【2022-07-17】上周内容回顾
上周内容回顾
python内置函数及迭代器对象
常见内置函数
# 常见内置函数
# 什么是内置函数,提前定义好的且可以直接使用的函数
# 1.abs() 求绝对值
# print(abs(-88)) # 88
# 2.all()与any() 判断容器类型中所有的数据值对应的布尔值是否为True 这两个类似于我们之前学过的逻辑运算符里边的三种表达方式中的两种,即与and和或or
# all() 所有的数据值为True的情况下,结果才是True
# print(all([11, 22, 33, 44, 55, 66, 0])) # False
# print(all([11, 22, 33, 44, 55, 66])) # True
# any() 所有的数据值中,只要有一个数据值为True,结果就是True
# print(any([11, 22, 33, 44, 55, 66, 0])) # True
# print(any([11, 22, 33, 44, 55, 66])) # True
# 3.bin() oct() hex() 将十进制分别转换为二进制、八进制、十六进制
# print(bin(99)) # 0b1100011 十进制转二进制
# print(oct(99)) # 0o143 十进制转八进制
# print(hex(99)) # 0x63 十进制转十六进制
# 4.int() 类型转换 其他进制转换为十进制
# print(int(0b1100011)) # 99 二进制转十进制
# print(int(0o143)) # 99 二进制转八进制
# print(int(0x63)) # 99 二进制转十六进制
# 5.bytes() 类型转换 可以用于编码与解码
# line = ('大鹏一日同风起 扶摇直上九万里'.encode('utf8'))
# print(line)
# line1 = line.decode('utf8')
# print(line1)
# line = (bytes('大鹏一日同风起 扶摇直上九万里', 'utf8'))
# print(line)
# line2 = str(line, 'utf8')
# print(line2)
# 6.callable() 判断某个变量是否可以被加括号调用
# name = 'zs'
# def index():
# print('111')
# print(callable(name)) # False
# print(callable(index)) # True
# 7.chr() ord() 两者互为反关系,一个是将数字转换为字母。一个是将字母转换为数字 依据ASCII码表实现字符与数字的转换,ASCII码表记录了英文字符与数字的对应关系
# print(chr(88)) # X 65~90
# print(chr(108)) # l 97~122
# print(ord('B')) # 66
# print(ord('b')) # 98
# 8.dir() 获取对象内部可以通过句点符获取的数据
# print(dir(str))
# 9.divmod 获取除法之后的整数和余数
"""
手上有很多数据 每页展示10条 需要多少页
通过代码自动计算
总数据 每页展示 需要多少页
100 10 10
99 10 10
101 10 11
898 10 ???
"""
# real_number, more = divmod(898, 10) # 解压赋值
# if more:
# real_number += 1
# print('总页数:%s' % real_number) # 总页数:90
# 10.enumerate() 枚举
# name_list = ['柳宗元', '韩愈', '欧阳修', '苏洵', '苏轼', '苏澈', '王安石', '曾巩']
# 需求:循环打印出上述列表里的数据值并且要有其对应的索引值
# count = 0
# for i in name_list:
# print(count, i)
# count += 1
# for i, j in enumerate(name_list, start=1):
# 将for循环出来的数据值交给前面的变量接收,然后使用解压赋值的方式把数据值依次赋值给变量名i和j 默认从0开始,但是可以自己设置
# print(i, j) # 1 柳宗元 2 韩愈 3 欧阳修 4 苏洵 5 苏轼 6 苏澈 7 王安石 8 曾巩
# 11.eval() exec() # 可以识别字符串中的python代码并执行
# chars = 'print(666)'
# print(chars)
# eval(chars) # 666 只能识别最简单的python代码
# exec(chars) # 666 能够识别复杂类的python代码
# chars = 'for i in range(10):print(i)'
# eval(chars)
# exec(chars)
# 12.hash 返回一串随机的数据值(哈希值)
# print(hash('666')) # -4553508281048470705
# 13.help() 查看帮助
# help(input)
# 14.isinstance() 判断某个数据是否属于某个数据类型
# print(isinstance('lisa', int)) # False
# print(isinstance('123', str)) # True
# 15.pow() 幂指数
# print(pow(2, 4)) # 16
# 16.round() 四舍五入
# print(round(99.4)) # 99
# print(round(99.5)) # 100
可迭代对象
-
迭代:就是更新换代的意思,就好比我们手机的系统升级,软件更新,还有电脑有的时候会提示让你更新,并说明此次版本更新以后,增加了哪些内容,删除了哪些内容,优化了些什么东西,包括我们以后参加工作了,都会编写技术文档或者用户手册,这些输出的技术文档,你肯定不止是写一个版本,初始版本,测试版本,优化版本,最终版本,这就是一个简单的迭代的概念,它每次更新都会基于上一个版本进行改动。
-
可迭代对象:可以对列表、字典、元组、字符串等类型的数据使用for循环的方式依次取值进行使用,并且提供了一种不依赖于索引取值的方式,因为字典和集合是不支持索引取值的,它们的内部是无序的
表达关键字:iterable
代码实例:
n = 0
while n < 10:
print(n)
n += 1
每一次打印n,都是基于n+1后得出的结果
- 如何判断是可迭代对象
内置有__iter__方法的都叫做可迭代对象
内置是能够通过句点符直接点出来的东西
__xxx__ 针对双下划线开头双下划线结尾的方法,统一读作双下xxx
对象的概念:没有具体的表现形式,可以是数字、字符串、列表、字典、元组、函数名等等 在python中一切皆对象
# int # 整型不是可迭代对象
# float # 浮点型不是可迭代对象
# str.__iter__() # 字符串是可迭代对象
# list.__iter__() # 列表是可迭代对象
# dict.__iter__() # 字典是可迭代对象
# tuple.__iter__() # 元组是可迭代对象
# set.__iter__() # 集合是可迭代对象
# bool # 布尔值不是可迭代对象
# def index(): # 函数名不是可迭代对象
# pass
# f = open(r'01 常见内置函数.py', 'r', encoding='utf8') 文件是可迭代对象,同时也是迭代器对象
# f.__iter__()
# f.__next__()
"""
可迭代对象:
字符串、列表、字典、元组、集合、文件
不可迭代对象:
整型、浮点型、布尔值、函数名
"""
迭代器对象
作用:迭代器对象给我们提供了一种不依赖于索引取值的方式,所以我们才能够对字典、集合等无序数据类型循环取值 还可以节省内存
- 如何判断迭代器对象
内置有__iter__和__next__的对象都称为是迭代器对象
可迭代对象与迭代器对象的关系
可迭代对象在调用__iter__方法之后就会变成迭代器对象
迭代器对象调用__iter__方法无论多少次还是迭代器本身
迭代器对象的迭代取值
迭代器对象执行__next__方法,就类似于循环取值
# name = '张三'.__iter__() # name已经是迭代器对象
# print(name) # <str_iterator object at 0x0000017E218C4B80>
# print(name.__next__()) # 张
# print(name.__next__()) # 三
# print(name.__next__()) # 报错
# dic = {'name': 'lisa', 'pwd': 666}
# dic1 = dic.__iter__()
# print(dic1.__next__()) # name
# print(dic1.__next__()) # pwd
# l1 = [777, 888, 99, 2, 3, 456, 66, 22]
# 需求:不使用for循环 依次打印出列表中所有的数据值
# 1.先将列表变成迭代器对象
# res = l1.__iter__()
# 2.定义一个计数器
# count = 0
# 3.编写while循环
# while count < len(l1):
# print(res.__next__())
# count += 1
# l1 = [66, 77, 88, 99]
# print(l1.__iter__().__next__()) # 66 把列表转换成迭代器对象 每次都是产生了一个新的迭代器对象
# print(l1.__iter__().__next__()) # 66 把列表转换成迭代器对象 每次都是产生了一个新的迭代器对象
# print(l1.__iter__().__next__()) # 66 把列表转换成迭代器对象 每次都是产生了一个新的迭代器对象
# print(l1.__iter__().__next__()) # 66 把列表转换成迭代器对象 每次都是产生了一个新的迭代器对象
# l2 = l1.__iter__()
# print(l2.__iter__().__next__()) # 66 每次使用的都是一个迭代器对象
# print(l2.__iter__().__next__()) # 77 每次使用的都是一个迭代器对象
# print(l2.__iter__().__next__()) # 88 每次使用的都是一个迭代器对象
# print(l2.__iter__().__next__()) # 99 每次使用的都是一个迭代器对象
针对双下方法
l1 = [1, 2, 3, 4, 5]
res = l1.__iter__() # iter(l1)
res.__next__() # next(res1)
迭代器对象特殊情况
可迭代对象 迭代器对象 通过打印的方式无法直接看出内部数据的情况 这个时候它们都可以节省内存,可以把它当做哆啦A梦的口袋,你要什么就从里边拿什么就可以了
# res = range(10).__iter__()
# print(res.__next__()) # 0
# print(res.__next__()) # 1
# print(res.__next__()) # 2
# print(res) # <range_iterator object at 0x000001E40A7379D0>
for循环本质
语法结构
for 变量名 in 可迭代对象:
循环体代码
1.for会自动将in后面的数据调用__iter__()变成迭代器对象
2.之后每次循环调用__next__()进行取值
3.最后没有值调用__next__()就会报错,for循环会自动处理报错,并让循环正常结束
Python异常处理及生成器对象
异常捕获
什么是异常
- 在计算机里边,异常就是指某个程序在运行过程中发生的错误,俗称为"bug"
什么是异常处理
- 当一个程序发生异常时,代表该程序在执行时出现了非正常的情况,无法再执行下去。默认情况下,程序是要终止的。如果要避免程序退出,可以使用捕获异常的方式获取这个异常的名称,再通过其他的逻辑代码让程序继续运行,这种根据异常做出的逻辑处理叫作异常处理
- 开发者可以使用异常处理全面地控制自己的程序。异常处理不仅仅能够管理正常的流程运行,还能够在程序出错时对程序进行必的处理。大大提高了程序的健壮性和人机交互的友好性
异常信息的组成
File "D:/python/study/day16/01 异常处理.py", line 1
print "hello word"
^
SyntaxError: Missing parentheses in call to 'print'. Did you mean print("hello word")?
以上运行输出结果中,前两段指明了错误的位置,最后一句表示出错的类型。在 Python 中,把这种运行时产生错误的情况叫做异常(Exceptions)。
异常的类型
| 异常类型 | 含义 |
|---|---|
| AssertionError | 当 assert 关键字后的条件为假时,程序运行会停止并抛出 AssertionError 异常 |
| AttributeError | 当试图访问的对象属性不存在时抛出的异常 |
| IndexError | 索引超出序列范围会引发此异常 |
| KeyError | 字典中查找一个不存在的关键字时引发此异常 |
| NameError | 尝试访问一个未声明的变量时,引发此异常 |
| TypeError | 不同类型数据之间的无效操作 |
| ZeroDivisionError | 除法运算中除数为 0 引发此异常 |
异常的分类
开发人员在编写程序时,难免会遇到错误,有的是编写人员疏忽造成的语法错误,有的是程序内部隐含逻辑问题造成的数据错误,还有的是程序运行时与系统的规则冲突造成的系统错误,等等。总的来说,编写程序时遇到的错误可大致分为 2 类,分别为语法错误和运行时错误。
python语法错误,不允许出现的错误,一旦出现需要立即进行修改
语法错误,也就是解析代码时出现的错误。当代码不符合python的语法规范时,python解释器就会在解析时进行报出SyntaxError语法错误,例如:
print "hello word"
File "D:/python/study/day16/01 异常处理.py", line 1
print "hello word"
^
SyntaxError: Missing parentheses in call to 'print'. Did you mean print("hello word")?
python运行时错误,允许出现的错误,发生错误之后在进行修改,也是程序员基本工作之一,即改bug
运行时错误,即程序在语法上都是正确的,但是在运行的过程中发生了错误,例如:
a = 1/0 # 用1除以0,然后赋值给a 但是0作为除数是没有意义的,所以运行之后产生了如下错误:
Traceback (most recent call last):
File "D:/python/study/day16/01 异常处理.py", line 3, in <module>
a = 1/0
ZeroDivisionError: division by zero
异常捕获实操
- 异常捕获的代码实现方式
基本语法结构(针对性很强)
try:
可能会出错的代码(被try监控)
except 错误类型1 as e: # e就是具体错误的原因
对应错误类型1的解决措施
except 错误类型2 as e: # e就是具体错误的原因
对应错误类型2的解决措施
except 错误类型3 as e: # e就是具体错误的原因
对应错误类型3的解决措施
except 错误类型4 as e: # e就是具体错误的原因
对应错误类型4的解决措施
万能语法结构(笼统处理方式)
# try:
# word
# except Exception as e:
# print(e) # name 'word' is not defined 'password'
#
# try:
# dic = {'name': 'jason'}
# dic['password']
# except Exception as e:
# print(e) # 'password'
#
# try:
# 'jason' + 666
# except Exception as e:
# print(e) # can only concatenate str (not "int") to str
其他异常捕获操作
try:
name = 'tony'
except Exception as e:
print('异常错误,你是不是瞎了')
else:
print('try监测的代码没有出错的情况下正常运行结束 则会执行else子代码')
finally:
print('try监测的代码无论有没有出错,都会执行finally子代码')
断言
l1 = [11, 22, 33, 44, 55, 66]
assert isinstance(l1, list)
print('针对l1数据使用列表相关的操作')
主动抛异常
username = input('username>>>:')
if username == '张三':
raise NameError('法外狂徒张三已上线') # NameError: 法外狂徒张三已上线
else:
print('who are you?')
生成器对象
# def index():
# print('这是一个函数')
# yield 111, 222, 333
# print('这是一个内置函数')
# yield 222
# print('函数名加括号调用')
# yield 333
"""
当函数体代码中有yield关键字
那么函数名第一次加括号调用不会执行函数体代码
而是由普通的函数变成了迭代器对象(生成器) 返回值
"""
# print(index) # <function index at 0x000001F499F7A5E0>
# res = index()
# print(res) # <generator object index at 0x0000021E18BACA50>
# res.__next__()
# res.__next__()
# res.__next__()
"""
yield可以在函数体代码中出现多次
每次调用__next__方法都会从上往下执行直到遇到yield代码停留在此处
"""
# print(res.__next__())
# print(res.__next__())
# print(res.__next__())
# print(res.__next__())
"""
yield后面如果有数据值 则会像return一样返回出去
如果有多个数据值逗号隔开 那么也会自动组织成元组返回
"""
yield使用方法
def index(name,food=None):
print(f'{name}准备干午饭!!!')
while True:
food = yield
print(f'{name}正在吃{food}')
res = index('jason')
res.__next__()
res.send('生蚝') # 传值并自动调用__next__方法
res.send('韭菜') # 传值并自动调用__next__方法
res.send('腰子') # 传值并自动调用__next__方法
生成器表达式
生成器本质就是一个迭代器对象,同样是为了节省内存空间
# l1 = [i**2 for i in range(10) if i > 3]
# print(l1)
# l1 = (i**2 for i in range(10) if i > 3)
# print(l1) # <generator object <genexpr> at 0x000001A793439C10>
python模块
模块简介
-
模块就是用一堆代码实现一些功能的代码的集合,通常一个或多个函数写在一个.py文件里,如果实现的功能过于复杂,那么就需要创建n个.py文件
这n个.py文件的集合就是模块。
-
通俗的讲,我们也可以把模块当成是一个工具包,要想使用这个工具包里面的工具,就需要导入这个模块。
模块的分类
- Python中的模块可分为三类,分别是内置模块、第三方模块和自定义模块,相关介绍如下:
内置模块:
Python内置标准库中的模块,也是Python的官方模块,可直接导入程序供开发人员使用
第三方模块:
由非官方制作发布的、供给大众使用的Python模块,在使用之前需要开发人员先自行安装
自定义模块:
开发人员在程序编写的过程中自行编写的、存放功能性代码的.py文件
模块的表现形式
- py文件(py文件也可以称之为是模块文件)
- 含有多个py文件的文件夹(按照模块功能的不同划分不同的文件夹存储)
- 已被编译为共享库或DLL的c或C++扩展
- 使用C编写并链接到python解释器的内置模块
导入模块语句-----import
import module # 1.导入module.py文件并且执行 打印结果:my name is module
# print(module.age) # 18
# print(module.test1()) # from module.py test1 function
"""
上述执行流程如下:
1.先运行01 import module way.py文件后,会立刻产生这个py文件的全局名称空间
2.import module即导入module.py文件,并自动执行module.py文件,产生该文件的全局名称空间
3.执行module.py文件中所有的代码,并将产生的名字存储到该名称空间中
4.当前名称空间中产生module,module指向的是module.py模块名称空间
5.使用module点名字,就相当于和module.py名称空间索要名字
"""
# age = 25
# print(module.age) # my name is module 18
# print(age) # 25
# def test1():
# print('我是来自执行文件内的test1函数') # from module.py test2 function
# module.test2() # from module.py test1 function 18
# age = 28
# module.change()
# print(age) # 28
# print(module.age) # 23
导入模块语句-----from....import....
from module import age # 从module.py文件中只取出age,其余暂不需要
print(age) # 18
"""
上述语句执行流程如下:
1.首先运行01 import module way.py文件后,会立刻产生这个py文件的全局名称空间
2.运行from module import age代码后,立刻产生module.py的全局名称空间
3.开始执行module.py文件中的代码
4.此时执行文件的名称空间里只存放了age,并且指向了module.py文件中的age指向的值18
"""
# from module import age, test1
# test1() # from module.py test1 function
补充说明
同一个程序反复导入相同的模块,导入语句只会执行一次
import module 执行有效
import module 执行无效
import module 执行无效
两种执行语句的优缺点
import module
优点:通过md点的方式可以使用到模块内所有的名字 并且不会冲突
缺点:md什么都可以点 有时候并不想让所有的名字都能被使用
from module import age, test1
优点:指名道姓的使用指定的名字 并且不需要加模块名前缀
缺点:名字及其容易产生冲突(绑定关系被修改)
循环导入问题
-
循环导入产生的问题
两个模块直接相互导入,且相互使用其名称空间中的名字,但是有些名字没有产生就使用,就出现了循环导入问题
-
解决问题
延后导入,先产生对方要使用的名字,再去完成导入对方
import y import x
name = 'from x.py' name = 'from y.py'
print(y.name) print(x.name)
"""
上述语句执行流程如下:
1.首先运行x.py文件,随即产生了x.py的全局名称空间
2.执行import y语句,随即产生了y.py文件的全局名称空间
3.然后执行y.py文件中的代码,即import x
4.名称空间已创建,并在x.py文件的空间里定义了一个name
5.此时print(y.name)是不可行的,name并没有产生,因为遇到了import x 于是陷入了一个循环
"""
from导入马上会使用名字,极容易出现错误,建议循环导入情况下,使用import导入
先提前产生名字,在导入模块(先做饭,再出门)
在导入逻辑放在函数中,将导入的逻辑延后到函数的调用,只要调用在产生名字后即可
"""循环导入将来尽量避免出现!!! 如果真的避免不了 就想办法让所有的名字在使用之前提前准备好"""
判断文件类型
因为一个python文件,可以是执行文件,也可以是被导入文件,那么我们该如何来区分呢?python中通过__name__的内容来进行区分。
注意:
如果在执行文件中,name__的值是__main,并且是字符串类型。
如果作为模块时,__name__的值被赋予模块名。
作为模块的开发者,可以在文件末尾基于__name__在不同应用场景下的值的不同来控制文件执行不同的逻辑。
if __name__ == '__main__':
test.py被当做脚本执行时运行的代码
else:
test.py被当做模块导入时运行的代码
模块的查找顺序
-
模块的查找顺序:内存空间>>>内置模块>>>sys.path查找(类似于我们之前学过的环境变量)。如果这三个地方都没找到,会直接报错
-
导入模块的时候一定要清楚哪一个是执行文件,因为所有的路径都是参照文件来的
内存空间查找
import module
import time
time.sleep(7) # 程序在睡眠期间被删除
print(module.age) # 18
"""
执行删除操作前,文件已经写进了内存里,所以还能看到打印的结果,如果在执行一次就会直接报错
"""
内置空间查找
import time
print(time) # <module 'time' (built-in)> 打印的结果是内置time
print(time.time()) # 1657711015.7224374 获取时间戳
"""
创建py文件时,一定不要和模块名关键字(内置、第三方)发生冲突
"""
sys.path查找
import sys
print(sys.path)
"""
['D:\\python\\study\\day17',
'D:\\python\\study\\day17',
'D:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_display',
'D:\\python38\\python38.zip',
'D:\\python38\\DLLs',
'D:\\python38\\lib',
'D:\\python38',
'D:\\python38\\lib\\site-packages',
'D:\\PyCharm 2021.1.3\\plugins\\python\\helpers\\pycharm_matplotlib_backend']
"""
"""
上述打印的结果是个列表,里面存放了很多路径,我们只需要从第一个路径中去查找就可以了,第一个其实就是执行文件所在的路径
"""
解决方法
方法一:
import sys
sys.path.append(r'D:\python\study\day17\xxx')
from xxx import time
print(time.name)
"""
sys.path是一个列表,所有我们可以使用append方法进行追加
之后把目标文件所在的路径添加到sys.path路径中就可以了
"""
方法二:
from xxx import time
print(time.name)
"""
使用from...import...句式指名道姓的查找
"""
python软件开发目录规范
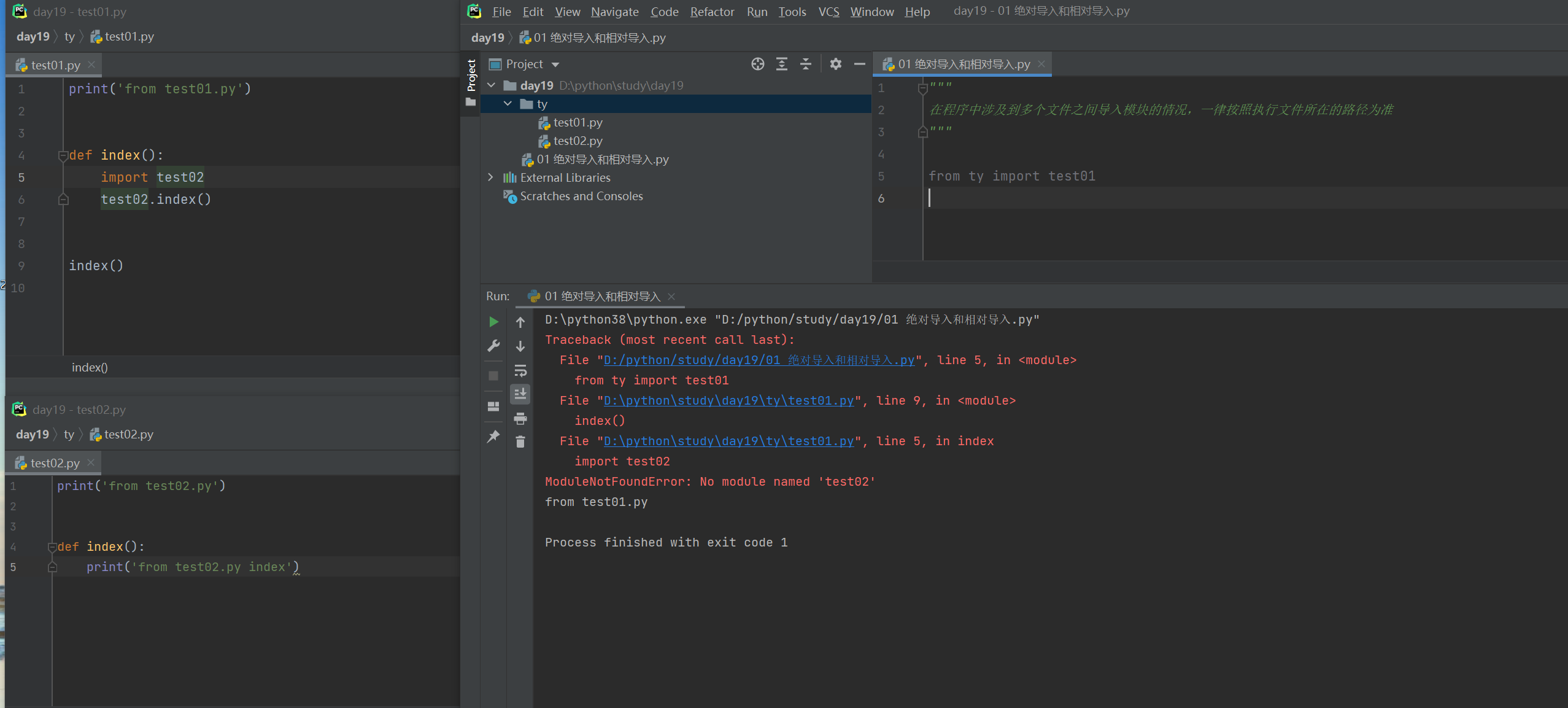
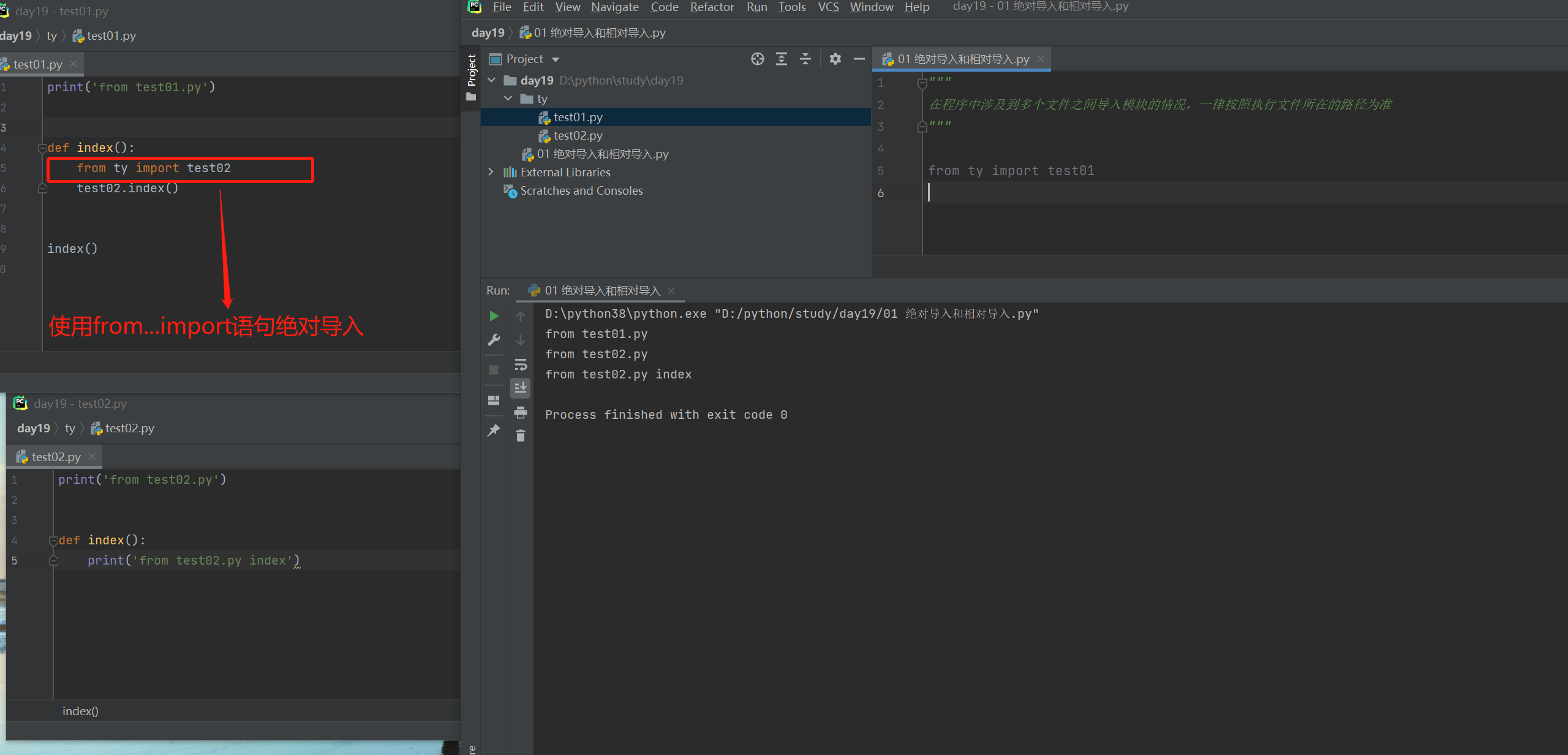
绝对导入与相对导入
"""
在程序中涉及到多个文件之间导入模块的情况,一律按照执行文件所在的路径为准
"""
from ty import test01
# 以执行路径所在的路径为准
绝对导入
始终按照执行文件所在的sys.path查找模块
ps:由于pycharm会自动将项目根目录添加到sys.path中,所以查找模块肯定不报错的方法就是永远从根路径往下一层层找
如果不是用pycharm运行 则需要将项目跟目录添加到sys.path(针对项目根目录的绝对路径有模块可以帮助我们获取>>>:os模块)
相对导入
"""
句点符(.)
.表示当前文件路径
..表示上一层文件路径
../..在路径中意思是上上一层路径
"""
能够打破始终以执行文件为准的规则 只考虑两个文件之间的位置
缺陷:
1.相对导入只能用在模块文件中 不能在执行文件中使用
2.相对导入在项目比较复杂的情况下 可能会出错
ps:相对导入尽量少用 推荐使用绝对导入
-
绝对导入和相对导入插图(1)
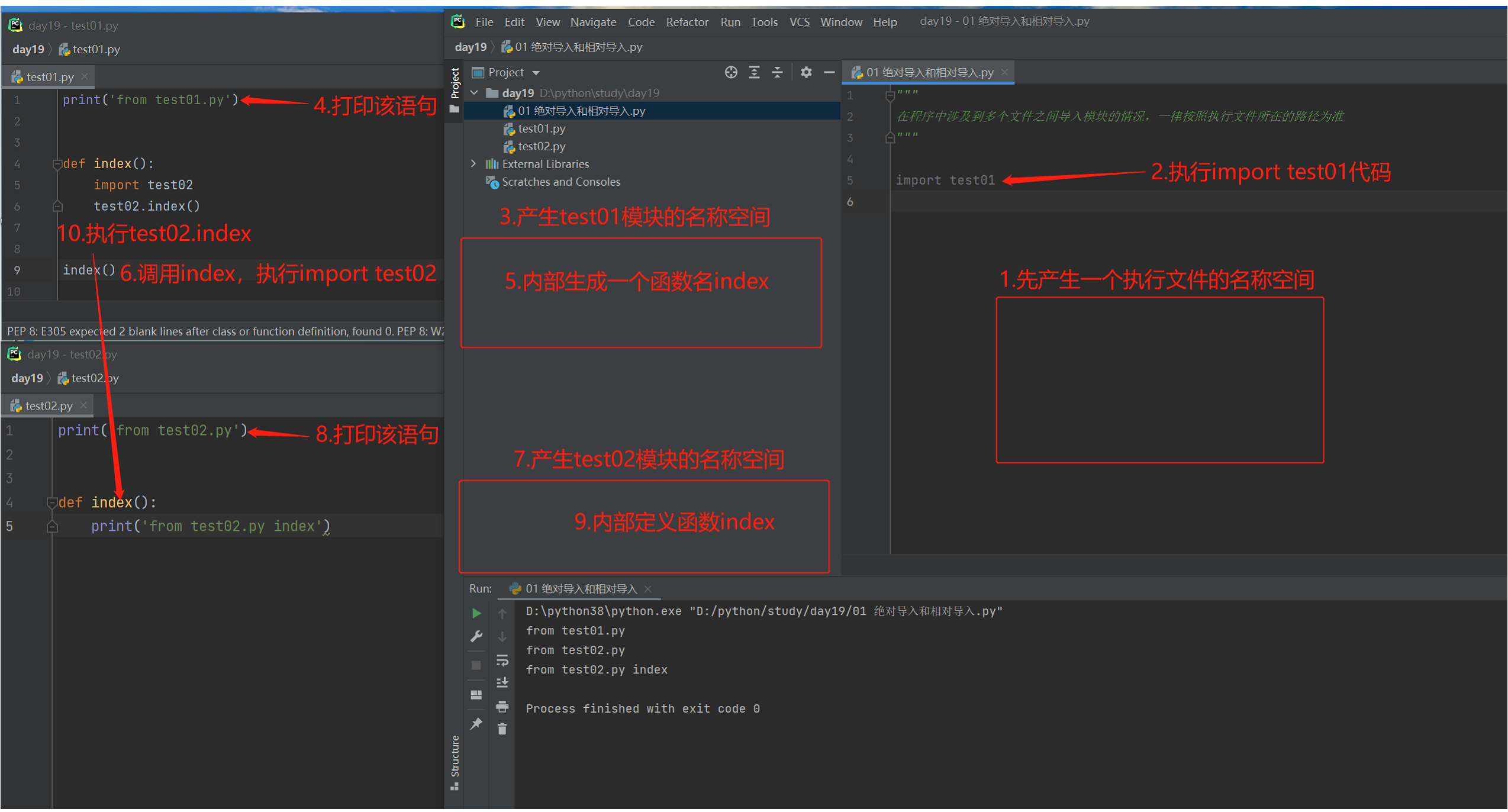
-
绝对导入和相对导入插图(2)
-
使用from...import语句解决
包的概念
在Python中,一个包可以说是一个带特定信息的目录结构:
1、 一个包对应一个目录,包名和目录名保持一致;
2、 包对应目录下必须有一个__init__.py文件,该文件用来标记该目录为包;
3、 init.py文件可以为空,也可以是一个有效的python文件,加载包时实际上就是执行__init__.py文件;
4、 要将模块加入包中,只需将模块文件放在包目录中即可,一个包目录可以存放多个模块文件;
5、 包的组织结构中还可以套包,即包可以嵌套,也就是包目录下还可以有子包目录;
6、 从逻辑上看,包的本质是模块的集合,是多个模块依靠目录结构组织在一起形成功能集合对外提供能力输出;
7、 导入包的本质就是加载井执行该包下的__init__.py文件,然后将整个文件内容赋值给与包同名的变量,该变量的类型是 module;
8、 与模块类似,包被导入后会在包目录下生成一个__pycache__子目录,并在该目录内为包生成一个 init.cpython-37.pyc 文件。
init.py文件的使用
1.Python对于定义目录为包的__init__.py文件没有强制要求,只要是一个符合Python代码源文件的文件即可,甚至是一个空文件也可以;
2.包的主要作用是组织多个模块或子包提供功能集,而导入包就相当于导入该包下的 init.py 文件,因此实际使用时是将包的__init__.py 文件的用于导入该包内包含的模块,而不是用来定义程序单元;
3.通过导入包时自动导入包内模块,可把模块中的成员导入变成包内成员这样通过导入包就完成了包内模块的导入,对于调用者来说,只要完成包导入就可以了,不用关注包内的每个模块,通过包就可以访问包内每个模块或子包提供的功能,以后使用起来会更加方便;
4.当然也可以导入包时不自动导入包内所有模块,而让调用方自行导入包内的模块,这样调用方仅需导入包内调用方需要使用的模块,可以节省系统开销。
"""
针对python3解释器 其实文件夹里面有没有__init__.py已经无所谓了 都是包
但是针对Python2解释器 文件夹下面必须要有__init__.py才能被当做包
"""
软件开发目录规范
针对上述的第三个阶段 模块文件多了之后还需要有文件夹
我们所使用的所有的程序目录都有一定的规范(有多个文件夹)
目录规范并无固定的要求,只要符合清晰可读即可
bin文件夹
存放程序的启动文件
# start.py (start.py可以放在bin文件夹下也可以直接放在项目根目录)
conf文件夹
存放一系列配置文件
# settings.py
core文件夹
存放项目核心代码文件
# src.py
lib文件夹
存放程序公共功能
# common.py
db文件夹
存放数据相关文件
# userinfo.py
log文件夹
存放日志记录文件
# log.log
interfance文件夹
存放程序的接口文件
# user.py order.py goods.py
# readme
存放说明相关信息(类似于说明书 广告 章程)
# requirements.txt
存放所需要的第三方模块及版本
python常见内置模块
数据类型模块
1.collections模块
在python中,除了整型、浮点型、字符串、列表、字典、元组、集合、布尔值这八种基本数据类型以外,还提供了更多特殊的数据类型
1.1 具名元组(namedtuple):生成可以使用名字来访问元素内容的tuple
from collections import namedtuple
# Point = namedtuple('二维坐标系', ['x', 'y'])
# print(Point) # <class '__main__.二维坐标系'>
# coordinate1 = Point(10, 20)
# coordinate2 = Point(100, 200)
# print(coordinate1) # 二维坐标系(x=10, y=20)
# print(coordinate2) # 二维坐标系(x=100, y=200)
# print(coordinate1.y) # 20
# print(coordinate2.x) # 100
# Point = namedtuple('三维坐标系', 'x y z')
# print(Point) # <class '__main__.三维坐标系'>
# coordinate1 = Point(10, 20, 30)
# coordinate2 = Point(100, 200, 300)
# print(coordinate1) # 二维坐标系(x=10, y=20, z=30)
# print(coordinate2) # 二维坐标系(x=100, y=200, z=300)
# print(coordinate1.y) # 20
# print(coordinate2.x) # 100
# poker = namedtuple('扑克牌', ['花色', '点数'])
# Game1 = poker('♥', '7')
# Game2 = poker('♠', '8')
# Game3 = poker('♦', '9')
# Game4 = poker('♣', 'k')
# print(Game1) # 扑克牌(花色='♥', 点数='7')
# print(Game2) # 扑克牌(花色='♠', 点数='8')
# print(Game3) # 扑克牌(花色='♦', 点数='9')
# print(Game4) # 扑克牌(花色='♣', 点数='k')
"""
模拟扑克牌21点游戏,网上找到的,看见有趣,于是乎发挥了我的拿来主义!!!
"""
# import random
# import sys
#
# # 牌面列表
# card_code = ['A', '2', '3', '4', '5', '6', '7', '8', '9', '10', 'J', 'Q', 'K']
# # 花色列表
# card_symbol = ['♦', '♣', '♥', '♠']
#
#
# # 游戏初始化
# def init(player_count):
# # 根据玩家数来生成玩家记牌器
# player_group = [[] for _ in range(player_count)]
# # 根据玩家数来生成玩家是否要牌
# player_isWant = [True for _ in range(player_count)]
# # 生成元素1~52的列表 (去掉大小鬼的扑克牌[52张])
# poker = list(range(1, 53))
# # 用random的shuffle函数对列表打乱顺序 (洗牌)
# random.shuffle(poker)
# # 返回玩家组 玩家是否要牌 乱序52张扑克
# return player_group, player_isWant, poker
#
#
# # 打印玩家点数
# def print_player_point(player_group):
# # 存放玩家点数
# player_point = []
# # 遍历每一位玩家
# for index in range(len(player_group)):
# # 打印每位玩家的牌和点数
# print("-------玩家"+str(index+1)+"------")
# # 初始化玩家点数 如果含有牌A 因为A可视为1点或11点 则有两种点数
# current_player = [0, 0]
# # 遍历每位玩家的手牌
# for card in player_group[index]:
# """
# 核心代码
# 由于牌面的数字是从1到52 所以牌面要先减1再求余才是牌面列表真正的下标
# 若玩家抽到牌为15 即牌面为15 - 13 = 2 且按花色顺序为♣ 即2♣
# 牌面 15 - 1 = 14 再 14 % 13 = 1 这个就是对应牌面列表的第二位元素 即2
# 花色 15 - 1 = 14 再 14 / 13 = 1 对应花色列表第二位元素 即♣
# """
# # 获取牌面和花色下标
# code_index = int((card - 1) % 13)
# symbol_index = int((card - 1) / 13)
# # 打印玩家牌信息
# print(card_code[code_index] + card_symbol[symbol_index], end="\t")
# # 如果牌面含有A 则添加不同点数1和11
# if (code_index + 1) == 1:
# current_player[0] += 1
# current_player[1] += 11
# # 如果牌面不含A 则添加相同点数
# else:
# current_player[0] += code_index + 1
# current_player[1] += code_index + 1
# # 如果两个点数一致 则打印一个点数
# if current_player[0] == current_player[1]:
# print("点数为"+str(current_player[0])+"点")
# # 否则打印两个点数
# else:
# print("点数为"+str(current_player[0])+"点或"+str(current_player[1]))
# # 添加当前玩家点数
# player_point.append(current_player)
# # 返回所有玩家点数
# return player_point
#
#
# # 玩游戏
# def play_game():
# # 打印游戏规则
# print("-------21点游戏------")
# print("---A可看做1点或11点---")
# # 死循环一直进行游戏
# while True:
# # 初始化玩家数为0
# player_count = 0
# # 当玩家数小于等于1或大于5时继续询问
# while player_count <= 1 or player_count > 5:
# # 询问玩家数
# print("有多少位玩家?(2~5位)", end="")
# # 获取控制台输入的数字 无验证输入 若输入非数字 程序直接报错
# player_count = int(input())
# # 初始化游戏 返回玩家组 玩家是否要牌 乱序52张扑克
# player_group, player_isWant, poker = init(player_count)
# # 开始发牌 先为每位玩家发两张牌 循环玩家数
# for index in range(player_count):
# for i in range(2):
# # pop() 函数用于移除列表中的一个元素(默认最后一个元素)并且返回该元素的值。
# player_group[index].append(poker.pop())
# # 打印玩家点数 并获取当前玩家点数
# player_point = print_player_point(player_group)
# # 只要玩家继续要牌 且 还有剩余牌 则一直询问玩家是否要牌
# while True in player_isWant and len(poker) > 0:
# # 遍历玩家
# for index in range(player_count):
# # 判断玩家是否有可能还需要牌
# if player_isWant[index] is True:
# # 询问玩家是否要牌
# print("玩家"+str(index+1)+",您再要一张?(y/n)")
# # 获取控制台输入
# isWant = str(input())[0]
# # 如果输入的字符为"n" 则将玩家标记为不再需要牌
# if isWant == "n":
# player_isWant[index] = False
# # 如果不为字符"n" 默认为继续要牌 给该玩家发一张牌
# else:
# player_group[index].append(poker.pop())
# # 每轮询问结束 打印玩家点数 并获取当前玩家点数
# player_point = print_player_point(player_group)
# print("\n"*5+"====本轮游戏结束====")
# # 定义一个计分器
# score = []
# # 要牌结束 遍历所有玩家的点数 判断哪位玩家胜利
# for point_list in player_point:
# # 如果两个两个点数相同 说明没有A
# if point_list[0] == point_list[1]:
# # 如果分数大于21 直接取负数 小于等于21 任意取一个作为分数
# score.append(-point_list[0] if point_list[0] > 21 else point_list[0])
# # 如果两个点数不想同 说明含有A 则继续判断
# else:
# # 如果两个点数中大的那个点数还小于等于21
# if max(point_list) <= 21:
# # 去最大值为分数
# score.append(max(point_list))
# # 如果两个点数中大的那个点数大于21
# else:
# # 如果小的点数大于21 直接取负数 小于等于21 取最小值为分数
# score.append(-min(point_list) if min(point_list) > 21 else min(point_list))
# # 最高分
# max_point = max(score)
# # 如果最高分的人数为1 直接认为最高分的玩家获胜 打印游戏结果
# if score.count(max_point) == 1:
# print("玩家"+str(score.index(max_point) + 1)+"获胜!")
# # 否则最高分的分数有并列 认为有多个人获胜
# else:
# # 获胜玩家列表
# temp_list = []
# # 遍历分数
# for index in range(len(score)):
# # 分数等于最高分 记录玩家
# if score[index] == max_point:
# temp_list.append("玩家"+str(index+1))
# # 拼接获胜玩家列表 打印游戏结果
# print("恭喜"+",".join(temp_list)+"获胜!")
# # 询问是否继续游戏
# print("是否继续游戏?(y/n)")
# # 如果控制台输入不为字符"y" 表示退出
# if str(input())[0] != 'y':
# sys.exit()
#
#
# # 程序主入口
# if __name__ == '__main__':
# # 玩游戏
# play_game()
1.2 双端队列(deque)
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素
# from collections import deque
# l1 = deque()
# l1.append(666)
# l1.append(777)
# l1.append(888)
# l1.append(999)
# l1.appendleft(1000)
# print(l1) # deque([1000, 666, 777, 888, 999])
1.3 计数器(Counter) 主要用来计数
# from collections import Counter
# res = 'abcdeabcdabcaba'
# res1 = Counter(res)
# print(res1) # Counter({'a': 5, 'b': 4, 'c': 3, 'd': 2, 'e': 1})
1.4 有序字典(Orderedict)
使用dict时,Key是无序的。在对dict做迭代时,我们无法确定Key的顺序
如果要保持Key的顺序,可以用OrderedDict
# from collections import OrderedDict
# d = dict([('a', 1), ('b', 2), ('c', 3), ('d', 4)])
# print(d) # {'a': 1, 'b': 2, 'c': 3, 'd': 4}
# od = OrderedDict([('a', 1), ('b', 2), ('c', 3)])
# print(od) # OrderedDict([('a', 1), ('b', 2), ('c', 3)])
C:\Users\User_system>python2
Python 2.7.14 (v2.7.14:84471935ed, Sep 16 2017, 20:19:30) [MSC v.1500 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> dict([('a', 1), ('b', 2), ('c', 3), ('d', 4)])
{'a': 1, 'c': 3, 'b': 2, 'd': 4}
>>>
1.5 默认值字典(defaultdict)
# 有如下值集合 [11,22,33,44,55,66,77,88,99,90],
# 将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中
# {'k1':[], 'k2':[]}
# from collections import defaultdict
# res = defaultdict(k1=[],k2=[])
# print(res)
时间模块
2.时间模块之time模块
时间的三种格式
1.时间戳 time.time()
2.结构化时间 time.gmtime()
3.格式化时间 time.strftime()
# import time
# print(time.time()) # 1657805946.599186
# print(time.gmtime())
# time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=13, tm_min=39, tm_sec=6, tm_wday=3, tm_yday=195, tm_isdst=0)
# print(time.strftime('%Y-%m-%d %H:%M:%S')) # 2022-07-14 21:42:11
# print(time.strftime('%Y-%m-%d')) # 2022-07-14
# print(time.strftime('%H:%M:%S')) # 21:44:16
# print(time.strftime('%Y-%m-%d %X')) # 2022-07-14 21:44:16
# print(time.strptime('2022-07-14 21:44:16', '%Y-%m-%d %H:%M:%S'))
# time.struct_time(tm_year=2022, tm_mon=7, tm_mday=14, tm_hour=21, tm_min=44, tm_sec=16, tm_wday=3, tm_yday=195, tm_isdst=-1)
datetime模块
- 与time模块类似,都是可以对时间进行一些相关的操作
- py文件名称尽量不要与模块名冲突(内置、第三方)
| 功能列表 | 功能说明 |
|---|---|
| datetime.datetime | 描述日期时间对象,即year、月month、日day、 Hours、分minutes、秒second |
| datetime.data | 描述日期对象,即年year、月month、日day |
| datetime.timedelta | 换算时间间隔,可适用于做定时任务或日志精确查询 |
| datetime.time | 描述时间对象,即时Hours、分minutes、秒second |
| datetime.now | 获取当前datetime |
| datetime.utcnow | 获取当前格林威治时间 |
import datetime
tes = datetime.datetime.today()
print(tes) # 2022-07-15 15:36:27.904993
tes1 = datetime.date.today()
print(tes1) # 2022-07-15
"""
如何区分时间模块中的年月日、时分秒
datetime 年月日 时分秒
date 年月日
"""
test2 = datetime.timedelta(days=6)
print(tes1 + test2) # 2022-07-21
print(tes1 - test2) # 2022-07-09
"""
timedelta后面的括号内可以添加很多参数,也可以通过换算进行获取,比如年、月
"""
print(datetime.datetime.now()) # 2022-07-15 15:50:23.004384
print(datetime.datetime.utcnow()) # 2022-07-15 07:50:23.004384
assign = datetime.datetime(2018, 1, 1, 00, 00)
print('时空穿梭:', assign) # 时空穿梭: 2018-01-01 00:00:00
os模块
- os模块是与操作系统交互的一个接口
| 功能列表 | 功能说明 |
|---|---|
| os.mkdir | 用于创建单级目录 |
| os.makedirs | 用于创建单级目录和多级目录 |
| os.rmdir | 用于删除单级目录,无法删除有数据的目录,只能删除空白文件夹 |
| os.removedirs | 用于删除多级目录,无法删除有数据的目录,由内往外删除依次删除 |
| os.listdir | 指定路径下的文件名称 |
| os.rename | 重命名文件 |
| os.remove | 删除文件 |
| os.getcwd | 获取当前所在的绝对路径 |
| os.chdir | 切换路径 |
| os.path.abspath(file) | 获取当前文件的绝对路径 |
| os.parh.dirname(file) | 获取当前文件所在的目录路径 |
| os.path.exists | 判断路径是否存在(文件、目录) |
| os.path.isdir | 判断路径是否是目录(文件夹) |
| os.path.isfile | 判断路径是否是文件 |
| os.path.join | 拼接路径 |
| os.ptah.getsize | 获取文件大小 |
import os
# 1.创建目录
# os.mkdir(r'home') # 可以创建单层目录,无法创建多级目录
# os.makedirs(r'tmp\dev\sdb\src1') # 创建多级目录
# os.makedirs(r'etc') # makedirs也可以创建单级目录
# 2.删除目录
# os.rmdir(r'etc') # 删除单级目录,无法删除有其他数据的目录 只能删除空白文件夹
# os.removedirs(r'tmp\dev\sdb\src1') # 删除多级目录,针对有数据的目录同样无法删除 由内而外删除空目录,直到有数据的目录为止
# 3.列举指定路径下的文件名称(文件、目录)
# print(os.listdir()) # ['.idea', 'datatime.py', 'home', 'os模块.py', '__pycache__']
# print(os.listdir(r'D:\\')) # 查看当前盘符内所有的文件夹
# 4.重命名文件、删除文件
# os.rename(r'userinfo.txt', r'my_info.txt') # 重命名文件
# os.remove(r'my_info.txt') # 删除文件
# 5.获取当前所在的路径
# print(os.getcwd()) # D:\python\study\day21 绝对路径
# os.chdir(r'..') # 切换路径
# print(os.getcwd()) # D:\python\study
# 6.与程序启动文件相关
# print(os.path.abspath(__file__)) # 获取当前文件的绝对路径
# print(os.path.dirname(__file__)) # 获取当前文件所在的目录路径
# 7.判断路径是否存在(文件、目录)
# print(os.path.exists(r'home')) # True
# print(os.path.exists(r'test')) # False
# print(os.path.exists(r'datatime.py')) # True
# print(os.path.exists(r'userinfo.txt')) # False
# print(os.path.isdir(r'home')) # True 用于判断路径是否是目录(文件夹)
# print(os.path.isdir(r'datatime.py')) # False
# print(os.path.isfile(r'home')) # False 用于判断路径是否是文件
# print(os.path.isfile('datatime.py')) # True
# 8.拼接路径
# relative_path = 'userinfo.txt'
# absolute_path = r'D:\python\study\day21\tmp'
# print(absolute_path + relative_path)
"""
涉及到路径拼接,不要使用+号 用join方法
"""
# res = os.path.join(absolute_path, relative_path)
# print(res) # D:\python\study\day21\tmp\userinfo.txt
# ps:join方法可以自动识别当前所在的操作系统并自动切换正确的分隔符 windows用\ mac用/
# 9.获取文件大小 bytes
# print(os.path.getsize(r'os模块.py')) # 2715
# print(os.path.getsize(r'userinfo.txt')) # 260
sys模块
- sys模块是与python解释器交互的一个接口
| 功能列表 | 功能说明 |
|---|---|
| sys.path | 搜索文件路径 |
| sys.version | 查看解释器版本 |
| sys.platfrom | 查看当前平台 |
| sys.argv | 命令行参数List,第一个元素是程序本身路径 |
# sys.argv 命令行参数List,第一个元素是程序本身路径
# sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
# sys.version 获取Python解释程序的版本信息
# sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
# sys.platform 返回操作系统平台名称
import sys
# print(sys.path) # 结果是个列表
# print(sys.version) # 3.8.6 (tags/v3.8.6:db45529, Sep 23 2020, 15:52:53) [MSC v.1927 64 bit (AMD64)] 查看解释器版本信息
# print(sys.platform) # 查看当前平台 win32
res = sys.argv
if len(res) == 3:
username = res[1]
password = res[2]
if username == 'zhangsan' and password == '666':
print('you can perform')
else:
print('username and password error')
else:
print('please input username and password')
json模块
| 功能列表 | 功能说明 |
|---|---|
| json.dumps | 将其他数据类型转换为json格式字符串 |
| json.loads | 将json格式字符串转换为对应的编程语言中的数据类型 |
| json.dump | 将其他数据以json格式字符串写入文件 |
| json.load | 将文件中json格式字符串读取出来并转换成对应的数据类型 |
json模块也称之为序列化模块
json模块是不同编程语言之间数据交互必备的模块(处理措施)
不同编程语言之间数据类型存在差异,无法直接进行交互
json格式的数据应该是什么
数据基于网络传输肯定是二进制 那么在python中只有字符串可以调用encode方法转成二进制数据 所以json格式的数据也属于字符串
json格式的数据有一个非常明显的特征
首先肯定是字符串 其次引号是标志性的双引号
# dic = {'name': 'zhangsan', 'pwd': 666}
"""
需求:将上述字典中的保存到文件中,并且读取出来之后还是字典
"""
# with open(r'dic.txt', 'w', encoding='utf8') as f:
# f.write(str(dic))
# with open(r'dic.txt', 'r', encoding='utf8') as f:
# data = f.read()
# print(data, type(data)) # {'name': 'zhangsan', 'pwd': 666} <class 'str'>
# import json # 序列化 将其他数据类型转换为json格式字符串
# userinfo = json.dumps(dic)
# print(userinfo, type(userinfo)) # {"name": "zhangsan", "pwd": 666} <class 'str'>
# dic1 = {"name": "lisi", "pwd": 777}
# print(dic1) # {'name': 'lisi', 'pwd': 777}
# userinfo1 = json.loads(userinfo) # 反序列化 将json格式字符串转换为对应的编程语言中的数据类型
# print(userinfo1, type(userinfo1)) # {'name': 'zhangsan', 'pwd': 666} <class 'dict'>
# import json
# with open(r'dic.txt', 'w', encoding='utf8') as f:
# f.write(json.dumps(dic)) # {"name": "zhangsan", "pwd": 666}
# json.dump(dic, f) # 直接将字典写入文件,json会自动完成格式转换
# with open(r'dic.txt', 'r', encoding='utf8') as f:
# data = f.read()
# res = json.loads(data)
# print(res, type(res)) # {'name': 'zhangsan', 'pwd': 666} <class 'dict'>
# res = json.load(f)
# print(res, type(res)) # {'name': 'zhangsan', 'pwd': 666} <class 'dict'>
"""
dumps() 将其他数据类型转换成json格式字符串
loads() 将json格式字符串转化成对应的数据类型
dump() 将其他数据数据以json格式字符串写入文件
load() 将文件中json格式字符串读取出来并转换成对应的数据类型
"""

 浙公网安备 33010602011771号
浙公网安备 33010602011771号