
RocketMQ 概念介绍
1、消息队列使用场景介绍
-
解耦:如果服务 A 调用服务 B 时是同步依赖,那么 B 服务压力过大可能导致整个系统链路阻塞。
- 流量削峰填谷:高并发场景下(如电商秒杀),直接将请求打到数据库或下游服务会导致瞬时压力过大。消息队列可以充当缓冲,异步处理峰值流量。
- 异步处理:对于非实时业务(日志处理、统计计算、推荐系统)可异步处理,提高整体吞吐和响应速度。
2、为什么选择RocketMQ?
Kafka: 虽然吞吐量惊人,但在企业场景中有明显短板: - 缺少事务消息、延时消息等关键特性 - 运维依赖ZooKeeper,故障排查困难
RabbitMQ:功能全面,但性能瓶颈明显: - Erlang VM的GC问题在高负载时暴露 - 镜像队列的网络开销过大 - 消息堆积时内存压力巨大。
RocketMQ: 在各维度都做到了很好的平衡: - 单机10万TPS对大部分业务够用 - 事务消息、顺序消息、延时消息等特性齐全 - NameServer去中心化设计,运维相对简单 - 阿里双11验证,稳定性有保障。
3、RocketMQ核心概念
核心组件
- NameServer:去中心化的路由注册中心,提供轻量级的服务发现和路由功能。
- Broker:消息存储和中转的核心组件,负责消息的接收、存储和转发。
- Producer:消息生产者,负责向Broker发送消息。
- Consumer:消息消费者,负责从Broker消费消息。
- Topic:消息的逻辑分类,一个Topic可以有多个队列。
- Message Queue:消息的物理存储单元,一个Topic可以有多个队列。
- Message:消息的载体,包含消息体、消息属性等。
消息类型
- 普通消息:最基本的消息类型。
- 顺序消息:保证消息的消费顺序。
- 延时消息:消息延迟消费。
- 批量消息:将多条消息批量发送。
- 事务消息:保证分布式事务的一致性。
4、消息流转过程:
1. 启动初始化:
Broker注册:Broker启动时,会向所有NameServer注册自身信息(包括IP地址、端口、存储的Topic-Queue列表,如“pay_topic的Queue0-3在Broker-A”)。
路由表生成:NameServer汇总所有Broker的信息,形成全局路由表(记录“哪个Topic的消息在哪些Broker的哪些MessageQueue上”)。
2. 生产者发送消息:从业务系统到Broker存储
步骤1:获取路由
生产者启动时,从NameServer拉取“pay_topic”对应的Broker地址(假设返回Broker-A和Broker-B)。
步骤2:选择MessageQueue
生产者按负载均衡策略(默认轮询,或按业务ID哈希,如订单ID%Queue数)选择一个MessageQueue(如Broker-A的Queue0)。
MessageQueue消息的“物理存储单元”,每个Topic包含多个MessageQueue(默认4个),可以分散在不同Broker上(比如Topic有8个MessageQueue,分布在2个Broker上,每个Broker存4个)。
核心作用:MessageQueue是实现“并行处理”的关键——生产者可向多个Queue并行发送消息,消费者可从多个Queue并行拉取消息,大幅提升吞吐量(类似“多个货架同时存/取包裹”)。
步骤3:发送消息
生产者通过网络将消息发送到Broker-A的Queue0,支持三种发送方式(默认超时时间3S):
- 同步发送:等Broker返回“成功”后再继续(适合核心消息,如支付通知);
- 异步发送:发送后立即返回,Broker处理完通过回调通知结果(适合非核心但需结果的场景);
- 单向发送:只发不关心结果(适合日志、监控等消息)。
步骤4:Broker存储消息
Broker-A收到消息后,执行两步存储:
- 写入CommitLog(全局日志文件,所有消息混存,按时间顺序写入);单个文件默认1G。
- 同步到ConsumeQueue(消息索引文件,按Topic-Queue划分,记录消息在CommitLog中的位置,便于消费者快速查询)。每个文件默认5.72M。
3. 消费者消费消息:从Broker拉取到业务处理
步骤1:获取路由
消费者启动时,同样从NameServer获取“pay_topic”的Broker地址(Broker-A和Broker-B)。
步骤2:拉取消息
消费者向Broker-A发起拉取请求,根据Offset(消费进度,记录“已消费到MessageQueue0的第100条消息”)拉取未消费的消息(如从第101条开始)。
步骤3:处理消息
消费者接收消息后,执行业务逻辑(如向用户发送支付短信、更新订单状态)。
步骤4:提交Offset
在实现消费者的业务逻辑时,应该要尽量使⽤同步实现⽅式,保证在⾃⼰业务处理完成之后再向Broker端返回状态。处理成功后,返回值是⼀个枚举值,有两个选项 CONSUME_SUCCESS和RECONSUME_LATER。如果消费者返回CONSUME_SUCCESS,那么消息⾃ 然就处理结束了。但是如果消费者没有处理成功,返回的是RECONSUME_LATER,Broker就会过⼀段时间再发起消息重试。消费者向Broker提交新的Offset(如“已消费到第150条”),Broker记录该进度(集群消费时Offset存在Broker,广播消费时存在本地)。
异常处理:
- 若消费失败(如业务逻辑抛异常),消息不会提交Offset,RocketMQ的做法是给每个消费者组⾃动⽣成⼀个对应的重试Topic。RocketMQ 会自动将消息推送到对应的重试队列中。可以通过配置定时重试时间间隔、最大重试次数等。
- 重试超过16次(默认)后,消息进入死信队列(DLQ),需人工排查处理(如“pay_topic%DLQ”)。
对于顺序消息和并发消息处理策略:

消费者消费消息时也可以指定消费的偏移量
public enum ConsumeFromWhere {
CONSUME_FROM_LAST_OFFSET, //从对列的最后⼀条消息开始消费
CONSUME_FROM_FIRST_OFFSET, //从对列的第⼀条消息开始消费
CONSUME_FROM_TIMESTAMP; //从某⼀个时间点开始重新消费
}
4、核心特性:保障高可用与可靠性的关键设计
RocketMQ能在电商、金融等核心场景立足,依赖五大核心特性,从根本上解决“消息丢失、服务中断、事务一致性”等问题。
1. 持久化机制:宕机不丢消息
消息写入Broker后,并非只存在内存,而是通过“刷盘”写入磁盘文件(CommitLog),确保Broker宕机后重启可恢复消息。支持两种刷盘策略:
- 同步刷盘:消息写入磁盘后才返回生产者“成功”(核心消息必用,如支付消息,零丢失但性能略低);
- 异步刷盘:消息先存内存,定时(默认500ms)批量刷盘(非核心消息用,如日志,性能高但极端情况可能丢消息)。
2. 主从架构:故障自动恢复
每个Broker可配置1个从节点(Slave),形成“主从备份”:
- 主节点(Master):负责接收生产者消息、处理消费者请求(读写都走主节点);
- 从节点(Slave):实时同步主节点的CommitLog,仅提供读能力(分担主节点读压力)。
核心能力:主节点宕机后,从节点通过DLedger协议(基于Raft算法)自动竞选为新主(约10秒内完成),生产者/消费者通过NameServer感知新主地址,无缝切换,服务不中断。
3. 事务消息:解决分布式事务一致性
在分布式系统中,“订单创建”和“库存扣减”需保证原子性(要么都成功,要么都失败),RocketMQ通过“半消息+确认/回滚”实现:
- 步骤1:生产者发送“半消息”(暂存,消费者不可见);
- 步骤2:执行本地事务(如创建订单);
- 步骤3:若事务成功,发送“确认”指令(半消息变为可见,消费者处理);若失败,发送“回滚”指令(半消息删除)。
兜底机制:若步骤3超时,Broker会主动查询生产者事务状态(回调check方法),避免消息长期处于半消息状态。
4. 延迟消息:支持定时投递
业务中常需“订单15分钟未支付自动取消”“30天后自动确认收货”,RocketMQ通过“延迟队列+定时调度”实现:
生产者发送消息时指定延迟级别(如message.setDelayTimeLevel(3),对应10秒,默认支持18个级别:1s/5s/10s/30s/1m…2h);
消息先存到“延迟队列”(系统内置Topic:SCHEDULE_TOPIC_XXXX);
定时任务(每隔1s)扫描延迟队列,将到期消息投递到目标Topic,消费者即可接收。
5. 重试与死信:确保消息不“失联”
消费失败的消息不会被丢弃,而是进入重试机制:
- 重试队列:消费失败后,消息被放入“%RETRY%消费组名”队列,默认重试16次(间隔从1s递增到2h);
- 死信队列:超过重试次数后,消息进入“%DLQ%消费组名”队列,可人工查看日志、修复问题后重新投递,避免消息丢失且便于排查。
5、RocketMQ怎么对文件进行读写
RocketMQ对文件的读写巧妙地利用了操作系统的一些高效文件读写方式——PageCache、顺序读写、零拷贝。
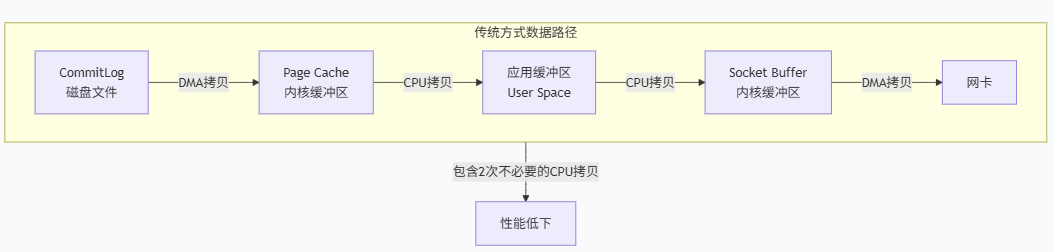
1、传统文件传输步骤:
-
read()系统调用:-
上下文切换:程序从用户态切换到内核态。
-
DMA 拷贝:DMA 引擎将文件数据从磁盘拷贝到内核空间的页缓存。
-
CPU 拷贝:CPU 将数据从内核页缓存拷贝到用户空间的缓冲区。
-
-
write()系统调用: -
上下文切换:程序再次从用户态切换到内核态。
-
CPU 拷贝:CPU 将数据从用户空间的缓冲区拷贝到内核空间的 Socket 缓冲区。
-
DMA 拷贝:DMA 引擎将数据从 Socket 缓冲区拷贝到网卡缓冲区,最终通过网络发送出去。
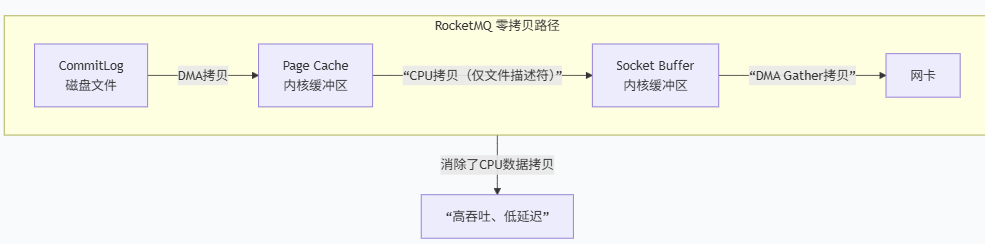
2、RocketMQ使用零拷贝
1、DMA 拷贝:磁盘上的 CommitLog 文件数据被 DMA 引擎加载到内核的 Page Cache。(这一步与传统方式相同,是必需的物理读取)。
2、CPU 拷贝(仅描述符拷贝):
- Broker 进程调用
sendfile()系统调用。
- CPU 不再拷贝数据本身,而是将 Page Cache 中对应数据块的内存地址和偏移量(文件描述符) 等信息,填充到 Socket 缓冲区。
3、DMA 拷贝
网卡驱动根据 Socket 缓冲区 中的描述符,直接从 Page Cache 的多个位置 将数据包的所有部分“收集”起来,一并发送到网络。
这是关键:数据直接从内核缓冲区流向网卡,再也没有经过用户态。
RocketMQ 独特的存储设计使得零拷贝能发挥最大效用:
-
所有消息顺序写入一个巨大的 CommitLog 文件。这意味着在磁盘上,数据是紧凑、连续的,非常适合顺序读和批量传输。
-
当 Consumer 拉取消息时,Broker 根据
ConsumeQueue(索引文件)找到一批消息在CommitLog中的物理偏移量。 -
这些消息在
CommitLog中很可能是连续存储的(因为是顺序追加写入)。这样,Broker 可以通过一次sendfile调用,将多个连续的消息内容(可能几十KB)作为一个整体发送出去。 -
即使消息在
CommitLog中不绝对连续,sendfile也支持多次 Gather 操作,将多个不连续的数据块一并发送,效率依然很高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号