Elasticsearch中处理关联关系
1、简介
Elasticsearch 是一个分布式搜索和分析引擎,它本身并不像关系型数据库那样原生支持关联关系(如 joins)。然而,在实际应用中,我们经常需要处理一些关联数据。Elasticsearch 提供了几种方法来处理关联关系:
-
非规范化(Denormalization):将相关数据合并到一个文档中。这是 Elasticsearch 中最常用的方法,因为它利用了 Lucene 索引的特性,可以提高查询性能。例如,将订单和订单项放在一个文档中,而不是分开存储。
-
应用端关联(Application-side Joins):在应用程序中执行多次查询,然后将结果进行关联。例如,先查询主实体,再根据主实体的结果去查询关联实体。
-
嵌套类型(Nested):当需要索引对象数组并保持数组中每个对象的独立性时,可以使用嵌套类型。嵌套文档被索引为独立的隐藏文档,因此可以独立查询。但需要注意的是,嵌套查询和聚合可能会比较昂贵。
-
父子关联(Parent-Child):允许将一个索引中的文档定义为另一个索引中文档的子文档。父子关联可以处理一对多的关系,并且子文档可以独立更新。但是,父子关联查询性能较差,且内存消耗较大。
2、非规范化(Denormalization)
最常用、性能最优的方法。优点:查询速度快,单次查询获取所有数据,适合搜索场景。缺点:数据冗余,更新复杂,需要更新所有相关文档。需要注意的是这种直接存对象数组在查询时会有一定的问题。如下:
# 写入一条电影信息 POST /my_movies/_doc/1 { "title":"Speed", "actors":[ { "first_name":"李白", "last_name":"王维" }, { "first_name":"杜甫", "last_name":"唐伯虎" } ] }
查询
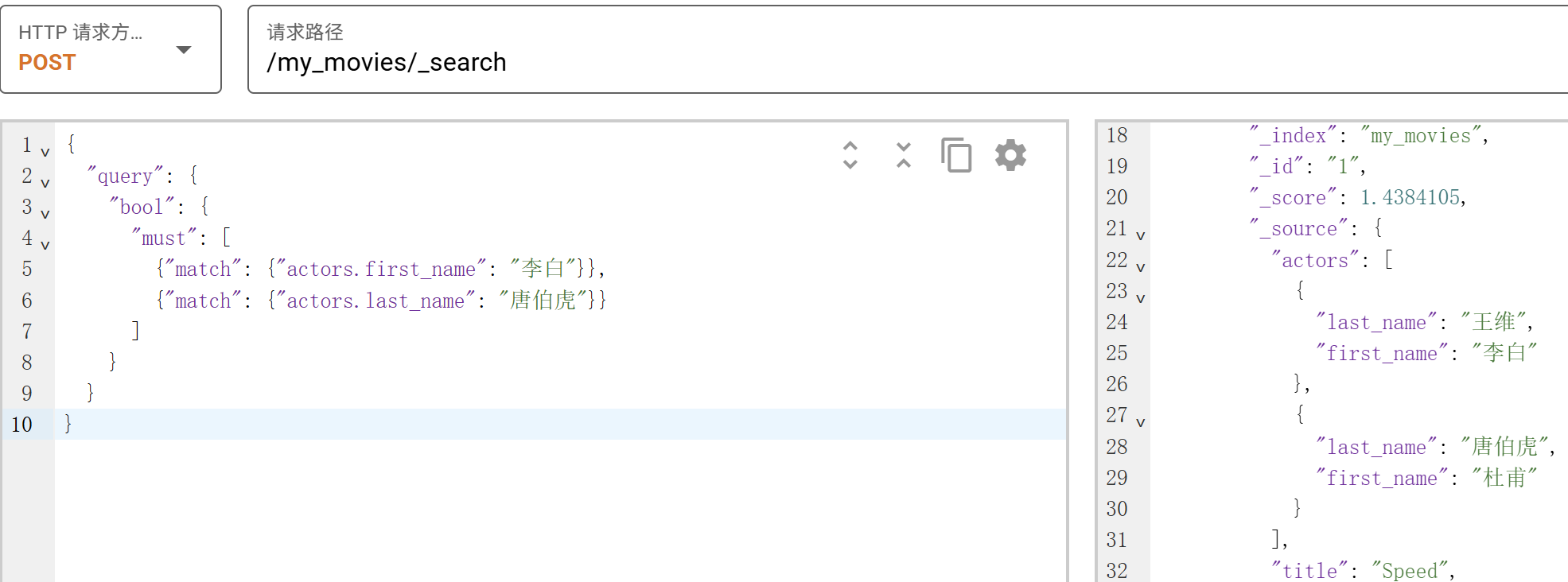
{ "actors.first_name": ["李白", "杜甫"], "actors.last_name": ["王维", "唐伯虎"] }
3、嵌套类型(Nested)
嵌套类型(nested type) 是一种特殊的字段类型,用于处理数组对象(array of objects)中各对象需要独立查询和聚合的场景。它解决了普通对象数组在内部扁平化存储导致的语义失真问题。

何时使用?
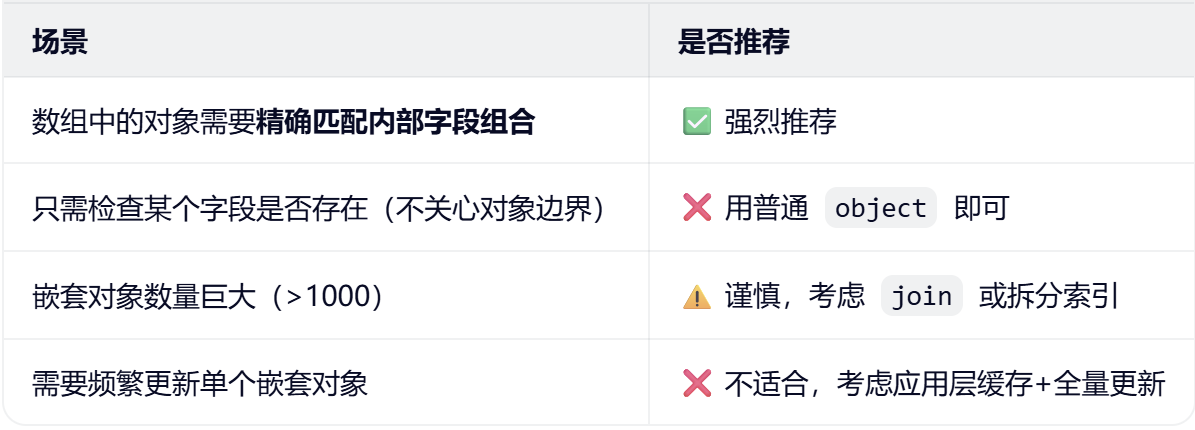
使用nested 和properties 关键字。用于处理一对多关系,保持子对象的独立性。
PUT /orders { "mappings": { "properties": { "items": { "type": "nested", "properties": { "product_id": { "type": "keyword" }, "quantity": { "type": "integer" } } } } } }
示例:一篇博客有多个评论
1、创建索引并插入数据
#################创建索引############################################# # 创建博客索引,comments字段为nested类型 PUT /blogs { "mappings": { "properties": { "title": { "type": "text" }, "author": { "type": "keyword" }, "comments": { "type": "nested", "properties": { "user": { "type": "keyword" }, "content": { "type": "text" }, "rating": { "type": "integer" } } } } } } ##############插入数据##################### # 插入一篇博客,包含多个评论 POST /blogs/_doc/1 { "title": "Elasticsearch入门教程", "author": "张三", "comments": [ { "user": "a1", "content": "很好的教程,学到了很多!", "rating": 5 }, { "user": "a2", "content": "期待更多高级用法", "rating": 4 } ] } # 插入第二篇博客 POST /blogs/_doc/2 { "title": "Python编程技巧", "author": "李四", "comments": [ { "user": "b1", "content": "实用技巧,感谢分享", "rating": 5 }, { "user": "b2", "content": "有些例子不太明白", "rating": 3 } ] } # 插入第三篇博客 POST /blogs/_doc/3 { "title": "Docker容器化部署", "author": "王五", "comments": [ { "user": "a1", "content": "部署变得简单多了", "rating": 5 }, { "user": "b2", "content": "文档写得很清晰", "rating": 4 }, { "user": "c3", "content": "第一次使用,感觉不错", "rating": 4 } ] }
2、查询更新聚合
###############查询############################################## 查询标题包含"入门"或者评论内容包含"教程"的博客(es默认使用stander分词器,一个单词分割,如果搜索中文推荐IK) GET /blogs/_search { "query": { "bool": { "should": [ { "match": { "title": "入门" } }, { "nested": { "path": "comments", "query": { "match": { "comments.content": "教程" } } } } ] } } } ##############嵌套数据的更新###################################################### 因为 nested 字段在内部被存储为独立的隐藏文档,与父文档关联。ES 无法单独更新这些子文档而不影响父文档结构,因此强制要求整体更新以保证数据一致性。 所以对于新增/修改/删除 comments这种嵌套类型时推荐使用客户端(如java) GET → 修改 → PUT(清晰、安全、易调试)。 #############嵌套数据的聚合操作########################## 统计每个author的平均rating GET /blogs/_search { "size": 0, "aggs": { "by_author": { "terms": { "field": "author", "size": 100 }, "aggs": { "comments_nested": { "nested": { "path": "comments" }, "aggs": { "avg_rating": { "avg": { "field": "comments.rating" } } } } } } } } // 返回值 { "took": 9, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 3, "relation": "eq" }, "max_score": null, "hits": [] }, "aggregations": { "by_author": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "张三", "doc_count": 1, "comments_nested": { "doc_count": 2, "avg_rating": { "value": 4.5 } } }, { "key": "李四", "doc_count": 1, "comments_nested": { "doc_count": 2, "avg_rating": { "value": 4 } } }, { "key": "王五", "doc_count": 1, "comments_nested": { "doc_count": 3, "avg_rating": { "value": 4.333333333333333 } } } ] } } }
4、父子关联(Parent-Child)
已弃用,不建议在新项目中使用。在 7.x 版本中标记为 deprecated。在 8.x 版本中移除。推荐使用 Join 字段替代。
5、Join 字段类型
对象和Nested对象的局限性: 每次更新,可能需要重新索引整个对象(包括根对象和嵌套对象)
ES提供了类似关系型数据库中Join 的实现。使用Join数据类型实现,可以通过维护Parent/ Child的关系,从而分离两个对象。
父文档和子文档是两个独立的文档,更新父文档无需重新索引子文档。子文档被添加,更新或者删除也不会影响到父文档和其他的子文档。
Join 字段类型允许在同一个索引中建立文档间的父子关系,一个索引只能有一个join字段。父子文档必须索引到同一个分片,因此索引子文档时必须指定routing(通常为父文档ID)。
替代父子关联的现代方案。在创建索引时,需要定义一个字段,其类型为join,并且通过relations定义父子关系。关系必须在索引创建时定义。
PUT /company { "mappings": { "properties": { "join_field": { // 定义关系字段名称 "type": "join", "relations": { "department": "employee" # "parent名称":"child名称"
# "department": ["employee", "manager"], // 一个父类型可以有多个子类型
# "project": "task" // 多个关系可以同时定义
}
}
}
}
}
下面还是以博客系统,一篇文章多个评论来进行演示
定义索引结构:
PUT /blogs_join { "mappings": { "properties": { // 博客字段(父文档) "title": { "type": "text" }, "author": { "type": "keyword" }, // 评论字段(子文档) "user": { "type": "keyword" }, "content": { "type": "text" }, "rating": { "type": "integer" }, // 👇 关键:定义 join 关系字段 "blog_comment": { "type": "join", "relations": { "blog": "comment" // blog 是父类型,comment 是子类型 } } } } }
- 所有字段都平铺在顶层;
- 通过
blog_comment.name区分文档是blog还是comment;
写入父文档(博客)数据
PUT /blogs_join/_doc/1 { "title": "Elasticsearch 入门教程", "author": "张三", "blog_comment": { "name": "blog" // 通过name指定前数据是父文档(blog) } }
写入子文档(评论)
?routing=1(等于父文档 _id)!确保数据在同一个分片上PUT /blogs_join/_doc/2?routing=1 { "user": "a1", "content": "很好的教程!", "rating": 5, "blog_comment": { "name": "comment", // 指定当前是子文档 "parent": "1" // 必须指定父文档的id } }
关联查询
Has Child 查询:查找有满足条件子文档的父文档
GET /blogs_join/_search { "query": { "has_child": { "type": "comment", "query": { "range": { "rating": { "gte": 4 } } }, "max_children": 10, "min_children": 1 } } }
Has Parent 查询:查找满足条件父文档的子文档
GET /blogs_join/_search { "query": { "has_parent": { "parent_type": "blog", "query": { "term": { "author": "张三" } } } } }
同时指定博客和评论查询条件
GET /blogs_join/_search { "query": { "bool": { "must": [ { "match": { "title": "Elasticsearch" } }, { "term": { "author": "张三" } }, { "has_child": { "type": "comment", "query": { "term": { "rating": 5 } } } } ] } } }
Parent ID 查询:直接通过父 ID 查子文档
GET /blogs_join/_search { "query": { "parent_id": { "type": "comment", "id": "1" } } }
聚合查询:按 author 统计平均 rating
GET /blogs_join/_search { "size": 0, "aggs": { "by_author": { "terms": { "field": "author", "size": 10 }, "aggs": { "comments": { "children": { "type": "comment" }, "aggs": { "avg_rating": { "avg": { "field": "rating" } } } } } } } }
更新删除评论(子文档)必须指定?routing
PUT /blogs_join/_doc/2?routing=1 { "user": "a1", "content": "已修改评论内容", "rating": 4, "blog_comment": { "name": "comment", "parent": "1" } }
关于inner_hits
inner_hits 是 Elasticsearch 中一个非常强大且常用的功能,主要用于在 嵌套查询(nested)或父子关联查询(join + has_child / has_parent) 中,
返回匹配的内部对象(子文档)的具体内容。

使用示例:
GET /blogs_join/_search { "query": { "has_child": { "type": "comment", "query": { "range": { "rating": { "gte": 4 } } }, "inner_hits": {} // 👈 启用 inner_hits } } }
高级配置
"inner_hits": { "name": "high_score_comments", // 自定义名称(避免冲突) "size": 5, // 返回最多5条匹配子文档 "from": 0, // 分页偏移 "_source": ["user", "rating"], // 只返回指定字段 "sort": [{ "rating": "desc" }], // 按评分排序 "highlight": { // 高亮匹配内容 "fields": { "content": {} } } }
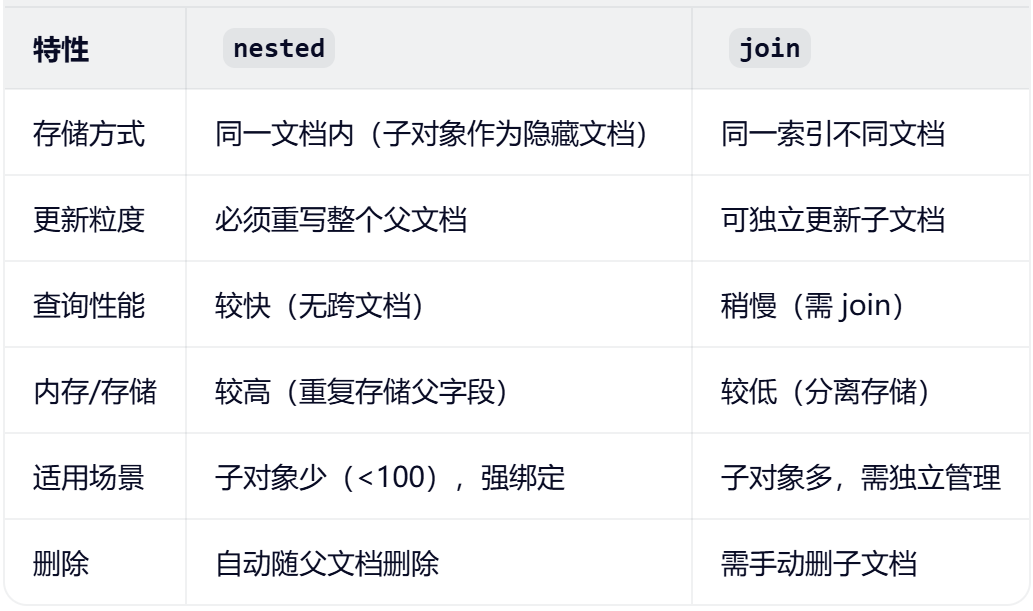
JOIN VS Nested
总结
在 Elasticsearch 中处理关联关系时,需要根据具体的业务场景选择合适的方法:
-
如果关联数据更新不频繁,且查询性能要求高,推荐使用非规范化的方式,将数据整合到一个文档中。
-
如果需要独立查询数组中的对象,可以使用嵌套类型。
-
如果关联数据更新频繁,且数据量较大,可以考虑使用父子关联,但要注意性能开销。
-
如果关联关系简单,且数据量不大,可以在应用端进行关联。
由于 Elasticsearch 的分布式特性,复杂的关联查询(如多表 join)通常不推荐使用,因为这样的查询往往性能很差。在设计 Elasticsearch 索引时,尽量采用非规范化的数据模型,将关联数据扁平化存储,以充分利用 Elasticsearch 的搜索能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号