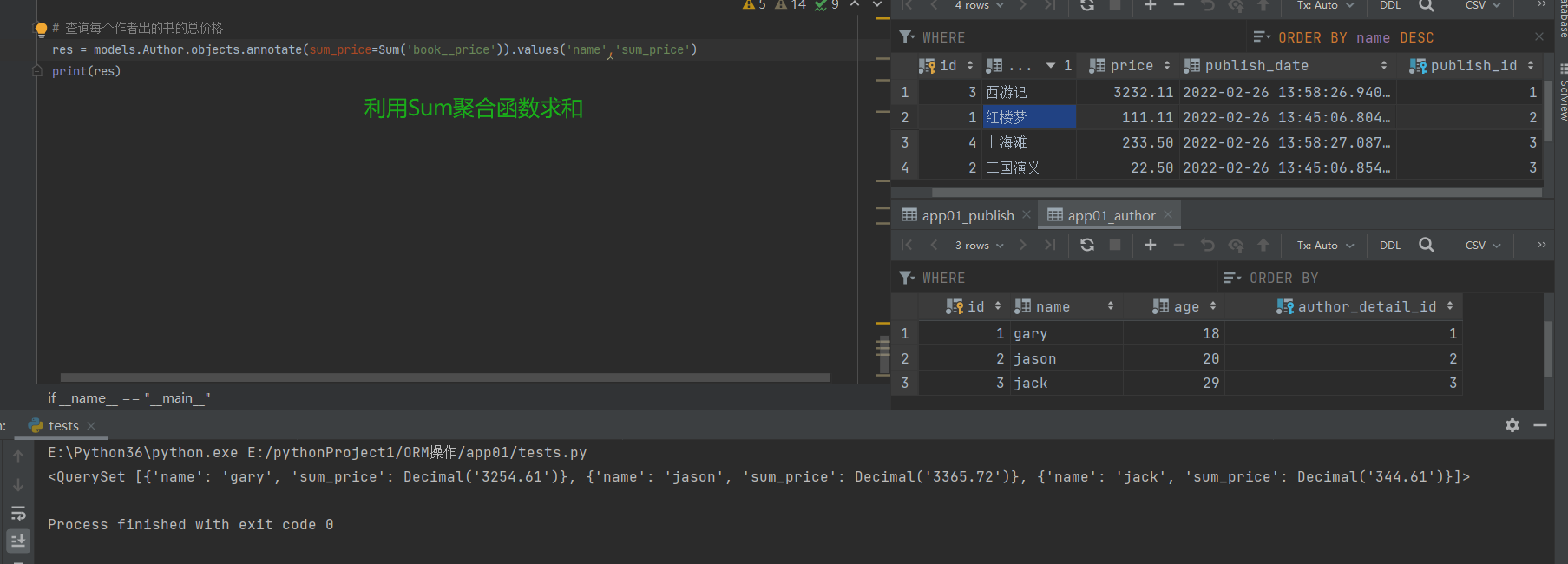
# 查询每个作者出的书的总价格
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','sum_price')
print(res)
如果想按照指定的字段分组该如何处理呢?
# 找到指定的字段后在进行分组
例:models.Book.objects.values('price').annotate()
注:如果在分组查询报错的情况,需要修改数据库的模式。
"""
分组有一个特性 默认只能够直接获取分组的字段 其他字段需要使用方法
我们也可以忽略掉该特性 将sql_mode中only_full_group_by配置移除即可
"""

ORM F与Q查询
- F查询:能够帮助我们直接获取列表中某个字段对应的数据
F查询
示例:
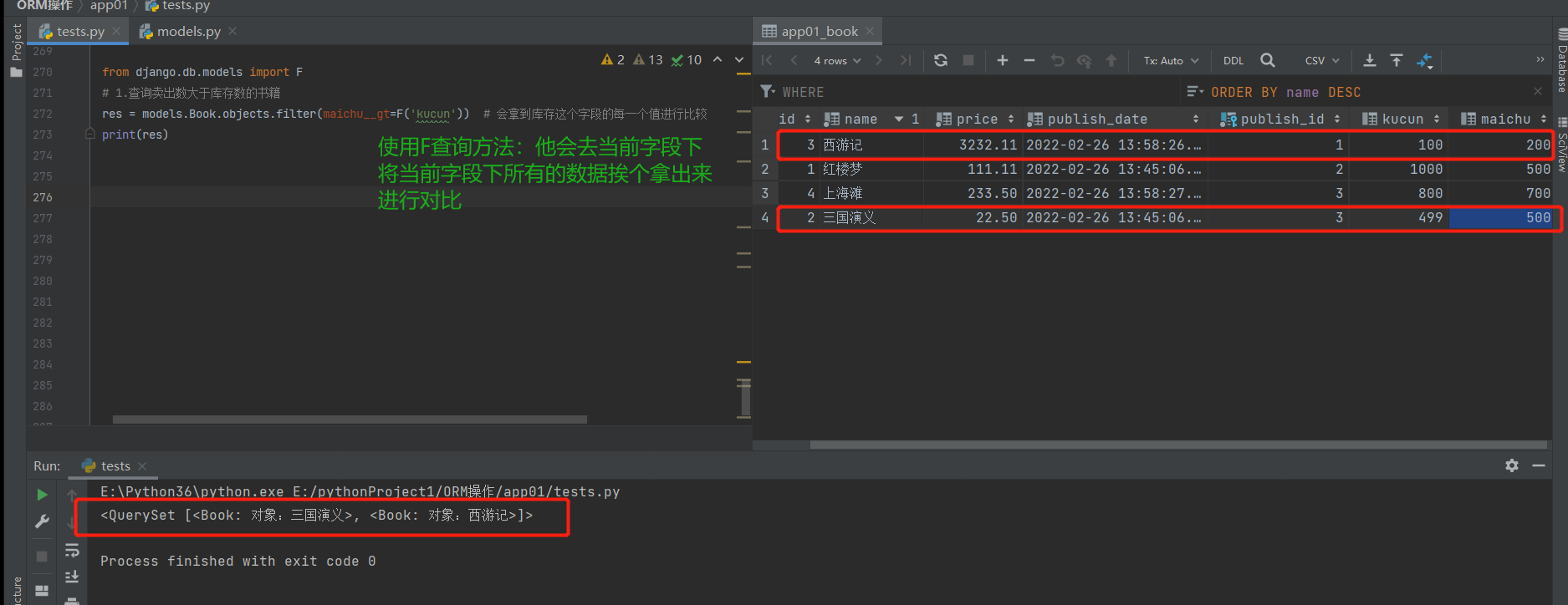
1.查询卖出数大于库存数的书籍
# 使用我们之前所学的知识来看看是否可以完成
res = models.Book.objects.filter(maichu__gt=???)
# 我们可以看到我们之前在使用__gt方法作比较的时候都是给等号后面一个精确的值来做比较,那么现在比较的是一个未知数那么这时就无法做出比较,这里就要用到F查询的方法。
# 使用F查询方法
from django.db.models import F # 需要导入模块
# 1.查询卖出数大于库存数的书籍
res = models.Book.objects.filter(maichu__gt=F('kucun')) # 会拿到库存这个字段的每一个值进行比较
print(res)
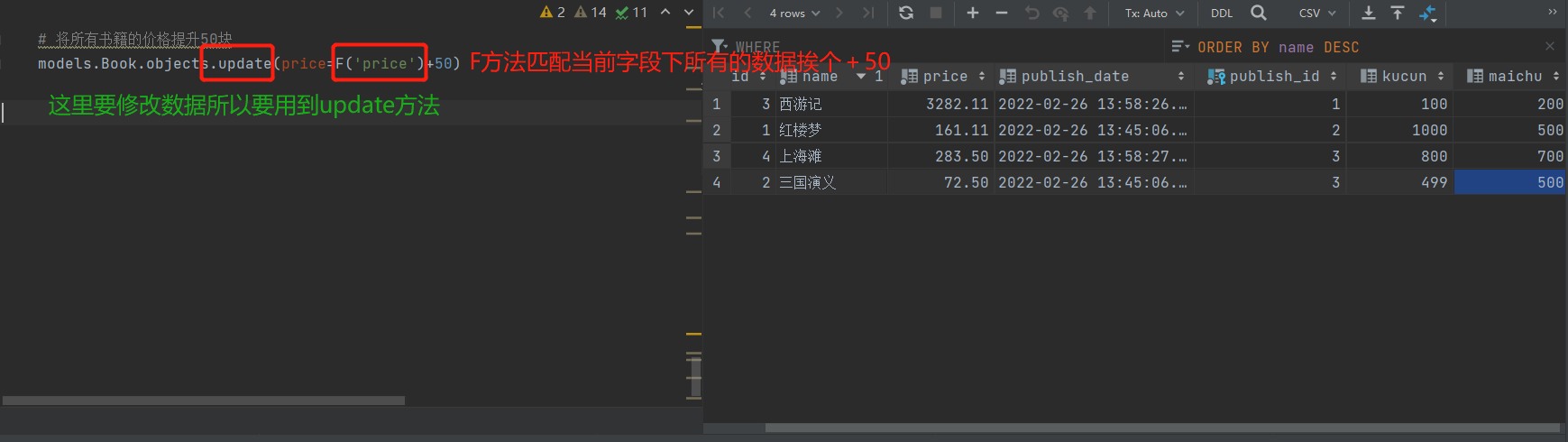
2.将所有书籍的价格提升50块。
models.Book.objects.update(price=F('price')+50)
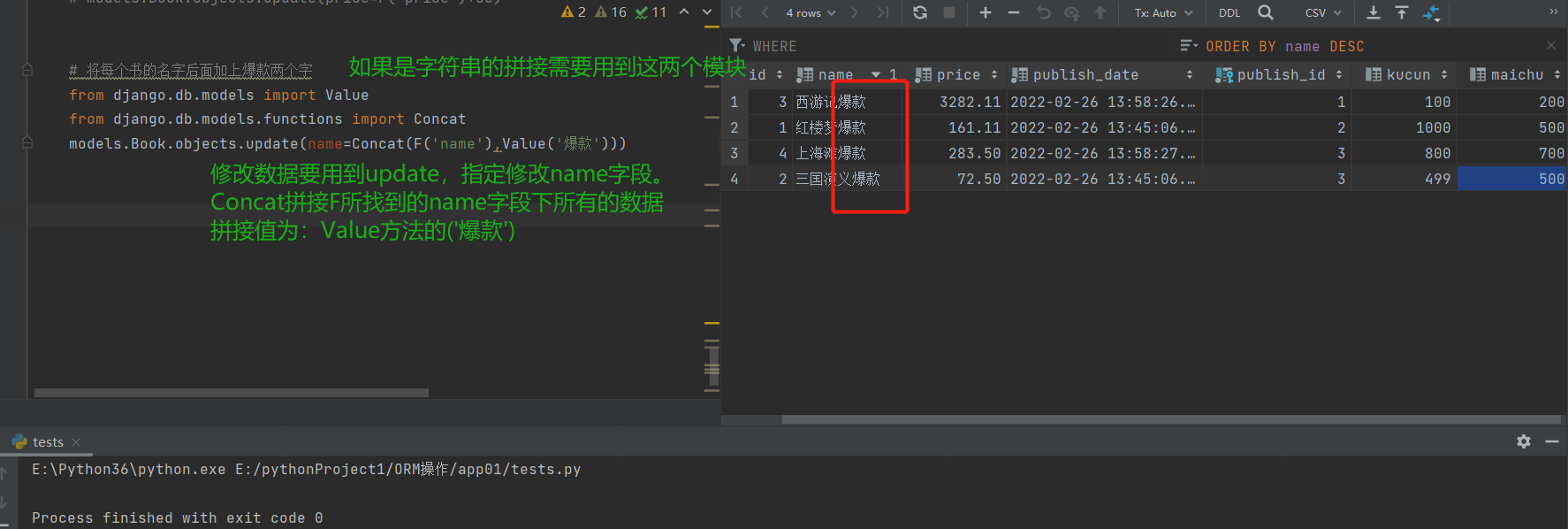
3.将所有书的名称后面加上爆款两个字:
# 在操作字符类型的数据的时候 F不能够直接做到字符串的拼接
from django.db.models import Value
from django.db.models.functions import Concat
models.Book.objects.update(name=Concat(F('name'),Value('爆款')))
# 注意:如果拼接字符串必须联合使用,
# models.Book.objects.update(title=F('title') + '爆款') # 所有的名称会全部变成空白
Q查询
示例:
# 1.查询卖出数大于100或者价格小于600的书籍
res = models.Book.objects.filter(maichu__gt=100,price__lt=600)
print(res)
# 结论:filter括号内多个参数是and关系
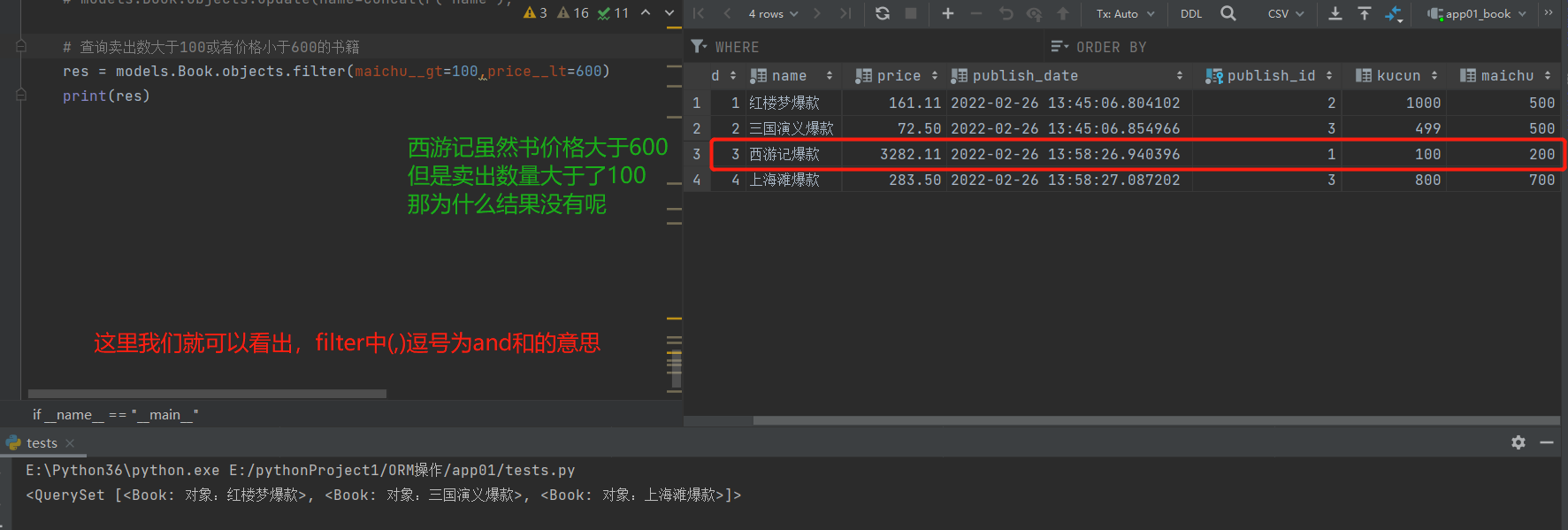
# 使用Q查询的方法:
from django.db.models import Q # 需要导入Q查询方法模块
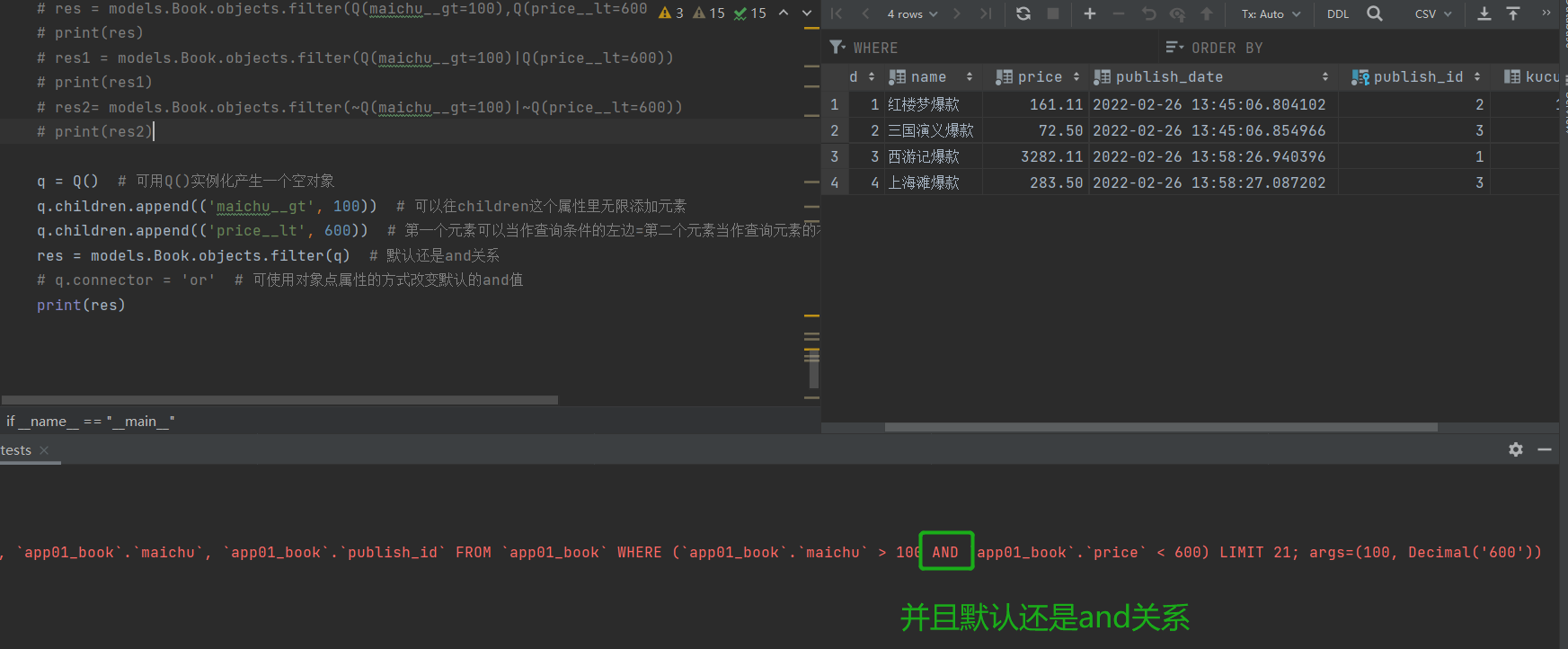
res = models.Book.objects.filter(Q(maichu__gt=100),Q(price__lt=600))
print(res) # 使用Q包裹后依然使用,做为多参数分割依然为and关系
res1 = models.Book.objects.filter(Q(maichu__gt=100)|Q(price__lt=600))
print(res1) # | 则表示的为or的关系
res2= models.Book.objects.filter(~Q(maichu__gt=100)|~Q(price__lt=600))
print(res2) # ~ 表示的为非的关系(取反)
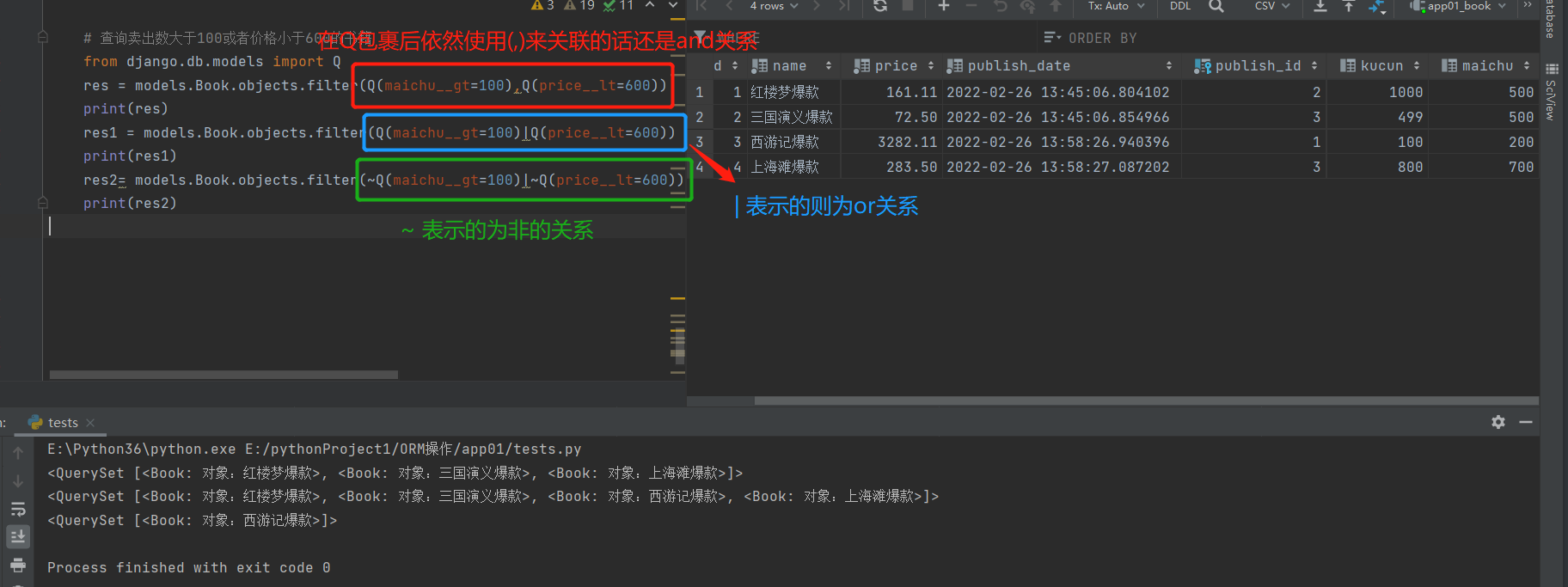
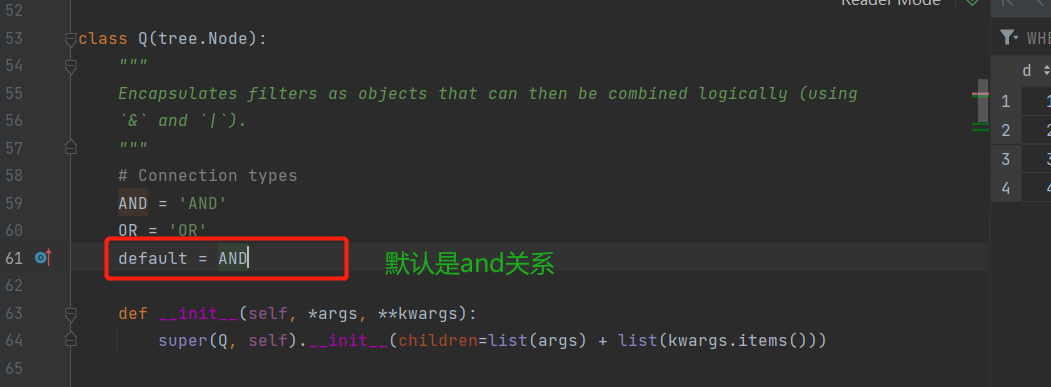
# Q的高级用法:能够将查询条件的左边也变成字符串的形式而不是变量名的形式。
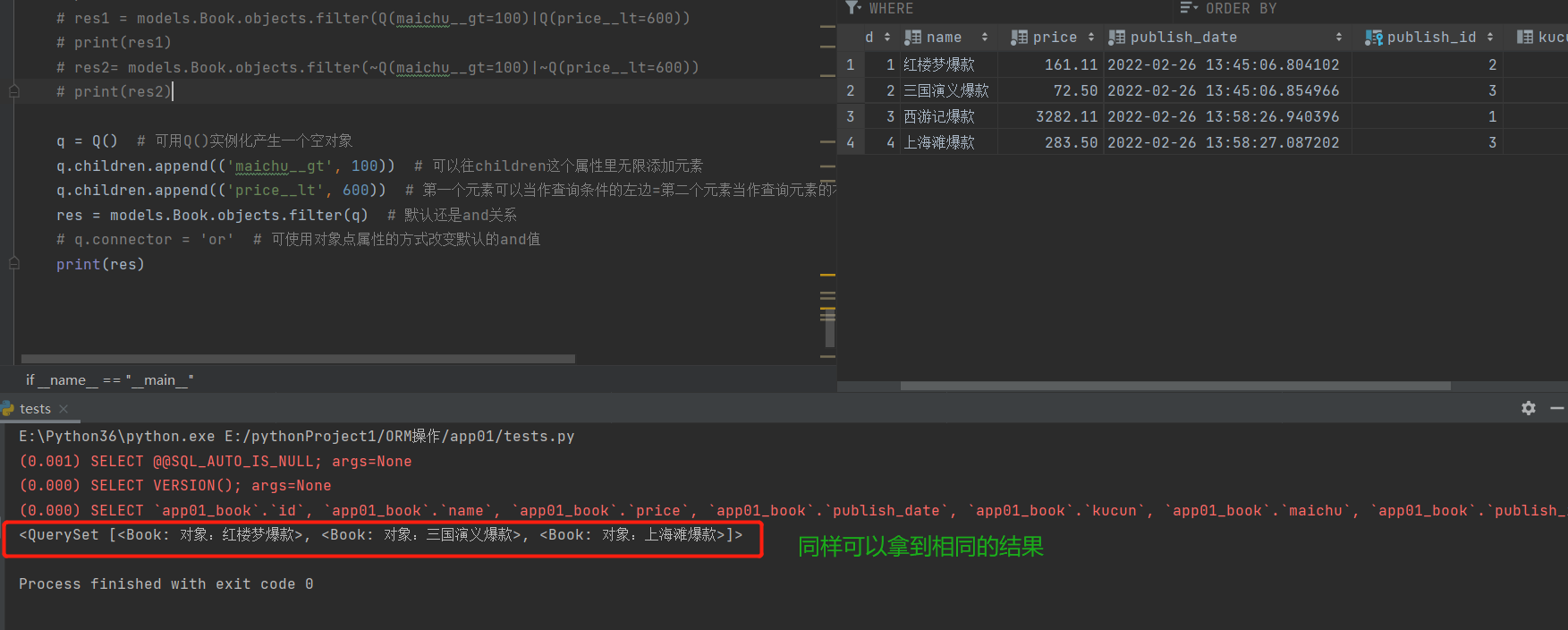
q = Q() # 可用Q()实例化产生一个空对象
q.children.append(('maichu__gt',100)) # 可以往children这个属性是一个列表,可无限添加元素
q.children.append(('price_lt',600))
res = models.Book.objects.filter(q) # 默认还是and关系
q.connector = 'or' # 可使用对象点connector属性的方式改变默认的and值
print(res)
ORM数据库查询优化
准备工作
# 只要操作数据库那么就会打印sql语句
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
惰性查询
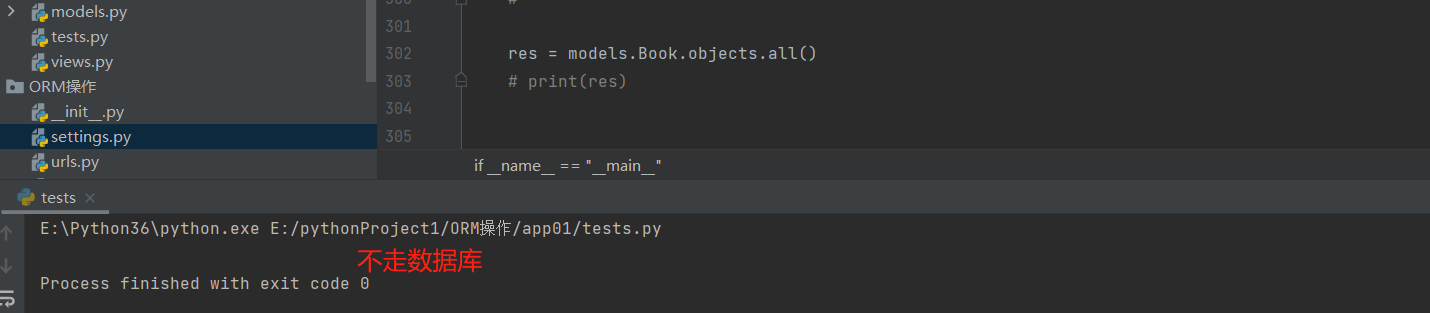
# 惰性查询:如果只是书写了orm语句,在后面根本没有用到该语句所查询出来的参数,那么orm会自动识别出来,直接不执行。
# 举例:
res = models.Book.objects.all() # 这时orm是不会走数据库的
print(res) # 只有当要用到的上述orm语句的结果时,才回去数据库查询。

# 我们下来做一个题目:
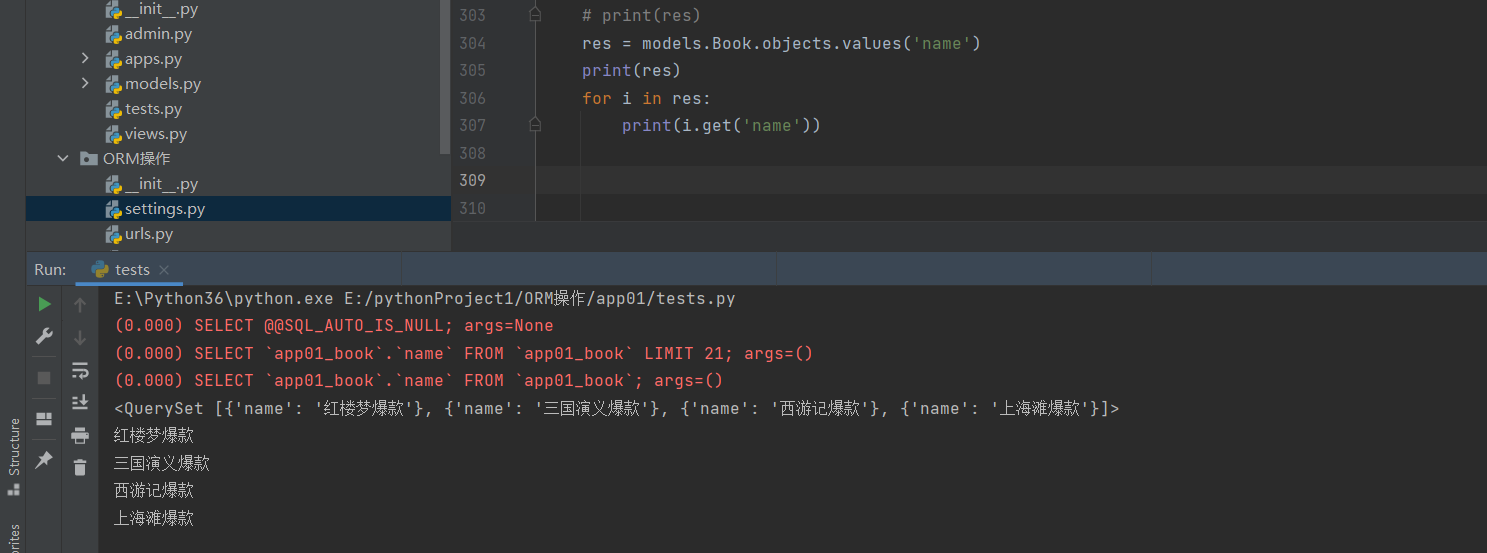
获取数据表中所有数的名字:
res = models.Book.objects.values('name')
print(res) # 拿到的是列表套字典的形式
for i in res:
print(i.get('name')) # for循环出字典,通过.get方法取出每个书的名字
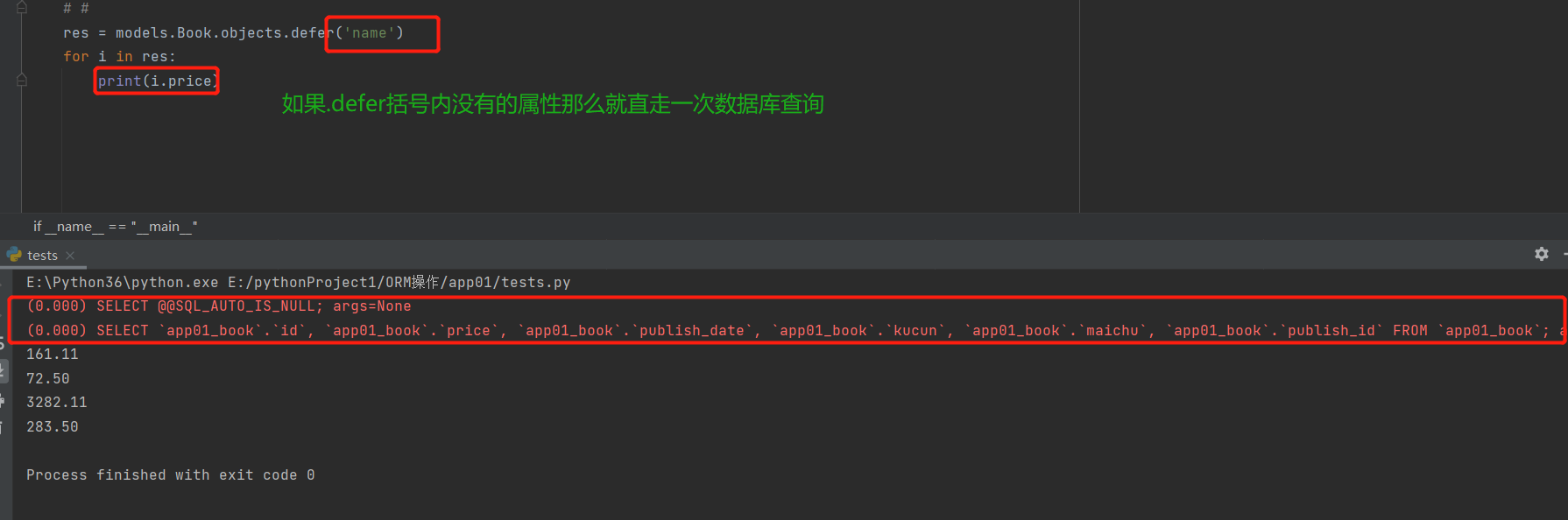
only方法
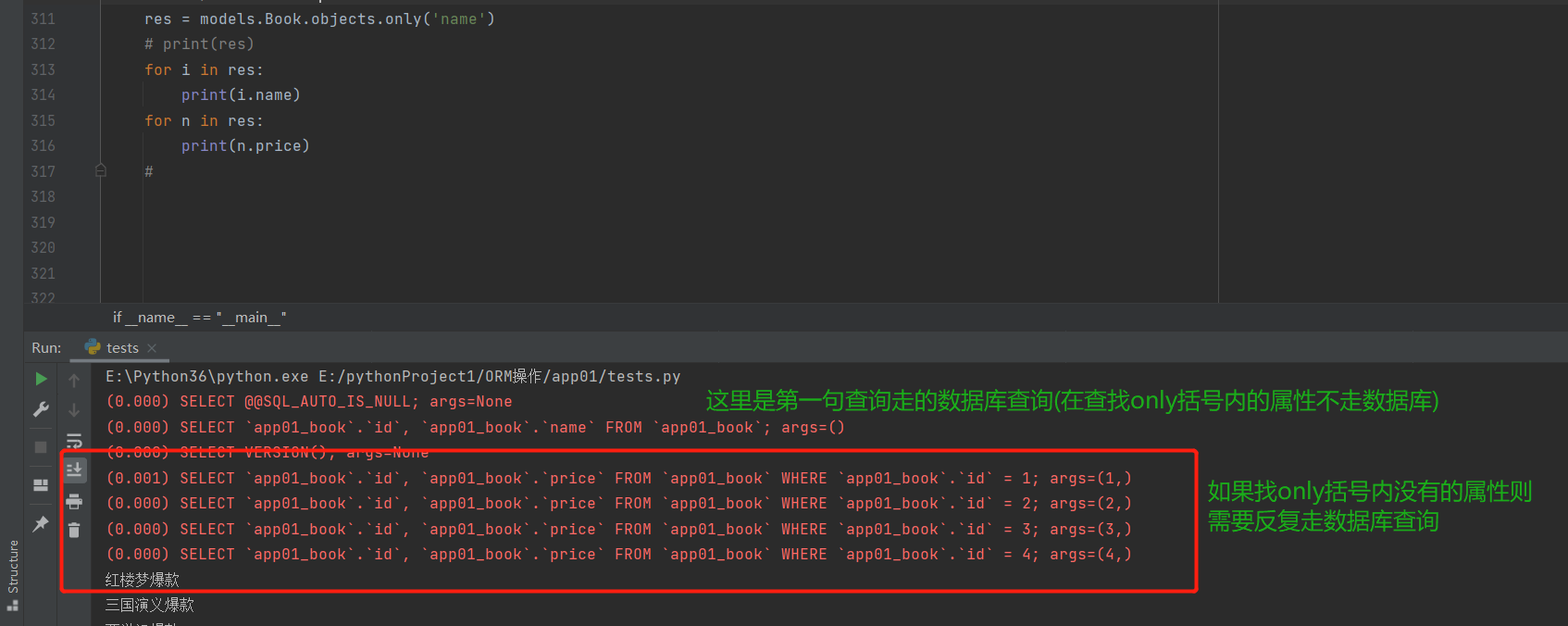
res = models.Book.objects.only('name') # 对象只有name属性
print(res)
for i in res:
print(i.name) # 如果点(.)only括号内有的字段,不走数据库
print(i.price) # 如果点(.)only括号内没有的字段,那么会反复走数据库去查询(查询一个返回一个)而all()不需要
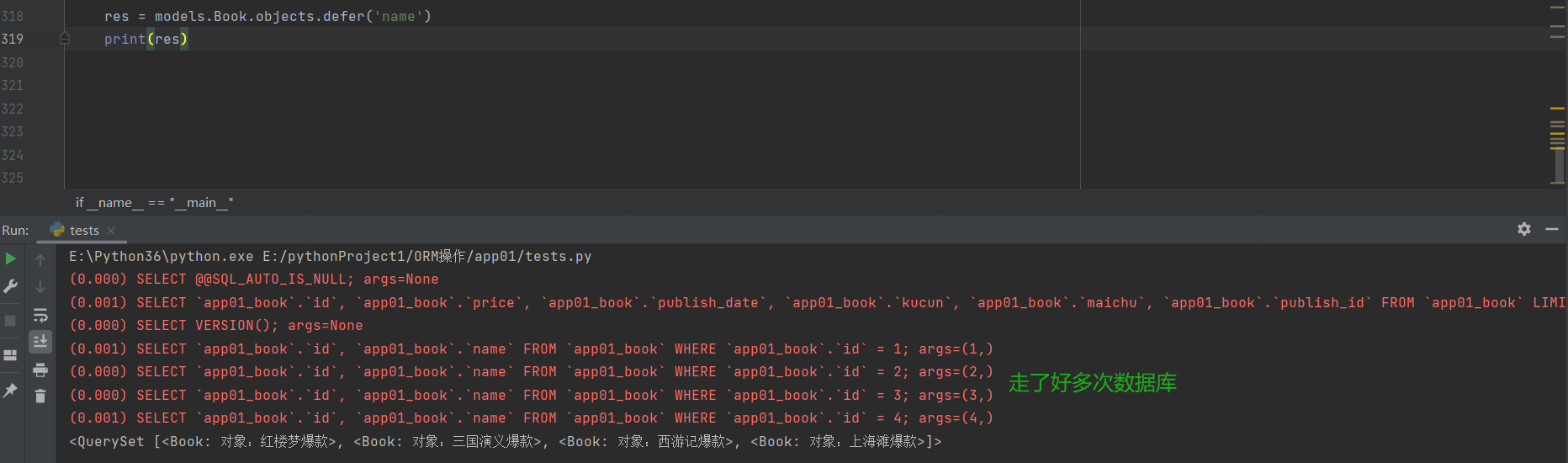
defer方法
res = models.Book.objects.defer('name') # 对象除了没有name属性之外其他的都有
for i in res:
print(i.price)
"""
defer与only刚好相反
defer括号内放的字段不在查询出来的对象里面 查询该字段需要重新走数据
而如果查询的是非括号内的字段 则不需要走数据库了
"""
# 跟跨表操作有关
示例:
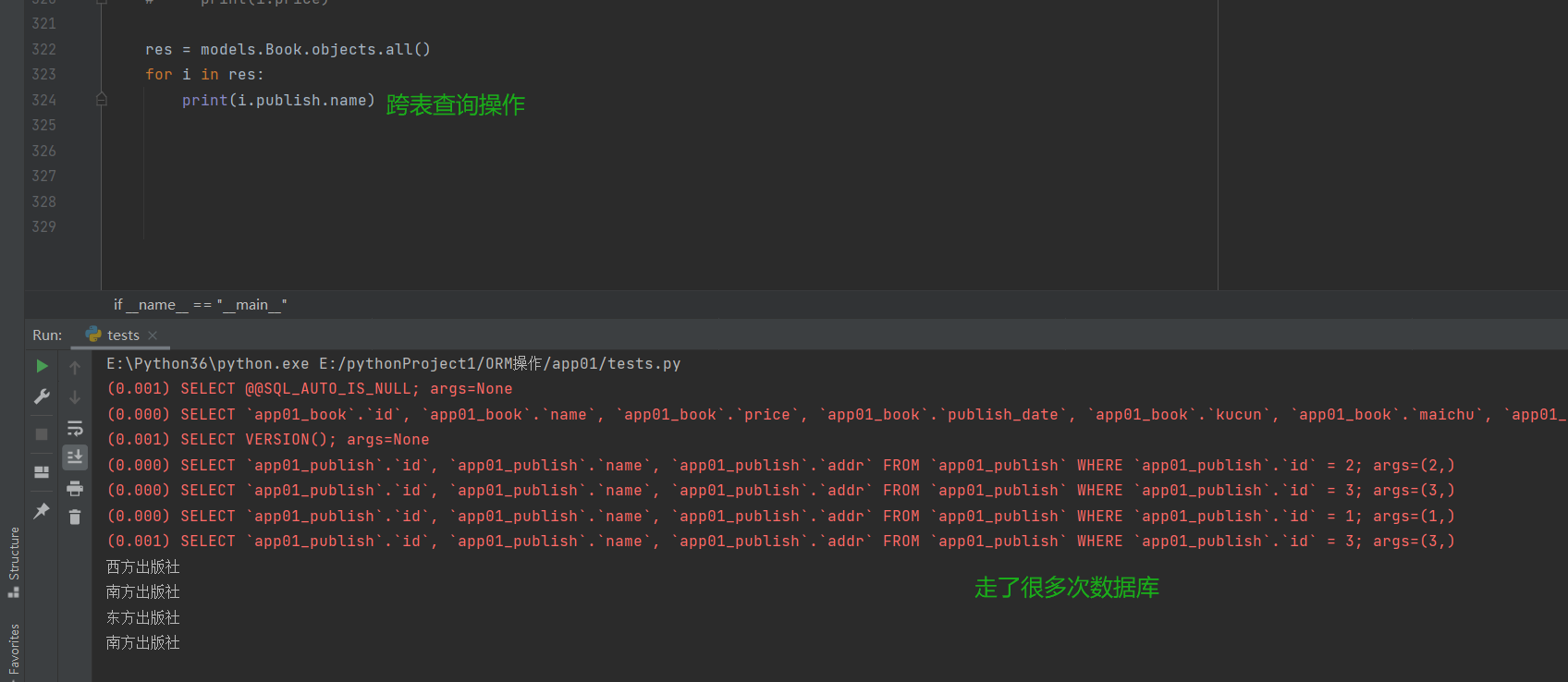
# 查询每本书的出版社名字
res = models.Book.objects.all()
for i in res:
print(i.publish.name)
# 使用all方法查询的时候,每一个对象都会去数据库查询数据
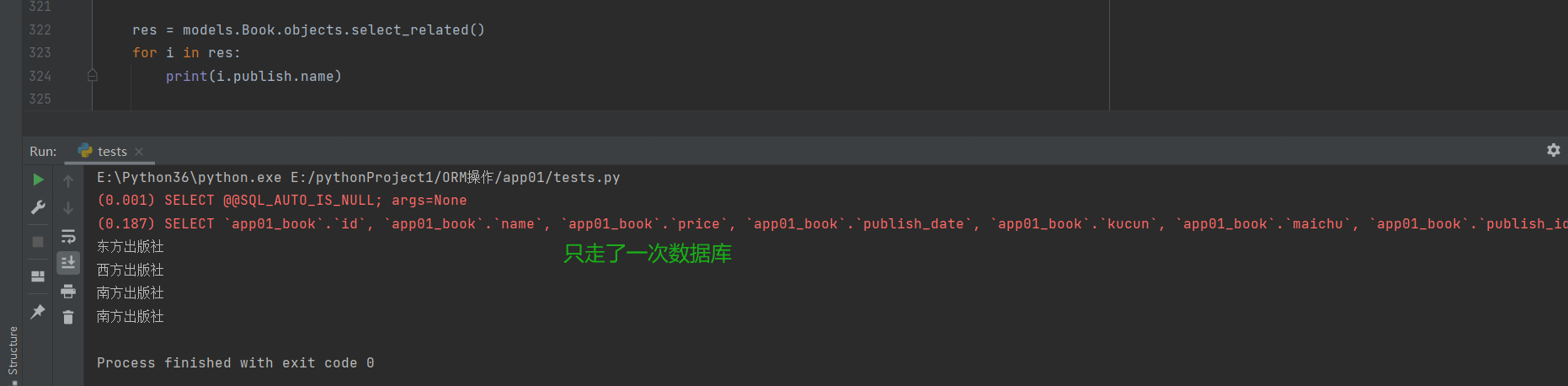
# 使用select_related()
res = models.Book.objects.select_related()
for i in res:
print(i.publish.name) # 直走一次数据库 INNER JOIN链表操作
"""
select_related内部直接先将book与publish连起来 然后一次性将大表里面的所有数据
全部封装给查询出来的对象
这个时候对象无论是点击book表的数据还是publish的数据都无需再走数据库查询了
select_related括号内只能放外键字段 一对多 一对一
多对多也不行
"""
# 这样就比all方法更加的优化一点,这样网络请求就少了,延迟就降低了,提高效率。
# 跟跨表操作有关
res = models.Book.objects.prefetch_related('publish') # 子查询
for i in res:
print(i.publish.name)
"""
prefetch_related该方法内部其实就是子查询
将子查询查询出来的所有结果也给你封装到对象中
给你的感觉好像也是一次性搞定的
"""
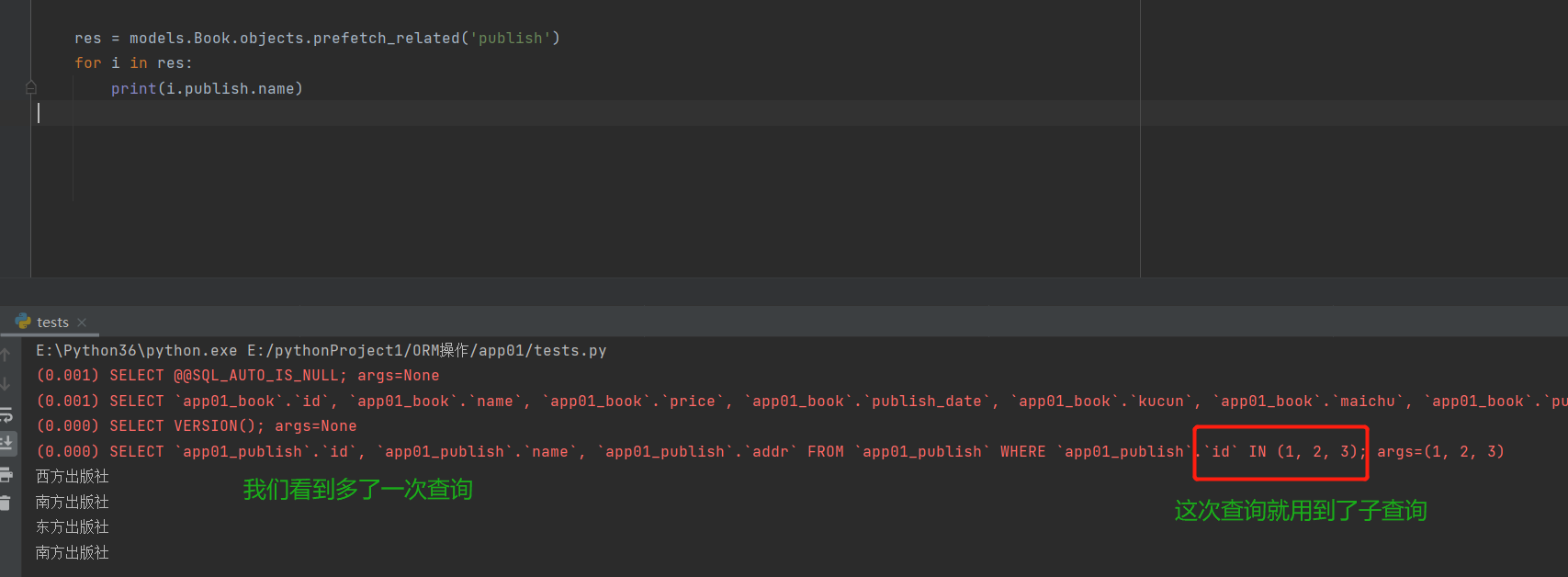
# prefetch_related对比select_related少了一次查询
# 到底孰优孰劣呢?
各有优缺点:如果表特别特别大的时候使用prefetch_related品表阶段就要耗费很长的时间,而select_related子查询虽然查询两次,但是操作两个表的时间非常短效率就会胜于联表查询prefetch_related
Django事务相关操作
什么是事务?
事务:一般是指要做的或所做的事情,而且事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所做的所有更改都会被撤销。
事务的四大特性:
ACID:
原子性:
一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做
一致性:
事务必须是数据库从一个一致性状态变成另一个一致性状态。一致性 与原子性是密切相关的
隔离性:
一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据,对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰
持久性:
持久性也称永久性,指一个事务一旦提交,他对数据库中的数据的改变就应该是永久性的,接下来的其他操作或故障不应该对其有任何影响。
MySQL中开启事务:
start transaction
事务的回滚:
rollback
事务的确认:
commit
# Django中开启事务:
from django.db import transaction # 导入事务需要的模块
with transaction.atomic(): # 开启事务
sql1
sql2
在with子代码块中书写的所有orm操作都属于同一个事务
print("只要不在with子代码块中就算结束事务")
ORM常用字段及参数
AutoField(Field)
- int自增列,必须填入参数 primary_key=True
BigAutoField(AutoField)
- bigint自增列,必须填入参数 primary_key=True
注:当model中如果没有自增列,则自动会创建一个列名为id的列
from django.db import models
class UserInfo(models.Model):
# 自动创建一个列名为id的且为自增的整数列
username = models.CharField(max_length=32)
class Group(models.Model):
# 自定义自增列
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
SmallIntegerField(IntegerField):
- 小整数 -32768 ~ 32767
PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正小整数 0 ~ 32767
IntegerField(Field)
- 整数列(有符号的) -2147483648 ~ 2147483647
PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField)
- 正整数 0 ~ 2147483647
BigIntegerField(IntegerField):
- 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807
BooleanField(Field)
- 布尔值类型
NullBooleanField(Field):
- 可以为空的布尔值
CharField(Field)
- 字符类型
- 必须提供max_length参数, max_length表示字符长度
TextField(Field)
- 文本类型
EmailField(CharField):
- 字符串类型,Django Admin以及ModelForm中提供验证机制
IPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制
GenericIPAddressField(Field)
- 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6
- 参数:
protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6"
unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启此功能,需要protocol="both"
URLField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证 URL
SlugField(CharField)
- 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号)
CommaSeparatedIntegerField(CharField)
- 字符串类型,格式必须为逗号分割的数字
UUIDField(Field)
- 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证
FilePathField(Field)
- 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能
- 参数:
path, 文件夹路径
match=None, 正则匹配
recursive=False, 递归下面的文件夹
allow_files=True, 允许文件
allow_folders=False, 允许文件夹
FileField(Field)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
ImageField(FileField)
- 字符串,路径保存在数据库,文件上传到指定目录
- 参数:
upload_to = "" 上传文件的保存路径
storage = None 存储组件,默认django.core.files.storage.FileSystemStorage
width_field=None, 上传图片的高度保存的数据库字段名(字符串)
height_field=None 上传图片的宽度保存的数据库字段名(字符串)
DateTimeField(DateField)
- 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ]
DateField(DateTimeCheckMixin, Field)
- 日期格式 YYYY-MM-DD
TimeField(DateTimeCheckMixin, Field)
- 时间格式 HH:MM[:ss[.uuuuuu]]
DurationField(Field)
- 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型
FloatField(Field)
- 浮点型
DecimalField(Field)
- 10进制小数
- 参数:
max_digits,小数总长度
decimal_places,小数位长度
BinaryField(Field)
- 二进制类型
ORM字段与MySQL字段对应关系
对应关系:
'AutoField': 'integer AUTO_INCREMENT',
'BigAutoField': 'bigint AUTO_INCREMENT',
'BinaryField': 'longblob',
'BooleanField': 'bool',
'CharField': 'varchar(%(max_length)s)',
'CommaSeparatedIntegerField': 'varchar(%(max_length)s)',
'DateField': 'date',
'DateTimeField': 'datetime',
'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)',
'DurationField': 'bigint',
'FileField': 'varchar(%(max_length)s)',
'FilePathField': 'varchar(%(max_length)s)',
'FloatField': 'double precision',
'IntegerField': 'integer',
'BigIntegerField': 'bigint',
'IPAddressField': 'char(15)',
'GenericIPAddressField': 'char(39)',
'NullBooleanField': 'bool',
'OneToOneField': 'integer',
'PositiveIntegerField': 'integer UNSIGNED',
'PositiveSmallIntegerField': 'smallint UNSIGNED',
'SlugField': 'varchar(%(max_length)s)',
'SmallIntegerField': 'smallint',
'TextField': 'longtext',
'TimeField': 'time',
'UUIDField': 'char(32)',
ORM自定义字段类型
- Django除了提供很多字段类型外,还支持我们自定义字段类型,所以我们在遇到某个字段没有的情况下可自定字段名与字段类型。
自定义char类型字段:
# 在使用字符字段:(CharField()类型定义时,它相当于定义的是varchar()类型,现在我们来自定义一个char()类型的字段)
# 要想定义字段的话,我们来模仿一下内置的字段是怎么写的。
ctrl+鼠标左键:我们来看一下CharField内部代码是怎么写的
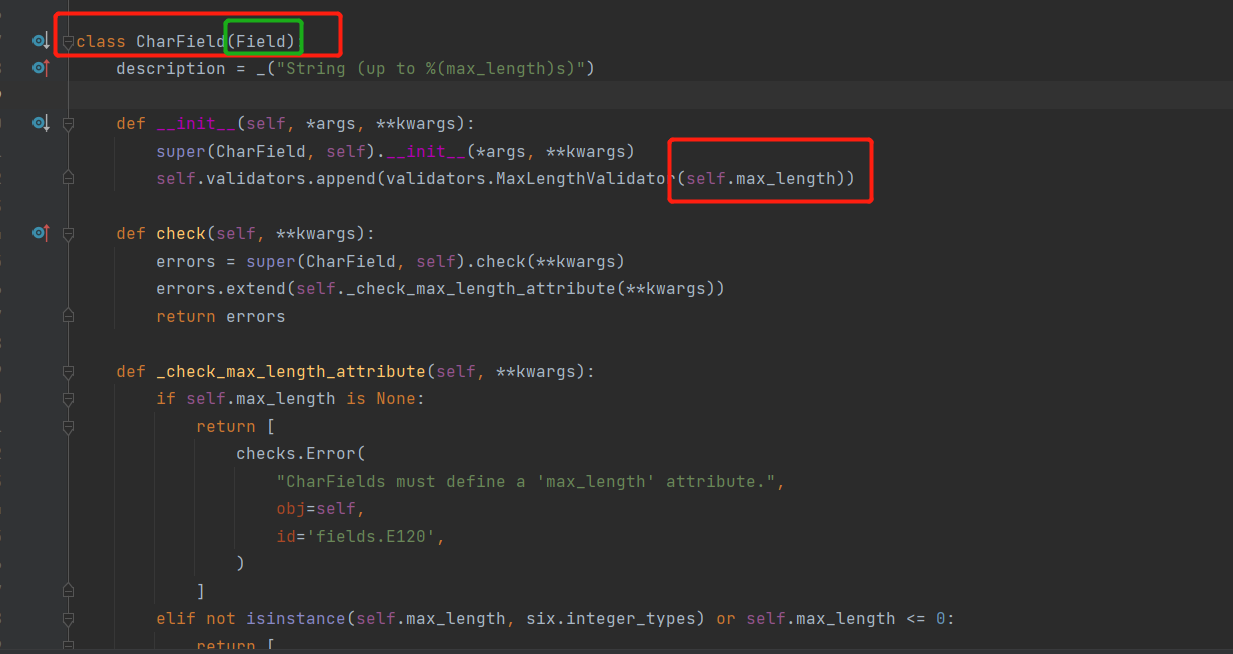
# 我们可以看到:它内部其实就是定义了一个类,其中的参数其实就是类的属性或者方法,并且他们都继承了Field父类
运行
class MyCharField(models.Field):
def __init__(self,max_length,*args,**kwargs):
self.max_length = max_length
# 重写了__init__方法需要重新调用父类的__init__方法
super().__init__(max_length=max_length,*args,**kwargs) # 必须写关键字的形式传入
def db_type(self, connection): # 需要用到db_type方法
'''
返回真正的数据类型及各种约束条件
:param connection:
:return:
'''
return 'char(%s)'%self.max_length # 定义字段名字
class User1(models.Model): # 尝试试一下是否可以使用
myfiele = MyCharField(max_length=16,null=True)
ORM多对多创建方式
全自动
# 利用orm自动帮我们创建第三张表关系。
class Book(models.Model):
title = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Authors') # 利用orm自动创建第三张关系表
class Authors(models.Model):
name = models.CharField(max_length=32)
# 优点:
第三张关系表代码不需要自己写,非常的方便,还支持orm提供操作第三张关系表的方法(add,set...)
# 缺点:
第三张关系表的扩展性极差(没有办法额外添加字段)
全手动
class Book(models.Model):
name = models.CharField(max_length=32)
class Author(models.Model):
name = models.CharField(max_length=32)
class Book2Author(models.Model): # 手动创建第三张关系表
book_id = models.ForeignKey(to='Book')
author_id = models.ForeignKey(to='Author')
# 优点:第三张表完全取决于我们自己进行额外的扩展
# 缺点:需要自己写的代码较多,不能够再使用orm提供的简单的方法(不推荐使用)
半自动
class Book(models.Model):
name = models.CharField(max_length=32)
authors = models.ManyToManyField(to='Author',
through='Book2Author',
through_fields=('book','author')
)
class Author(models.Model):
name = models.CharField(max_length=32)
# books = models.ManyToManyField(to='Book',
# through='Book2Author',
# through_fields=('author','book')
# )
# 多对多表关系外键字段可以创建在任意一张表中:throuth_fields字段先后顺序是:
判断的本质:
通过第三张表查询对应的表,需要用到那个字段就把那个字段放前面
('如果要通过关系表找到Book表,就把book字段放在前面')
简化判断:
当前外键创建在那张表中,就把对应的关联字段放在前面
class Book2Author(models.Model):
book = models.ForeignKey(to='Book')
author = models.ForeignKey(to='Author')
# 半自动可以使用orm正反向查询:但是没法使用add,set,remove,clear这四个方法
# 总结:需要掌握的是全自动和半自动 因为半自动的扩展性更高 一般我们都会采用半自动,
比如:如果我们用全自动创建的多对多的关系表后,需要在关系表中添加新的字段,比如两个关系的绑定时间之类的,那么这时使用全自动就无法实现了,所以这时使用半自动就可以更方便后续的拓展

 浙公网安备 33010602011771号
浙公网安备 33010602011771号