
ElasticSearch基础数据管理-1-核心概念
1、什么是全文检索
全文检索(Full-Text Search)是一种从大量文本数据中快速检索出包含指定词汇或短语的信息的技术。它允许用户输入一个或多个关键词,然后系统会在预先建立好的索引中查找包含这些关键词的文档或文档片段,并返回给用户。
- 查询:有明确的搜索条件边界。比如,年龄 15~25 岁,颜色 = 红色,价格 < 3000,这里的 15、25、红色、3000 都是条件边界。即有明确的范围界定。
- 检索:即全文检索,无搜索条件边界,召回结果取决于相关性,其相关性计算无明确边界性条件,如同义词、谐音、别名、错别字、混淆词、网络热梗等均可成为其相关性判断依据。
2、全文检索实现原理
1、在全文检索中,首先需要对文本数据进行处理,包括分词、去除停用词等。然后,对处理后的文本数据建立索引,索引会记录每个单词在文档中的位置信息以及其他相关的元数据,如词频、权重等。这个过程通常使用倒排索引(inverted index)来实现,倒排索引将单词映射到包含该单词的文档列表中,以便快速定位相关文档。
2、当用户发起搜索请求时,搜索引擎会根据用户提供的关键词或短语,在建立好的索引中查找匹配的文档。搜索引擎会根据索引中的信息计算文档的相关性,并按照相关性排序返回搜索结果。用户可以通过不同的搜索策略和过滤条件来精确控制搜索结果的质量和范围。
3、什么是倒排索引
倒排索引是根据单词或短语建立的索引结构。它将每个单词映射到包含该单词的文档列表中。倒排索引的建立过程是先对文档进行分词处理,然后记录每个单词在哪些文档中出现,以及出现的位置信息。通过倒排索引,可以根据关键词或短语快速找到包含这些词语的文档,并确定它们的相关性。倒排索引适用于在大规模文本数据中进行关键词搜索和相关性排序的场景,它能够快速定位文档,提高搜索效率。
倒排索引的实现涉及到多个步骤:
- 文档预处理:对文档进行分词处理,移除停用词,并进行词干提取等操作。
- 构建词典:将处理后的词汇添加到词典中,并为每个词汇分配一个唯一的ID。
- 创建倒排列表:对于词典中的每个词汇,创建一个倒排列表,记录该词汇在哪些文档中出现,以及出现的位置信息。
- 存储索引文件:将词典和倒排列表存储在磁盘上的索引文件中,通常会进行压缩处理以减小存储空间并提升查询效率。
- 查询处理:当用户发起搜索请求时,搜索引擎会从词典中查找每个关键词对应的倒排列表,并根据列表中的文档ID快速定位到包含这些关键词的文档。
4、ElasticSearch常用术语
可以对比MySQL来理解Elasticsearch,如下图所示。左侧是MySQL的基本概念,右侧是Elasticsearch对应的相似概念的定义。借由这种对比,我们可以更直观地看出Elasticsearch与传统数据库之间的关系及差异。
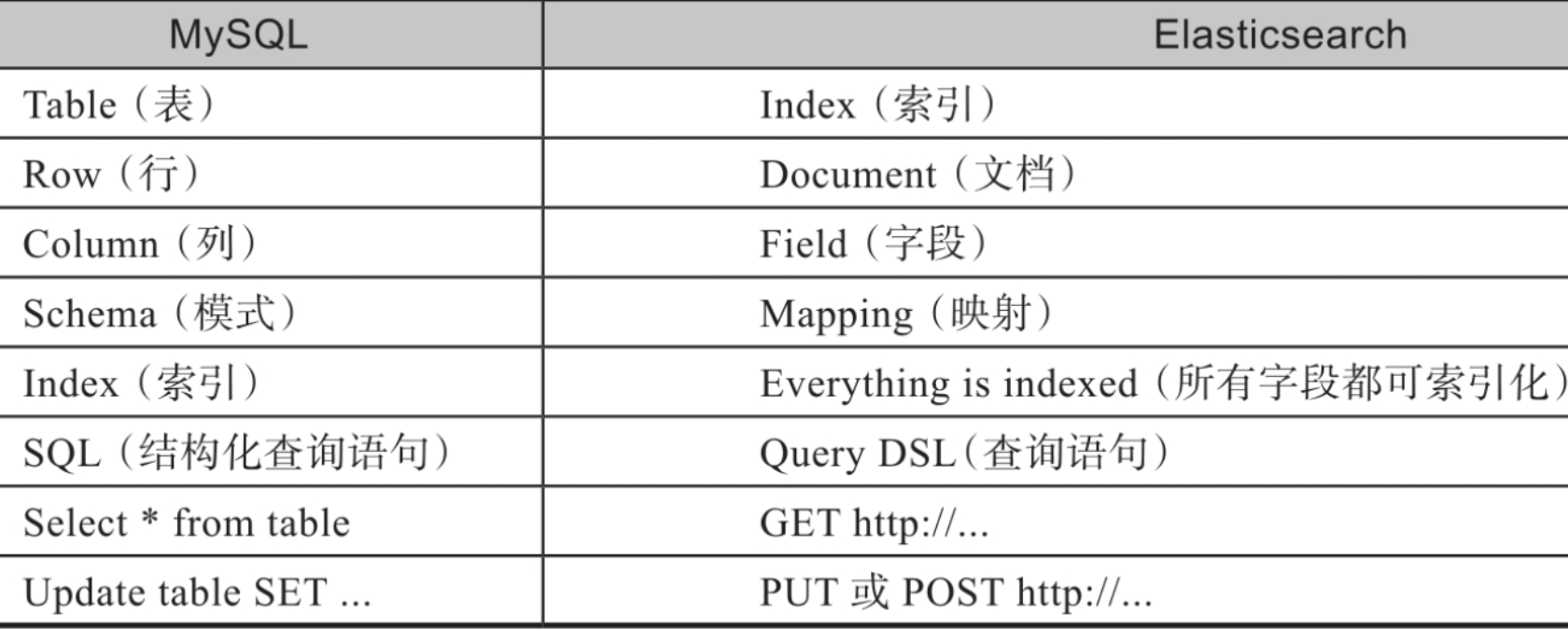
注意:在Elasticsearch 6.X之前的版本中,索引类似于SQL数据库,而type(类型)类似于表。然而,从ES 7.x版本开始,类型已经被弃用,一个索引只能包含一个文档类型。
索引
索引是Elasticsearch中用于存储和管理相关数据的逻辑容器。索引可以看作数据库中的一个表,它包含了一组具有相似结构的文档。在Elasticsearch中,数据以JSON格式的文档存储在索引内。每个索引具有唯一的名称,以便在执行搜索、更新和删除操作时进行引用。索引的名称可以由用户自定义,但必须全部小写。总之,索引是Elasticsearch中用于组织、存储和检索数据的一个核心概念。通过将数据划分为不同的索引,用户可以更有效地管理和查询相关数据。
映射
映射类似于关系型数据库中的Schema,可以近似地理解为“表结构”。
映射的定义如下所示:
PUT /employee { "mappings": { "properties": { "name": { "type": "keyword" }, "sex": { "type": "integer" }, "age": { "type": "integer" }, "address": { "type": "text", "analyzer": "ik_max_word" }, "remark": { "type": "text", "analyzer": "ik_smart" } } } }
文档
关系型数据库将数据以行或元组为单位存储在数据库表中,而Elasticsearch将数据以文档为单位存储在索引中。作为Elasticsearch的基本存储单元,文档是指存储在Elasticsearch索引中的JSON对象。文档中的数据由键值对构成。键是字段的名称,值是不同数据类型的字段。不同的数据类型包含但不限于字符串类型、数字类型、布尔类型、对象类型等。
{ "_index": "employee", "_id": "2", "_version": 1, "_seq_no": 1, "_primary_term": 1, "found": true, "_source": { "name": "李四", "sex": 1, "age": 28, "address": "广州荔湾大厦", "remark": "java assistant" } }
文档元数据,用于标注文档的相关信息:
- _index:文档所属的索引名
- _type:文档所属的类型名
- _id:文档唯一id
- _source: 文档的原始Json数据
- _version: 文档的版本号,修改删除操作_version都会自增1
- _seq_no: 和_version一样,一旦数据发生更改,数据也一直是累计的。Shard级别严格递增,保证后写入的Doc的_seq_no大于先写入的Doc的_seq_no。
- _primary_term: _primary_term主要是用来恢复数据时处理当多个文档的_seq_no一样时的冲突,避免Primary Shard上的写入被覆盖。每当Primary Shard发生重新分配时,比如重启,Primary选举等,_primary_term会递增1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号