
Mysql 面试题
1、问:MySQL选择InnoDB作为引擎,它有什么优势?
MySQL 默认的存储引擎是 InnoDB,这是因为 InnoDB 在性能、事务支持和容错能力等方面具有较好的特性,适合大多数应用场景。下面是一些原因:
- 支持事务:InnoDB 是一个支持事务的存储引擎。事务是一组数据库操作的原子性执行,可以保证操作的一致性和完整性。
- 并发控制:InnoDB 支持行级锁定, 在高并发环境下可以最大程度地减少锁冲突,提高并发性能。相比之下,MySQL 的另一个存储引擎 MyISAM 只支持表级锁定,并发性能较低。
- 外键约束:InnoDB 支持外键约束,可以保证数据的完整性。外键用于建立表与表之间的连接,通过外键约束可以实现数据之间的关联和参照完整性。
- 崩溃恢复:InnoDB 具有自动崩溃恢复的能力。即使在发生意外故障或系统崩溃时,InnoDB 引擎也能够自动进行崩溃恢复,保障数据的一致性。
- 支持热备份:InnoDB 支持在线热备份,可以在不停止数据库服务的情况下进行备份操作。这对于需要实时运行且对数据可用性要求高的应用程序非常重要。
需要注意的是,虽然 InnoDB 是 MySQL 默认的存储引擎,但在某些场景下,可以根据实际需求选择其他存储引擎,如 MyISAM、Memory 等。不同的存储引擎适用于不同的应用场景和需求。
2、问:小明公司的数据库用的MySQL 引擎是Innodb。小明创建了一张表,忘记给这张表添加主键,请问这边表有没有聚簇索引?如果有的话聚簇索引是什么样的?
聚簇索引创建的原则:
- 主键存在:如果表中定义了主键,主键即为聚簇索引。
- 没有主键时:如果没有定义主键,InnoDB 会选择第一个唯一且非空的索引作为聚簇索引。
- 既没有主键也没有唯一索引时:如果既没有主键也没有合适的唯一索引,InnoDB 会自动创建一个隐藏的6字节的行 ID (ROWID) 用作聚簇索引。这个是内部管理的,对用户不可见。
官网参考:https://dev.mysql.com/doc/refman/8.0/en/innodb-index-types.html
相关源码: https://github.com/mysql/mysql-server/blob/8.0/storage/innobase/handler/ha_innodb.cc
3、公司创建了一张订单表(mysql数据库),关于订单金额字段类型的设计争论不休, 依你之见应该使用什么类型呢?说说你的理由?
在 MySQL 中,记录货币值时一般使用的字段类型有:
1. DECIMAL 类型:
推荐使用:DECIMAL 类型是最适合存储货币数据的,因为它是一个定点数,有助于避免精度问题。
定义方法:通常用 `DECIMAL(M, D)` 来定义,其中 `M` 是总位数,`D` 是小数位数。例如,`DECIMAL(10, 2)` 可以储存最大值为 99999999.99 的货币数。
优点:提供高精度的数值存储,适合精确计算。
2. BIGINT 类型:
场景:在某些情况下,货币可以以最小单位存储(比如分或厘),然后使用 BIGINT 类型进行存储,这样可以避免浮点运算的问题。
优点:使用整数可以提高计算性能,避免小数精度问题。
实现方式:将货币值以最小单位进行存储,例如将 $10.23 存为 1023(以分为单位)。
3. FLOAT/DOUBLE 类型:
不推荐:这些浮点类型可能会由于精度问题导致金额计算不准确,因此不建议用于存储货币数据。
4、SQL场景实战问题
环境:Mysql V5.7.30 Innodb RR隔离级别(可重复读)。
t_user用户表如下:
CREATE TABLE t_user ( id int(10) NOT NULL, name varchar(100) DEFAULT NULL, PRIMARY KEY (id) ) ENGINE=InnoDB;
表里面的数据如下:
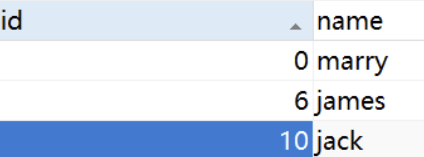
业务场景描述:

问题: 请问事务1 的第二次查询结果是什么?为什么?
答:4条数据。 事务2新增数据提交之后,事务1更新的当前读是可以操作成功,根据可见性规则:当前事务更新的数据对当前事务是可见的。所以事务1的第2个查询是可以看到id=20这条数据,再加上快照里面的3条数据,一共就是4条数据。
5、想清理一下这张订单表(mysql数据库)历史数据,请问这三种truncate、delete、drop方式哪种更好些?有什么区别吗?
truncate、delete、drop方式 在面试中问得很多,也是工作经常使用的SQL语句,他们的特性如下:
一、DELETE语句
特点:
- 1. 可以根据条件删除部分数据
- 2. 支持事务,可以回滚
- 3. 删除数据时会记录日志
- 4. 删除速度较慢
- 5. 不会释放表空间
- 6. 会一行一行地删除。
适用场景:
- 1. 需要删除部分数据
- 2. 需要保留删除记录
- 3. 需要事务支持
- 4. 表数据量不大
二、TRUNCATE语句
特点:
- 1. 删除速度快
- 2. 会释放表空间
- 3. 表的自增ID重置为1
- 4. 不能根据条件删除
- 5. 不支持事务回滚
- 6. 不记录日志
适用场景:
- 1. 需要删除全表数据
- 2. 需要重置自增ID
- 3. 对删除速度有要求
- 4. 不需要保留删除记录
三、DROP语句
特点:
- 1. 执行速度最快
- 2. 完全释放表空间
- 3. 删除表结构和索引
- 4. 删除整个表定义
- 5. 不支持事务回滚
- 6. 需要重建表结构
适用场景:
- 1. 需要删除整个表
- 2. 表结构需要重建
- 3. 不需要保留任何信息
【实用建议】
1. 如果只是想清理部分历史数据:
使用DELETE,可以指定条件。示例:DELETE FROM orders WHERE create_time < '2024-01-01';
2. 如果想清空整个表但保留表结构:
使用TRUNCATE,速度快且释放空间。示例:TRUNCATE TABLE orders;
3. 如果要完全废弃这个表:
使用DROP,删除整个表。示例:DROP TABLE orders;
【安全建议】
1. 执行删除操作前先备份数据
示例:CREATE TABLE orders_backup AS SELECT * FROM orders;
2. 对于大表删除,建议分批执行
示例:DELETE FROM orders WHERE create_time < '2024-01-01' LIMIT 10000;
3. 在业务低峰期执行删除操作
4. 删除前先确认是否有外键关联
【性能对比】
1. 执行速度:DROP > TRUNCATE > DELETE
2. 空间释放:DROP = TRUNCATE > DELETE
3. 安全性:DELETE > TRUNCATE > DROP
4. 灵活性:DELETE > TRUNCATE > DROP
【总结】
选择合适的删除方式主要取决于:
1. 是否需要保留表结构
2. 是否需要部分删除
3. 是否需要事务支持
4. 是否需要删除日志
5. 表的大小和业务影响
选择合适的删除方式可以大大提高效率,同时避免不必要的风险。在实际操作中,建议先在测试环境验证,确保操作安全无误后再在生产环境执行。
6、订单表3年积累了5000万条数据,需要删除1年前的历史订单(约3000万条),要求不影响线上业务,请说下你的方案?先不关注订单在业务上是否允许,生产上也有类似场景,比如一些日志表。重点关注方案设计。先分析这个场景:
- 数据量大(3000万条)
- 不能影响线上业务(不能长时间锁表)
- 需要保证数据安全
一般有以下几个方案,大家可以对比下:
方案1:直接DELETE(这个是不推荐的),主要的问题会有:
- 会产生巨大的锁,阻塞其他业务操作。
- 回滚日志(undo log)巨大,可能导致磁盘空间不足。
- 主从复制延迟严重。
- 执行时间可能数小时,期间数据库压力极大。
方案2:分批删除,可以按照主键分批删除,通过批处理或者存储过程实现。
这种方案的特点:每次只锁少量数据, 可以在业务低峰期分多批次多天执行,每个批次大小:5000-10000条(这个要根据自己项目的服务器性能调整)出问题可以随时停止对主从复制影响小。
方案3:先做归档后删除。这种方案数据可追溯,万一需要还能找回更安全,不用担心误删。但是需要需要额外存储空间,耗时也可能更长。
方案4:按时间分区表。这个需要提前做好设计,如果经常需要清理历史数据,建议改造成分区表。我们可以按照分区删除历史数据,性能快,不产生锁,也不影响其他分区查询。
所以推荐相对安全和完善的方案:提前做好数据备份+分批删除+业务低峰期执行+做好数据监控以及验证,有条件改造成分区表最好,另外记得做完这类大范围删除操作,要 OPTIMIZE TABLE 回收空间,减少内存碎片。
7、小明想使用模糊查询MySQL数据库的数据,根据业务场景前缀匹配和后缀匹配都可能用到, 请问这个模糊查询该如何优化?
在我们实际的开发过程可能碰到这类模糊匹配的场景,这个也是面试官非常喜欢问的面试题。模糊匹配使用不当就会导致全表扫描引发慢查询的问题。问题严重的甚至会导致系统崩溃。针对模糊匹配的优化方案,总结为以下五种,大家可以参考下:
1.针对前缀匹配
使用 name LIKE 'prefix%'的形式,这种情况只要name建了索引,或者说使用name前缀列的联合索引,一般还是会用到索引或者部分索引。
2. 使用后缀匹配使用反向索引
对于需要匹配后缀的情况(即LIKE '%suffix'),可以创建一个辅助列存储反转字符串,并基于此列进行前缀匹配。这个时候就和第一种方式类似了。
3. 限制扫描范围
在LIKE查询中,如果可以通过其他条件进一步缩小搜索范围,请尽量加入这些条件。
SELECT * FROM users WHERE created_at >= '2023-01-01' AND username LIKE 'John%';
4.使用全文索引
myISAM支持全文索引,Innodb 5.6之后也开始支持全文索引。所以针对这种情况处理方案:针对有这类搜索的业务单独使用myISAM就可以轻松解决;
如果版本在5.6之后,也可以使用Innodb创建全文索引,5.7.6之后甚至开始支持中文的全文索引。
查询时,使用 MATCH 关键字与 AGAINST 子句来指定搜索词。
SELECT * FROM articles WHERE MATCH (title, body) AGAINST ('search terms');
5. 使用搜索引擎类中间件
对于数据量非常庞大的业务量,比如亿级数据,可以使用外部全文搜索引擎如Elasticsearch、Solr等代替MySQL的LIKE操作。
8、面试官问他mysql查询的时候使用where 1=1会不会影响性能?你的答案是什么呢?说说你的看法。
很多小伙伴会在where后面跟上1=1的保证语,经常看网上的八股文说1=1会影响性能, 建议用Mybatis的<where>标签。两种方案,该如何选择?
- 如果 MySQL Server版本小于 5.7,用了 MyBatis的话,建议使用<where> 标签。
- 如果 MySQL版本大于等于 5.7,两个随便选;因为在MySQL5.7后,有一个所谓的(常量折叠优化)可以在编译期消除重言式表达式。什么是重言式表达式,就是任何时候永远都为true的结果, 就会被优化器识别并优化掉,好奇的话你可以通过show warnings;查看,就会发现1=1没有了。并且我也在一张100多万的表里面把1=1 和<where>标签分别做了100次查询, 耗时时间相差无几。 所以5.7后两种方式随便选。
当然现在 MySQL Server版本基本都是 5.7以上了,不是的话那赶紧升级吧。
9、MVCC的原理是什么?谈谈你的理解!(热点面试题)
关于MVCC的原理可以理解如下:
(1)undolog多版本链。MVCC通过为每行数据项维护多个版本来实现并发控制。当一个事务对数据进行修改时,它不会直接覆盖现有的数据,而是创建一个新的版本。这些不能数据版本形成了单向版本链
(2) readview视图。
readview组成:
- 当前活跃的事务ID数组(活跃是指未提交的事务)
- 最小事务m_ids
- 最大事务max_id
- 当前事务creator_trx_id
(3) readview创建时机
- START TRANSACTION WITH CONSISTENT SNAPSHOT; 立即创建快照
- Start Transaction 对于RR来说第一个select语句,对于RC来说每条select语句都会创建。
(4)可见性规则
- 版本的事务ID小于m_ids:该版本在Read View创建之前已经提交,因此对当前事务可见。
- 版本的事务ID大于max_id:该版本在Read View创建之后生成,因此对当前事务不可见。
- 版本的事务ID在m_ids和max_id之间:如果版本的事务ID不在活跃事务列表中,则该版本已经提交,对当前事务可见。如果版本的事务ID在活跃事务列表中,则该版本尚未提交,对当前事务不可见。
特别备注: 如果是当前事务creator_trx_id操作的数据,也是可见的!!
(5)当前读与快照读
- 快照读: 普通查询select语句属于快照读。
- 当前读: 删除更新类语句属于当前读,读的是数据库已经提交的数据。
(6)select数据是如何可见或者不可见的?
从undolog版本链的头部开始遍历,根据每个数据版本的事务ID,结合readview以及可见性的规则,来判定数据是否可见。
10、Mysql(Innodb引擎)加索引的时候会锁表吗?
关于这个问题从以下6个方面回答:
(1)参考答案:
MySQL加索引技术上不锁表,但实际使用中可能因MDL锁导致阻塞。
(2)技术层面分析:
从MySQL 5.6开始,创建和删除索引都支持Online DDL,意味着在索引操作过程中允许并发的DML操作(增删改查),不会对表进行锁定。这是通过INPLACE算法实现的,操作过程中不需要重建整个表。
(3)实际问题:
虽然支持Online DDL,但存在MDL(元数据锁)的影响。DDL操作分为三个阶段:
- 1.首先,在开始进行 DDL 时,需要拿到对应表的 MDL X 锁,然后进行一系列的准备工作;
- 2.然后将 MDL X 锁降级为 MDL S 锁,进行真正的 DDL 操作;
- 3.最后再次将 MDL S 锁升级为 MDL X 锁,完成 DDL 操作,释放 MDL 锁;
关键问题在于第一阶段和第三阶段需要排他锁。如果此时有长时间运行的查询占用了MDL共享锁,DDL操作就会被阻塞等待。更严重的是,由于写饥饿预防机制,后续的查询操作也会被阻塞,形成锁等待链。
(4)生产上的业务场景
当有长查询正在运行时,加索引操作会等待该查询完成。在等待期间,所有新的查询请求也会被阻塞,造成类似"锁表"的效果。
(5)版本差异
MySQL 8.0引入了INSTANT DDL,某些操作可以瞬间完成,进一步减少了锁定时间。但对于创建二级索引,仍然需要INPLACE算法。
(6)生产使用建议
生产环境中建议在业务低峰期执行索引操作,执行前检查是否有长时间运行的查询,可以设置合理的锁等待超时时间,并监控MDL锁的等待情况。
最后的结论:
MySQL加索引不会在技术层面锁表,但MDL锁机制可能导致实际的表访问阻塞,因此仍需谨慎操作。
11、一张表有500万数据,100多个字段,请问如何快速把数据查出来?
在处理大数据量和多字段的表时,优化查询性能是至关重要的。以下是一些策略,可以帮助你快速查询数据:
1. 选择必要的字段:
只选择你需要的字段,而不是使用`SELECT *`。这可以减少数据传输量和内存使用。
2. 使用索引:
- 确保查询条件中的列(如`WHERE`子句中的列)上有适当的索引。
- 使用覆盖索引(即索引包含所有查询的字段)可以避免回表查询。
3. 分页查询:
如果需要处理大量数据,考虑使用分页查询(如`LIMIT`和`OFFSET`)来分批获取数据。
注意:对于大偏移量的分页,`OFFSET`可能会导致性能问题,可以考虑使用“延续键”分页。
4. 优化查询条件:
- 使用高效的查询条件,避免在`WHERE`子句中使用函数或计算。
- 尽量使用等值查询而不是范围查询。
5. 数据库配置优化:
- 调整数据库配置参数,如`innodb_buffer_pool_size`,以便更好地利用内存。
- 确保数据库服务器有足够的内存和CPU资源。
6. 分区表:
对于非常大的表,可以考虑使用表分区,将数据按某个字段(如日期)分割成多个物理部分。
7. 缓存机制:
使用缓存机制(如Redis)来存储常用查询的结果,减少数据库的负载。
8. 分析执行计划:
使用`EXPLAIN`命令分析查询的执行计划,找出潜在的性能瓶颈。
9. 批量处理:
如果需要对大量数据进行批量处理,考虑使用批量操作而不是逐行处理。
通过结合这些策略,可以显著提高查询性能,尤其是在处理大数据量和多字段的复杂查询时。
12、假如今天不小心把数据库删了,领导让你把数据恢复出来,请问应该怎么做?
如果因为某些原因误删误删数据或者数据库,需要面对如何快速恢复问题。关于这个问题的解决总结如下:
一、恢复数据的方法:
(1) 误删数据表或数据库:
使用 `DROP TABLE`、`TRUNCATE TABLE` 或 `DROP DATABASE` 误删数据时,binlog 记录的是 statement 格式,可能不能通过 binlog 恢复。
恢复方法:依赖全量备份和增量日志。这个需要定期的全量备份和实时备份的 binlog。
(2) 误删数据行:
使用 `DELETE` 语句误删数据行,可以通过 Flashback或者美团闪回工具Myflash进行恢复数据。
13、多事务并发导入数据场景题
环境:Mysql V5.7.30 Innodb RR隔离级别
t_user用户表,表格如下:
CREATE TABLE t_user ( id int(10) NOT NULL, name varchar(100) DEFAULT NULL, PRIMARY KEY (id) ) ENGINE=InnoDB;
表里面的数据量:
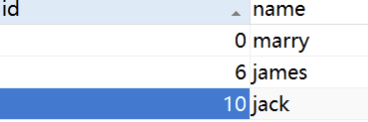
业务场景描述:

问题: 请问三个事务是否能够正常执行?说说你的理解。
事务执行的结果:
事务1正常执行 ,事务2,3形成死锁,有一个事务会被中止。
问题分析:
为什么会这样呢,我们首先要知道三个事务的执行流程就明白了怎么回事了。
(1)事务1给记录20 加X锁
(2)事务2 ,3 加X锁时发现记录20 被锁,由于主键的唯一性,事务2,3锁会降级为S锁
(3)事务1 回滚,事务2,3同时持有了记录20 S锁
(4) 同时事务2,3申请 插入的 IX锁,由于两个事务都是持有了S锁。我们知道IX和S锁不兼容的,所以两个事务相互等待,形成了死锁。
(5) 数据库发现死锁后,自动中止掉其中一个事务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号