
Redis数据结构以及应用场景分析
1. String(字符串)
1.1、底层实现:
String 类型的底层实现有三种,Redis 会根据存储的值自动选择最合适的:
- int:当存储的值是整数值且可以用 `long` 类型表示时,Redis 会直接将其保存在 `redisObject` 的 `ptr` 位置,这样无需额外分配内存,效率最高。
- embstr:当存储的字符串值长度较短(在 Redis 3.x 及以前是 ≤ 39 字节,新版本有调整)时,Redis 会分配一块连续的内存空间,将 `redisObject` 和 SDS 结构放在一起。这能提高缓存 locality,减少内存分配次数。
- raw:当存储的字符串值长度较长时,Redis 会为一个 SDS 分配独立的内存空间,并通过 `redisObject` 的 `ptr` 指针指向它。
1.2、应用场景:
-
缓存: 最经典的场景,缓存对象(如用户信息、商品信息),通常序列化成JSON字符串后存储。
-
计数器: 利用
INCR,DECR命令实现文章阅读量、视频播放量、点赞数等。INCR是原子操作,无需担心并发问题。 -
分布式锁: 使用
SET key value NX PX timeout命令实现简单的分布式锁。NX表示仅当Key不存在时设置,PX设置过期时间。 -
Session存储: 在分布式Web服务中,将用户Session集中存储在Redis中。
-
单值存储: 存储简单的键值对,如系统配置、验证码等。
2. Hash(哈希/字典)
Hash 类型的底层实现有两种:
- 压缩列表(ziplist):当 Hash 中的 字段数量 少于 `hash-max-ziplist-entries` 且 所有字段名和字段值 的长度都小于 `hash-max-ziplist-value` 时使用。
- 哈希表(hashtable):当不满足上述条件时,会转换为真正的哈希表(`dict` 结构)。
哈希表如何解决 rehash 问题?
Redis 的哈希表使用渐进式 rehash。
过程:在需要扩容时,会同时维护两个哈希表(`ht[0]` 和 `ht[1]`)。新数据写入 `ht[1]`,同时,在每次对 Hash 进行增、删、改、查操作时,Redis 会顺带将 `ht[0]` 中对应的一个 bucket 的所有键值对 “迁移” 到 `ht[1]`。
优点:将庞大的 rehash 操作平摊到多次请求中,避免了单次操作导致的服务停顿
应用场景:
-
存储对象: 这是最自然的场景。与String存储整个JSON对象相比,Hash可以更精细地操作对象的字段。优势: 需要修改年龄时,Hash只需
HINCRBY user:1 age 1,而String需要读取、反序列化、修改、序列化、写回整个对象。 -
购物车: Key为
cart:userId,Field为商品ID,Value为商品数量。可以轻松实现添加商品、删除商品、获取全部商品。
3. List(列表)
在 Redis 3.2 之前,List 的底层实现有两种:
- 压缩列表:当列表元素个数少于 `list-max-ziplist-entries` 且每个元素大小小于 `list-max-ziplist-value` 时使用,以节省内存。
- 双向链表:当不满足压缩列表条件时使用。
但是,在 Redis 3.2 及之后,统一使用 `quicklist` 作为 List 的底层实现。
- `quicklist` 是一个由 “压缩列表节点” 构成的 双向链表。它折中了压缩列表和双向链表的优缺点。
优点:既保留了双向链表易于修改的特性,又通过压缩列表节点**降低了内存碎片和内存占用**。
应用场景:
-
消息队列:
-
生产者使用
LPUSH将任务放入列表。 -
消费者使用
RPOP(非阻塞)或BRPOP(阻塞)取出任务进行处理。 -
这是一个简单的FIFO(先进先出)队列。
-
-
文章列表:
-
用户发布新文章时,
LPUSH到user:1:articles列表中。 -
展示时,使用
LRANGE user:1:articles 0 9获取最新的10篇文章。
-
4. Set(集合)
底层实现:
-
intset(整数集合): 当集合中所有元素都是整数且元素数量较少时使用。
-
hashtable(哈希表): 不满足intset条件时使用。Value为NULL,只有Key的哈希表。
特点: 无序、元素不可重复、支持高效的集合运算(交集、并集、差集)。
应用场景:
-
标签(Tag)系统: 给对象(如文章、用户)打标签。
-
给文章打标签:
SADD article:1:tags "tech" "redis" "database" -
查找有
tech和redis两个标签的文章:SINTER tag:tech:articles tag:redis:articles
-
-
共同关注 / 好友推荐:
-
用户A的关注列表:
follows:A -
用户B的关注列表:
follows:B -
计算A和B的共同关注:
SINTER follows:A follows:B -
给A推荐B关注的人:
SDIFF follows:B follows:A
-
-
抽奖/随机元素: 使用
SADD添加参与者,SRANDMEMBER进行随机抽奖(不删除元素),SPOP进行抽奖(删除元素)。
5. Sorted Set(有序集合 / ZSet)
底层实现:
-
ziplist: 当元素数量少于 `zset-max-ziplist-entries` 且每个元素的 `member` 长度小于 `zset-max-ziplist-value` 时使用。
-
skiplist + hashtable(跳表+哈希表): 标准实现。
-
跳表(SkipList): 负责按分数排序,支持范围查询。
-
哈希表(HashTable): 负责O(1)复杂度通过成员(Member)查找分数(Score)。
-
特点: 每个元素关联一个分数(Score),根据分数进行排序。元素不可重复,但分数可以相同。
应用场景:
-
排行榜: 这是最经典的应用。
-
记录玩家分数:
ZADD leaderboard 1000 "player1" 1500 "player2" -
获取Top 10:
ZREVRANGE leaderboard 0 9 WITHSCORES -
查看某个玩家的排名:
ZREVRANK leaderboard "player1"
-
-
范围查找: 例如处理电话号码区间、日期区间等。
什么是跳表?
跳表是一种基于有序链表的数据结构,它通过在链表中添加多级索引,实现快速的查找、插入和删除操作。想象一下,普通的链表查找需要O(n)的时间复杂度,而跳表则通过在不同层级上"跳跃",将时间复杂度降低到O(log n)。
跳表的核心思想是:在有序链表的基础上,构建多级索引。每一级索引都包含当前层级的节点,通过这些索引,我们可以快速跳过大量节点,直接定位到目标区域。
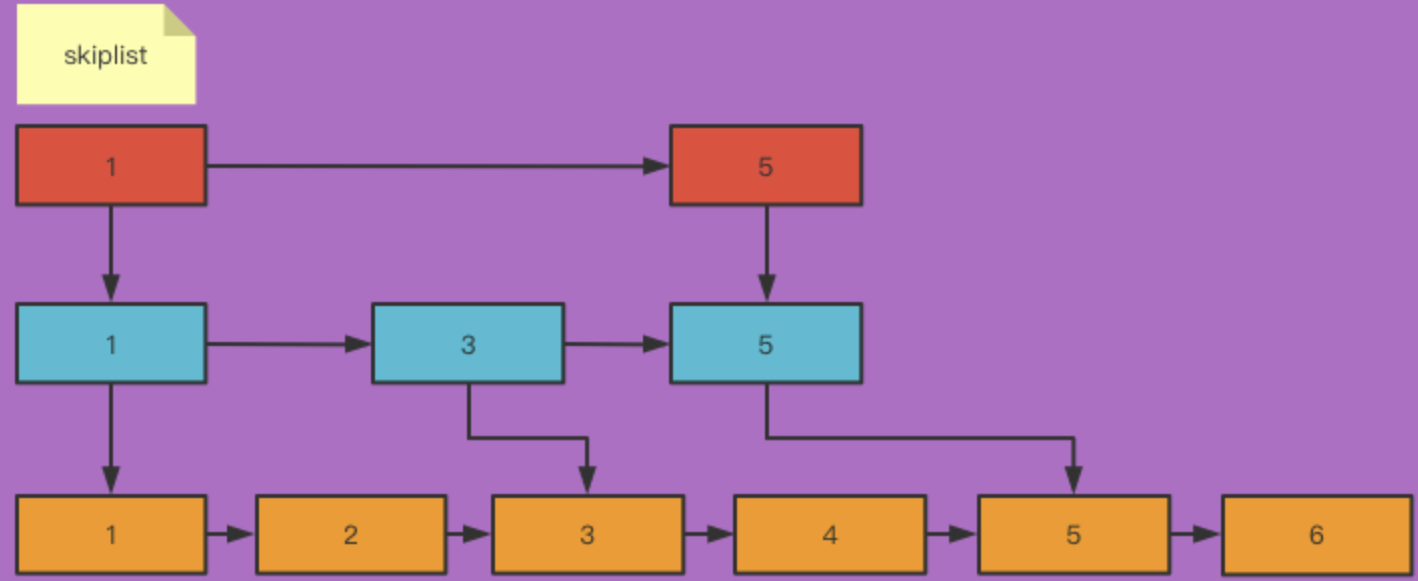
跳表的查找过程:
- 从最高层开始
- 比较当前节点的分数
- 如果当前节点的分数小于目标分数(或者分值相等但成员对象的字典序小于目标成员),则继续向后查找
- 如果当前节点的分数大于目标分数,则向下一层
- 重复直到找到目标节点或到达最低层
跳跃表的底层结构:
typedef struct zskiplistNode { // 存储的元素(SDS字符串) sds ele; // 分值,跳跃表按此排序 double score; // 后退指针,用于从表尾向表头遍历 struct zskiplistNode *backward; // 层数组 struct zskiplistLevel { // 前进指针,指向该层下一个节点 struct zskiplistNode *forward; // 跨度,记录该层前进指针指向的节点与当前节点的距离 unsigned long span; } level[]; } zskiplistNode;
关键点:
-
层(Level):每个节点拥有随机的高度(层数)。层数越高,节点越少,相当于高层是底层的“快速通道”。
-
前进指针(forward):每一层都有一个指向下一个节点的指针。
-
分值(score):节点按分值从小到大排序。分值相同时,按成员对象(ele)的字典序排序。
-
跨度(span):用于快速计算排位(Rank)。
为什么Redis选择跳表而非红黑树或B+树?
- 跳跃表能达到和红黑树相近的 O(log N) 性能,同时实现更简单,范围查询更高效。
- B+树是磁盘友好型数据结构,而 Redis 是内存数据库。在内存访问模式下,跳跃表的简单性带来的好处远超过 B+树为磁盘优化所带来的边际收益。
6. Bitmaps
本质: 它不是一种独立的数据类型,而是基于String类型的一套位操作。可以将String值当作一个巨大的位数组。
应用场景:
-
用户签到: Key为
sign:yyyyMM:userId,偏移量是日期(如1-31)。签到:SETBIT sign:202410:1 15 1(用户1在15号签到)。统计当月签到次数:BITCOUNT sign:202410:1。 -
活跃用户统计: 统计每天哪些用户活跃。Key为
active:yyyy-MM-dd,偏移量是用户ID。可以轻松通过BITOP AND计算连续活跃用户。 -
布隆过滤器(Bloom Filter): 一个概率型数据结构,用于判断“某元素一定不存在或可能存在”。可以用Bitmaps实现,极大节省存储空间。
7、Geospatial(地理空间)
本质: 基于Sorted Set实现,将二维的经纬度编码成一个分数(Score),从而能够进行地理位置的计算和查询。
常用命令: GEOADD, GEOPOS, GEODIST, GEORADIUS, GEORADIUSBYMEMBER
应用场景:
-
附近的人:
GEORADIUS key longitude latitude radius m|km查询指定位置半径内的地点。 -
计算两点距离:
GEODIST key member1 member2 unit。 -
打车软件: 存储司机位置,快速查找附近的司机。
总结:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号