常用技巧
1. 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已
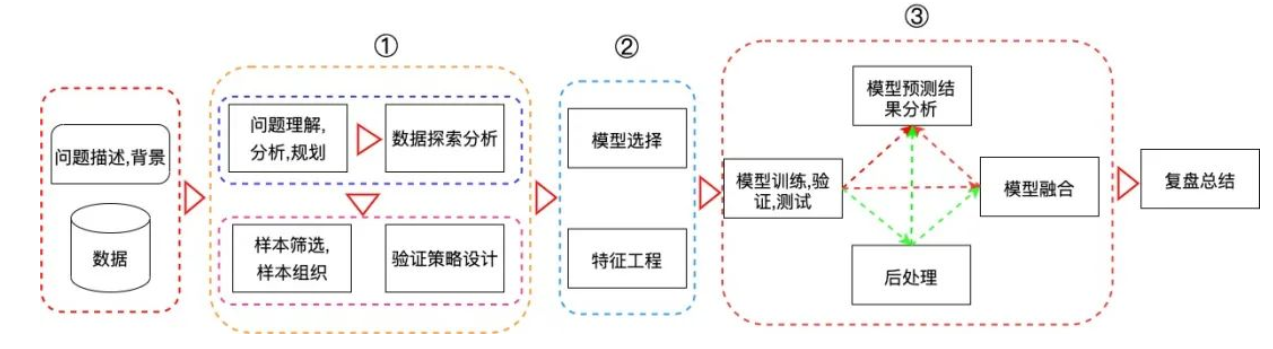
2. 对官方所给的数据进行细致的分析与探索,对于数据的探索与分析是为了能更好地理解数据,包括数据的整体情况、每个字段的含义、数据字段中是否存在奇怪的或错误的情况(例如某些特征字段中出现了大量的空值,身高体重等特征中出现了负数的情况等)、标签是否分布平衡、特征字段与标签的关系、训练集合与测试集合的数据分布是否存在较大的差异等。初期的特征探索与分析能帮助我们更好地理解数据,为后面的决策提供强有力的参考。
3. 所以是直接采用简单的五折交叉验证做线下验证,还是进行分组进行交叉验证亦或是按照时间顺序进行训练集和验证集合的划分?是我们在这一块需要重点思考的问题
4. Kaggle知识点:5种时序特征处理方法
a)理时序特征时,可以根据历史数据提取出工作日和周末信息
b)让模型决定哪个是最有价值的。训练线性回归模型,它将为滞后特征分配适当的权重(或系数)
c)根据过去的值计算一些统计值?这种方法称为滚动窗口方法
d)扩展窗口功能背后的想法是它考虑了所有过去的值。
Kaggle知识点:sklearn决策树、 api: DecisionTreeRegressor
决策树是一种用于分类和回归的监督学习方法。
决策树的一些缺点是:
- 深度太深,很容易过拟合
- 决策树可能不稳定
- 决策树的预测结果不是连续的
- 决策树节点分裂过程是贪心的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号