kaggle 入侵肾脏大赛
赛题任务 : 语义分割任务
赛题思路 : 构建深度学习语义分割模型完成
步骤1: 基本的语义分割模型 (FCN或UNet )、损失函数,跑通流程
步骤2 : 根据交又验证训练多个模型,完成模型结果集成
步骤3 : 对预测闻值进行搜索&可视化,改进损失函数&模型结构
步骤4 :寻找外部数据,构建预训练模型
步骤5 : 对测试集进行预测,进行伪标签训练
Epochs(周期): 一个 epoch 表示模型训练过程中,将训练数据集中的所有样本都用于训练一次的次数。训练一个神经网络模型通常需要多个 epoch,因为每个 epoch 都可以使模型逐步调整权重和参数,以更好地拟合训练数据。在每个 epoch 中,模型会对整个训练数据集进行前向传播、反向传播和参数更新。较小的 epoch 数可能导致模型欠拟合,而较大的 epoch 数可能导致过拟合。
Batch Size(批大小): Batch size 表示每次模型训练中使用的样本数量。在每个 epoch 中,训练数据集会被分割成多个大小为 batch size 的小批次(mini-batches)。模型的参数更新是根据每个小批次的损失函数来进行的,而不是在整个训练集上计算损失。通过使用小批次进行训练,可以加快训练过程,同时还可以利用硬件加速,如GPU的并行计算能力。较大的 batch size 可以利用硬件性能,但可能导致训练过程中的内存占用增加。
数据集( 训练集与验证集 )划分方法先切分到小尺寸,然后随机划分为训练集和验证集按照文件划分训练集和验证集,然后再切分
模型训练过程的细节:
模型网络结构 ( FCN 或 Unet,CNN网络结构 );
损失函数( Dice loss、 BCE loss )
数据切分过程
数据扩增方法
改进细节:
数据读取&数据扩增 :
按照文件读取,按照文件划分为训练集和验证集;
将没有mask的文件加入训练集
增加更强的数据扩增方法
测试集进行伪标签打标:当模型精度较高,当比赛规则允许,当模型为深度学习时
模型对测试进行预测,并将预测结果与训练集一起再训练
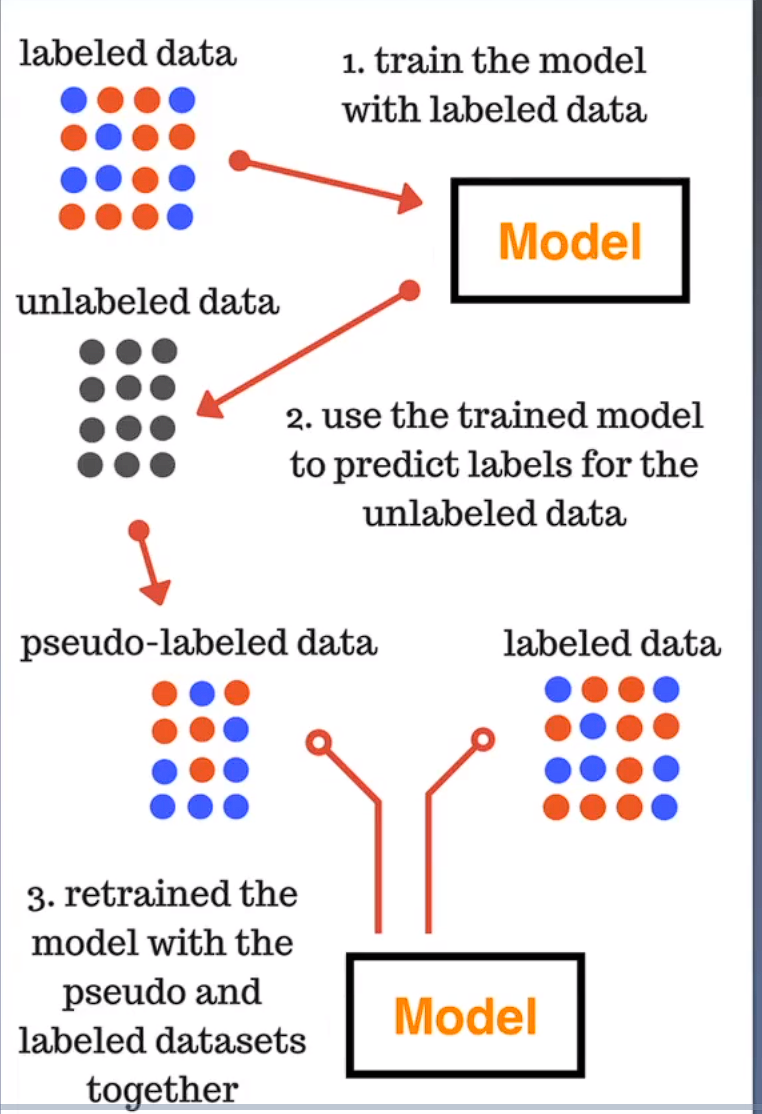
将数据存储为jipg,方便下次使用
网络模型 :
使用UNet代替FCN,并尝试EffecientNet作为网络结构C加入SPP网络结构
超参数:
Batch 和 Epoch
Batch : 不能太大,也不能太小,本场比赛8-32之间即可
Epoch : 设置有Val early stopping ,则不影响
Fold:4或者8
优化器:
优化器分类 :SGD、动量的优化器、权重衰减的优化器
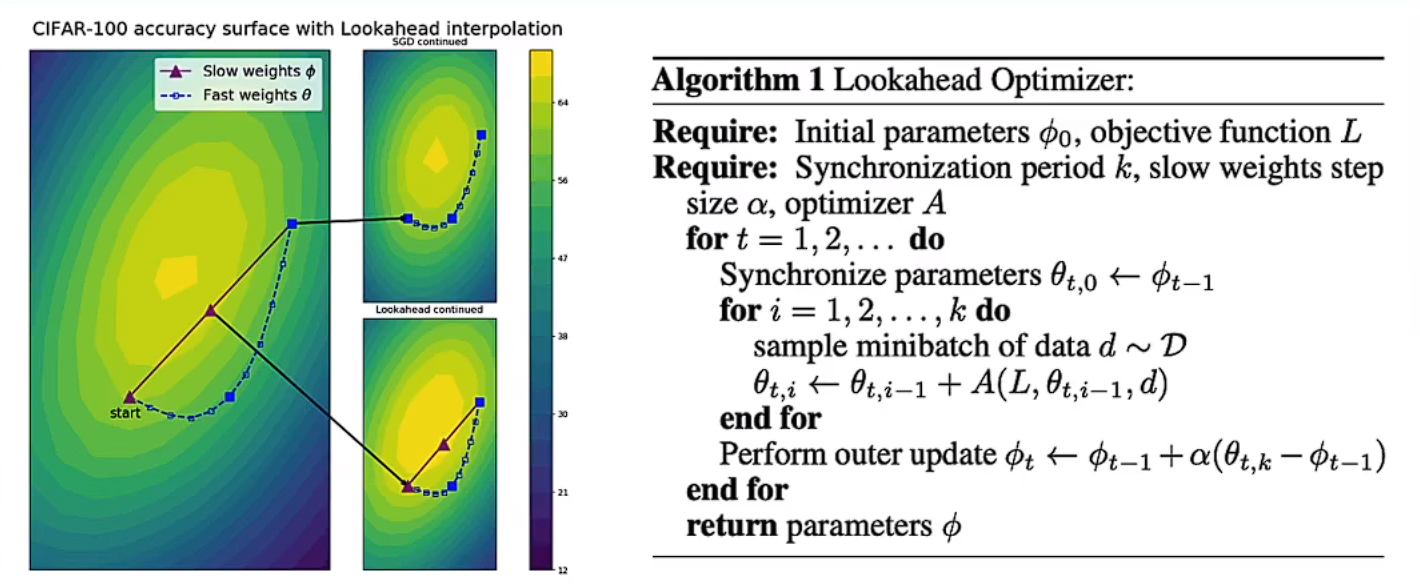
LookaHead优化器
学习率调整:
StepLR :间隔调整学习率 ;
MultistepLR : 按设定的间隔调整学习率 ;
ExponentialLR : 按指数衰减调整学习率
CosineAnnealingLR : 以余弦函数周期,在每个周期最大值时重置学习率
CosineAnnealingLR_warmup ;CosineAnnealingLR加上warmup
ReduceLROnPlateau : 当某指标不再变化( 下降或升高 ) ,调整学习率
参考:https://www.kaggle.com/code/isbhargav/guide-to-pytorch-learning-rate-scheduling/notebook#
训练与验证:
验证精度不能单张计算Dice score,整张图计算更为精确
Dice loss不适合加入训练,不平滑
Lovasz-Softmax loss
出发点 : IOU和Dice非常容易受到类别影响
具体原理 : 结合Lovasz hinge 和Jaccard loss 解决2值图片的分割问题
具体实现 : https://github.com/bermanmaxim/LovaszSoftmax
Focal Loss (kaggle中很少work)
出发点 :样本类别不均衡情况 ;
具体原理 :根据样本概率调节损失;
具体实现:https://www.kaggle.com/c/tgs-salt-identification-challenge/discussion/65938
OHEM (可能带来过拟合)
出发点 : 重点关注错误样本
具体原理 : 增加错误样本的loss,或将错误样本再训练 ;
具体实现:https://github.com/linbo0518/BLSeg/blob/master/blseg/loss.py
自动化调参:
网格、随机搜索
贝叶斯搜索:https:/towardsdatascience.com/automated-machine-learning-hyperparameter-tuning-in-python-dfda59b72f8a
自动化调参工具
NNl , https://github.com/Micrsoft/nni
ray , https://docs.ray.io/en/master/tune/index.html
但是上述工具不能代替人,在计算资源有限的情况下日志记录对比最有效
模型预测 :
多折模型集成精度收益 >单折TTA :
多折模型的预测闽值可以加入搜索过程
比赛进化路线
The Right way
构建比赛线下验证集,每个TIF是一折验证集(多模型集成) ;
闯值可视化与搜索函数
寻找合理的TIF拆分方法,到256、512和1024尺寸
寻找更加合适的损失函数和评价函数( 与线上一致 )
寻找更合理的模型结构
寻找更合适的结果集成方法
寻找外部数据,用于预训练
使用测试集完成伪标签训练,对公开测试集进行标注
推荐使用的数据扩增
翻转、旋转或平移;亮度改变、颜色改变;随机形变;随机图像缩小;
Hflip, VFlip, Equalize, CLAHE, RandomBrightnessContrast, RandomGammaShiftScaleRotate,GridDistortion,GaussNoise :
有些方法谨慎用 ( 但需要调参 ) : Mixup、CutMix ;
推荐使用的库
OpencV自己手写
Albumentations
参考方法:https://www.kaggle.com/parulpandey/overview-of-popular-image-augmentation-packages
常用python包
- Numba: Numba 是一个用于加速 Python 函数的 Just-In-Time(JIT)编译器。它通过将 Python 代码编译为机器码来提高执行速度,特别是在科学计算、数据分析和数值计算领域。你可以在需要高性能的函数上使用 Numba 的装饰器,使其运行速度更快。Numba 支持多核 CPU 和 GPU 并行计算。
- cv2 (OpenCV-Python): OpenCV-Python(cv2)是一个用于计算机视觉任务的开源计算机视觉库。它提供了许多图像处理、计算机视觉和计算机图形学相关的函数和工具,用于处理图像、视频、特征提取、对象检测等。OpenCV-Python 是处理图像和视频的首选工具,适用于许多应用领域,包括计算机视觉、图像处理、机器学习等。
- tqdm:
tqdm是一个用于在循环中显示进度条的库,它提供了简单易用的接口来监视迭代的进度。通过在循环中使用tqdm,你可以获得对进度的可视化表示,从而更方便地跟踪代码的执行进度。tqdm支持在终端或者 Jupyter Notebook 中显示进度条 -
rasterio是一个用于处理栅格数据(如卫星影像、遥感数据、DEM 等)的 Python 库。它提供了许多功能,帮助你读取、写入、操作和分析栅格数据,以及进行空间数据的处理和可视化。以下是一些rasterio的主要功能和用途
Deep Lab V1、V2、V3 ( 2014 ,2016 ,2017)
V1 : 使用空洞卷积扩大感受野,条件随机场细化边界;
V2 :加入多尺度下融合特征( Atrous Spatial Pyramid Pooling,ASPP)
V3:使用image-level feature代替CRF :
图像的伽马变换(Gamma Transformation)
是一种常用的图像增强技术,用于调整图像的亮度和对比度。伽马变换通过将图像的像素值映射到一个新的范围,以改变图像的感知明暗度。
伽马变换的公式为:
![]()
当 $\gamma > 1$ 时,伽马变换会增加图像的亮度,使得图像中的暗区域更亮,同时减少图像的对比度。当 $\gamma < 1$ 时,伽马变换会降低图像的亮度,使得图像中的亮区域更暗,同时增加图像的对比度。
在图像处理中,伽马变换可以用来处理不同照明条件下的图像,或者调整图像中亮暗细节的显示程度。伽马变换通常在非线性颜色空间中执行,但也可以在线性颜色空间中进行近似
model.eval() 是 PyTorch 中用于将模型设置为评估模式的方法。当你调用 model.eval() 时,模型的行为会发生变化,以适应评估阶段的需求。具体来说,以下是 model.eval() 的作用:
-
Batch Normalization 和 Dropout 的行为变化: 在训练模式下,
BatchNormalization和Dropout层会根据数据进行批归一化和随机丢弃一部分节点。但在评估模式下,BatchNormalization会使用移动平均的统计信息来进行归一化,而Dropout层则不会进行随机丢弃。 -
不会进行梯度计算: 在评估模式下,模型不会计算梯度,这有助于减少内存占用和加速计算。
-
影响模型的状态: 一些模型可能会在训练和评估模式下使用不同的逻辑。通过调用
model.eval(),你可以确保模型以正确的方式进行预测和推断
语义分割基础
像素精度 PA
平均交叉比 IOU
dice coefficient
分割模型
在自然场景下Mask-RCNN模型占优,在医学或简单场景下Unet占优
改进角度
骨干网络
空洞卷积
注意事项
并不是约复杂的模型越好,模型复杂度 与 数据任务难度需要匹配
一般情况下学习率、优化器不是精度瓶颈
模型训练模型训练可以先小尺寸 ,然后大尺寸finetune
损失函数可以组合 : BCE、Dice、Focal Loss和分类损失
如果有类别不均衡的情况,可以先分类再分割 ;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号