
第一次个人编程作业
- 作业如下
一、GitHub链接在这里
对于commit的操作不熟,所以把很多用于测试函数的.py文件也扔上去了
作业中要求的是main.py文件和rerequirements.txt文件也都在
还有在pycharm中可以跑的pycharm.py文件
题目:论文查重
描述如下:
设计一个论文查重算法,给出一个原文文件和一个在这份原文上经过了增删改的抄袭版论文的文件,在答案文件中输出其重复率。
看到题目的时候感觉这就是以后的作业要用我们自己写的东西来测试我们,感觉浑身一冷
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 70 | 70 |
| Analysis | 需求分析 (包括学习新技术) | 60 | 60 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 30 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 10 | 10 |
| Design | 具体设计 | 60 | 80 |
| Coding | 具体编码 | 240 | 300 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 100 |
| Reporting | 报告 | 10 | 10 |
| Test Repor | 测试报告 | 15 | 15 |
| Size Measurement | 计算工作量 | 10 | 10 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 30 | 50 |
| 合计 | 690 | 710 |
看上去题目不难,基础的文件读入读出,对字符串的一些处理
就只有怎么判定相似度对我来说是个黑盒,查阅资料我试了三种方法;
(1)拥抱开源,CSDN上一种算法原模原样用下来:
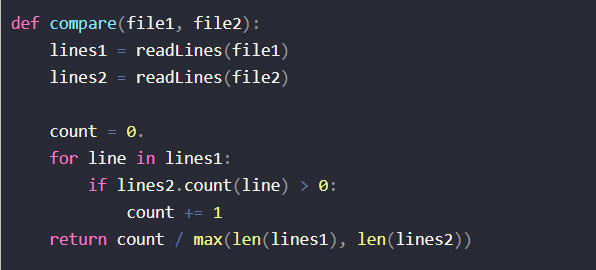
然后我的查重率就爆了,没一个低于95的,划掉。
(2)在查资料时发现python自带一种查重方法,如下:

然后我的查重率还是爆了,比上一个好了一点点点点,所以划掉
(3)之前在某门课上有听过余弦相似度这个说法,就尝试了一下
相似度还是高,但是好了一些,所以我决定遵从柯老板的指令
对算法进行亿点点优化
详情就在下面慢慢说
三、计算模块接口的设计与实现过程
主要函数有三个,clear()函数做字符串处理,TF()函数做分词,以及coscompare()函数做文本比较
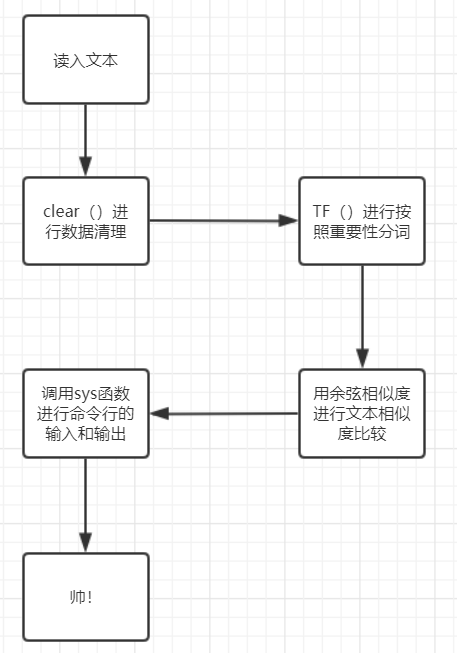
clear:
def clear(filepath):
with open(filepath, 'r', encoding='utf-8') as f:
lines = f.readlines()
lines1 = ''.join(lines)
punc = '~!#$%^&*()_+-=|\';":/.,?><~·!@#¥%……&*()——+-=“:’;、。,?》《{}'
s = re.sub(r"[%s]+" % punc, "", lines1)
res = []
for line in s:
a = line.split()
a_res = ''.join(a)
res.append(a_res)
res_res = ''.join(res)
return res_res
这样就通过正则把所有恶意添加的标点符号还有空格给去掉了
TF():
def TF(txt):
# 把处理好的文本进行分词,分词个数按照字数决定
len_in = len(txt)
if len_in < 40:
topk = round(len_in / 4) + 1
elif 400 > len_in >= 40:
topk = round(len_in / 10) + 1
elif 2000 > len_in >= 400:
topk = round(len_in / 20) + 1
else:
topk = round(len_in / 40)
key_word = jieba.analyse.extract_tags(txt, topK=topk, withWeight=False)
return key_word
在关键词个数上我考虑了一段时间,本来想要设定500个,一瞬间突然醒悟过来,给的样例是9000字小散文,那测试样例又不一定
要是测试样例是20字的句子,用500个词那不是着了道了,所以就按照文章的长度来决定关键词数量
coscompare():
def coscompare(res1_tf, res2_tf):
# 计算分好的词的余弦相似度
s1_cut = res1_tf
s2_cut = res2_tf
word_set = set(s1_cut).union(set(s2_cut))
word_dict = dict()
i = 0
for word in word_set:
word_dict[word] = i
i += 1
len1 = len(word_dict)
s1_code = [0] * len1
s2_code = [0] * len1
for word in s1_cut:
s1_code[word_dict[word]] += 1
for word in s2_cut:
s2_code[word_dict[word]] += 1
sum = 0
sq1 = 0
sq2 = 0
for i in range(len(s2_code)):
sum += s1_code[i] * s2_code[i]
sq1 += pow(s1_code[i], 2)
sq2 += pow(s2_code[i], 2)
res = round((float(sum) / (math.sqrt(sq1) * math.sqrt(sq2))), 2)
return res
余弦相似度的黑盒破解:
就是把分好词的两个列表转换成集合,再求出两个集合的并集,把并集中的词用字典排序,然后就可以算出词是否出现以及出现的数量,
并且把结果保存在向量中,用两个向量进行相似度求解(胡言乱语)
算法的关键自然就是余弦相似度了,但是单纯的余弦相似度并不适用与这一道题,因为样例中很多是为了测试而可以改出来的,正常抄论文谁这么抄啊。
至于独特的地方可能就是独特的分词函数和关键词数量的计算。
四、计算模块接口部分的性能改进
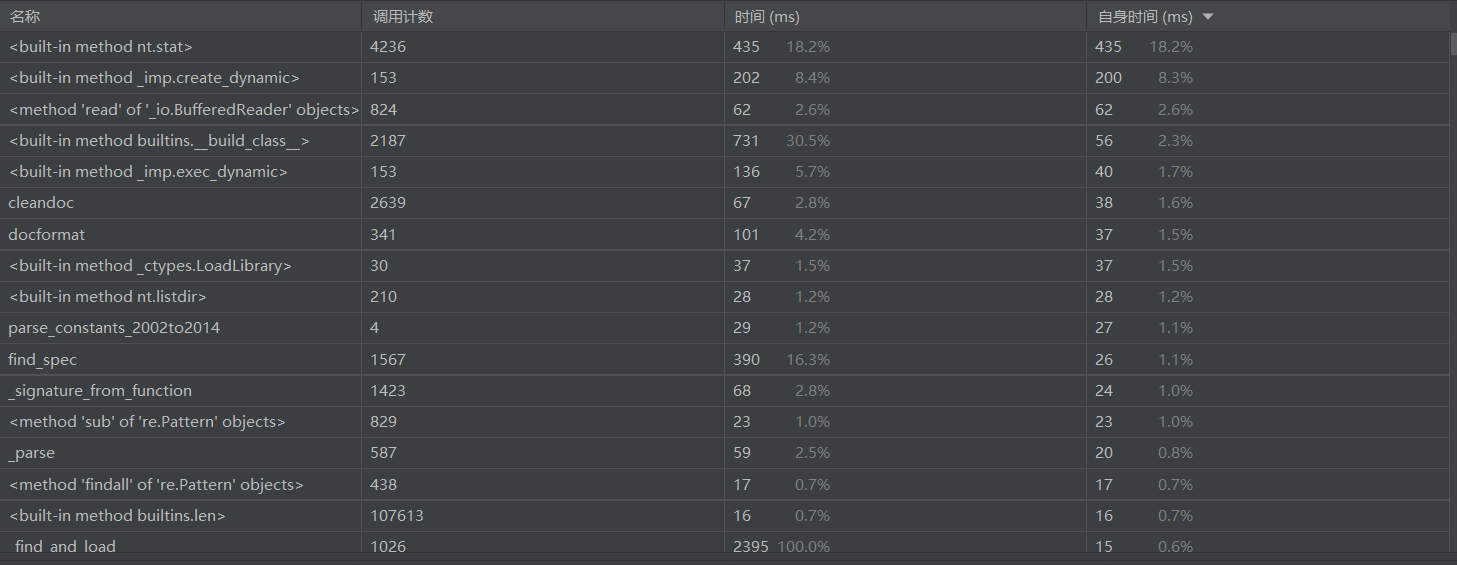
总时间如下
怎么说呢,时间上小的超出我的想象,可以是因为过于简陋,但还是比较满意了
五、计算模块部分单元测试展示
软工真的算法实现不是最花时间的地方,这个单元模块测试也折磨了我一会儿,class有关的东西是在java课上学的
早就全都还给老师了,这也算是复习了一下类的调用和引入。
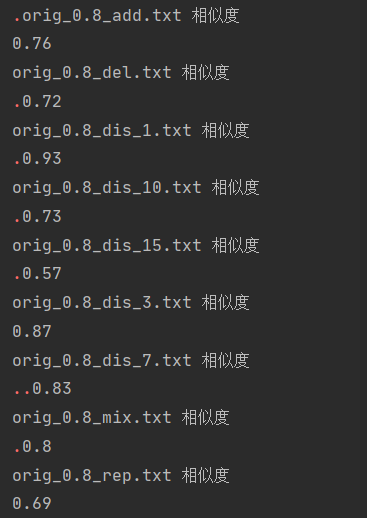
测试结果如上,除了极少数偏差之外,大多都是在80附近浮动,我对这个结果还算满意,因为当我打开偏差最大的文档看见繁体文言文的时候
我就觉得这有点超出我的能力范畴
测试程序如下:写法上有略微的借鉴
就是把前面写好的main函数封装成class,然后在测试文件中进行调用
import unittest
from 软工.specialTest import Testt
class MyTest(unittest.TestCase):
def test_add(self):
orig = 'sim_0.8/orig.txt'
filepath = "sim_0.8/orig_0.8_add.txt"
res_1 = Testt.cclear(orig, filepath)
res_final = str(res_1)
print("orig_0.8_add.txt 相似度")
print(res_final)
def test_del(self):
print("orig_0.8_del.txt 相似度")
orig = 'sim_0.8/orig.txt'
filepath = "sim_0.8/orig_0.8_del.txt"
res_1 = Testt.cclear(orig, filepath)
res_final = str(res_1)
print(res_final)
def test_dis_1(self):
print("orig_0.8_dis_1.txt 相似度")
orig = 'sim_0.8/orig.txt'
filepath = "sim_0.8/orig_0.8_dis_1.txt"
res_1 = Testt.cclear(orig, filepath)
res_final = str(res_1)
print(res_final)
def test_dis_3(self):
print("orig_0.8_dis_3.txt 相似度")
orig = 'sim_0.8/orig.txt'
filepath = "sim_0.8/orig_0.8_dis_3.txt"
res_1 = Testt.cclear(orig, filepath)
res_final = str(res_1)
print(res_final)
def test_dis_7(self):
print("orig_0.8_dis_7.txt 相似度")
orig = 'sim_0.8/orig.txt'
filepath = "sim_0.8/orig_0.8_dis_7.txt"
res_1 = Testt.cclear(orig, filepath)
res_final = str(res_1)
print(res_final)
def test_dis_10(self):
print("orig_0.8_dis_10.txt 相似度")
orig = 'sim_0.8/orig.txt'
filepath = "sim_0.8/orig_0.8_dis_10.txt"
res_1 = Testt.cclear(orig, filepath)
res_final = str(res_1)
print(res_final)
def test_dis_15(self):
print("orig_0.8_dis_15.txt 相似度")
orig = 'sim_0.8/orig.txt'
filepath = "sim_0.8/orig_0.8_dis_15.txt"
res_1 = Testt.cclear(orig, filepath)
res_final = str(res_1)
print(res_final)
def test_mix(self):
print("orig_0.8_mix.txt 相似度")
orig = 'sim_0.8/orig.txt'
filepath = "sim_0.8/orig_0.8_mix.txt"
res_1 = Testt.cclear(orig, filepath)
res_final = str(res_1)
print(res_final)
def test_rep(self):
print("orig_0.8_rep.txt 相似度")
orig = 'sim_0.8/orig.txt'
filepath = "sim_0.8/orig_0.8_rep.txt"
res_1 = Testt.cclear(orig, filepath)
res_final = str(res_1)
print(res_final)
if __name__ == '__main__':
unittest.main()
将单元测试得到的测试覆盖率截图,如下,
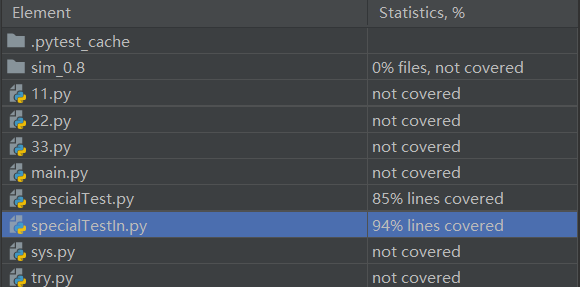
两个Test,前一个是main函数的改版,后一个就是上面贴出来的函数了,覆盖率蛮高的
第一个文件85覆盖率是因为我在前文写的按照文本字数分关键字个数几乎全部冒红,但我觉得这部分是有用的,所以只能85%了
第二个则是个别的黄色,不太在意
六、计算模块部分异常处理说明
本来是不太懂这什么意思,看了几篇先发同学的博客后知道,这好像就是自己去想这个程序可能哪里有错
我能想到的就是,全文不是汉字这一种
异常处理如下:
class NoChinese(Exception):
def __init__(self):
print("无汉字")
res = open(sys.argv[3], 'w', encoding='UTF-8')
res_res = str(0.00)
res.write(res_res)
res.close()
就这就这
七、总结
软工实验做的很累,收获也很多,真的像柯老板说的那样,打代码用的时间不到30%,上周就打好了代码,以为可以摸鱼了,没想到一堆从没有接触过的东西在等着我
为了分析还用学生邮箱白嫖了个pycharm专业版本,git的上传也弄了半天,害。
下次一定先想明白了再打,算法都跑出来了一分析发现不对,全部删了重新改了有两次,得劲嗷。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号