
JUC 包下并发容器实战与原理详解
1、简介
Java的集合容器框架中,主要有四大类别:List、Set、Queue、Map,大家熟知的这些集合类 ArrayList、LinkedList、HashMap这些容器都是非线程安全的。 所以,Java先提供了同步容器供用户使用。同步容器可以简单地理解为通过synchronized来实现同步的容器,比如Vector、Hashtable以及SynchronizedList等容器。这样做的代价是削弱了并发性,当多 个线程共同竞争容器级的锁时,吞吐量就会降低。
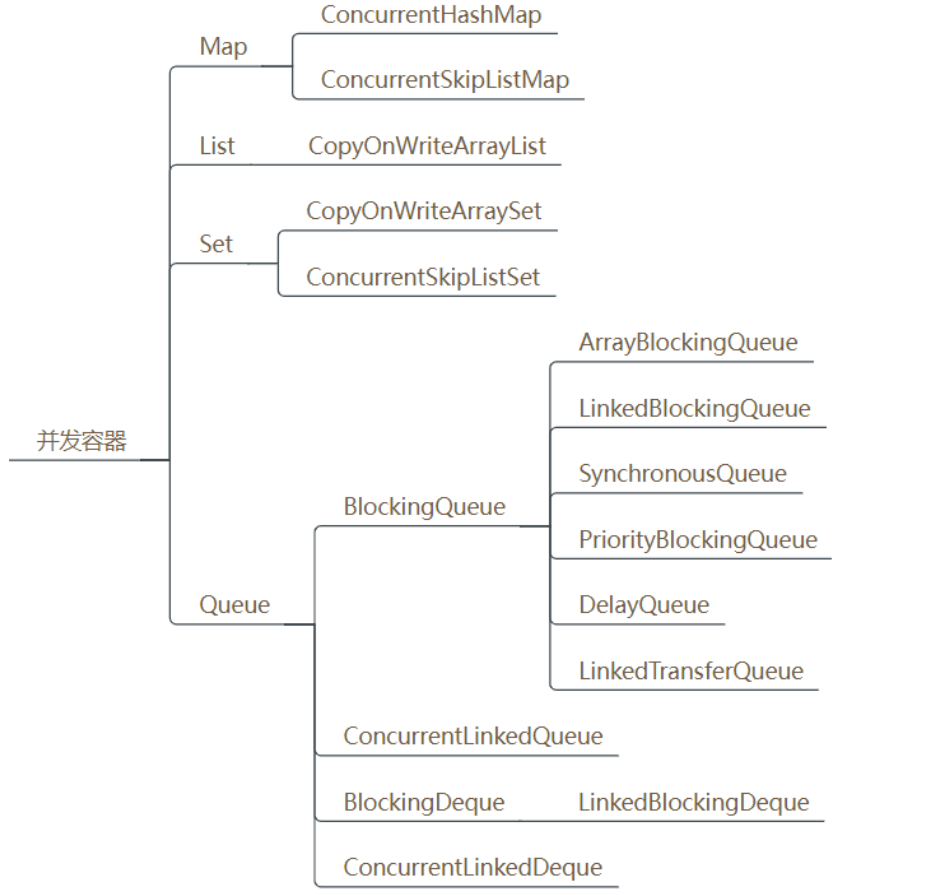
因此为了解决同步容器的性能问题,所以才有了并发容器。java.util.concurrent包中提供了多种并发类容器:
2、CopyOnWriteArrayList
CopyOnWriteArrayList 是 Java 中的一种线程安全的 List,它是一个可变的数组,支持并发读和写。它通过在修改操作时创建底层数组的副本来实现线程安全,从而保证了并发访问的一致性。
对应的非并发容器:ArrayList
目标:代替Vector、synchronizedList。
原理:利用高并发往往是读多写少的特性,对读操作不加锁,对写操作,先加锁,然后复制一份新的集合,在新的集合上面修改,然后将新集合赋值给旧的引用,最后解锁,并通过volatile 保证其可见性。
整体上来说,CopyOnWriteArrayList 就是利用锁 + 数组拷贝 + volatile 关键字保证了 List 的线程安全。
应用场景:
- 读多写少的场景 :由于 CopyOnWriteArrayList 的读操作不需要加锁,因此它非常适合在读多写少的场景中使用。
- 不需要实时更新的数据:读和写操作是分离得,读到得数据不一定是最新的。
缺点:
- 内存占用问题,毕竟每次执行写操作都要将原容器拷贝一份。数据量大时,对内存压力较大,可能会引起频繁 GC;
- 读可能不是实时读的最新数据。
3、CopyOnWriteArraySet
对应的非并发容器:HashSet 目标:代替synchronizedSet。
原理:基于CopyOnWriteArrayList实现,其唯一的不同是在add时调用的是CopyOnWriteArrayList的 addIfAbsent方法,其遍历当前Object数组,如Object数组中已有了当前元素,则直接返回,如果没有 则放入Object数组的尾部,并返回。
4、ConcurrentHashMap
ConcurrentHashMap 是 Java 中线程安全的哈希表,它支持高并发并且能够同时进行读写操作。 在JDK1.8之前,ConcurrentHashMap使用分段锁以在保证线程安全的同时获得更大的效率。JDK1.8开始舍弃了分段 锁,使用自旋 + CAS + synchronized关键字来实现同步。
对应的非并发容器:HashMap
目标:代替Hashtable、synchronizedMap,支持复合操作。
原理:JDK6中采用一种更加细粒度的加锁机制Segment“分段锁”,JDK8中采用CAS+synchronized算法。
应用场景:
- 共享数据的读写,可以使用 ConcurrentHashMap 保证线 程安全。
- 缓存:ConcurrentHashMap 的高并发性能和线程安全能力,使其成为一种很好的缓存实现方案。
常用复合操作API:
// 不存在再插入
V putlfAbsent(K key, V value)
// 计算新值,参数:key, BiFunction(k, v) -> 新值
compute(key, BiFunction)
// 不存在才计算并设置值,Function返回值作为key的值
computelfAbsent(key,Function);
// 存在才计算
computeIfPresent(key, BiFunction)
// 不存在指定的key时,将value设置为key的值。当key存在值时,执行BiFunction接收oldKey和value返回结果设置为key的值。
merge(key, value, BiFunction)
在jdk1.7中,HashMap结构是用Segments数组 + HashEntry数组 + 链表实现的 (写分散的思想)。 ConcurrentHashMap内部维护了一个Segment数组。每个Segment继承自ReentrantLock并且它内部本 质上是一个Hash表。这样做的好处是能够减小锁的粒度,提高并发访问的效率。默认Segment 数量为 16,可以通过构造函数来修改默认值。当需要put或get一个元素时,线程首先通过hash定位到具体的 Segment,然后在对应的Segment上进行锁定操作。
jdk1.8 抛弃了Segments分段锁的方案,而是改用了和HashMap一样的结构操作,也就是数组 + 链表 + 红黑树结构,比jdk1.7中的ConcurrentHashMap提高了效率,在并发方面,使用了cas + synchronized 的方式保证数据的一致性 。
链表转化为红黑树需要满足2个条件:
- 链表的节点数量>=树化阈值8。
- Node数组的长度大于等于最小树化容量值64。
- 红黑树节点数 ≤ 6 时退化为链表。

HashMap、Hashtable、ConccurentHashMap三者的区别
- HashMap线程不安全,数组+链表+红黑树
- Hashtable线程安全,锁住整个对象,数组+链表
- ConccurentHashMap线程安全,CAS+同步锁,数组+链表+红黑树
- HashMap的key,value均可为null,其他两个不行。
5、ConcurrentSkipListMap
ConcurrentSkipListMap 是 Java 中的一种线程安全、基于跳表实现的有序映射(Map)数据结构。它是对 TreeMap 的并发实现,支持高并发读写操作。 ConcurrentSkipListMap适用于需要高并发性能、支持有序性和区间查询的场景,能够有效地提高系统的性能和可扩展性。
跳表是一种基于有序链表的数据结构,它是一种概率型数据结构,通过随机概率决定节点高度。通过在有序链表上添加多级索引,实现对数级别的查找效率。

跳表的特性:
- 一个跳表结构由很多层数据结构组成。 每一层都是一个有序的链表,默认是升序。也可以自定义排序方法。
- 最底层链表(图中所示Level1)包含了所有的元素。
- 如果每一个元素出现在LevelN的链表中(N>1),那么这个元素必定在下层链表出现。
- 每一个节点都包含了两个指针,一个指向同一级链表中的下一个元素,一个指向下一层级别链表中的相同值元 素。
- 查找方式:从最高层开始,快速跳过大量节点。
对应的非并发容器:TreeMap
目标:代替synchronizedSortedMap(TreeMap)
原理:Skip list(跳表)是一种可以代替平衡树的数据结构,默认是按照Key值升序的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号