
ES 深度分页问题及其解决方案详解
ES 深度分页问题及其解决方案详解
1、简介
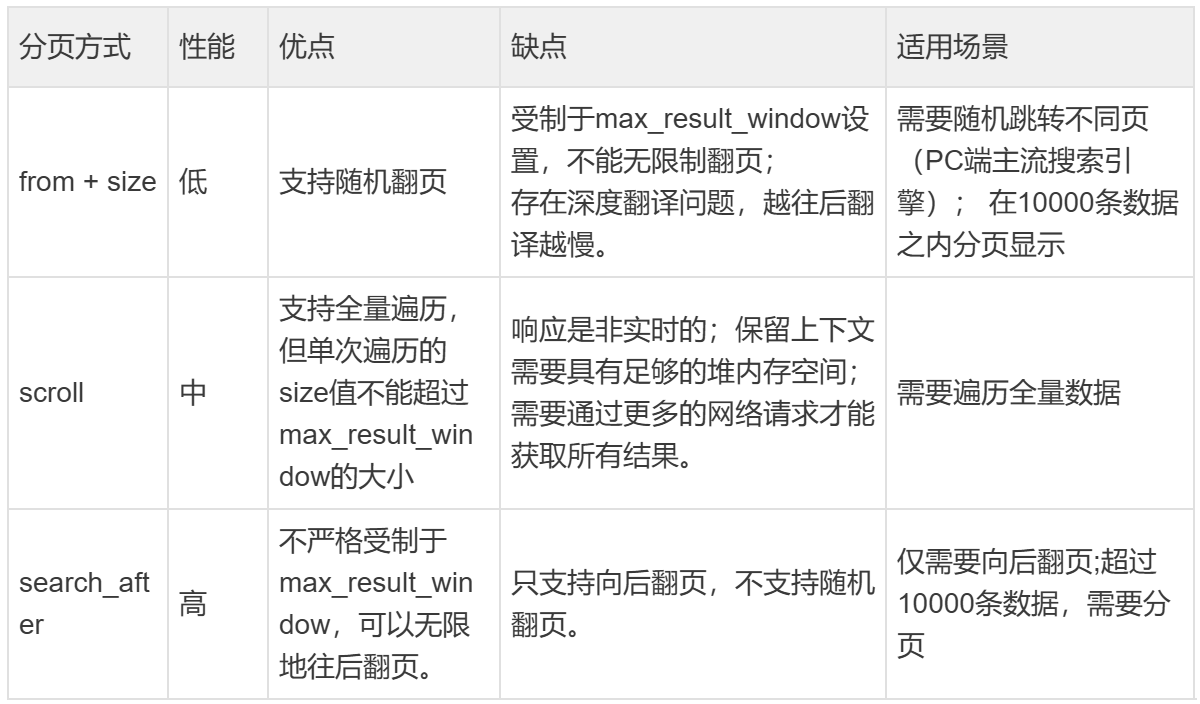
Elasticsearch(ES)的深度分页问题是指在数据量很大的情况下,使用from和size参数进行分页时,随着页码的增加,性能会急剧下降,甚至可能导致内存溢出。这是因为ES的分页原理导致的。
在ES中,当我们执行一个查询并指定from和size时,ES需要为每个分片创建一个大小为from+size的优先级队列,然后协调节点需要收集所有分片的结果,再全局排序,最后返回第from到from+size条结果。这意味着,当from值很大时,每个分片都需要构建一个很大的优先级队列,并且协调节点需要处理大量的数据,这会消耗大量的CPU、内存和网络资源。
例如,如果我们有10个分片,要获取第10000到10010条记录(即from=10000, size=10),那么每个分片都需要返回10010条记录给协调节点,然后协调节点对10*10010=100100条记录进行全局排序,最后返回10条记录。显然,这非常低效。
因此,ES默认限制最大只能查询10000条记录(通过index.max_result_window设置,默认10000)。如果超过这个限制,就需要使用其他解决方案。
2、解决方案
# 查询第一页5条数据 GET /employee/_search { "query": { "match_all": {} }, "from": 0, "size": 5 }

1、Scroll Search滚动查询
Scroll API(滚动查询)步骤:
-
发起一个滚动搜索请求,指定scroll参数(表示快照的保持时间)和size(每次滚动返回的文档数)。
-
从响应中获取scroll_id,然后使用scroll_id来获取下一批数据。
-
重复步骤2直到没有数据返回。
初始查询: POST /my_index/_search?scroll=1m { "size": 100, "query": { "match_all": {} } } 然后使用返回的_scroll_id来获取下一批数据: POST /_search/scroll { "scroll": "1m", "scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAA..." }
DELETE /_search/scroll { "scroll_id" : "FGluY2x1ZGVfY29udGV4dF91dWlkDXF1ZXJ5QW5kRmV0Y2gBFmNwcVdjblRxUzVhZXlicG9HeU02bWcAAAAAAABmzRY2YlV3Z0o5VVNTdWJobkE5Z3MtXzJB" }
scroll查询优点:支持全量遍历,是检索大量文档的重要方法,但单次遍历的size值不能超过max_result_window的大小。
scroll查询缺点:
- 响应是非实时的;
- 保留上下文需要具有足够的堆内存空间;
- 需要通过更多的网络请求才能获取所有结果。
2、search_after查询
Search After是一种基于上一页最后一行的排序值来检索下一页的方法,适用于实时滚动分页。它要求排序字段的值是唯一的(通常使用_id字段)。
查询步骤:
-
第一次查询需要指定排序字段(最好是一个唯一字段,如_id)和size。
-
从响应中获取最后一个文档的排序值,然后将这个值作为search_after参数进行下一次查询。
示例:
# 首次查询 GET /products/_search { "size": 10, "query": { "match_all": {} }, "sort": [ {"price": "asc"}, {"_id": "asc"} # 二级排序确保唯一性 ] } # 响应包含 sort 值 { "took": 15, "hits": { "hits": [ { "_id": "1", "_score": null, "_source": {...}, "sort": [100, "1"] # 排序字段值 }, ... ] } } # 下一页查询 GET /products/_search { "size": 10, "query": { "match_all": {} }, "sort": [ {"price": "asc"}, {"_id": "asc"} ], "search_after": [100, "1"] # 使用上一页最后一条的sort值 }
3、Point In Time + Search After(ES 7.10+)
PIT(Point in Time)为搜索创建一个时间点视图,确保在滚动过程中数据不会发生变化。PIT是Elasticsearch 7.10版本之后才有的新特性,实际上是存储索引数据状态的轻量级视图。
步骤:
-
创建一个PIT,指定索引和保持时间(默认5分钟)。
-
使用PIT的id进行搜索,结合Search After进行分页。
-
完成后删除PIT以释放资源。
示例:
# 1. 创建PIT(有效期5分钟) POST /products/_pit?keep_alive=5m # 响应 { "id": "46ToAwMDaWR5BXV1aWQyKwZub2RlXzMAAAAAAAAAACoBYwADaWR4BXV1aWQxAgZub2RlXzEAAAAAAAAAAAEBYQADaWR5BXV1aWQyKgZub2Rl
XzIAAAAAAAAAAAwBYgACBXV1aWQxAAAFdXVpZDIAAAt0ZXN0LWluZGV4AAA=" } # 2. 使用PIT进行Search After查询,设置了PIT,因此检索时候就不需要再指定索引
GET /_search { "size": 10, "query": { "match": { "title": "商品" } }, "pit": { "id": "上面的ID", "keep_alive": "5m" }, "sort": [ {"_shard_doc": "asc"} # ES内部排序,性能最优 ] } # 3. 后续查询携带search_after GET /_search { "size": 10, "query": {...}, "pit": {...}, "sort": [...], "search_after": [上次最后一条的sort值] } # 4. 删除PIT DELETE /_pit { "id": "PIT_ID" }
总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号