
selenium真的太香了,这种自动化的爬取真的让爬虫充满了乐趣,相比之下的re和scrapy就显得捉襟见肘,而且第三题mooc是真的很好玩,看着它自己动有种写了脚本的感觉,真不戳
作业一
1)、爬京东
代码如下:
import datetime
from selenium.webdriver import Firefox
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.keys import Keys
import urllib.request
import threading
import sqlite3
import os
import time
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
imagePath = "download"
def startUp(self, url, key):
firefox_options = Options()
#firefox_options.add_argument("——headless")
#firefox_options.add_argument("——disable-gpu")
self.driver = Firefox(options=firefox_options)
self.threads = []
self.No = 0
self.imgNo = 0
try:
self.con = sqlite3.connect("selenium.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table phones")
except:
pass
try:
sql = "create table phones (mNo varchar(32) primary key, mMark varchar(256),mPrice varchar(32),mNote varchar(1024),mFile varchar(256))"
self.cursor.execute(sql)
except:
pass
except Exception as err:
print("err0")
try:
if not os.path.exists(MySpider.imagePath):
os.mkdir(MySpider.imagePath)
images = os.listdir(MySpider.imagePath)
for img in images:
s = os.path.join(MySpider.imagePath, img)
os.remove(s)
except Exception as err:
print("err1")
self.driver.get(url)
keyInput = self.driver.find_element_by_id("key")
keyInput.send_keys(key)
keyInput.send_keys(Keys.ENTER)
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print("err2")
def insertDB(self, mNo, mMark, mPrice, mNote, mFile):
try:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (?,?,?,?,?)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
except Exception as err:
print("err3")
def showDB(self):
try:
con = sqlite3.connect("phones.db")
cursor = con.cursor()
print("%-8s%-16s%-8s%-16s%s" % ("No", "Mark", "Price", "Image", "Note"))
cursor.execute("select mNo,mMark,mPrice,mFile,mNote from phones order by mNo")
rows = cursor.fetchall()
for row in rows:
print("%-8s %-16s %-8s %-16s %s" % (row[0], row[1], row[2], row[3], row[4]))
con.close()
except Exception as err:
print(err)
def download(self, src1, src2, mFile):
data = None
if src1:
try:
req = urllib.request.Request(src1, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if not data and src2:
try:
req = urllib.request.Request(src2, headers=MySpider.headers)
resp = urllib.request.urlopen(req, timeout=10)
data = resp.read()
except:
pass
if data:
print("download begin", mFile)
fobj = open(MySpider.imagePath + "\\" + mFile, "wb")
fobj.write(data)
fobj.close()
print("download finish", mFile)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
lis = self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
for li in lis:
# We find that the image is either in src or in data-lazy-img attribute
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
self.No = self.No + 1
no = str(self.No)
while len(no) < 6:
no = "0" + no
print(no, mark, price)
if src1:
src1 = urllib.request.urljoin(self.driver.current_url, src1)
p = src1.rfind(".")
mFile = no + src1[p:]
elif src2:
src2 = urllib.request.urljoin(self.driver.current_url, src2)
p = src2.rfind(".")
mFile = no + src2[p:]
if src1 or src2:
T = threading.Thread(target=self.download, args=(src1, src2, mFile))
T.setDaemon(False)
T.start()
self.threads.append(T)
else:
mFile = ""
self.insertDB(no, mark, price, note, mFile)
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(10)
nextPage.click()
self.processSpider()
except Exception as err:
print(err)
def executeSpider(self, url, key):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url, key)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
for t in self.threads:
t.join()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://www.jd.com"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url, "手机")
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
- 爬取过程:

- 数据库中的数据:

- 图片:

2)、心得体会
完全的复现,但是最好还是自己打了一遍之后学到了一些东西用于之后的两个作业,复现过程中要注意python中的缩进,process函数中的一小块地方的缩进差点让我把anaconda卸了重装
所以要在理解了代码的基础上复现才行。
作业二
1)、股票实验
代码如下:
import datetime
from selenium.webdriver import Firefox
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.keys import Keys
import urllib.request
import threading
import sqlite3
import os
import time
import pymysql
class MySpider:
flag=1
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def startUp(self, url):
firefox_options = Options()
self.driver = Firefox(options=firefox_options)
time.sleep(3)
self.driver.get(url)
time.sleep(3)
self.No = 0
try:
self.con = sqlite3.connect("selenium.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table stocks")
except:
pass
try:
sql = "create table stocks (nnum varchar(256),ncode varchar(256),nname varchar(256),nprice varchar(256),nup varchar(256),nup_num varchar(256),nfinish varchar(256),nfinish_num varchar(256),nupup varchar(256),nhighest varchar(256),nlowest varchar(256),now varchar(256),yestoday varchar(256))"
self.cursor.execute(sql)
except:
pass
except:
print("err0")
def closeUp(self):
try:
self.con.commit()
self.con.close()
# self.driver.close()
except Exception as err:
print("err1")
print(err)
def insertDB(self, nnum, ncode, nname, nprice, nup, nup_num, nfinish, nfinish_num, nupup, nhighest, nlowest, now,
yestoday):
try:
sql = "insert into stocks (nnum ,ncode ,nname ,nprice ,nup ,nup_num ,nfinish ,nfinish_num ,nupup ,nhighest ,nlowest ,now ,yestoday) values(?,?,?,?,?,?,?,?,?,?,?,?,?)"
self.cursor.execute(sql, (
nnum, ncode, nname, nprice, nup, nup_num, nfinish, nfinish_num, nupup, nhighest, nlowest, now, yestoday))
except:
print("err3")
def showDB(self):
try:
con = sqlite3.connect("selenium.db")
cursor = con.cursor()
print("%-16s%-16s%-16s%-16s%-16s%-16s%-16s" % ("nnum", "ncode", "nname", "nprice", "nup", "nup_num", "nfinish"))
cursor.execute("select nnum ,ncode ,nname ,nprice ,nup ,nup_num ,nfinish from stocks order by nnum")
rows = cursor.fetchall()
for row in rows:
print("%-16s %-16s %-16s %-16s %-16s %-16s %-16s" % (row[0], row[1], row[2], row[3], row[4], row[5], row[6]))
con.close()
except:
print("err4")
def processSpider(self):
try:
time.sleep(3)
print(self.driver.current_url)
lis = self.driver.find_elements_by_xpath("//table[@id='table_wrapper-table']/tbody/tr")
print(lis)
for li in lis:
try:
ncode = li.find_element_by_xpath(".//td[position()=2]").text
nname = li.find_element_by_xpath(".//td[position()=3]").text
nprice = li.find_element_by_xpath(".//td[position()=5]").text
nup = li.find_element_by_xpath(".//td[position()=6]").text
nup_num = li.find_element_by_xpath(".//td[position()=7]").text
nfinish = li.find_element_by_xpath(".//td[position()=8]").text
nfinish_num = li.find_element_by_xpath(".//td[position()=9]").text
nupup = li.find_element_by_xpath(".//td[position()=10]").text
nhighest = li.find_element_by_xpath(".//td[position()=11]").text
nlowest = li.find_element_by_xpath(".//td[position()=12]").text
now = li.find_element_by_xpath(".//td[position()=13]").text
yesterday = li.find_element_by_xpath(".//td[position()=14]").text
except:
print("err5")
self.No = self.No + 1
no = str(self.No)
while len(no) < 3:
no = "0" + no
print(no)
self.insertDB(no, ncode, nname, nprice, nup, nup_num, nfinish, nfinish_num, nupup, nhighest, nlowest,
now, yesterday)
try:
nextpage = self.driver.find_element_by_xpath(
"//div[@class='dataTables_wrapper']//div[@class='dataTables_paginate paging_input']//a[@class='next paginate_button']")
time.sleep(6)
nextpage.click()
self.processSpider()
except:
self.driver.find_element_by_xpath(
"//div[@class='dataTables_wrapper']//div[@class='dataTables_paginate paging_input']//a[@class='next paginate_button disabled']")
self.flag += 1
if self.flag <= 3:
li=self.driver.find_elements_by_xpath("//ul[@class='tab-list clearfix']//li")[self.flag-1]
li.click()
time.sleep(2)
self.processSpider()
except Exception as err:
print(err)
print("err7")
def executeSpider(self, url):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url)
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
- 运行过程:
- 数据库中数据:
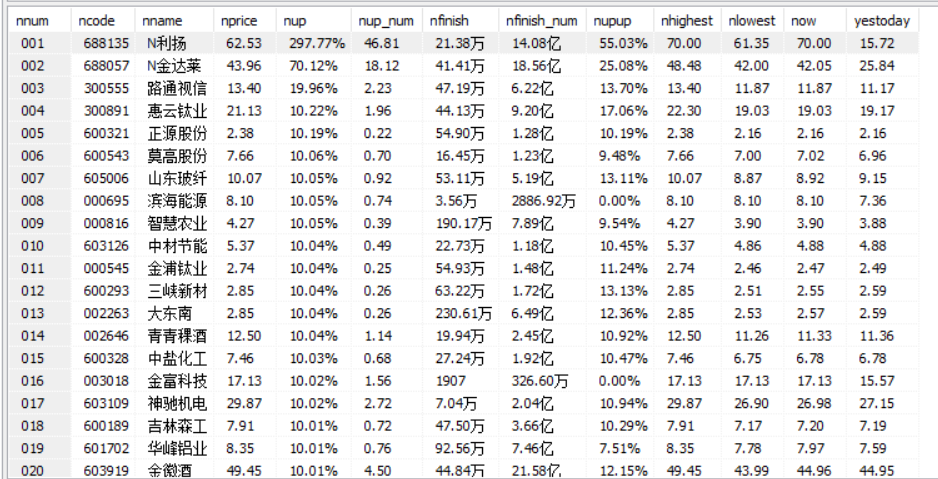
2)、心得体会
在理解了第一题的情况下难度不大
就是爬取类别较多,sql语句打的有点烦
爬取多个股票就在翻页的try except中加这个东西,但是两百多页真的爬不完了
然后在process过程中熟练运用position()=?就可以很快定位到这种结构化的表格
然后翻页按钮和京东不同,不可照抄第一题。
作业三
1)、中国慕课网
代码如下:
import datetime
import selenium
from selenium.webdriver import Firefox
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.keys import Keys
import urllib.request
import threading
import sqlite3
import os
import time
import pymysql
class MySpider:
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
def startUp(self, url):
firefox_options = Options()
self.driver = Firefox(options=firefox_options)
time.sleep(1)
self.driver.get(url)
time.sleep(1)
self.No = 0
try:
self.con = sqlite3.connect("selenium.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute("drop table mooc")
except:
pass
try:
sql = "create table mooc (id varchar(256),cCource varchar(256),cCollege varchar(256),cTeacher varchar(256),cTeam varchar(256),cCount varchar(256),cProcess varchar(256),cBrief varchar(256))"
self.cursor.execute(sql)
except:
pass
except:
print("err0")
def closeUp(self):
try:
self.con.commit()
self.con.close()
self.driver.close()
except Exception as err:
print("err1")
print(err)
def insertDB(self, id, cCource, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief):
try:
sql = "insert into mooc (id,cCource,cCollege,cTeacher,cTeam,cCount,cProcess,cBrief) values(?,?,?,?,?,?,?,?)"
self.cursor.execute(sql, (
id, cCource, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
except:
print("err3")
def showDB(self):
try:
con = sqlite3.connect("selenium.db")
cursor = con.cursor()
print("%-16s%-16s%-16s%-16s%-16s%-16s%-16s%-16s" % (
"id", "cCource", "cCollege", "cTeacher", "cTeam", "cCount", "cProcess","cBrief"))
cursor.execute("select id, cCource, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief from mooc order by id")
rows = cursor.fetchall()
for row in rows:
print("%-16s %-16s %-16s %-16s %-16s %-16s %-16s %-16s" % (
row[0], row[1], row[2], row[3], row[4], row[5], row[6],row[7]))
con.close()
except:
print("err4")
def load_mooc(self):
self.driver.maximize_window()
load_1=self.driver.find_element_by_xpath("//a[@class='f-f0 navLoginBtn']")
load_1.click()
time.sleep(1)
load_2=self.driver.find_element_by_xpath("//span[@class='ux-login-set-scan-code_ft_back']")
load_2.click()
time.sleep(1)
load_3=self.driver.find_elements_by_xpath("//ul[@class='ux-tabs-underline_hd']//li")[1]
load_3.click()
time.sleep(1)
iframe_id=self.driver.find_elements_by_tag_name("iframe")[1].get_attribute('id')
self.driver.switch_to.frame(iframe_id)
self.driver.find_element_by_xpath("//input[@id='phoneipt']").send_keys('13023875560')
time.sleep(1)
self.driver.find_element_by_xpath("//input[@class='j-inputtext dlemail']").send_keys('8585asd369')
time.sleep(1)
self.driver.find_element_by_xpath("//a[@class='u-loginbtn btncolor tabfocus ']").click()
time.sleep(5)
self.driver.get(self.driver.current_url)
def processSpider(self):
try:
time.sleep(1)
print(self.driver.current_url)
print('0')
lis = self.driver.find_elements_by_xpath("//div[@class='_1aoKr']//div[@class='_1gBJC']//div[@class='_2mbYw']")
print('1')
for li in lis:
li.find_element_by_xpath(".//div[@class='_3KiL7']").click()
last_window=self.driver.window_handles[-1]
self.driver.switch_to.window(last_window)
print(self.driver.current_url)
time.sleep(2)
try:
cCource=self.driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text
print(cCource)
cCollege = self.driver.find_element_by_xpath("//img[@class='u-img']").get_attribute("alt")
print(cCollege)
cTeacher = self.driver.find_element_by_xpath("//div[@class='um-list-slider_con']/div[position()=1]//h3[@class='f-fc3']").text
print(cTeacher)
z=0
cTT = []
while(True):
try:
cTeam = self.driver.find_elements_by_xpath(
"//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']")[z].text
z += 1
cTT.append(cTeam)
except:
break
ans=",".join(cTT)
print(ans)
cCount=self.driver.find_element_by_xpath("//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text
print(cCount)
cProcess=self.driver.find_element_by_xpath("//div[@class='course-enroll-info_course-info_term-info_term-time']//span[position()=2]").text
print(cProcess)
cBrief = self.driver.find_element_by_xpath("//div[@id='j-rectxt2']").text
print(cBrief)
except Exception as err:
print(err)
self.driver.close()
old_window=self.driver.window_handles[0]
self.driver.switch_to.window(old_window)
self.No = self.No + 1
no = str(self.No)
while len(no) < 3:
no = "0" + no
print(no)
self.insertDB(no, cCource, cCollege, cTeacher, ans, cCount, cProcess, cBrief)
try:
nextpage = self.driver.find_element_by_xpath("//a[@class='_3YiUU ']")
time.sleep(3)
nextpage.click()
self.processSpider()
except:
self.driver.find_element_by_xpath("//a[@class='_3YiUU _1BSqy']")
except:
print("err10")
def executeSpider(self, url):
starttime = datetime.datetime.now()
print("Spider starting......")
self.startUp(url)
print("Spider processing......")
self.load_mooc()
print("loading closing......")
self.processSpider()
print("Spider closing......")
self.closeUp()
print("Spider completed......")
endtime = datetime.datetime.now()
elapsed = (endtime - starttime).seconds
print("Total ", elapsed, " seconds elapsed")
url = "https://www.icourse163.org/channel/2001.htm"
spider = MySpider()
while True:
print("1.爬取")
print("2.显示")
print("3.退出")
s = input("请选择(1,2,3):")
if s == "1":
spider.executeSpider(url)
continue
elif s == "2":
spider.showDB()
continue
elif s == "3":
break
- 爬取过程:

- 数据库中数据:
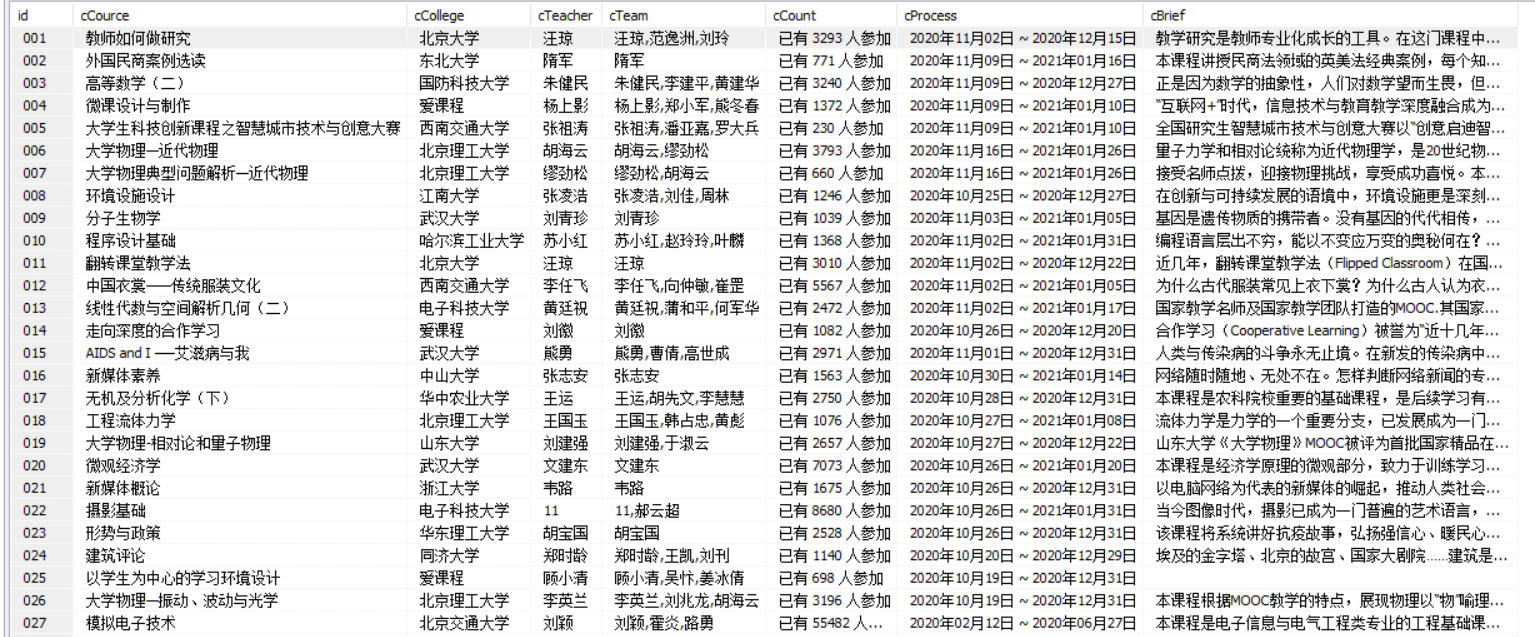
2)、心得体会
这个实验真得有意思,慢慢研究之后会发现所有东西全学会了。
登录界面有点意思,弹出一个新的窗口之后需要转换iframe才能继续爬(switch_to.frame),不然爬出来的东西都是空的,
重点还是在process函数里面,但这次的爬取不一样了,因为主页面的课程不包含我们需要的简介之类的信息,所以我们必须先点进详情页之后爬取,关掉,回到主页面,如此往复
窗口的切换也很搞人,switch_to_window是个废弃函数了,结果他的报错告诉我self.driver.switch_to_window()不可以,但是driver.switch_to_window()可以,让我头有点痛,以为不能放在类里面
后来才知道要改成switch_to.window()。(百度的东西记得看日期)。
接下来就是慢慢找xpath语句,点进页面别立刻退出,time.sleep一会儿才能爬出东西
Mooc的切换页面也是真的好玩,上一页和下一页都是这个语句 : a[@class='_3YiUU _1BSqy'] 的时候是不可点,所以我的第一页一直过不去第二页了,后来换了个顺序,直接try下一页,而不是按照第一题那样。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号