
果然我已经把bs4全忘了并且scrapy只记得一半
因为selenium真的方便好玩且功能齐全
所以第一第二题就只能用很丑陋的代码把他勉强实现出来,害。
作业一
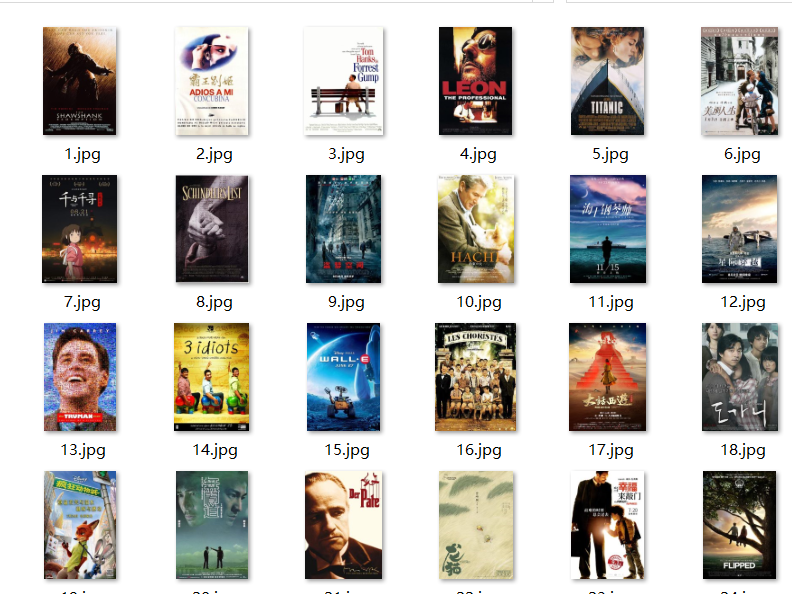
1)、爬取豆瓣top250
代码如下:
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
from prettytable import PrettyTable
import re
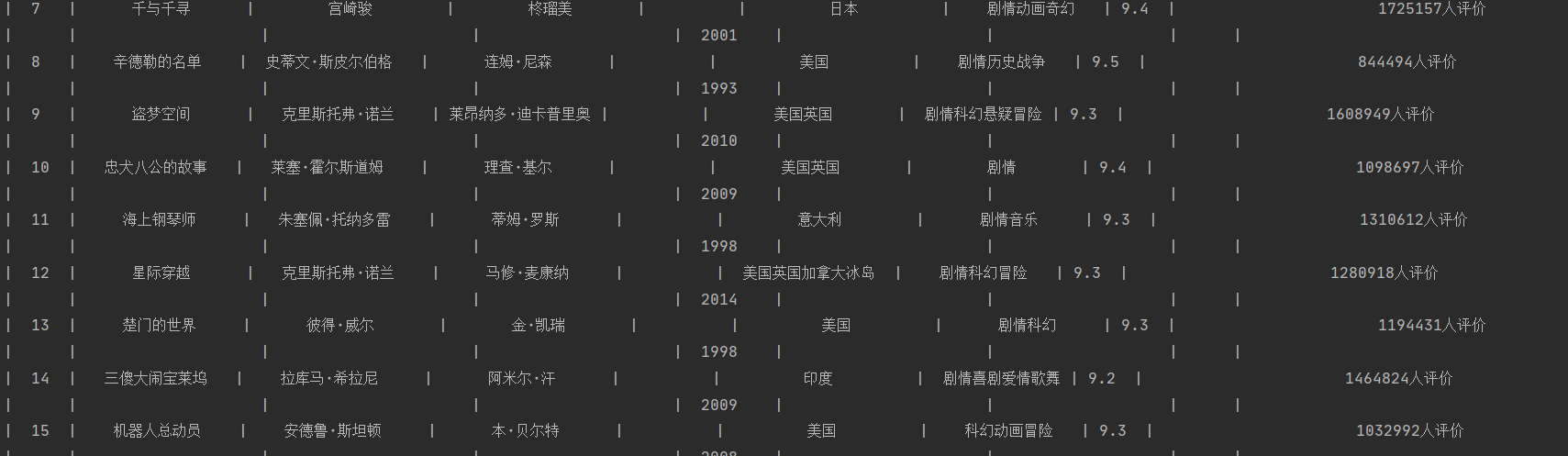
x = PrettyTable(["排名", '电影名称', '导演', '主演', '上映时间','国家','电影类型','评分','评价人数','引用','文件路径'])
def imageSpider(url):
global threads
global count
global name
try:
count=0
urls=[]
req=urllib.request.Request(url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit=UnicodeDammit(data,["utf-8","gbk"])
data=dammit.unicode_markup
soup=BeautifulSoup(data,'html.parser')
images=soup.select("img")
for image in images:
try:
info = soup.find('ol', attrs={'class': "grid_view"})
info_1=info.find_all('li')[count]
name=info_1.find('span',attrs={'class':'title'}).text
director=info_1.find('p',attrs={'class':''}).text
first=director.split(r":",1)
first_1=director.split(r':',2)
first_2=director.split(r'...',1)
second=first[1].split(r' ')
second_1=first_1[2].split(r' ')
second_2=first_2[1].split(r' ')
second_2 = [item for item in filter(lambda x: x != '', second_2)]
m=''.join(second_2)
m.replace(u'\xa0', u' ')
m.split(' ')
direct=second[1]
maind=second_1[1]
m=m.split(r'/',3)
time=m[0]
nation=m[1]
plot=m[2]
num=info_1.find('span',attrs={'class':'rating_num'}).text
num_people=info_1.find_all('span')[7].text
go=info_1.find('span',attrs={'class':'inq'}).text
x.add_row([count+1,name,direct,maind,time,nation,plot,num,num_people,go,name+'.jpg'])
except Exception as err :
print(err)
print('err4')
try:
src=image["src"]
url=urllib.request.urljoin(url,src)
if url not in urls:
count=count+1
T=threading.Thread(target=download,args=(url,count))
T.setDaemon(False)
T.start()
threads.append(T)
except:
print('err')
except Exception as err:
print(err)
print('err1')
def download(url,count):
try:
flag=0
if(url[len(url)-4]=="."):
ext=url[len(url)-4:]
if ext=='.png':
flag=1
else:
ext=""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data=data.read()
if flag==0:
fobj = open("..\文件夹\豆瓣\\" + name + '.jpg', "wb")
fobj.write(data)
fobj.close()
print("downloaded" + str(count) + ext)
except Exception as err:
print(err)
print('err2')
def nextpage():
try:
if count%25==0:
url='https://movie.douban.com/top250?start='+count+'&filter='
imageSpider(url)
except:
print('err3')
url = 'https://movie.douban.com/top250'
headers = {
'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3775.400 QQBrowser/10.6.4209.400'}
count = 0
threads=[]
imageSpider(url)
for i in threads:
i.join()
print('the end')
print(x)
- prettytable:

- 图片:
2)、心得体会
看了看自己前面的代码,在大框架有的情况下倒是不难
就是中间部分的导演、主演全部写在了一起
所有只能用了我自己都看不下去的丑陋的re表达式把那一大段的句子一点一点的从各种符号中拆分出来
prettytable对的不是很齐,不过不太在意,想要对齐存数据库就好了。
作业二
1)、爬取大学信息
随着接触的框架越来越多(django,scrapy)之类的,一个前人搭建好的框架真的可以节省很多时间。
因为分类太多,加上之前也做过,这里只放上主函数的代码
代码如下:
import scrapy
from ..items import ruankeItem
from selenium.webdriver.firefox.options import Options
from selenium import webdriver
from selenium.webdriver import Firefox
import time
import urllib.request
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3776.400 QQBrowser/10.6.4212.400'}
class MySpider(scrapy.Spider):
name = 'ruanke'
count = 0
def start_requests(self):
url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
fire_option = Options()
self.driver = Firefox(options=fire_option)
try:
self.driver.get("https://www.shanghairanking.cn/rankings/bcur/2020")
time.sleep(2)
self.driver.maximize_window()
a=len(self.driver.find_elements_by_xpath("//table[@class='rk-table']//tbody//tr"))
for i in range(a):
self.driver.find_element_by_xpath("//table[@class='rk-table']//tbody//tr[position()="+str(i+1)+"]//a[@class='']").click()
self.count += 1
time.sleep(2)
print(self.driver.current_url)
time.sleep(2)
try:
item = ruankeItem()
item['sNo'] = str(self.count)
item['school'] = str(self.driver.find_element_by_xpath('//div[@class="univ-name"]').text)
a = self.driver.find_elements_by_xpath('//div[@class="science-rank-text"]')[1].text
item['city'] = str(a[:-3])
item['official'] = str(self.driver.find_element_by_xpath('//div[@class="univ-website"]/a').text)
item['info'] = str(self.driver.find_element_by_xpath("//div[@class='univ-introduce']/p").text)
item['mFile'] = str(self.count) + '.jpg'
yield item
except Exception as err:
print(err)
print('err10')
try:
image=self.driver.find_element_by_xpath("//td[@class='univ-logo']//img").get_attribute('src')
req=urllib.request.Request(image)
data=urllib.request.urlopen(req)
data=data.read()
print(image)
fobj=open(r"G:\TECENT(3)\tech study\untitled\爬虫\文件夹\example(软科)\img\\"+str(self.count)+'.png',"wb")
fobj.write(data)
fobj.close()
except Exception as err:
print(err)
time.sleep(1)
self.driver.back()
time.sleep(1)
except Exception as er:
print(er)
print('err11')
-
数据库:

-
图片:

2)、心得体会
在scrapy框架下混杂使用了selenium,因为涉及到了页面跳转,而我不太找得出每个url中的关联,所有选择自动化点击。
pipeline中的函数process_item在复写的时候仅仅只是改了个名字成process_spider就害我找了半个小时,框架好用的前提是你理解框架并且不会一不小心破坏它。
这个页面是点击跳转之后之前的界面就消失了,所以不需要window转换,只要简单的back()回去就可以了
剩下问题不大
作业三
1)、selenium自动化登录以及爬取mooc
基本等同于上次做过的作业,就是登陆之后需要点进个人中心,然后有两次的页面跳转,每爬完一个界面需要self.driver.close()两次
代码如下:
import datetime
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
import sqlite3
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def startUp(self, url):
firefox_options = Options()
self.driver = Firefox(options=firefox_options)
time.sleep(1)
self.driver.get(url)
time.sleep(1)
self.No = 0
try:
self.con = sqlite3.connect("selenium.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table mooc")
except:
pass
try:
sql = "create table mooc (id varchar(256),cCource varchar(256),cCollege varchar(256),cTeacher varchar(256),cTeam varchar(256),cCount varchar(256),cProcess varchar(256),cBrief varchar(256))"
self.cursor.execute(sql)
except:
pass
except:
print("err0")
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print("err1")
print(err)
def insertDB(self, id, cCource, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief):
try:
sql = "insert into mooc (id,cCource,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) values(?,?,?,?,?,?,?,?)"
self.cursor.execute(sql, (
id, cCource, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
except:
print("err3")
def showDB(self):
try:
con = sqlite3.connect("selenium.db")
cursor = con.cursor()
print("%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s" % (
"id", "cCource", "cCollege", "cTeacher", "cTeam", "cCount", "cProcess","cBrief"))
cursor.execute("select id, cCource, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief from mooc order by id")
rows = cursor.fetchall()
for row in rows:
print("%-16s %-16s %-16s %-16s %-16s %-16s %-16s %-16s" % (
row[0], row[1], row[2], row[3], row[4], row[5], row[6],row[7]))
con.close()
except:
print("err4")
def load_mooc(self):
self.driver.maximize_window()
load_1=self.driver.find_element_by_xpath("//a[@class='f-f0 navLoginBtn']")
load_1.click()
time.sleep(1)
load_2=self.driver.find_element_by_xpath("//span[@class='ux-login-set-scan-code_ft_back']")
load_2.click()
time.sleep(1)
load_3=self.driver.find_elements_by_xpath("//ul[@class='ux-tabs-underline_hd']//li")[1]
load_3.click()
time.sleep(1)
iframe_id=self.driver.find_elements_by_tag_name("iframe")[1].get_attribute('id')
self.driver.switch_to.frame(iframe_id)
self.driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys('13023875560')
time.sleep(1)
self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']").send_keys('8585asd369')
time.sleep(1)
self.driver.find_element_by_xpath("//a[@class='u-loginbtn btncolor tabfocus ']").click()
time.sleep(5)
self.driver.get(self.driver.current_url)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
print('0')
self.driver.find_element_by_xpath("//div[@class='u-navLogin-myCourse-t']").click()
print('1')
time.sleep(2)
self.driver.find_element_by_xpath("//div[@class='f-fl f-f0']//a[position()=4]").click()
time.sleep(2)
ms=self.driver.find_elements_by_xpath("//div[@class='course-card-wrapper']")
for m in ms:
m.click()
time.sleep(2)
last_window=self.driver.window_handles[-1]
self.driver.switch_to.window(last_window)
self.driver.find_element_by_xpath("//h4[@class='f-fc3 courseTxt']").click()
last_window=self.driver.window_handles[-1]
self.driver.switch_to.window(last_window)
print(self.driver.current_url)
time.sleep(2)
try:
cCource=self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text
print(cCource)
cCollege = self.driver.find_element_by_xpath("//img[@class='u-img']").get_attribute("alt")
print(cCollege)
cTeacher = self.driver.find_element_by_xpath("//div[@class='um-list-slider_con']/div[position()=1]//h3[@class='f-fc3']").text
print(cTeacher)
z=0
cTT = []
while(True):
try:
cTeam = self.driver.find_elements_by_xpath(
"//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']")[z].text
z += 1
cTT.append(cTeam)
except:
break
ans=",".join(cTT)
print(ans)
cCount=self.driver.find_element_by_xpath("//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text
print(cCount)
cProcess=self.driver.find_element_by_xpath("//div[@class='course-enroll-info_course-info_term-info_term-time']//span[position()=2]").text
print(cProcess)
cBrief = self.driver.find_element_by_xpath("//div[@id='j-rectxt2']").text
print(cBrief)
self.driver.close()
dd=self.driver.window_handles[-1]
self.driver.switch_to.window(dd)
except Exception as err:
print(err)
self.driver.close()
old_window=self.driver.window_handles[0]
self.driver.switch_to.window(old_window)
self.No = self.No + 1
no = str(self.No)
while len(no) < 3:
no = "0" + no
print(no)
self.insertDB(no, cCource, cCollege, cTeacher, ans, cCount, cProcess, cBrief)
except Exception as err:
print(err)
print("err10")
def executeSpider(self, url):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
self.load_mooc()
print("loading closing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "https://www.icourse163.org/channel/2001.htm"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url)
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
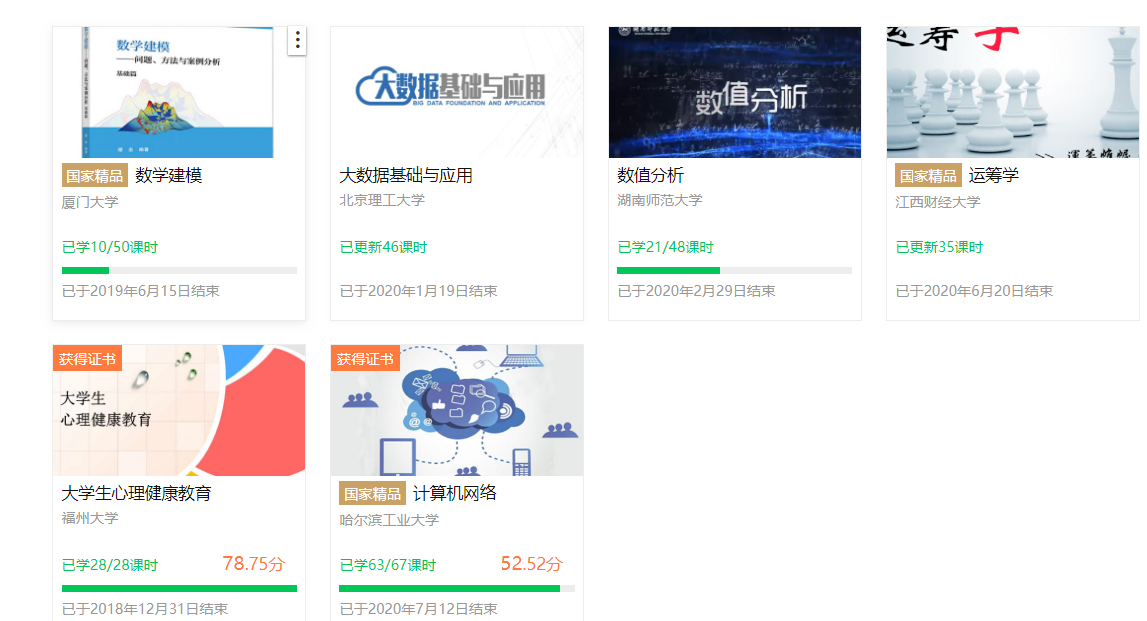
- 数据库:

-
确实只有这六门课
-
gif 动态图:
随便找了个格式转换,不过应该能勉强看清
2)、心得体会
其实和上次基本相同,登录的时候需要转换iframe。
就是需要点进个人中心,再点进你学完的课程的主页面。
这次有会跳转出两个窗口,所以需要在爬完页面后关掉两个窗口,并且回到主页面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号