
RocketMQ 的消息模型
1、RocketMQ 主要有如下几种消息模型
- 广播消息
- 过虑消息
- 顺序消息机制
- 延迟消息
- 批量消息
- 事务消息
1、广播消息
应⽤场景: ⼴播模式和集群模式是RocketMQ的消费者端处理消息最基本的两种模式。集群模式下,⼀个消息,只会被⼀个消费者组中的多个消费者实例 共同 处理⼀次。⼴播模式下,⼀个消息,则会推送给所有消费者实例处理,不再关⼼消费者组。
消费者核⼼代码:
consumer.setMessageModel(MessageModel.BROADCASTING);
启动多个消费者,⼴播模式下,这些消费者都会消费⼀次消息。
实现思路:
默认模式(也就是集群模式)下,Broker端会给每个ConsumerGroup维护⼀个统⼀的Offset,这样,当Consumer来拉取消息时,就可以通过 Offset保证⼀个消息,在同⼀个ConsumerGroup内只会被消费⼀次。⽽⼴播模式的本质,是将Offset转移到Consumer端⾃⾏保管,包括Offset 的记录以及更新,全都放到客户端。这样Broker推送消息时,就不再管ConsumerGroup,只要Consumer来拉取消息,就返回对应的消息。
注意点:
- 1、Broker端不维护消费进度,意味着,如果消费者处理消息失败了,将⽆法进⾏消息重试。
- 2、Consumer端维护Offset的作⽤是可以在服务重启时,按照上⼀次消费的进度,处理后⾯没有消费过的消息。如果Offset丢了,Consuer依然 可以拉取消息。
⽐如⽣产者发送了1~10号消息。消费者当消费到第6个时宕机了。当他重启时,Broker端已经把第10个消息都推送完成了。如果消费者端维护好 了⾃⼰的Offset,那么他就可以在服务重启时,重新向Broker申请6号到10号的消息。但是,如果消费者端的Offset丢失了,消费者服务依然可 以正常运⾏,但是6到10号消息就⽆法再申请了。后续这个消费者就只能获取10号以后的消息。
2、过滤消息
应⽤场景: 同⼀个Topic下有多种不同的消息,消费者只希望关注某⼀类消息。 例如,某系统中给仓储系统分配⼀个Topic,在Topic下,会传递过来⼊库、出库等不同的消息,仓储系统的不同业务消费者就需要过滤出⾃⼰ 感兴趣的消息,进⾏不同的业务操作。
示例代码1:简单过滤 ⽣产者端需要在发送消息时,增加Tag属性。⽐如我们上⾯举例当中的⼊库、出库。核⼼代码:
String[] tags = new String[] {"TagA", "TagB", "TagC"};
for (int i = 0; i < 15; i++) {
Message msg = new Message("TagFilterTest",
tags[i % tags.length],
"Hello world".getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
}
消费者端就可以通过这个Tag属性订阅⾃⼰感兴趣的内容。核⼼代码:
consumer.subscribe("TagFilterTest", "TagA");
示例代码2:SQL过滤
通过Tag属性,只能进⾏简单的消息匹配。如果要进⾏更复杂的消息过滤,⽐如数字⽐较,模糊匹配等,就需要使⽤SQL过滤⽅式。SQL过滤⽅ 式可以通过Tag属性以及⽤户⾃定义的属性⼀起,以标准SQL的⽅式进⾏消息过滤。
⽣产者端在发送消息时,出了Tag属性外,还可以增加⾃定义属性。核⼼代码:
String[] tags = new String[] {"TagA", "TagB", "TagC"};
for (int i = 0; i < 15; i++) {
Message msg = new Message("SqlFilterTest",
tags[i % tags.length],
("Hello RocketMQ " + i).getBytes(RemotingHelper.DEFAULT_CHARSET)
);
msg.putUserProperty("a", String.valueOf(i));
SendResult sendResult = producer.send(msg);
System.out.printf("%s%n", sendResult);
}
消费者端在进⾏过滤时,可以指定⼀个标准的SQL语句,定制复杂的过滤规则。核⼼代码:
consumer.subscribe("SqlFilterTest",
MessageSelector.bySql("(TAGS is not null and TAGS in ('TagA', 'TagB'))" +
"and (a is not null and a between 0 and 3)"));
注意:如果需要使⽤⾃定义参数进⾏过滤,需要在Broker端,将参数enablePropertyFilter设置成true。这个参数默认是false。
Tag属性的处理⽐较简单,就是直接匹配。⽽SQL语句的处理会⽐较麻烦⼀点。RocketMQ也是通过ANLTR引擎来解析SQL语句,然后再进⾏消 息过滤的。ANLTR是⼀个开源的SQL语句解析框架。很多开源产品都在使⽤ANLTR来解析SQL语句。⽐如ShardingSphere,Flink等。
注意点:
1、使⽤Tag过滤时,如果希望匹配多个Tag,可以使⽤两个竖线(||)连接多个Tag值。另外,也可以使⽤星号(*)匹配所有。
2、使⽤SQL顾虑时,SQL语句是按照SQL92标准来执⾏的。SQL语句中⽀持⼀些常⻅的基本操作:
- 数值⽐较,⽐如:>,>=,<,<=,BETWEEN,=;
- 字符⽐较,⽐如:=,<>,IN; IS NULL 或者 IS NOT NULL;
- 逻辑符号 AND,OR,NOT;
3、消息过滤,其实在Broker端和在Consumer端都可以做。Consumer端也可以⾃⾏获取⽤户属性,不感兴趣的消息,直接返回不成功的状 态,跳过该消息就⾏了。但是RocketMQ会在Broker端完成过滤条件的判断,只将Consumer感兴趣的消息推送给Consumer。这样的好处是减 少了不必要的⽹络IO,但是缺点是加⼤了服务端的压⼒。不过在RocketMQ的良好设计下,更建议使⽤消息过滤机制。
4、Consumer不感兴趣的消息并不表示直接丢弃。通常是需要在同⼀个消费者组,定制另外的消费者实例,消费那些剩下的消息。但是,如果 ⼀直没有另外的Consumer,那么,Broker端还是会推进Offset。
3、顺序消息机制
应⽤场景:
每⼀个订单有从下单、锁库存、⽀付、下物流等⼏个业务步骤。每个业务步骤都由⼀个消息⽣产者通知给下游服务。如何保证对每个订单的业 务处理顺序不乱?
⽣产者核⼼代码:
for (int i = 0; i < 10; i++) {
int orderId = i;
for(int j = 0 ; j <= 5 ; j ++){
Message msg =
new Message("OrderTopicTest", "order_"+orderId, "KEY" + orderId,
("order_"+orderId+" step " + j).getBytes(RemotingHelper.DEFAULT_CHARSET));
SendResult sendResult = producer.send(msg, new MessageQueueSelector() {
@Override
public MessageQueue select(List<MessageQueue> mqs, Message msg, Object arg) {
Integer id = (Integer) arg;
int index = id % mqs.size();
return mqs.get(index);
}
}, orderId);
System.out.printf("%s%n", sendResult);
}
}
通过MessageSelector,将orderId相同的消息,都转发到同⼀个MessageQueue中。
消费者核⼼代码:
consumer.registerMessageListener(new MessageListenerOrderly() {
@Override
public ConsumeOrderlyStatus consumeMessage(List<MessageExt> msgs, ConsumeOrderlyContext context) {
context.setAutoCommit(true);
for(MessageExt msg:msgs){
System.out.println("收到消息内容 "+new String(msg.getBody()));
}
return ConsumeOrderlyStatus.SUCCESS;
}
});
注⼊⼀个MessageListenerOrderly实现。
实现思路: RocketMQ实现消息顺序消费,是需要⽣产者和消费者配合才能实现的。
- 1、⽣产者只有将⼀批有顺序要求的消息,放到同⼀个MesasgeQueue上,通过MessageQueue的FIFO特性保证这⼀批消息的顺序。 如果不指定MessageSelector对象,那么⽣产者会采⽤轮询的⽅式将多条消息依次发送到不同的MessageQueue上。
- 2、消费者需要实现MessageListenerOrderly接⼝,实际上在服务端,处理MessageListenerOrderly时,会给⼀个MessageQueue加锁,拿到 MessageQueue上所有的消息,然后再去读取下⼀个MessageQueue的消息。
注意点:
- 1、理解局部有序与全局有序。⼤部分业务场景下,我们需要的其实是局部有序。如果要保持全局有序,那就只保留⼀个MessageQueue。性能 显然⾮常低。
- 2、⽣产者端尽可能将有序消息打散到不同的MessageQueue上,避免过于集中导致数据热点竞争。
- 3、消费者端只进⾏有限次数的重试。如果⼀条消息处理失败,RocketMQ会将后续消息阻塞住,让消费者进⾏重试。但是,如果消费者⼀直处 理失败,超过最⼤重试次数,那么RocketMQ就会跳过这⼀条消息,处理后⾯的消息,这会造成消息乱序。
- 4、消费者端如果确实处理逻辑中出现问题,不建议抛出异常,可以返回ConsumeOrderlyStatus.SUSPEND_CURRENT_QUEUE_A_MOMENT 作为替代。
4、延迟消息
应⽤场景:
延迟消息发送是指消息发送到Apache RocketMQ后,并不期望⽴⻢投递这条消息,⽽是延迟⼀定时间后才投递到Consumer进⾏消费。
核⼼⽅法: 当前版本RocketMQ提供了两种实现延迟消息的机制,⼀种是指定固定的延迟级别,⼀种是指定消息发送时间(RocketMQ 5.0版本才支持)。
⽣产者端核⼼代码:
// 指定固定的延迟级别
Message message = new Message(TOPIC, ("Hello scheduled message " + i).getBytes(StandardCharsets.UTF_8));
message.setDelayTimeLevel(3); //10秒之后发送
// 指定消息发送时间
Message message = new Message(TOPIC, ("Hello scheduled message " + i).getBytes(StandardCharsets.UTF_8));
message.setDeliverTimeMs(System.currentTimeMillis() + 10_000L); //指定10秒之后的时间点
关于延迟级别,RocketMQ给消息定制了18个默认的延迟级别

实现思路:
对于指定固定延迟级别的延迟消息,RocketMQ的实现⽅式是预设⼀个系统Topic,名字叫做SCHEDULE_TOPIC_XXXXX。在这个Topic下,预 设了18个MessageQueue。这⾥每个对列就对应了⼀种延迟级别。然后每次扫描这18个队列⾥的消息,进⾏延迟操作就可以了。
另外指定时间点的延迟消息,RocketMQ是通过时间轮算法实现的。
5、批量消息
应⽤场景:
⽣产者要发送的消息⽐较多时,可以将多条消息合并成⼀个批量消息,⼀次性发送出去。这样可以减少⽹络IO,提升消息发送的吞吐量。
⽣产者核⼼代码:
List<Message> messages = new ArrayList<>(MESSAGE_COUNT);
for (int i = 0; i < MESSAGE_COUNT; i++) {
messages.add(new Message(TOPIC, TAG, "OrderID" + i, ("Hello world " +
i).getBytes(StandardCharsets.UTF_8)));
}
//split the large batch into small ones:
ListSplitter splitter = new ListSplitter(messages);
while (splitter.hasNext()) {
List<Message> listItem = splitter.next();
SendResult sendResult = producer.send(listItem);
System.out.printf("%s", sendResult);
}
注意点:
批量消息的使⽤⾮常简单,但是要注意RocketMQ做了限制。同⼀批消息的Topic必须相同,另外,不⽀持延迟消息。 还有批量消息的⼤⼩不要超过1M,如果太⼤就需要⾃⾏分割。
6、事务消息
应⽤场景:
事务消息是RocketMQ⾮常有特⾊的⼀个⾼级功能。他的基础诉求是通过RocketMQ的事务机制,来保证上下游的数据⼀致性。 以电商为例,⽤户⽀付订单这⼀核⼼操作的同时会涉及到下游物流发货、积分变更、购物⻋状态清空等多个⼦系统的变更。这种场景,⾮常适 合使⽤RocketMQ的解耦功能来进⾏串联。
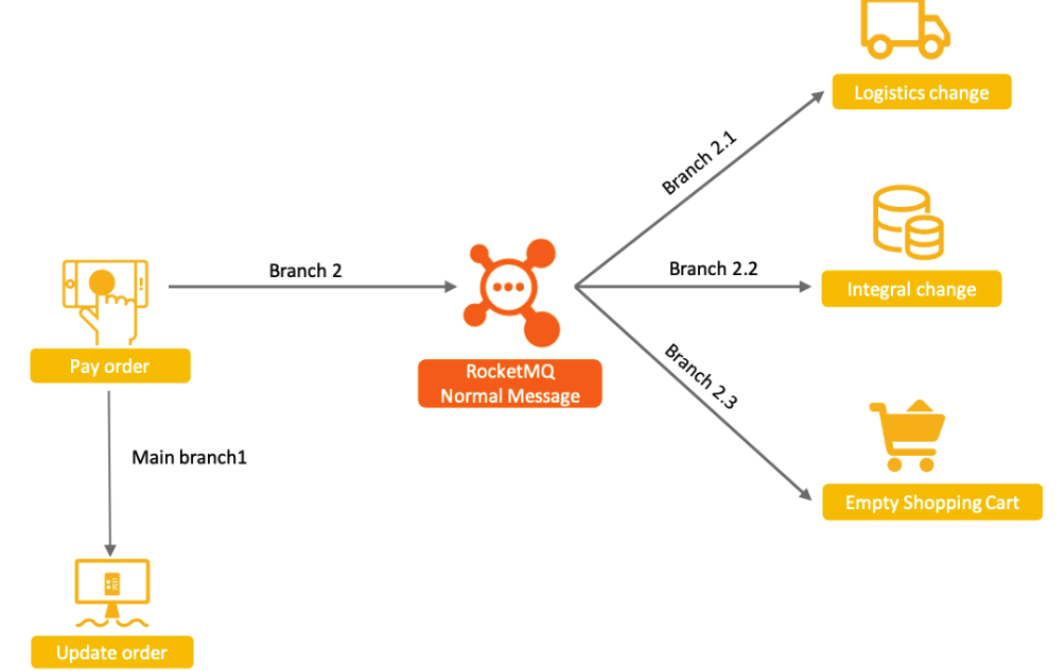
考虑到事务的安全性,即要保证相关联的这⼏个业务⼀定是同时成功或者同时失败的。如果要将四个服务⼀起作为⼀个分布式事务来控制,可 以做到,但是会⾮常麻烦。⽽使⽤RocketMQ在中间串联了之后,事情可以得到⼀定程度的简化。由于RocketMQ与消费者端有失败重试机制, 所以,只要消息成功发送到RocketMQ了,那么可以认为Branch2.1,Branch2.2,Branch2.3这⼏个分⽀步骤,是可以保证最终的数据⼀致性 的。这样,⼀个复杂的分布式事务问题,就变成了MinBranch1和Branch2两个步骤的分布式事务问题。
然后,在此基础上,RocketMQ提出了事务消息机制,采⽤两阶段提交的思路,保证Main Branch1和Branch2之间的事务⼀致性。
具体的实现思路是这样的:
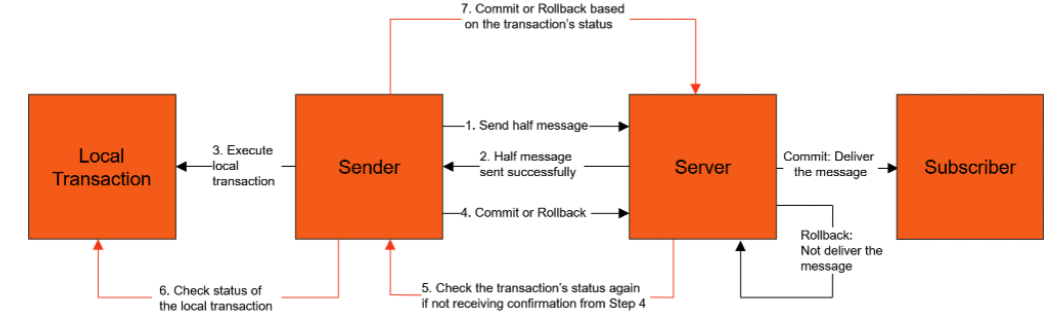
1、⽣产者将消息发送⾄Apache RocketMQ服务端。
2、Apache RocketMQ服务端将消息持久化成功之后,向⽣产者返回Ack确认消息已经发送成功,此时消息被标记为"暂不能投递",这种状态下 的消息即为半事务消息。
3、⽣产者开始执⾏本地事务逻辑。
4、⽣产者根据本地事务执⾏结果向服务端提交⼆次确认结果(Commit或是Rollback),服务端收到确认结果后处理逻辑如下:
- ⼆次确认结果为Commit:服务端将半事务消息标记为可投递,并投递给消费者。
- ⼆次确认结果为Rollback:服务端将回滚事务,不会将半事务消息投递给消费者。
5、在断⽹或者是⽣产者应⽤重启的特殊情况下,若服务端未收到发送者提交的⼆次确认结果,或服务端收到的⼆次确认结果为Unknown未知 状态,经过固定时间后,服务端将对消息⽣产者即⽣产者集群中任⼀⽣产者实例发起消息回查。
6、⽣产者收到消息回查后,需要检查对应消息的本地事务执⾏的最终结果。
7、⽣产者根据检查到的本地事务的最终状态再次提交⼆次确认,服务端仍按照步骤4对半事务消息进⾏处理。
实现时的重点是使⽤RocketMQ提供的TransactionMQProducer事务⽣产者,在TransactionMQProducer中注⼊⼀个TransactionListener事务 监听器来执⾏本地事务,以及后续对本地事务的检查。
注意点:
1、半消息是对消费者不可⻅的⼀种消息。实际上,RocketMQ的做法是将消息转到了⼀个系统Topic,RMQ_SYS_TRANS_HALF_TOPIC。
2、事务消息中,本地事务回查次数通过参数transactionCheckMax设定,默认15次。本地事务回查的间隔通过参数transactionCheckInterval 设定,默认60秒。超过回查次数后,消息将会被丢弃。
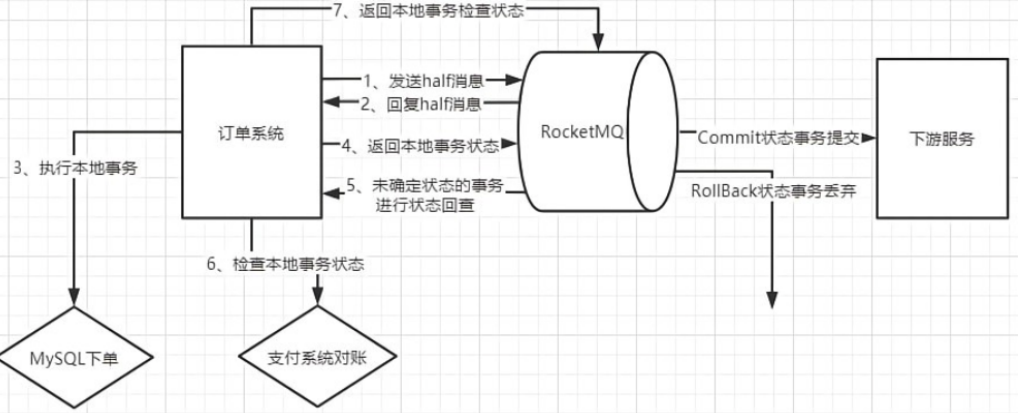
3、其实,了解了事务消息的机制后,在具体执⾏时,可以对事务流程进⾏适当的调整。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号