
阻塞队列BlockingQueue实战及其原理分析
1、简介
对列:限定在一端进行插入,另一端进行删除的先进先出(FIFO)特殊线性表。 允许出队的一端称为队头,允许入队的一端称为队尾。
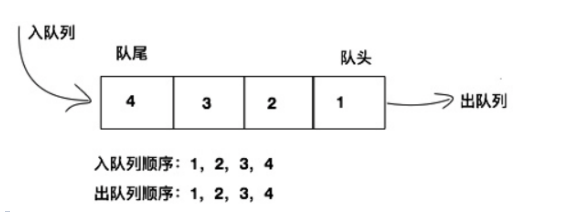
Queue接口
public interface Queue<E> extends Collection<E> {
//添加一个元素,添加成功返回true, 如果队列满了,就会抛出异常
boolean add(E e);
//添加一个元素,添加成功返回true, 如果队列满了,返回false
boolean offer(E e);
//返回并删除队首元素,队列为空则抛出异常
E remove();
//返回并删除队首元素,队列为空则返回null
E poll();
//返回队首元素,但不移除,队列为空则抛出异常
E element();
//获取队首元素,但不移除,队列为空则返回null
E peek();
}
2 、阻塞队列
阻塞队列 (BlockingQueue)是Java util.concurrent包下重要的数据结构,BlockingQueue提供了线程安 全的队列访问方式:当阻塞队列插入数据时,如果队列已满,线程将会阻塞等待直到队列非满;从阻 塞队列取数据时,如果队列已空,线程将会阻塞等待直到队列非空。并发包下很多高级同步类的实现 都是基于BlockingQueue实现的。
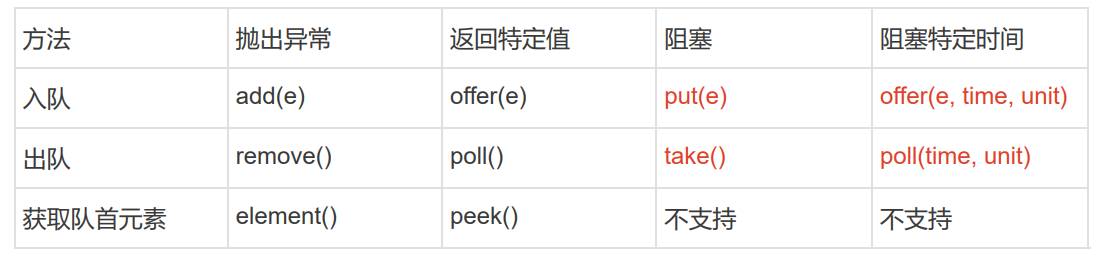
BlockingQueue接口
3、应用场景
阻塞队列在实际应用中有很多场景,以下是一些常见的应用场景:
1.线程池
线程池中的任务队列通常是一个阻塞队列。当任务数超过线程池的容量时,新提交的任务将被放入任务队列中等待执行。线程池中的工作线程从任务队列中取出任务进行处理,如果队列为空,则工作线程会被阻塞,直到队列中有新的任务被提交。
2.生产者-消费者模型
在生产者-消费者模型中,生产者向队列中添加元素,消费者从队列中取出元素进行处理。阻塞队列可以很好地解决生产者和消费者之间的并发问题,避免线程间的竞争和冲突。
3.消息队列
消息队列使用阻塞队列来存储消息,生产者将消息放入队列中,消费者从队列中取出消息进行处理。消息队列可以实现异步通信,提高系统的吞吐量和响应性能,同时还可以将不同的组件解耦,提高系统的可维护性和可扩展性。
4.缓存系统
缓存系统使用阻塞队列来存储缓存数据,当缓存数据被更新时,它会被放入队列中,其他线程可以从队列中取出最新的数据进行使用。使用阻塞队列可以避免并发更新缓存数据时的竞争和冲突
5.并发任务处理
在并发任务处理中,可以将待处理的任务放入阻塞队列中,多个工作线程可以从队列中取出任务进行处理。使用阻塞队列可以避免多个线程同时处理同一个任务的问题,并且可以将任务的提交和执行解耦,提高系统的可维护性和可扩展性。
4、JUC包下的阻塞队列
BlockingQueue 接口的实现类都被放在了 juc 包中,它们的区别主要体现在存储结构上或对元素操作上的不同,但是对于take与put操作的原理却是类似的。
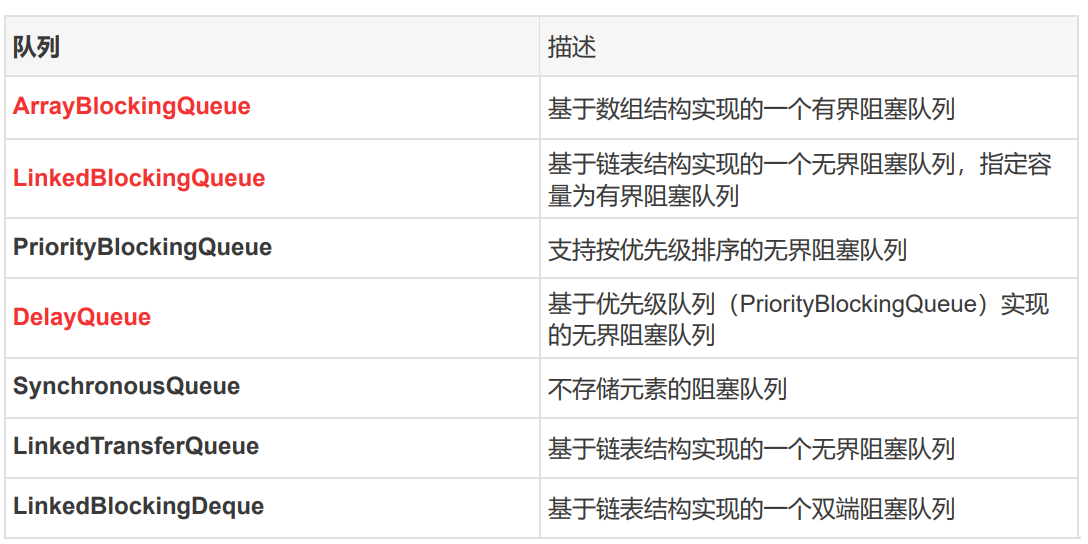
1、ArrayBlockingQueue
ArrayBlockingQueue是最典型的有界阻塞队列,其内部是用数组存储元素的,初始化时需要指定容量大小,利用 ReentrantLock 实现线程安全。ArrayBlockingQueue可以用于实现数据缓存、限流、 生产者-消费者模式等各种应用。 在生产者-消费者模型中使用时,如果生产速度和消费速度基本匹配的情况下,使用 ArrayBlockingQueue是个不错选择;当如果生产速度远远大于消费速度,则会导致队列填满,大量生产线程被阻塞。
实现原理:
ArrayBlockingQueue使用独占锁ReentrantLock实现线程安全,入队和出队操作使用同一个锁对象,也就是只能有一个线程可以进行入队或者出队操作;这也就意味着生产者和消费者无法并行操作,在高并发场景下会成为性能瓶颈。利用了Lock锁的Condition通知机制进行阻塞控制。
//数据元素数组 final Object[] items; //下一个待取出元素索引 int takeIndex; //下一个待添加元素索引 int putIndex; //元素个数 int count; //内部锁 final ReentrantLock lock; //消费者 private final Condition notEmpty; //生产者 private final Condition notFull; public ArrayBlockingQueue(int capacity) { this(capacity, false); } public ArrayBlockingQueue(int capacity, boolean fair) { ... lock = new ReentrantLock(fair); //公平,非公平 notEmpty = lock.newCondition(); notFull = lock.newCondition(); }
为什么ArrayBlockingQueue对数组操作要设计成双指针 ?
使用双指针的好处在于可以避免数组的复制操作。如果使用单指针,每次删除元素时需要将后面的元 素全部向前移动,这样会导致时间复杂度为 O(n)。而使用双指针,我们可以直接将 takeIndex 指向下 一个元素,而不需要将其前面的元素全部向前移动。同样地,插入新的元素时,我们可以直接将新元 素插入到 putIndex 所指向的位置,而不需要将其后面的元素全部向后移动。这样可以使得插入和删除 的时间复杂度都是 O(1) 级别,提高了队列的性能。
2、LinkedBlockingQueue
LinkedBlockingQueue是一个基于链表实现的阻塞队列,默认情况下,该阻塞队列的大小为 Integer.MAX_VALUE,由于这个数值特别大,所以 LinkedBlockingQueue 也被称作无界队列,代表它 几乎没有界限,队列可以随着元素的添加而动态增长,但是如果没有剩余内存,则队列将抛出OOM错误。所以为了避免队列过大造成机器负载或者内存爆满的情况出现,我们在使用的时候建议手动传一 个队列的大小。
LinkedBlockingQueue使用:
//指定队列的大小创建有界队列 BlockingQueue<Integer> boundedQueue = new LinkedBlockingQueue<>(100); // 无界队列 BlockingQueue<Integer> unboundedQueue = new LinkedBlockingQueue<>();
LinkedBlockingQueue原理
LinkedBlockingQueue内部由单链表实现,只能从head取元素,从tail添加元素。 LinkedBlockingQueue采用两把锁的锁分离技术实现入队出队互不阻塞,添加元素和获取元素都有独立的锁,也就是说LinkedBlockingQueue是读写分离的,读写操作可以并行执行。
3、SynchronousQueue
SynchronousQueue是一个没有数据缓冲的BlockingQueue,生产者线程对其的插入操作put必须等 待消费者的移除操作take。 SynchronousQueue 最大的不同之处在于,它的容量为 0,所以没有一个地方来暂存元 素,导致每次取数据都要先阻塞,直到有数据被放入;同理,每次放数据的时候也会阻塞,直到有消 费者来取。 需要注意的是,SynchronousQueue 的容量不是 1 而是 0,因为 SynchronousQueue 不需要去持 有元素,它所做的就是直接传递(direct handoff)。由于每当需要传递的时候,SynchronousQueue 会把元素直接从生产者传给消费者,在此期间并不需要做存储,所以如果运用得当,它的效率是很高 的。
需要注意的是,SynchronousQueue 的使用需要谨慎,因为它非常容易导致死锁,如果没有恰当地设 计和同步生产者和消费者线程,可能会造成程序无法继续执行。因此,在使用 SynchronousQueue 时 要注意线程同步和错误处理。
4、PriorityBlockingQueue
PriorityBlockingQueue是一个无界的基于数组的优先级阻塞队列,数组的默认长度是11,虽然指定了数 组的长度,但是可以无限的扩充,直到资源消耗尽为止,每次出队都返回优先级别最高的或者最低的元素。 默认情况下元素采用自然顺序升序排序,当然我们也可以通过构造函数来指定Comparator来对元素进 行排序。需要注意的是PriorityBlockingQueue不能保证同优先级元素的顺序。
优先级队列PriorityQueue: 队列中每个元素都有一个优先级,出队的时候,优先级最高的先出。
应用场景:
- 电商抢购活动,会员级别高的用户优先抢购到商品。
- 银行办理业务,vip客户插队 。
使用:
//创建优先级阻塞队列 Comparator为null,自然排序 PriorityBlockingQueue<Integer> queue=new PriorityBlockingQueue<Integer>(5); //自定义Comparator PriorityBlockingQueue queue=new PriorityBlockingQueue<Integer>( 5, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2-o1; } });
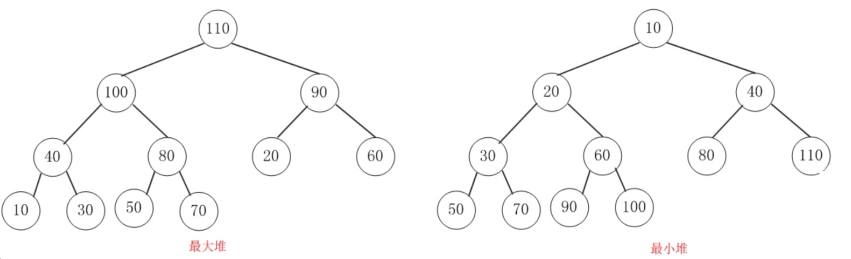
底层数据结构:二叉堆
完全二叉树:除了最后一行,其他行都满的二叉树,而且最后一行所有叶子节点都从左向右开始排 序。
二叉堆:完全二叉树的基础上,加以一定的条件约束的一种特殊的二叉树。根据约束条件的不同,二 叉堆又可以分为两个类型:
- 大顶堆(最大堆):父结点的键值总是大于或等于任何一个子节点的键值。
- 小顶堆(最小堆):父结点的键值总是小于或等于任何一个子节点的键值。
5、DelayQueue
DelayQueue 是一个支持延时获取元素的阻塞队列, 内部采用优先队列 PriorityQueue 存储元素, 同时元素必须实现 Delayed 接口;在创建元素时可以指定多久才可以从队列中获取当前元素,只有在 延迟期满时才能从队列中提取元素。延迟队列的特点是:不是先进先出,而是会按照延迟时间的长短 来排序,下一个即将执行的任务会排到队列的最前面。 它是无界队列,放入的元素必须实现 Delayed 接口,而 Delayed 接口又继承了 Comparable 接 口,所以自然就拥有了比较和排序的能力,代码如下:
public interface Delayed extends Comparable<Delayed> { //getDelay 方法返回的是“还剩下多长的延迟时间才会被执行”, //如果返回 0 或者负数则代表任务已过期。 //元素会根据延迟时间的长短被放到队列的不同位置,越靠近队列头代表越早过期。 long getDelay(TimeUnit unit); }
使用示例:DelayQueue 实现延迟订单
在实现一个延迟订单的场景中,我们可以定义一个 Order 类,其中包含订单的基本信息,例如订单编 号、订单金额、订单创建时间等。同时,我们可以让 Order 类实现 Delayed 接口,重写 getDelay 和 compareTo 方法。在 getDelay 方法中,我们可以计算订单的剩余延迟时间,而在 compareTo 方法 中,我们可以根据订单的延迟时间进行比较。
public class DelayQueueExample { public static void main(String[] args) throws InterruptedException { DelayQueue<Order> delayQueue = new DelayQueue<>(); // 添加三个订单,分别延迟 5 秒、2 秒和 3 秒 delayQueue.put(new Order("order1", System.currentTimeMillis(), 5000)); delayQueue.put(new Order("order2", System.currentTimeMillis(), 2000)); delayQueue.put(new Order("order3", System.currentTimeMillis(), 3000)); // 循环取出订单,直到所有订单都被处理完毕 while (!delayQueue.isEmpty()) { Order order = delayQueue.take(); System.out.println("处理订单:" + order.getOrderId()); } } static class Order implements Delayed { private String orderId; private long createTime; private long delayTime; public Order(String orderId, long createTime, long delayTime) { this.orderId = orderId; this.createTime = createTime; this.delayTime = delayTime; } public String getOrderId() { return orderId; } @Override public long getDelay(TimeUnit unit) { long diff = createTime + delayTime - System.currentTimeMillis(); return unit.convert(diff, TimeUnit.MILLISECONDS); } @Override public int compareTo(Delayed o) { long diff = this.getDelay(TimeUnit.MILLISECONDS) - o.getDelay(TimeUnit.MILLISECONDS); return Long.compare(diff, 0); } } }
DelayQueue实现原理:
数据结构:
//用于保证队列操作的线程安全 private final transient ReentrantLock lock = new ReentrantLock(); // 优先级队列,存储元素,用于保证延迟低的优先执行 private final PriorityQueue<E> q = new PriorityQueue<E>(); //用于标记当前是否有线程在排队(仅用于取元素时)leader指向的是第一个从队列获取元素阻塞的线程 private Thread leader = null; // 条件,用于表示现在是否有可取的元素 当新元素到达,或新线程可能需要成为leader时被通知 private final Condition available = lock.newCondition(); public DelayQueue() {} public DelayQueue(Collection<? extends E> c) { this.addAll(c); }
take() 方法源码分析
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { for (;;) { // 取出堆顶元素( 最早过期的元素,但是不弹出对象) E first = q.peek(); // 如果堆顶元素为空,说明队列中还没有元素,直接阻塞等待 if (first == null) // 当前线程无限期等待,直到被唤醒,并且释放锁。 available.await(); else { // 堆顶元素的到期时间 long delay = first.getDelay(NANOSECONDS); // 如果小于0说明已到期,直接调用poll()方法弹出堆顶元素 if (delay <= 0L) return q.poll(); first = null; // don't retain ref while waiting // 如果有线程争抢的Leader线程,则进行无限期等待 if (leader != null) available.await(); else { Thread thisThread = Thread.currentThread(); leader = thisThread; try { // 等待剩余等待时间 available.awaitNanos(delay); } finally { if (leader == thisThread) leader = null; } } } } } finally { if (leader == null && q.peek() != null) available.signal(); lock.unlock(); } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号