【2022-07-03】上周内容总结
上周内容回顾
Python数据类型内置方法
数据类型之列表内置方法
-
列表类型描述:使用中括号括起来,内部可以存放多个数据值,数据值与数据值之间用逗号隔开,数据值可以是任意数据类型,表达关键字为list
# 1.定义列表 l1 = [11, 22, 'huawei', {'name': 'la'}, 77, 88] l2 = [1, 2, 3, 4, 5, 6] l3 = [11, 22, 33, 44, 55] # 2.统计列表中数据值的个数 print(len(l1)) # 6 print(len(l2)) # 6 print(len(l3)) # 5 # 3.列表的增 # 3.1 尾部追加元素append() 括号内无论写什么数据类型,都是当成单个数据值进行追加 l1.append({'age': '18'}) # [11, 22, 'huawei', {'name': 'la'}, 77, 88, {'age': '18'} l1.append([7, 8, 9]) # [11, 22, 'huawei', {'name': 'la'}, 77, 88, {'age': '18'}, [7, 8, 9]] print(l1) # 列表在调用内置方法后不会产生新的数据值,而是修改它自身 # 3.2 在任意位置放入数据值insert() l1.insert(3, 'ali') print(l1) # [11, 22, 'huawei', 'ali', {'name': 'la'}, 77, 88, {'age': '18'}, [7, 8, 9]] # 3.3 扩展列表extend() l2.extend(l3) print(l2) # [1, 2, 3, 4, 5, 6, 11, 22, 33, 44, 55] # 4.查询列表与修改数据 # 查询列表用print print(l1) # [11, 22, 'huawei', 'ali', {'name': 'la'}, 77, 88, {'age': '18'}, [7, 8, 9]] print(l1[2]) # huawei print(l1[1:5]) # [22, 'huawei', 'ali', {'name': 'la'}] # 修改数据 l2[3] = 7 print(l2) # [1, 2, 3, 7, 5, 6, 11, 22, 33, 44, 55] # 5.删除数据 # 5.1 使用索引的方式进行数据删除 del l1[4] print(l1) # [11, 22, 'huawei', 'ali', 77, 88, {'age': '18'}, [7, 8, 9]] # 5.2 指定数据值进行删除 l1.remove({'age': '18'}) l1.remove([7, 8, 9]) print(l1) # [11, 22, 'huawei', 'ali', 77, 88] # 5.3 先取出数据值,然后进行删除 l4 = l3.pop() # 如果括号后面不指定数据值,默认取出列表最后一个数据值进行删除 print(l3, l4) # [11, 22, 33, 44] 55 l4 = l3.pop(1) # 括号内指定了要删除的数据值 print(l3, l4) # [11, 33, 44] 22 # 6.查看数据值对应的索引值 print(l1.index('huawei')) # 2 # 7.统计某个数据值出现的次数 print(l1.count(11)) # 1 # 8.排序 l2.sort() print(l2) # [1, 2, 3, 5, 6, 7, 11, 22, 33, 44, 55] 升序 l2.sort(reverse=True) print(l2) # [55, 44, 33, 22, 11, 7, 6, 5, 3, 2, 1] 降序 # 9.反转 l2.reverse() print(l2) # [1, 2, 3, 5, 6, 7, 11, 22, 33, 44, 55] # 10.比较运算 print(l2 < l3) # True 列表在比较大小的时候是按照位置顺序进行一一比对的
数据类型之字典内置方法
-
字典类型描述:使用大括号括起来,内部可以存放多个数据值,数据值与数据值之间用逗号隔开,数据值可以是任意数据类型,组织形式为K:V键值对
-
表达关键字为dict
字典类型转换一般很少涉及,都是直接定义使用的 info = { 'username': '张三', 'password': 666, 'hobby': ['study', 'run'], } # 1.取值操作,字典内K:V键值对是无序的,无法使用索引取值 print(info['password']) # 666 # print(info['weight']) # 如果字典内键值不存在,则会报错,不推荐使用 print(info.get('username')) # 张三 print(info.get('gender')) # None 如果字典内键值不存在,默认会返回值None # 2.统计字典内键值对的个数 print(len(info)) # 3 # 3.字典的内置方法不可以查询,只能进行增加、删除和修改数据,K键存在则是修改数据,K键不存在则是新增数据 # 3.1 字典新增数据 info['salary'] = 12000 print(info) # {'username': '张三', 'password': 666, 'hobby': ['study', 'run'], 'salary': 12000} # 3.2 修改数据 info['username'] = '李四' info['password'] = 777 print(info) # {'username': '李四', 'password': 777, 'hobby': ['study', 'run'], 'salary': 12000} # 3.3 删除数据 # 方式一:del删除 del info['hobby'] # {'username': '李四', 'password': 777, 'salary': 12000} print(info) # 方式二:内置方法pop删除 info_back = info.pop('salary') print(info, info_back) # {'username': '李四', 'password': 777} 12000 # 方式三:随机删除 info.popitem() print(info) # {'username': '李四'} # 4.快速获取字典内的键、值、键值对数据 print(info.keys()) # dict_keys(['username']) 获取字典所有的K值,结果是一个列表 print(info.values()) # dict_values(['李四']) 获取字典所有的V值,结果是一个列表 print(info.items()) # dict_items([('username', '李四')]) 获取字典所有的K:V键值对,结果是列表套元组 # 5.快速构造一个字典 create = dict.fromkeys(['username', 'age', 'job'], {}) print(create) # {'username': {}, 'age': {}, 'job': {}}
数据类型之元组内置方法
-
元组类型描述:用小括号括起来,内部存放多个数据值,数据值与数据值之间用逗号隔开,数据值可以是任意数据类型,也称为不可变的列表
-
表达关键字为tuple
元组的类型转换,支持for循环的数据类型都可以进行转换 print(tuple('six')) # ('s', 'i', 'x') print(tuple([11, 22, 33, 44, 55])) # (11, 22, 33, 44, 55) print(tuple({'username': '张三', 'age': 32})) # ('username', 'age') # 当元组内只有一个数据值时,括号内数据值的后面,逗号不能省略,否则括号里是什么数据类型就打印什么数据类型 t1 = () print(type(t1)) # <class 'tuple'> t2 = (11,) print(type(t2)) # <class 'tuple'> t3 = (11.11,) print(type(t3)) # <class 'tuple'> t4 = ('username',) print(type(t4)) # <class 'tuple'> t5 = (666, 777, 888, 999) # 1.统计元组内数据值的个数 print(len(t5)) # 4 # 2.查找数据值,元组的索引无法改变绑定地址 print(t5[2]) # 888 # t5[1] = 444 # 元组内数据值无法修改,元组内如果数据值有列表的话,可以更改列表绑定的对应数据值 t6 = (666, 777, 888, 999, [1, 2, 3]) t6[-1].append(4) print(t6) # (666, 777, 888, 999, [1, 2, 3, 4]) 在元组内的列表末尾追加一个数据值
数据类型之集合内置方法
-
定义空集合需要使用关键字set才可以
-
类型转换:和元组一样,能够被for循环的数据类型都可以转换为集合,但是转换完的数据值只能是不可变的数据类型
-
集合内数据类型必须是不可变的数据类型,即整型、浮点型、字符串、元组、布尔值
# 集合自带去重特性,且返回的值默认会存放在字典里{},也可以进行指定,如存放在列表里 l1 = ['张三', '李四', 'eat', 'run', 'run', 'read', 'red', 'red', 'green', 'black', 'green'] l2 = set(l1) print(l2) # {'eat', 'read', 'red', 'black', '李四', '张三', 'run', 'green'} l1 = list(l2) print(l1) # ['red', 'read', 'run', 'eat', 'black', '张三', '李四', 'green'] # 关系运算,模拟两个人的好友集合 a1 = {'宋江', '吴用', '卢俊义', '晁盖', '武松', '李逵'} a2 = {'刘备', '关羽', '李逵', '曹操', '周瑜', '马超'} # 1.求a1和a2的共同好友 print(a1 & a2) # {'李逵'} # 2.求a1和a2独有的好友 print(a1 - a2) # {'卢俊义', '晁盖', '宋江', '吴用', '武松'} print(a2 - a1) # {'刘备', '马超', '关羽', '周瑜', '曹操'} # 3.求a1和a2所有的好友 print(a1 | a2) # {'吴用', '宋江', '马超', '李逵', '曹操', '卢俊义', '刘备', '晁盖', '武松', '关羽', '周瑜'} # 4.求a1和a2各自独有的好友,排除共同好友 print(a1 ^ a2) # {'武松', '宋江', '卢俊义', '吴用', '关羽', '周瑜', '晁盖', '刘备', '曹操', '马超'} # 5.父集、子集 s1 = {1, 2, 3, 4, 5, 6, 7} s2 = {3, 2, 1} print(s1 > s2) # True 判断s1是不是s2的父集,s2是不是s1的子集
可变类型与不可变类型
-
可变数据类型:数据值发生改变时,内存地址不变,即id不变,证明在改变原有的数据值
-
不可变数据类型:数据值发生改变时,内存地址也发生改变,即id也改变,证明是没有在改变原有的数据值,而是产生了新的数据值
-
数字类型
>>> x = 10 >>> id(x) 1830448896 >>> x = 20 >>> id(x) 1830448928 # 内存地址改变了,说明整型是不可变数据类型,浮点型也一样 -
字符串
>>> x = "Jy" >>> id(x) 938809263920 >>> x = "Ricky" >>> id(x) 938809264088 # 内存地址改变了,说明字符串是不可变数据类型 -
列表
>>> list1 = ['tom','jack','oscar'] >>> id(list1) 486316639176 >>> list1[2] = 'kevin' >>> id(list1) 486316639176 >>> list1.append('lili') >>> id(list1) 486316639176 # 对列表的值进行操作时,值改变但内存地址不变,所以列表是可变数据类型 -
字典
>>> dic = {'name':'oscar','sex':'male','age':18} >>> >>> id(dic) 4327423112 >>> dic['age']=19 >>> dic {'age': 19, 'sex': 'male', 'name': 'oscar'} >>> id(dic) 4327423112 # 对字典进行操作时,值改变的情况下,字典的id也是不变,即字典也是可变数据类型 -
元组
>>> t1 = ("tom","jack",[1,2]) >>> t1[0]='TOM' # 报错:TypeError >>> t1.append('lili') # 报错:TypeError # 元组内的元素无法修改,指的是元组内索引指向的内存地址不能被修改 >>> t1 = ("tom","jack",[1,2]) >>> id(t1[0]),id(t1[1]),id(t1[2]) (4327403152, 4327403072, 4327422472) >>> t1[2][0]=111 # 如果元组中存在可变类型,是可以修改,但是修改后的内存地址不变 >>> t1 ('tom', 'jack', [111, 2]) >>> id(t1[0]),id(t1[1]),id(t1[2]) # 查看id仍然不变 (4327403152, 4327403072, 4327422472)
字符编码简介
垃圾回收机制
-
什么是垃圾回收机制
垃圾回收机制(简称GC)是python解释器自带的一种机制,专门用来回收不可用的数据值所占用的内存空间
-
垃圾回收机制的原理
Python 的GC模块主要运用了引用计数来跟踪和回收垃圾;通过“标记-清除”解决容器对象可能产生的循环引用问题;通过分代回收以空间换时间进一步提高垃圾回收的效率。
-
引用计数
为每一个对象维护一个引用计数器,当一个对象的引用被创建或者复制时,(对象的引用)计数器+1,当一个对象的引用被销毁时,计数器的值-1,当计数器的值为0时,就意味着对象已经再没有被使用了,可以将其内存释放掉。
比如:a = 66 # 数据值66绑定给了变量名a,这个就称之为引用计数为1 增加引用计数: a = 66 # 此时的引用计数为1 b = a # 把a的内存地址给了b,此时a和b都绑定了66,所以数据值66的引用计数就为2 减少引用计数: a = 20 # 变量名a先与数据值66解除绑定,数据值66的引用计数为1 del b # del的意思就是解除变量名b与数据值66的关联关系,这个时候,数据值66的引用计数为0此外,引用计数还存在着一个巨大的缺陷就是循环引用,类似于while循环里的死循环,它会导致数据值不再被任何的变量名绑定,但是数据值的引用计数不会为0 # 如下我们定义了两个列表,简称列表1与列表2,变量名l1指向列表1,变量名l2指向列表2 # l1=['123'] # 列表1被引用一次,列表1的引用计数变为1 # l2=['321'] # 列表2被引用一次,列表2的引用计数变为1 # l1.append(l2) # 把列表2追加到l1中作为第二个元素,列表2的引用计数变为2 # l2.append(l1) # 把列表1追加到l2中作为第二个元素,列表1的引用计数变为2 # l1与l2之间有相互引用 # l1 = ['123'的内存地址,列表2的内存地址] # l2 = ['321'的内存地址,列表1的内存地址] # l1 ['123', ['321', [...]]] # l2 ['321', ['123', [...]]] # del l1 # 列表1的引用计数减1,列表1的引用计数变为1 # del l2 # 列表2的引用计数减1,列表2的引用计数变为1此时,只剩下列表1与列表2之间的相互引用,两个列表的引用计数均不为0,但两个列表不再被任何其他对象关联,没有任何人可以再引用到它们,所以它俩占用内存空间应该被回收,但由于相互引用的存在,每一个对象的引用计数都不为0,因此这些对象所占用的内存永远不会被释放,所以循环引用是致命的,这与手动进行内存管理所产生的内存泄露毫无区别。所以Python引入了“标记-清除” 与“分代回收”来分别解决引用计数的循环引用与效率低的问题
-
标记清除
“标记-清除”的出现打破了循环引用,它只关注那些可能会产生循环引用的对象,Python中的循环引用总是发生在容器container对象之间,也就是能够在内部持有其他对象的对象(比如:list、dict、class等)。这也使得该方法带来的开销只依赖于容器对象的数量。
- 分代回收
在检查数据值的过程中,多次扫描都没有被回收的数据值,GC机制就会认为,该数据值是常用数据值,存活时间越长的数据值,就越不可能是垃圾,于是便减少了对它的垃圾收集频率
字符编码简介
-
什么是字符编码
字符编码,编码的意思是指将数据通过一定方式表达或储存。所以字符编码就是字符的表现、储存方式,也就是字符集的实现方式。
-
编码与解码
我们计算机中存储的信息都是用二进制数来表示的,像我们在电脑屏幕上看到的数字,文本文件,标点符号等等都是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称之为编码。反之,将存储在计算机中的二级制数按照某种规则解析显示出来,称之为解码。
字符编码发展史
1.一家独大
计算机是有美国人发明的 美国人需要让计算机识别英文字符
ps:英文所有的字符加起来不超过127个(2的七次方) 但是美国人考虑到后续可能出现新的字符所以加了一位以备不时之需(2的八次方)
ASCII码:内部只记录了英文字符与数字的对应关系
1bytes来存储字符
A-Z 65-90
a-z 97-122
ps:此时的计算机只能识别英文 不识别其他文字
2.群雄割据
中国
需要让计算机识别中文 需要开发一套中文的编码表
GBK码:内部记录了中文字符、英文字符与数字的对应关系
2bytes起步存储中文(遇到生僻字使用更多字节)
1bytes存储英文
韩国
需要让计算机识别韩文 需要开发一套韩文的编码表
Euc_kr码:内部记录了韩文字符、英文字符与数字的对应关系
日本
需要让计算机识别日文 需要开发一套日文的编码表
shift_JIS码:内部记录了日文字符、英文字符与数字的对应关系
ps:此时的各国计算机文本文件无法直接交互 会出现乱码的情况
3.天下一统
万国码(unicode):兼容万国字符
所有的字符全部使用2bytes起步存储
utf家族(针对unicode的优化版本)>>>:utf8
英文还是采用1bytes
其他统一采用3bytes
Python文件处理
文件操作简介
-
什么是文件
文件是操作系统为用户或应用程序提供的一个读写硬盘的虚拟单位。文件的操作是基于文件,即文件的操作核心就是:读和写。也就是说只要我们想要操作文件就要向操作系统发起请求,然后由操作系统将用户或应用程序对文件的读写操作转换为集体的硬盘指令,来读取数据
-
为什么要有文件
内存是无法永久保存数据的,如果出现意外断电的情况,那么很有可能会造成数据的损坏与丢失,但是我们可以通过把文件保存在硬盘中,而操作文件就可以实现对硬件的操作
-
如何使用文件
比如从硬盘中读取数据,打开一个文件夹,我们需要向操作系统发起请求,要求操作系统打开文件,占用操作系统资源。在python中使用open()方法可以打开某个具体的文件,open()方法内写入文件的路径即可
open(r'D:\aaa\bbb\1.txt) 针对文件路径需要注意 可能存在特殊含义(字母与撬棍的组合,在字符串的前面加字母r即可取消特殊含义
文件读写模式
1.with语法可以一次性打开多个文件
with open(r'123.txt', 'r', encoding='utf8') as f1, open(r'a.txt', 'r', encoding='utf8')as f2:
print(f1.read())
print(f2.read())
2.pass 是一个python补全语法,但是不执行任何操作,还有一种补全语法:...但是不推荐使用
3.在程序里边,读写是分离的,目的是为了防止文件过多,同时进行读写的话,容易造成文件数据的错乱
4.通常情况下,英语单词的末尾如果加上了able就表示具备了该单词描述的功能
readable 具备读取内容的功能
writable 具备填写内容的功能
not readable 不具备读取内容的功能
not writable 不具备填写内容的功能
文件常用的三种读写模式:
r 只读模式 使用该模式打开的文本文件只能进行读取操作,无法进行其他操作(比如写操作) 适用于读取数据的场景使用
# 当文件路径存在时:只读模式会打开文件,等待用户读取文件内容
with open(r'123.txt', 'r', encoding='utf8')as f:
f.read()
# 当文件路径不存在时:只读模式r会直接报错
with open(r'666.txt', 'r', encoding='utf8')as f1:
pass
w 只写模式 使用该模式打开的文本文件只能进行写操作,无法进行其他操作(比如读操作) 适用于产生数据的场景使用
# 当文件路径存在时:只写模式w在打开文件后,会清空文件的内容,之后等待用户填写新的内容
# with open(r'123.txt', 'w', encoding='utf8')as f:
# pass
# 当文件路径不存在时:只写模式w会自动创建该文件
# with open(r'666.txt', 'w', encoding='utf8')as f1:
# pass
a 追加模式 使用该模式打开的文本文件,默认在文件的末尾追加新的内容,无法进行其他的操作(比如读操作)
# 当文件路径存在时:追加模式a在打开文件后,不会清空文件的内容,只在文件的末尾等待用户填写新的内容
# with open(r'123.txt', 'a', encoding='utf8')as f:
# f.write('好好学习,天天向上\n')
# 当文件路径不存在时:追加模式a会自动创建该文件
# with open(r'777.txt', 'a', encoding='utf8')as f1:
# pass
默认情况下,用的都是只读模式r
| 模式 | 描述说明 |
|---|---|
| t | 文本模式(默认) |
| x | 写模式,新建一个文件,如果该文件已存在,则会报错 |
| b | 二进制模式 |
| + | 打开一个文件进行更新(可读可写) |
| U | 通用换行模式(不推荐使用) |
| r | 以只读的方式打开文件,文件的指针会放在文件的开头,这是默认模式 |
| rb | 以二级制格式打开一个文件用于只读, 文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
下图很好的总结了这几种模式:
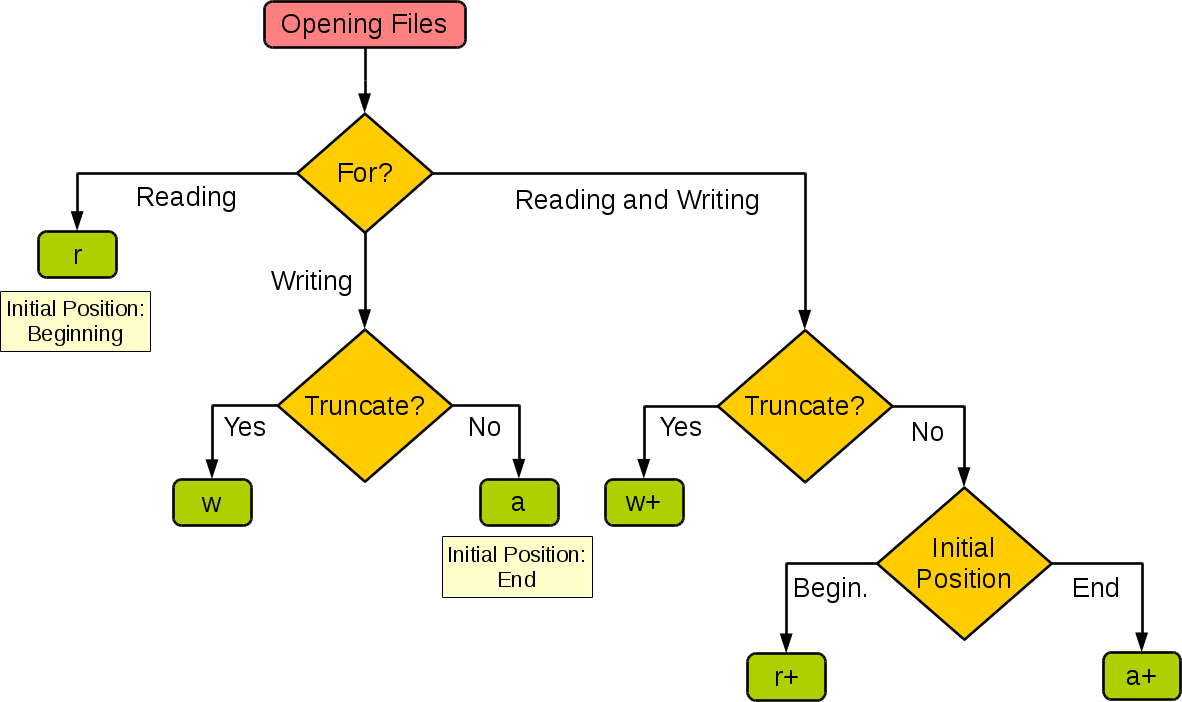
支持原创,以上内容摘自:https://www.runoob.com/python/python-files-io.html
文件操作模式
文件的操作模式有两种:
t 文本模式
文件操作的默认模式
r>>>>>>>>>>rt
w>>>>>>>>>>wt
a>>>>>>>>>>at
特点:
1.只能操作文本文件
2.必须指定encoding参数
3.读写数据默认都是以字符串为单位
# with open(r'123.txt', 'r', encoding='utf8')as f:
# print(type(f.read())) # <class 'str'>
b 二进制模式
rb wb ab 必须自己指定,不能省略
特点:
1.能够操作所有类型的文件
2.不需要指定encoding参数
3.读写都是以bytes为单位
# with open(r'美女.png', 'rb')as f:
# print(f.read()
二进制模式下读写的数据都是二进制,可以打开任意数据类型的文件(图片、音频、视频等)
二进制模式下可以实现拷贝功能
with open(r'666.png', 'rb')as read_f, open(r'777.png', 'wb')as write_f:
write_f.write(read_f.read())
文件操作方法
read() 一次性读取文件内容并且光标会停留在文件末尾 继续读则为空
"""当文件数据较大的时候 不推荐一次性读取"""
for line in f:
print(line) 文件对象支持for循环一次只读一行
readline() 一次只读一行内容
readlines() 按照行的方式读取所有的内容并组织成列表返回
readable() 判断当前文件是否可读
writable() 判断当前文件是否可写
write() 填写文件内容
writelines() 支持填写容器类型(内部可以存放多个数据值的数据类型)多个数据值
flush() 将内存中的文件数据立刻刷到硬盘(主动按ctrl+s)
文件内光标的移动
只有在文本模式使用的情况下,read控制的是字符,其余情况都是以字节为单位
userinfo.txt = libai say 人生得意须尽欢,莫使金樽空对月
with open(r'userinfo.txt', 'r', encoding='utf8') as f:
data = f.read(30) # 在文本模式下,read括号内的数字表示读取几个字符
print(data) # libai say 人生得意须尽欢,莫使金樽空对月
with open(r'userinfo.txt', 'rb') as f:
data = f.read(30) # 在二进制模式下,read括号内的数字表示读取几个字节(英文表示一个bytes,中文表示三个bytes)
print(data) # b'libai say \xe4\xba\xba\xe7\x94\x9f\xe5\xbe\x97\xe6\x84\x8f\xe9\xa1\xbb\xe5\xb0\xbd\xe6\xac'
查看目前光标移动的位移量:
print(f.tell()) # 获取光标移动的字节数
如何使用代码控制光标的移动
seek(offset,whence)
offset 控制光标移动的位移量(以字节为单位)
whence 移动的模式
0 基于文件开头的位置往后移动多少字节
1 基于光标当前所在的位置移动多少字节
2 基于文件末尾移动多少字节
1和2只能在二进制模式下使用
# with open(r'userinfo.txt', 'rb') as f:
# data = f.read(4)
# print(data.decode('utf8')) # liba
# # f.seek(-2, 1)
# # print(data.decode('utf8')) # liba
# f.seek(-2, 2)
# print(data.decode('utf8')) # liba
# 小练习:实现动态查看最新一条日志的效果
import time
with open('access.log', 'rb') as f:
f.seek(0, 2)
while True:
line = f.readline()
if len(line) == 0:
# 没有内容
time.sleep(0.5)
else:
print(line.decode('utf-8'), end='')
文件内数据的修改
机械硬盘存储数据的原理
1.数据的修改 其实是覆盖写
2.数据的删除 占有态自由态
# 文件桃园三结义.txt内容如下
刘备 东汉 100 30 10086
关羽 东汉 95 100 10086
张飞 东汉 70 95 10086
# 执行操作
with open('桃园三结义.txt',mode='r+t',encoding='utf-8') as f:
f.seek(9)
f.write('<周瑜打黄盖>')
# 文件修改后的内容如下
刘备<周瑜打黄盖> 100 30 10086
关羽 东汉 95 100 10086
张飞 东汉 70 95 10086
PS:
# 1、硬盘空间是无法修改的,硬盘中数据的更新都是用新内容覆盖旧内容
# 2、内存中的数据是可以修改的
代码修改文件的方式
1.覆盖写
先读取文件内容到内存 在内存中完成修改 之后w模式打开该文件写入
2.重命名
先读取文件内容到内存 在内存中完成修改 之后保存到另外一个文件中
再将原文件删除 将新的文件重命名为原文件
文件修改方式一:覆盖写
# 将文件内容发一次性全部读入内存,然后在内存中修改完毕后再覆盖写回原文件
# 优点: 在文件修改过程中同一份数据只有一份
# 缺点: 会过多地占用内存,当数据量过大时,容易造成内存溢出
with open('123.txt',mode='rt',encoding='utf-8') as f:
data=f.read()
with open('123.txt',mode='wt',encoding='utf-8') as f:
f.write(data.replace('张三','NB'))
文件修改方式二:重命名
# 以读的方式打开原文件,以写的方式打开一个临时文件,一行行读取原文件内容,修改完后写入临时文件...,删掉原文件,将临时文件重命名原文件名
# 优点: 不会占用过多的内存空间
# 缺点: 在文件修改过程中同一份数据存了两份
import os
with open('123.txt',mode='rt',encoding='utf-8') as read_f,\
open('.123.txt.swap',mode='wt',encoding='utf-8') as wrife_f:
for line in read_f:
wrife_f.write(line.replace('NB','张三'))
os.remove('123.txt') # 删除文件
os.rename('.123.txt.swap','123.txt') # 重命名文件
Python函数
函数简介
- 什么是函数
假设你现在是一名维修工人,如果你事先已经准备好了工具,当你接收到某个维修任务的时候,那你就可以直接拿上工具去工作,而不是临时去制作。
同理,在程序中,函数其实就是具备某一个功能的工具,事先将工具准备好就是函数的定义,遇到需要使用的应用场景,就是函数的调用。
函数的作用
- 减少代码的冗余,增加程序的可扩展性和维护性
- 提高应用的模块性和代码的重复利用率
- 避免重复的编写代码,函数的编写更容易理解
- 保持代码的一致性,方便修改,更易于扩展
函数的基本使用
函数的本质
- 结合上面的例子,我们可以把函数看做是一个工具,提前定义好,之后就可以进行反复的使用,函数的使用必须遵循一个原则:即先定义,后调用!!!
函数语法结构
def 函数名(参数1,参数2):
"""函数注释"""
函数体代码
return返回值
语法参数说明
- def:是定义函数的关键字
- 函数名:与变量名的命名一致,尽量做到见名知意
- 括号:在定义函数的时候函数名后面必须要有括号
- 参数:定义函数括号内可以写参数也可以不写参数,写参数的时候,个数不固定,用于接收外界传给函数体代码内部的数据
- 函数注释:类似于用户说明书,用于介绍函数的主体功能和具体用法
- 函数体代码:函数最核心的区域,即逻辑代码
- return返回值:控制函数的返回值,返回值就是在调用函数之后,看有没有反馈的结果,如果有结果就可以得到返回值,没有结果就得不到返回值
函数的定义与调用
- 函数的定义
def my_func():
pass
- 函数的调用
my_func()
-
定义函数必须遵循一个原则:先定义后调用
-
定义函数的代码必须要在调用函数的代码之前先运行
-
定义函数使用关键字def,调用函数使用函数名加括号(可能需要添加额外的参数)
-
函数在定义阶段只检测函数体代码的语法,不执行函数体代码,函数只有在调用阶段才会执行函数体代码
-
什么是函数名
-
函数名绑定的是一个内存地址,里面存放了函数体代码,要想运行该函数体代码,就需要调用函数>>>函数名加括号
def my_function(x, y):
"""这是一行简单的注释"""
print('这是函数体代码')
print(my_function) # <function my_function at 0x000002B2632995E0>
def my_function():
print('这是打印的内容')
name = 'zs'
name = my_function
my_function() # 这是打印的内容
name() # 这是打印的内容
- PS:函数名加括号执行优先级最高(定义阶段除外,因为定义阶段不会执行函数体代码)
函数的分类
内置函数
- python解释器提前定义好的函数,用户可以直接进行使用,如input()、len()等等
- 内置函数可以直接调用,但是数据类型的内置方法(函数)必须使用数据类型点的方式才可以调用,相当于是数据类型独有的一些内置方法
自定义函数
-
空函数,即函数体代码使用pass顶替,暂时没有任何功能,主要用于项目前期的搭建,充当提示功能
def function(): pass -
无参函数,在函数定义阶段,括号内没有添加任何参数,无参函数直接使用函数名+括号就可以调用
def function(): print('这是一个无参函数') -
有参函数,在函数定义阶段,括号内填写参数,有参函数调用需要函数名+括号,并且要有数据值
def function(name, age): # 可以是任意数据值 print('这是一个有参函数') function('张三', 30) # 这是一个有参函数 function([1, 2], 'lisa') # 这是一个有参函数
函数的返回值
-
返回值就是调用函数之后产生的结果,可有可无,且获取函数返回值的方式是固定的,即变量名 = 函数名()
-
上述方式如果有则获取,没有则默认返回None
# 1.当函数体代码没有return关键字时:默认返回None def function(): print('这是一个没有return返回值的结果') info = function() # 先执行function函数体代码,然后将函数执行后的返回值赋值给变量名info print(info) # None # 2.当函数体代码没有return关键字时:后面不填写参数,也会返回None def function(): print('这是一个有return返回值的结果') return info = function() print(info) # None # 3.当函数体代码没有return关键字时:return后面写什么,就返回什么 def function(): print('这是一个有return返回值,并且后边跟了参数的结果') return 666 info = function() print(info) # 666 def function(): print('这是一个有return返回值,并且后边跟了参数的结果') # 如果return后面是一个变量名或者是函数名,就需要找到变量名绑定的对应值,然后返回数据 name = '张三' return name info = function() print(info) # 张三 # 4.当函数体代码有return关键字并且后面有多个数据值(名字)用逗号隔开时:默认情况下会自动组织成元组形式返回,也可以是列表,需要自己添加 def function(): return 11, 22, 33, 44, 55 info = function() print(info) # (11, 22, 33, 44, 55) def function(): return [11, 22, 33, 44, 55] info = function() print(info) # [11, 22, 33, 44, 55] def function(): return [11, 22, 33, 44, 55], {'name':'张三'}, 666 info = function() print(info) # ([11, 22, 33, 44, 55], {'name': '张三'}, 666) # 5.当函数体代码遇到return关键字会立刻结束函数体代码的运行,如果return后面有数据值,则返回数据值,这也类似于循环里的break def function(): print('how are you') return print('ok') function() # how are you
函数的参数
-
函数的参数有两大类:形式参数和实际参数
-
形式参数:函数在定义阶段括号内填写的参数,简称为形参
-
实际参数:函数在调用阶段括号内填写的参数,简称为实参
def function(info): # info就是function的形式参数 pass def function(info): # 777就是function的实际参数 pass function(777) -
形参与实参的关系
形参相当于是变量名,实参相当于是数据值,在函数调用阶段形参会与实参临时进行绑定,函数体代码运行结束以后,立刻解除关系
def function(info): # 动态绑定 print(info) function(777) # 777 function('李四') # 李四 function('666') # 666 function([11, 22, 33, 44, 55]) # 11, 22, 33, 44, 55 # 当函数在定义阶段的时候,形参info处于一个游离状态,当函数调用实参的时候,形参就会与实参临时进行绑定,函数体代码运行结束以后,形参与实参解绑,之后等待下一次的调用,在进行绑定,获取数据值,以此类推,形参可以和任意数据值进行绑定,给它什么它就输出什么!
位置参数
-
位置形参,在函数定义阶段括号内从左往右依次填写的变量名,称之为位置形参
-
给位置形参传值的时候个数必须一一对应,不能多也不能少
def function(name, age): # name, age就是位置形参 pass -
位置实参,在函数调用阶段括号内从左往右依次填写的数据值,称之为位置实参。
-
实参填写的可以是数据值,也可以是变量名
def function(name, age): print(name) # 老六 print(age) # 23 function('老六', 23) # 形参name对应实参老六 形参age对应实参23ef function(name, age): print(name) # boy print(age) # 23 gender = 'boy' function(gender, 23)
关键字参数
-
关键字实参,在函数调用阶段括号内以x=y的方式进行传值,称之为关键字实参
-
指名道姓的给形参传值,打破了位置的限制
-
位置实参必须在关键字形参的前面
-
无论是形参还是实参,都遵循一个传值顺序规律,那就是越短的越靠前,越长的越靠后
-
同一个形参在函数调用的时候只能绑定一个实参,不能同时接收多个实参
def function(x, y): print(x, y) function(x=666, y=777) # 666 777 def function(x, y): print(x, y) function(y=666, x=777) # 777 666 def function(x, y): print(x, y) function(777, y=666 ) # 777 666 def function(x, y): print(x, y) function(777, x=666 ) # 报错 TypeError: function() got multiple values for argument 'x'
默认值参数
-
默认值形参,在函数定义阶段括号内以什么等于什么的形式填写的形参称之为默认值形参
-
在函数定义阶段给形参绑定值,后续调用阶段就可以不用传值
-
调用阶段不传值使用默认值,传值就使用传了的值
-
默认值参数也遵循一个传值顺序规律,那就是越短的越靠前,越长的越靠后
def register(name, age, gender='male'): print(f""" ----------------student_info-------------- name:{name} age:{age} gender:{gender} ------------------------------------------ """) register('孙悟空', 999, ) register('猪八戒', 444, ) register('沙悟净', 333, ) register('李天王', 222, ) register('lisa', 18, 'girl') # ----------------student_info - ------------- # name: 孙悟空 # age: 999 # gender: male # ------------------------------------------ # # ----------------student_info - ------------- # name: 猪八戒 # age: 444 # gender: male # ------------------------------------------ # # ----------------student_info - ------------- # name: 沙悟净 # age: 333 # gender: male # ------------------------------------------ # # ----------------student_info - ------------- # name: 李天王 # age: 222 # gender: male # ------------------------------------------ # # ----------------student_info - ------------- # name: lisa # age: 18 # gender: girl # ------------------------------------------
可变长参数
- 可变长形参,可以打破形参与实参的个数限制,随意传值
- *在形参中的作用,接收多余的位置参数并组织成元组的形式赋值给*\后面的变量名
- **在形参中的作用,接收多余的关键字参数并组织成字典的形式赋值给**\后面的变量名
# 定义一个函数,无论接收多少位置实参,都可以执行
def function(*args):
print(args)
function() # ()
function(66) # (66,)
function(77, 88) # (77, 88)
# 定义一个函数,无论接收多少关键字实参,都可以执行
def function(**kwargs):
print(kwargs)
function() # {}
function(name='张三') # {'name': '张三'}
function(name='李四', age=20) # {'name': '李四', 'age': 20}
function(name='tony',age=22,hobby='running') # {'name': 'tony', 'age': 22, 'hobby': 'running'}
# 定义一个函数,无论怎么传值都可以执行,不管是位置实参还是关键字实参
def function(*args,**kwargs):
print(args,kwargs)
function() # () {}
function(22) # (22,) {}
function(11, 22) # (11, 22) {}
function(a=1) # () {'a': 1}
function(a=1, b=2) # () {'a': 1, 'b': 2}
function(1, 2, 3, a=1, b=2) # (1, 2, 3) {'a': 1, 'b': 2}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号