
第二次作业:卷积神经网络 part 1
------------恢复内容开始------------
1. 视频学习
-
深度学习的数学基础
-
自编码器变种包括
正则自编码器,稀疏自编码器,去噪自编码器,变分自编码器
-
数学基础
线性代数(数据表示、空间变换的基础)
概率论统计(模型假设、策略设计的基础)
最优化(求解目标函数的具体算法)
信息论
微积分
-
神经网络在“学”什么
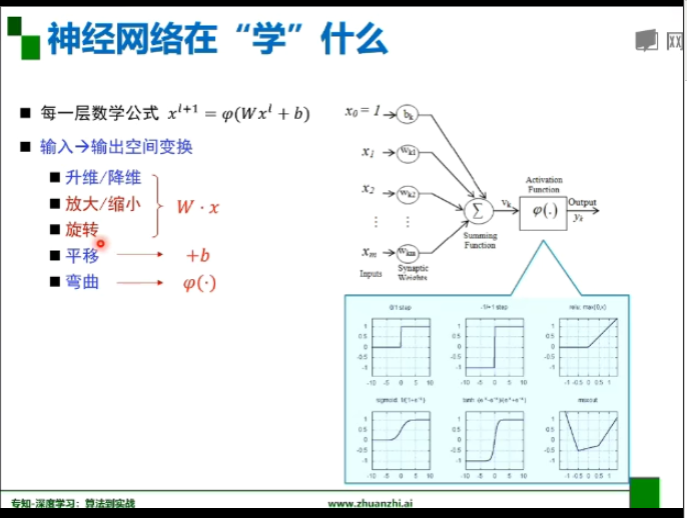

任意一个向量,只要乘A的次数足够多,就会到矩阵的最大特征值所对应的特征向量的方向上去。
秩越小,基越小,数据分布模式越容易被捕捉。数据冗余度越大,需要的基就越少,秩越小。(下图中r为秩的大小)

使用n*r+r*r+r*d来进行降维操作
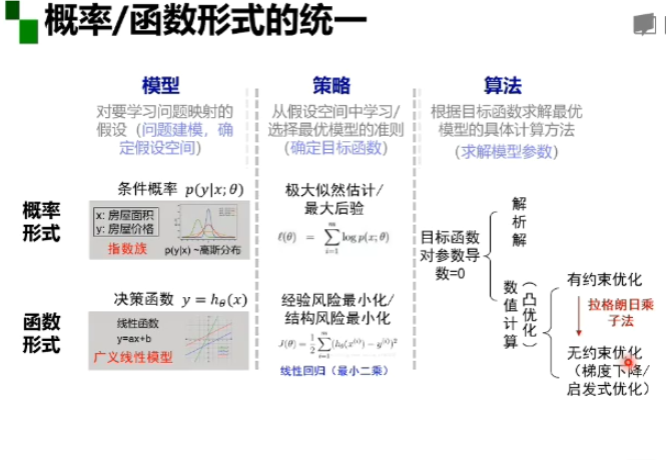
概率形式和函数形式是一一对应的关系(吴恩达 模型:假设函数 ;策略:J(θ) ;算法:梯度下降算法,使J取最小值,即假设函数与真实数据差做小)
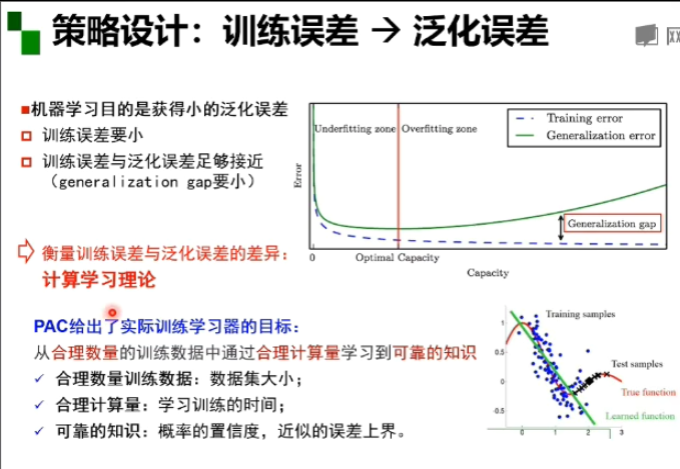
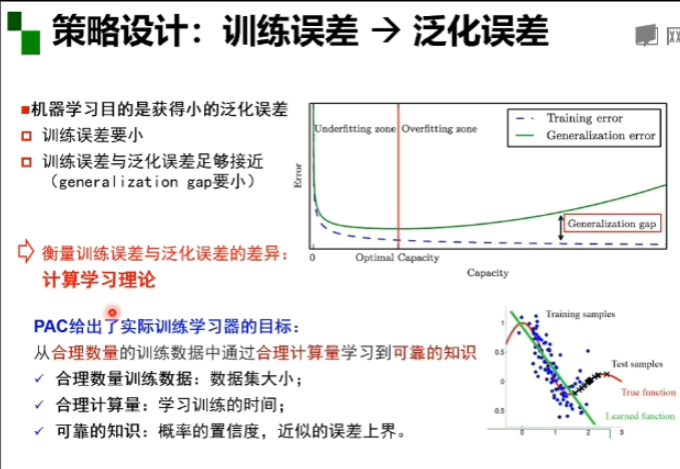
训练误差小比较容易实现 训练误差与泛化误差足够接近难实现
策略设计定理:1,无免费早餐定理(没有一个模型可以在所有的学习任务里表现最好)
2,奥卡姆剃刀原理(如无必要,勿增实体。如果多种模型能同等程度的符合一个问题的观测结果,应该选择其中使用假设最少的,即最简单的模型)

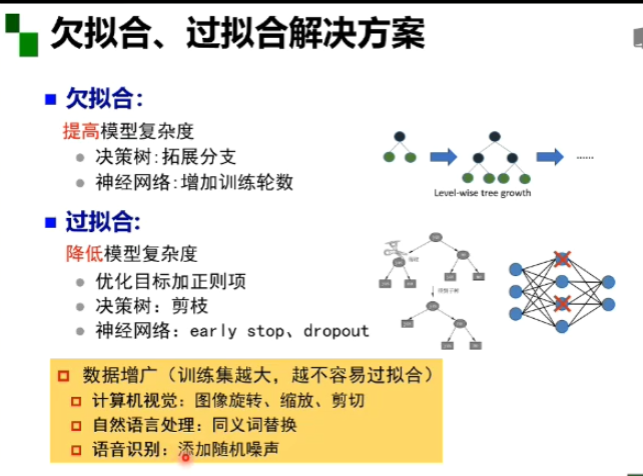

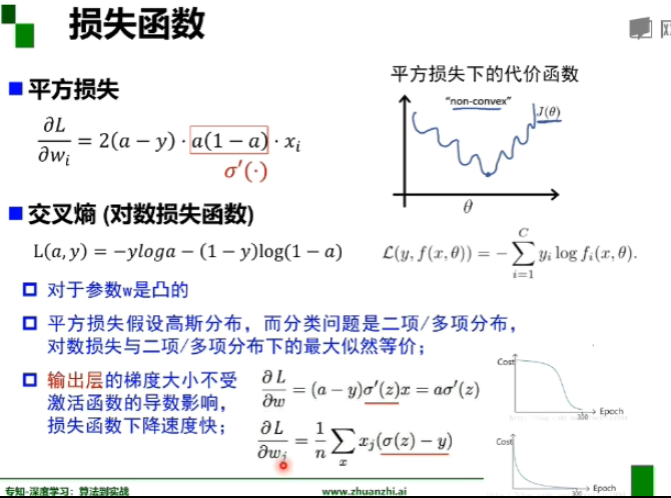
平方损失对于分类问题并不友好,而对数损失函数更适合,蓝字的三条都是对数损失函数的优点,激活函数用relu。平方损失是常用的回归损失算法,交叉熵损失是常用的分类损失算法。


-
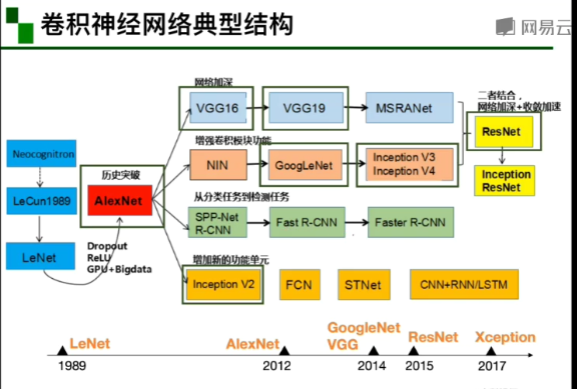
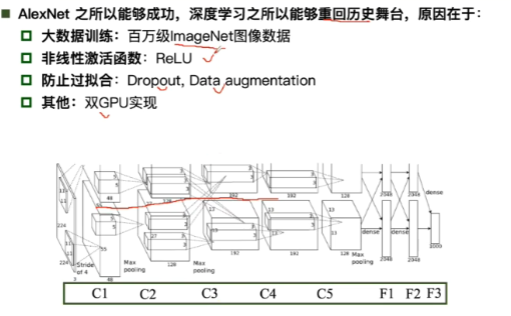
卷积神经网络
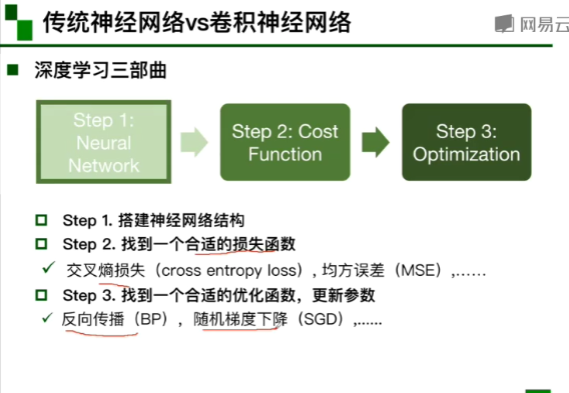
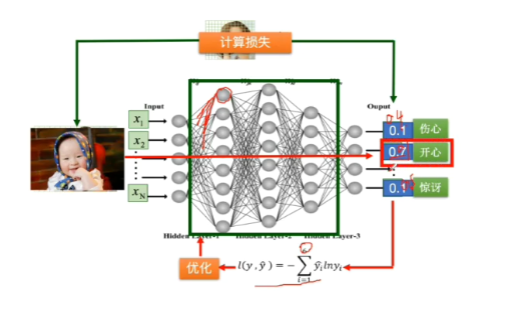
1,输入,传统神经网络给出预测 2,计算与真实情况的损失 3,进行优化 4,优化结束后,确定参数并且用新的例子进行测试。(传统神经网络是全连接)
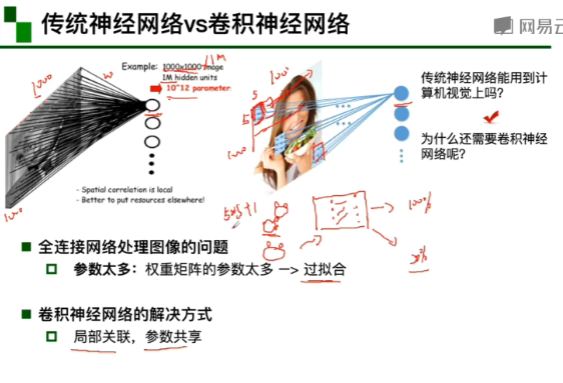
卷积神经网络处理的参数很少
全连接需要的参数:1000*1000 卷积需要的参数:因为参数共享 所以一个5*5的卷积核中虽然输入一直在移动但是参数值不变,个数是5*5,所以需要的参数为5*5+1(1位偏执项的值),若有十个卷积核,则需要参数量为10*(5*5+1)。

这些层都有用到,是各个层互相连接的

卷积层:一维卷积
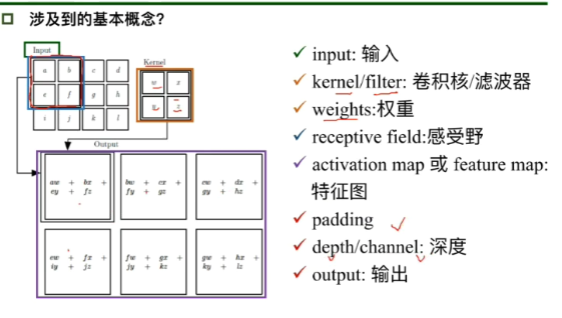

卷积层:二维卷积。由输入到特征图的计算方法是右下角红字的方法,步长为1的意思是每次只向右移动宽度为1的距离。
卷积核中参数的确定,先是随机出现,然后根据反馈进行修改。
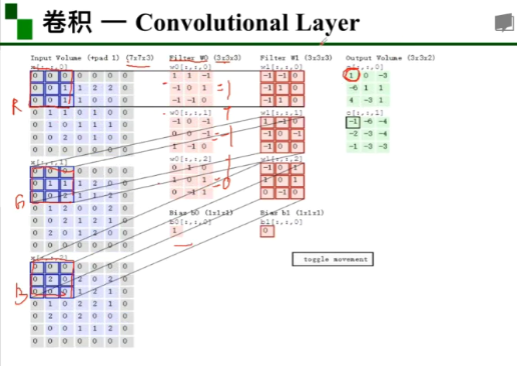
一个彩色图像分成RGB三层,有两组卷积核,每一组为3*3*3,每组卷积核中分别对应RGB有三个卷积核,因为有两组卷积核,所以最后的特征图有两个该卷积depth/channel为2。
特征图中每一小格的计算方法是R与相对应卷积核计算得到一个值,同时G,B也会得到一个值,三个值相加再加上每组卷积核下面的那个数(b)就得到第一个特征图中的数值,接着按照步数移动,计算下一个数值。

若是绿色部分很明显每一行最后只剩下一竖列,不够往下移动,填充padding之后就可以了,不管步长是多少,往下移动的时候都只移动一个横格。
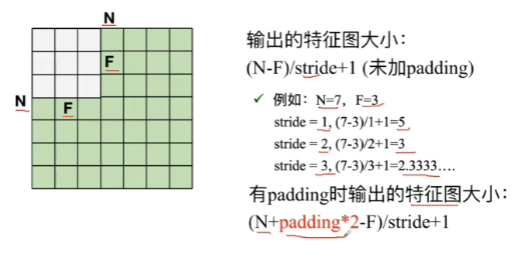
N:输入是7*7 F:卷积核是3*3

e.g 6 5*5*3 (六组5*5*3的卷积核)所以depth为6

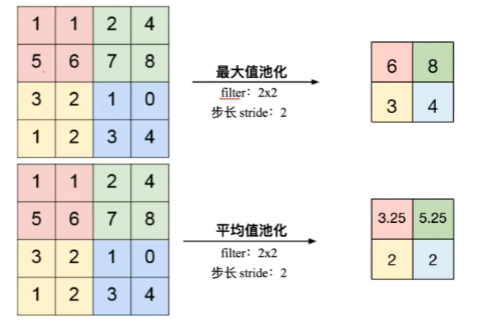
filter:每次在多大的范围内进行池化 分类问题使用最大值池化效果比较好
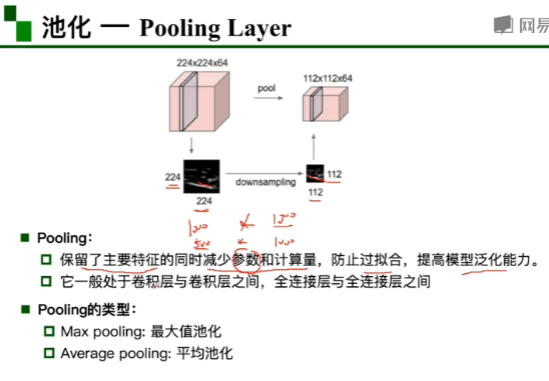



激活函数对特征图中的每一个值都需要处理 sigmoid函数两端求导为零,就会导致参数更新不动。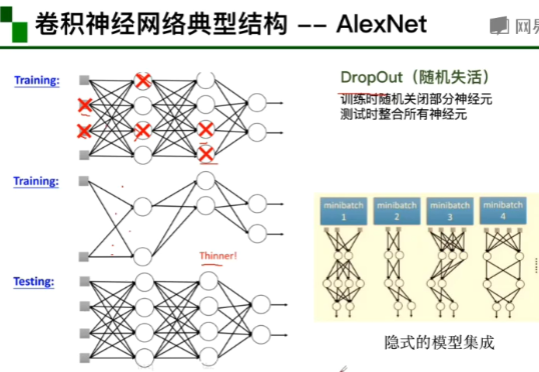

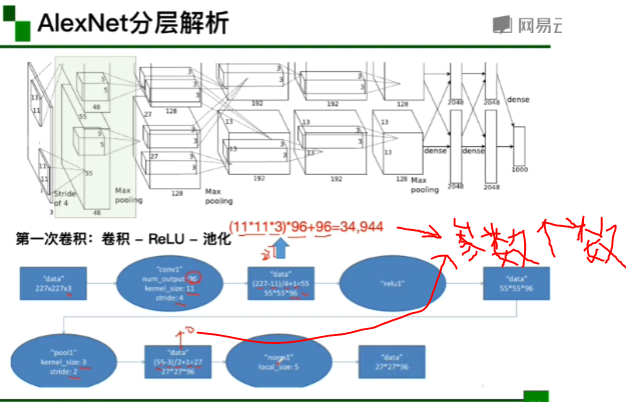
池化层的参数为0
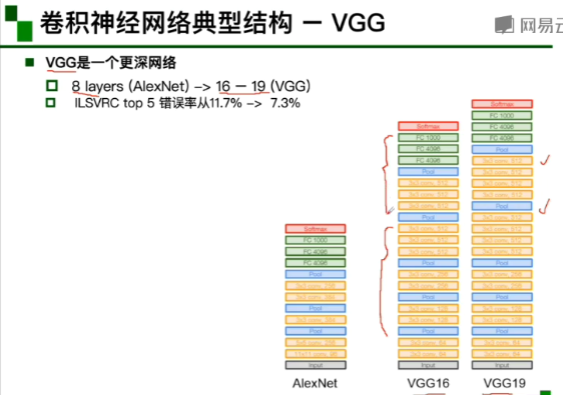
FC层:全连接层
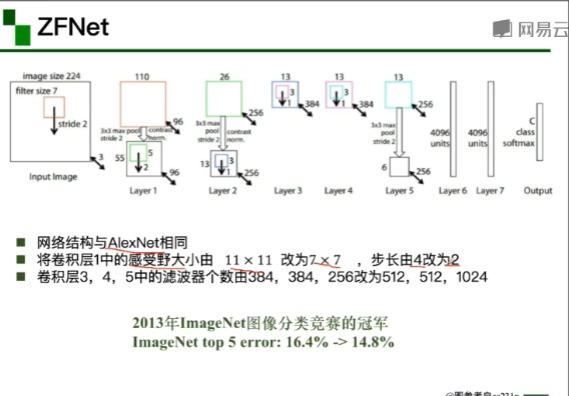
使用多卷积核增加特征多样性
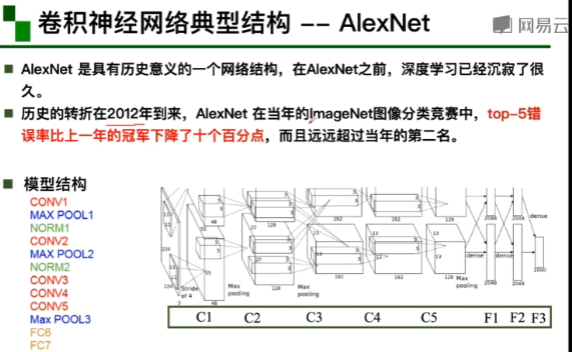
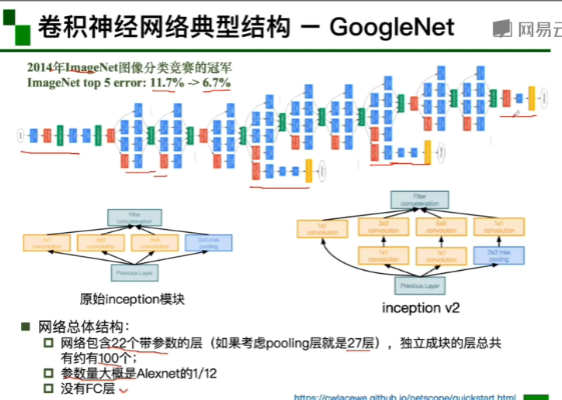
GoogleNet的组成(从前往后):1,stem部分:卷积-池化-卷积-卷积-池化
2,多个inception结构堆叠 3,输出:没有额外的全连接层(除了最后的类别输出层)4,辅助分类器(就是下面那两个黄的):解决由于模型深度过深导致的梯度消失的问题。
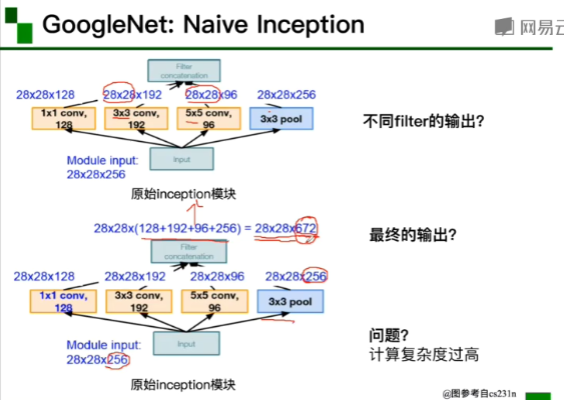
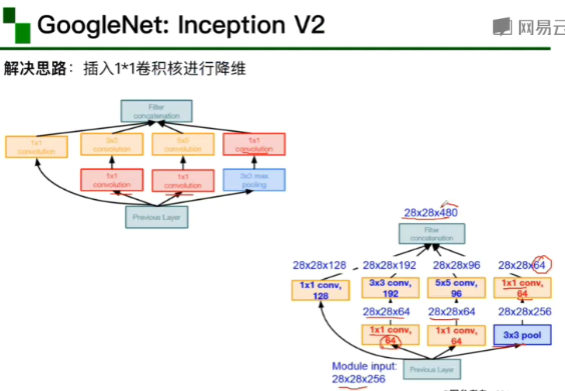
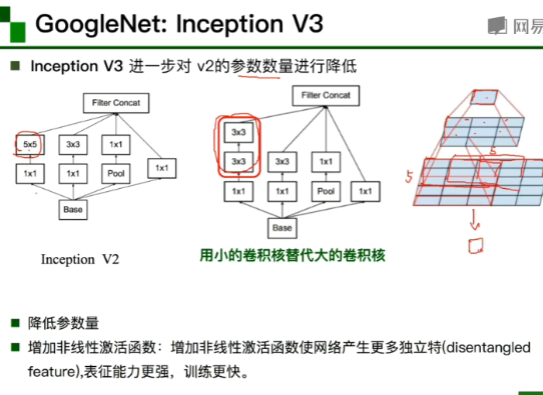
用两个3*3代替一个5*5的卷积核

-
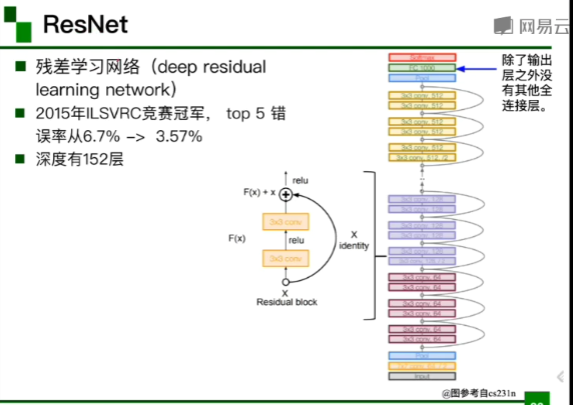
京东专家结合 pytorch 代码讲解 ResNet

ResNet的网络结构图。
152层的ResNet由5个stage组成->每个stage由若干block组成->block由若干个卷积层(layer)组成
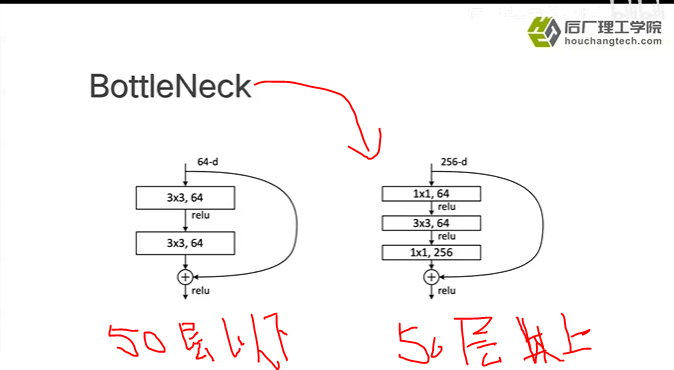
左边是50层以下的ResNet 右边是50层以上的ResNet 主要区别是50层以上用的是bottleneck结构(瓶颈)


import torch import torch.nn as nn from .utils import load_state_dict_from_url __all__ = ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152', 'resnext50_32x4d', 'resnext101_32x8d', 'wide_resnet50_2', 'wide_resnet101_2'] model_urls = { 'resnet18': 'https://download.pytorch.org/models/resnet18-5c106cde.pth', 'resnet34': 'https://download.pytorch.org/models/resnet34-333f7ec4.pth', 'resnet50': 'https://download.pytorch.org/models/resnet50-19c8e357.pth', 'resnet101': 'https://download.pytorch.org/models/resnet101-5d3b4d8f.pth', 'resnet152': 'https://download.pytorch.org/models/resnet152-b121ed2d.pth', 'resnext50_32x4d': 'https://download.pytorch.org/models/resnext50_32x4d-7cdf4587.pth', 'resnext101_32x8d': 'https://download.pytorch.org/models/resnext101_32x8d-8ba56ff5.pth', 'wide_resnet50_2': 'https://download.pytorch.org/models/wide_resnet50_2-95faca4d.pth', 'wide_resnet101_2': 'https://download.pytorch.org/models/wide_resnet101_2-32ee1156.pth', } def conv3x3(in_planes, out_planes, stride=1, groups=1, dilation=1): """3x3 convolution with padding""" return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=dilation, groups=groups, bias=False, dilation=dilation) def conv1x1(in_planes, out_planes, stride=1): """1x1 convolution""" return nn.Conv2d(in_planes, out_planes, kernel_size=1, stride=stride, bias=False) class BasicBlock(nn.Module): expansion = 1 def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1, base_width=64, dilation=1, norm_layer=None): super(BasicBlock, self).__init__() if norm_layer is None: norm_layer = nn.BatchNorm2d if groups != 1 or base_width != 64: raise ValueError('BasicBlock only supports groups=1 and base_width=64') if dilation > 1: raise NotImplementedError("Dilation > 1 not supported in BasicBlock") # Both self.conv1 and self.downsample layers downsample the input when stride != 1 self.conv1 = conv3x3(inplanes, planes, stride) self.bn1 = norm_layer(planes) self.relu = nn.ReLU(inplace=True) self.conv2 = conv3x3(planes, planes) self.bn2 = norm_layer(planes) self.downsample = downsample self.stride = stride def forward(self, x): identity = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) if self.downsample is not None: identity = self.downsample(x) out += identity out = self.relu(out) return out class Bottleneck(nn.Module): # Bottleneck in torchvision places the stride for downsampling at 3x3 convolution(self.conv2) # while original implementation places the stride at the first 1x1 convolution(self.conv1) # according to "Deep residual learning for image recognition"https://arxiv.org/abs/1512.03385. # This variant is also known as ResNet V1.5 and improves accuracy according to # https://ngc.nvidia.com/catalog/model-scripts/nvidia:resnet_50_v1_5_for_pytorch. expansion = 4 def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1, base_width=64, dilation=1, norm_layer=None): super(Bottleneck, self).__init__() if norm_layer is None: norm_layer = nn.BatchNorm2d width = int(planes * (base_width / 64.)) * groups # Both self.conv2 and self.downsample layers downsample the input when stride != 1 self.conv1 = conv1x1(inplanes, width) self.bn1 = norm_layer(width) self.conv2 = conv3x3(width, width, stride, groups, dilation) self.bn2 = norm_layer(width) self.conv3 = conv1x1(width, planes * self.expansion) self.bn3 = norm_layer(planes * self.expansion) self.relu = nn.ReLU(inplace=True) self.downsample = downsample self.stride = stride def forward(self, x): identity = x out = self.conv1(x) out = self.bn1(out) out = self.relu(out) out = self.conv2(out) out = self.bn2(out) out = self.relu(out) out = self.conv3(out) out = self.bn3(out) if self.downsample is not None: identity = self.downsample(x) out += identity out = self.relu(out) return out class ResNet(nn.Module): def __init__(self, block, layers, num_classes=1000, zero_init_residual=False, groups=1, width_per_group=64, replace_stride_with_dilation=None, norm_layer=None): super(ResNet, self).__init__() if norm_layer is None: norm_layer = nn.BatchNorm2d self._norm_layer = norm_layer self.inplanes = 64 self.dilation = 1 if replace_stride_with_dilation is None: # each element in the tuple indicates if we should replace # the 2x2 stride with a dilated convolution instead replace_stride_with_dilation = [False, False, False] if len(replace_stride_with_dilation) != 3: raise ValueError("replace_stride_with_dilation should be None " "or a 3-element tuple, got {}".format(replace_stride_with_dilation)) self.groups = groups self.base_width = width_per_group self.conv1 = nn.Conv2d(3, self.inplanes, kernel_size=7, stride=2, padding=3, bias=False) self.bn1 = norm_layer(self.inplanes) self.relu = nn.ReLU(inplace=True) self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1) self.layer1 = self._make_layer(block, 64, layers[0]) self.layer2 = self._make_layer(block, 128, layers[1], stride=2, dilate=replace_stride_with_dilation[0]) self.layer3 = self._make_layer(block, 256, layers[2], stride=2, dilate=replace_stride_with_dilation[1]) self.layer4 = self._make_layer(block, 512, layers[3], stride=2, dilate=replace_stride_with_dilation[2]) self.avgpool = nn.AdaptiveAvgPool2d((1, 1)) self.fc = nn.Linear(512 * block.expansion, num_classes) for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu') elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)): nn.init.constant_(m.weight, 1) nn.init.constant_(m.bias, 0) # Zero-initialize the last BN in each residual branch, # so that the residual branch starts with zeros, and each residual block behaves like an identity. # This improves the model by 0.2~0.3% according to https://arxiv.org/abs/1706.02677 if zero_init_residual: for m in self.modules(): if isinstance(m, Bottleneck): nn.init.constant_(m.bn3.weight, 0) elif isinstance(m, BasicBlock): nn.init.constant_(m.bn2.weight, 0) def _make_layer(self, block, planes, blocks, stride=1, dilate=False): norm_layer = self._norm_layer downsample = None previous_dilation = self.dilation if dilate: self.dilation *= stride stride = 1 if stride != 1 or self.inplanes != planes * block.expansion: downsample = nn.Sequential( conv1x1(self.inplanes, planes * block.expansion, stride), norm_layer(planes * block.expansion), ) layers = [] layers.append(block(self.inplanes, planes, stride, downsample, self.groups, self.base_width, previous_dilation, norm_layer)) self.inplanes = planes * block.expansion for _ in range(1, blocks): layers.append(block(self.inplanes, planes, groups=self.groups, base_width=self.base_width, dilation=self.dilation, norm_layer=norm_layer)) return nn.Sequential(*layers) def _forward_impl(self, x): # See note [TorchScript super()] x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) x = torch.flatten(x, 1) x = self.fc(x) return x def forward(self, x): return self._forward_impl(x) def _resnet(arch, block, layers, pretrained, progress, **kwargs): model = ResNet(block, layers, **kwargs) if pretrained: state_dict = load_state_dict_from_url(model_urls[arch], progress=progress) model.load_state_dict(state_dict) return model def resnet18(pretrained=False, progress=True, **kwargs): r"""ResNet-18 model from `"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_ Args: pretrained (bool): If True, returns a model pre-trained on ImageNet progress (bool): If True, displays a progress bar of the download to stderr """ return _resnet('resnet18', BasicBlock, [2, 2, 2, 2], pretrained, progress, **kwargs) def resnet34(pretrained=False, progress=True, **kwargs): r"""ResNet-34 model from `"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_ Args: pretrained (bool): If True, returns a model pre-trained on ImageNet progress (bool): If True, displays a progress bar of the download to stderr """ return _resnet('resnet34', BasicBlock, [3, 4, 6, 3], pretrained, progress, **kwargs) def resnet50(pretrained=False, progress=True, **kwargs): r"""ResNet-50 model from `"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_ Args: pretrained (bool): If True, returns a model pre-trained on ImageNet progress (bool): If True, displays a progress bar of the download to stderr """ return _resnet('resnet50', Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs) def resnet101(pretrained=False, progress=True, **kwargs): r"""ResNet-101 model from `"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_ Args: pretrained (bool): If True, returns a model pre-trained on ImageNet progress (bool): If True, displays a progress bar of the download to stderr """ return _resnet('resnet101', Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs) def resnet152(pretrained=False, progress=True, **kwargs): r"""ResNet-152 model from `"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_ Args: pretrained (bool): If True, returns a model pre-trained on ImageNet progress (bool): If True, displays a progress bar of the download to stderr """ return _resnet('resnet152', Bottleneck, [3, 8, 36, 3], pretrained, progress, **kwargs) def resnext50_32x4d(pretrained=False, progress=True, **kwargs): r"""ResNeXt-50 32x4d model from `"Aggregated Residual Transformation for Deep Neural Networks" <https://arxiv.org/pdf/1611.05431.pdf>`_ Args: pretrained (bool): If True, returns a model pre-trained on ImageNet progress (bool): If True, displays a progress bar of the download to stderr """ kwargs['groups'] = 32 kwargs['width_per_group'] = 4 return _resnet('resnext50_32x4d', Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs) def resnext101_32x8d(pretrained=False, progress=True, **kwargs): r"""ResNeXt-101 32x8d model from `"Aggregated Residual Transformation for Deep Neural Networks" <https://arxiv.org/pdf/1611.05431.pdf>`_ Args: pretrained (bool): If True, returns a model pre-trained on ImageNet progress (bool): If True, displays a progress bar of the download to stderr """ kwargs['groups'] = 32 kwargs['width_per_group'] = 8 return _resnet('resnext101_32x8d', Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs) def wide_resnet50_2(pretrained=False, progress=True, **kwargs): r"""Wide ResNet-50-2 model from `"Wide Residual Networks" <https://arxiv.org/pdf/1605.07146.pdf>`_ The model is the same as ResNet except for the bottleneck number of channels which is twice larger in every block. The number of channels in outer 1x1 convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048 channels, and in Wide ResNet-50-2 has 2048-1024-2048. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet progress (bool): If True, displays a progress bar of the download to stderr """ kwargs['width_per_group'] = 64 * 2 return _resnet('wide_resnet50_2', Bottleneck, [3, 4, 6, 3], pretrained, progress, **kwargs) def wide_resnet101_2(pretrained=False, progress=True, **kwargs): r"""Wide ResNet-101-2 model from `"Wide Residual Networks" <https://arxiv.org/pdf/1605.07146.pdf>`_ The model is the same as ResNet except for the bottleneck number of channels which is twice larger in every block. The number of channels in outer 1x1 convolutions is the same, e.g. last block in ResNet-50 has 2048-512-2048 channels, and in Wide ResNet-50-2 has 2048-1024-2048. Args: pretrained (bool): If True, returns a model pre-trained on ImageNet progress (bool): If True, displays a progress bar of the download to stderr """ kwargs['width_per_group'] = 64 * 2 return _resnet('wide_resnet101_2', Bottleneck, [3, 4, 23, 3], pretrained, progress, **kwargs)
2. 代码练习
-
MNIST 数据集分类
import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim from torchvision import datasets,transforms import matplotlib.pyplot as plt import numpy #一个用来计算模型中有多少参数的函数 p.nelement()返回参数的个数 def get_n_params(model): np=0 for p in list(model.parameters()): np+=p.nelement() return np #使用GPU训练,可以在菜单 "代码执行程序"-> "更改运行时类型" 里进行设置 device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu") #加载数据 (MNIST) input_size =28*28 #MNIST上的图像尺寸是28*28 output_size= 10 #类别为0到9的数字,因此为十类 train_loader = torch.utils.data.DataLoader( datasets.MNIST('./data',train=True,download=True, transform=transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,))])), batch_size=64,shuffle=True ) test_loader=torch.utils.data.DataLoader( datasets.MNIST('./data',train=False, transform=transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.1307,),(0.3081,))])), batch_size=1000,shuffle=True ) #显示数据集中的部分图像 plt.figure(figsize=(8,5)) for i in range(20): plt.subplot(4,5,i+1) image,_=train_loader.dataset.__getitem__(i) plt.imshow(image.squeeze().numpy(),'gray') plt.axis('off');

#创建网络 kernel_size表示过滤器的大小 batch_size样本数 #nn.linear(输入特征值数,输出特征值数)表示全连接 #F.log_softmax(x, dim=1) #dim=0:对每一列的所有元素进行softmax运算,并使得每一列所有元素和为1。再进行Log(Softmax(x)) #dim=1:对每一行的所有元素进行softmax运算,并使得每一行所有元素和为1.Log(Softmax(x)) class FC2Layer(nn.Module): def __init__(self,input_size,n_hidden,output_size): # nn.Module子类的函数必须在构造函数中执行父类的构造函数 # 下式等价于nn.Module.__init__(self) super(FC2Layer,self).__init__() self.input_size=input_size # 这里直接用 Sequential 就定义了网络,注意要和下面 CNN 的代码区分开 self.network=nn.Sequential( nn.Linear(input_size,n_hidden), nn.ReLU(), nn.Linear(n_hidden,n_hidden), nn.ReLU(), nn.Linear(n_hidden,output_size), nn.LogSoftmax(dim=1) ) def forward(self,x): # view一般出现在model类的forward函数中,用于改变输入或输出的形状 # x.view(-1, self.input_size) 的意思是多维的数据展成二维 # 代码指定二维数据的列数为 input_size=784,行数 -1 表示我们不想算,电脑会自己计算对应的数字 # 在 DataLoader 部分,我们可以看到 batch_size 是64,所以得到 x 的行数是64 # 大家可以加一行代码:print(x.cpu().numpy().shape) # 训练过程中,就会看到 (64, 784) 的输出,和我们的预期是一致的 # forward 函数的作用是,指定网络的运行过程,这个全连接网络可能看不啥意义, # 下面的CNN网络可以看出 forward 的作用。 x=x.view(-1,self.input_size) return self.network(x) class CNN(nn.Module): def __init__(self,input_size,n_feature,output_size): # 执行父类的构造函数,所有的网络都要这么写 super(CNN,self).__init__() # 下面是网络里典型结构的一些定义,一般就是卷积和全连接 # 池化、ReLU一类的不用在这里定义 self.n_feature=n_feature self.conv1=nn.Conv2d(in_channels=1,out_channels=n_feature, kernel_size=5) self.conv2=nn.Conv2d(n_feature, n_feature, kernel_size=5) self.fc1 = nn.Linear(n_feature*4*4, 50) self.fc2 = nn.Linear(50, 10) # 下面的 forward 函数,定义了网络的结构,按照一定顺序,把上面构建的一些结构组织起来 # 意思就是,conv1, conv2 等等的,可以多次重用 def forward(self, x, verbose=False): x=self.conv1(x) x=F.relu(x) x = F.max_pool2d(x, kernel_size=2) x = self.conv2(x) x = F.relu(x) x = F.max_pool2d(x, kernel_size=2) x = x.view(-1, self.n_feature*4*4) x = self.fc1(x) x = F.relu(x) x = self.fc2(x) x = F.log_softmax(x, dim=1) return x # 训练函数 def train(model): model.train() # 从train_loader里,64个样本一个batch为单位提取样本进行训练 for batch_idx, (data, target) in enumerate(train_loader): # 把数据送到GPU中 data, target = data.to(device), target.to(device) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % 100 == 0: print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) def test(model): model.eval() test_loss = 0 correct = 0 for data, target in test_loader: # 把数据送到GPU中 data, target = data.to(device), target.to(device) # 把数据送入模型,得到预测结果 output = model(data) # 计算本次batch的损失,并加到 test_loss 中 test_loss += F.nll_loss(output, target, reduction='sum').item() # get the index of the max log-probability,最后一层输出10个数, # 值最大的那个即对应着分类结果,然后把分类结果保存在 pred 里 pred = output.data.max(1, keepdim=True)[1] # 将 pred 与 target 相比,得到正确预测结果的数量,并加到 correct 中 # 这里需要注意一下 view_as ,意思是把 target 变成维度和 pred 一样的意思 correct += pred.eq(target.data.view_as(pred)).cpu().sum().item() test_loss /= len(test_loader.dataset) accuracy = 100. * correct / len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), accuracy)) #在小型全连接网络上训练(Fully-connected network) n_hidden = 8 # number of hidden units model_fnn = FC2Layer(input_size, n_hidden, output_size) model_fnn.to(device) optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5) print('Number of parameters: {}'.format(get_n_params(model_fnn))) train(model_fnn) test(model_fnn)

#在卷积神经网络上训练 n_features = 6 # number of feature maps model_cnn = CNN(input_size, n_features, output_size) model_cnn.to(device) optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5) print('Number of parameters: {}'.format(get_n_params(model_cnn))) train(model_cnn) test(model_cnn)

#打乱像素顺序再次在两个网络上训练与测试 # 这里解释一下 torch.randperm 函数,给定参数n,返回一个从0到n-1的随机整数排列 #重新定义训练与测试函数,我们写了两个函数 train_perm 和 test_perm,分别对应着加入像素打乱顺序的训练函数与测试函数。 #与之前的训练与测试函数基本上完全相同,只是对 data 加入了打乱顺序操作。 perm = torch.randperm(784) plt.figure(figsize=(8, 4)) for i in range(10): image, _ = train_loader.dataset.__getitem__(i) # permute pixels image_perm = image.view(-1, 28*28).clone() image_perm = image_perm[:, perm] image_perm = image_perm.view(-1, 1, 28, 28) plt.subplot(4, 5, i + 1) plt.imshow(image.squeeze().numpy(), 'gray') plt.axis('off') plt.subplot(4, 5, i + 11) plt.imshow(image_perm.squeeze().numpy(), 'gray') plt.axis('off')

# 对每个 batch 里的数据,打乱像素顺序的函数 def perm_pixel(data, perm): # 转化为二维矩阵 data_new = data.view(-1, 28*28) # 打乱像素顺序 data_new = data_new[:, perm] # 恢复为原来4维的 tensor data_new = data_new.view(-1, 1, 28, 28) return data_new # 训练函数 def train_perm(model, perm): model.train() for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) # 像素打乱顺序 data = perm_pixel(data, perm) optimizer.zero_grad() output = model(data) loss = F.nll_loss(output, target) loss.backward() optimizer.step() if batch_idx % 100 == 0: print('Train: [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( batch_idx * len(data), len(train_loader.dataset), 100. * batch_idx / len(train_loader), loss.item())) # 测试函数 def test_perm(model, perm): model.eval() test_loss = 0 correct = 0 for data, target in test_loader: data, target = data.to(device), target.to(device) # 像素打乱顺序 data = perm_pixel(data, perm) output = model(data) test_loss += F.nll_loss(output, target, reduction='sum').item() pred = output.data.max(1, keepdim=True)[1] correct += pred.eq(target.data.view_as(pred)).cpu().sum().item() test_loss /= len(test_loader.dataset) accuracy = 100. * correct / len(test_loader.dataset) print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( test_loss, correct, len(test_loader.dataset), accuracy)) #在全连接网络上训练与测试: perm = torch.randperm(784) n_hidden = 8 # number of hidden units model_fnn = FC2Layer(input_size, n_hidden, output_size) model_fnn.to(device) optimizer = optim.SGD(model_fnn.parameters(), lr=0.01, momentum=0.5) print('Number of parameters: {}'.format(get_n_params(model_fnn))) train_perm(model_fnn, perm) test_perm(model_fnn, perm)

#在卷积神经网络上训练与测试: #从打乱像素顺序的实验结果来看,全连接网络的性能基本上没有发生变化 #但是 卷积神经网络的性能明显下降。 #这是因为对于卷积神经网络,会利用像素的局部关系 #但是打乱顺序以后,这些像素间的关系将无法得到利用。 perm = torch.randperm(784) n_features = 6 # number of feature maps model_cnn = CNN(input_size, n_features, output_size) model_cnn.to(device) optimizer = optim.SGD(model_cnn.parameters(), lr=0.01, momentum=0.5) print('Number of parameters: {}'.format(get_n_params(model_cnn))) train_perm(model_cnn, perm) test_perm(model_cnn, perm)

-
CIFAR10 数据集分类
import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np import torch.nn as nn import torch.nn.functional as F import torch.optim as optim # 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") transform = transforms.Compose( [transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]) # 注意下面代码中:训练的 shuffle 是 True,测试的 shuffle 是 false # 训练时可以打乱顺序增加多样性,测试是没有必要 trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform) trainloader = torch.utils.data.DataLoader(trainset, batch_size=64, shuffle=True, num_workers=2) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform) testloader = torch.utils.data.DataLoader(testset, batch_size=8, shuffle=False, num_workers=2) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
#展示 CIFAR10 里面的一些图片 def imshow(img): plt.figure(figsize=(8,8)) img = img / 2 + 0.5 # 转换到 [0,1] 之间 npimg = img.numpy() plt.imshow(np.transpose(npimg, (1, 2, 0))) plt.show() # 得到一组图像 images, labels = iter(trainloader).next() # 展示图像 imshow(torchvision.utils.make_grid(images)) # 展示第一行图像的标签 for j in range(8): print(classes[labels[j]])

#定义网络,损失函数和优化器 class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x # 网络放到GPU上 net = Net().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.001) #训练网络 for epoch in range(10): # 重复多轮训练 for i, (inputs, labels) in enumerate(trainloader): inputs = inputs.to(device) labels = labels.to(device) # 优化器梯度归零 optimizer.zero_grad() # 正向传播 + 反向传播 + 优化 outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # 输出统计信息 if i % 100 == 0: print('Epoch: %d Minibatch: %5d loss: %.3f' %(epoch + 1, i + 1, loss.item())) print('Finished Training')

#从测试集中取出8张图片 # 得到一组图像 images, labels = iter(testloader).next() # 展示图像 imshow(torchvision.utils.make_grid(images)) # 展示图像的标签 for j in range(8): print(classes[labels[j]])

#把图片输入模型,看看CNN把这些图片识别成什么 outputs = net(images.to(device)) _, predicted = torch.max(outputs, 1) # 展示预测的结果 for j in range(8): print(classes[predicted[j]])

#有几个都识别错了~~~ 让我们看看网络在整个数据集上的表现 correct = 0 total = 0 for data in testloader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item() print('Accuracy of the network on the 10000 test images: %d %%' % ( 100 * correct / total))

-
使用 VGG16 对 CIFAR10 分类
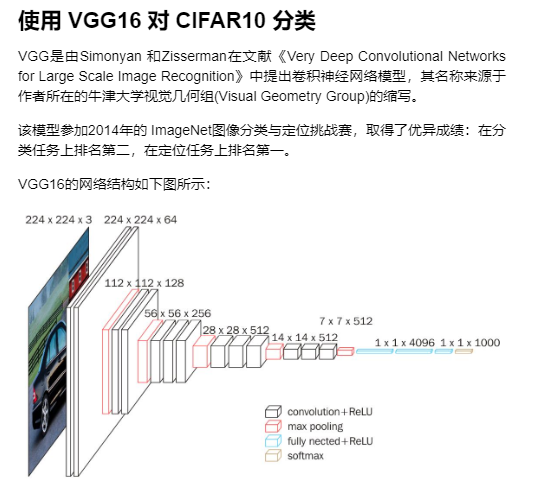

#定义 dataloader import torch import torchvision import torchvision.transforms as transforms import matplotlib.pyplot as plt import numpy as np import torch.nn as nn import torch.nn.functional as F import torch.optim as optim # 使用GPU训练,可以在菜单 "代码执行工具" -> "更改运行时类型" 里进行设置 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") transform_train = transforms.Compose([ transforms.RandomCrop(32, padding=4), transforms.RandomHorizontalFlip(), transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))]) transform_test = transforms.Compose([ transforms.ToTensor(), transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))]) trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train) testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=True, transform=transform_test) trainloader = torch.utils.data.DataLoader(trainset, batch_size=128, shuffle=True, num_workers=2) testloader = torch.utils.data.DataLoader(testset, batch_size=128, shuffle=False, num_workers=2) classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
#定义VGG网络 #初始化网络,根据实际需要,修改分类层。 #因为 tiny-imagenet 是对200类图像分类,这里把输出修改为200。 class VGG(nn.Module): def __init__(self): super(VGG, self).__init__() self.cfg=[64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'] self.features = self._make_layers(cfg) self.classifier = nn.Linear(2048, 10) def forward(self, x): out = self.features(x) out = out.view(out.size(0), -1) out = self.classifier(out) return out def _make_layers(self, cfg): layers = [] in_channels = 3 for x in cfg: if x == 'M': layers += [nn.MaxPool2d(kernel_size=2, stride=2)] else: layers += [nn.Conv2d(in_channels, x, kernel_size=3, padding=1), nn.BatchNorm2d(x), nn.ReLU(inplace=True)] in_channels = x layers += [nn.AvgPool2d(kernel_size=1, stride=1)] return nn.Sequential(*layers) # 网络放到GPU上 net = VGG().to(device) criterion = nn.CrossEntropyLoss() optimizer = optim.Adam(net.parameters(), lr=0.001)

错误暂时没解决
-
使用VGG模型迁移学习进行猫狗大战
import numpy as np import matplotlib.pyplot as plt import os import torch import torch.nn as nn import torchvision from torchvision import models,transforms,datasets import time import json # 判断是否存在GPU设备 device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") print('Using gpu: %s ' % torch.cuda.is_available()) ! wget http://fenggao-image.stor.sinaapp.com/dogscats.zip ! unzip dogscats.zip

normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) vgg_format = transforms.Compose([ transforms.CenterCrop(224), transforms.ToTensor(), normalize, ]) data_dir = './dogscats' dsets = {x: datasets.ImageFolder(os.path.join(data_dir, x), vgg_format) for x in ['train', 'valid']} dset_sizes = {x: len(dsets[x]) for x in ['train', 'valid']} dset_classes = dsets['train'].classes # 通过下面代码可以查看 dsets 的一些属性 print(dsets['train'].classes) print(dsets['train'].class_to_idx) print(dsets['train'].imgs[:5]) print('dset_sizes: ', dset_sizes) loader_train = torch.utils.data.DataLoader(dsets['train'], batch_size=64, shuffle=True, num_workers=6) loader_valid = torch.utils.data.DataLoader(dsets['valid'], batch_size=5, shuffle=False, num_workers=6) ''' valid 数据一共有2000张图,每个batch是5张,因此,下面进行遍历一共会输出到 400 同时,把第一个 batch 保存到 inputs_try, labels_try,分别查看 ''' count = 1 for data in loader_valid: print(count, end='\n') if count == 1: inputs_try,labels_try = data count +=1 print(labels_try) print(inputs_try.shape) # 显示图片的小程序 def imshow(inp, title=None): # Imshow for Tensor. inp = inp.numpy().transpose((1, 2, 0)) mean = np.array([0.485, 0.456, 0.406]) std = np.array([0.229, 0.224, 0.225]) inp = np.clip(std * inp + mean, 0,1) plt.imshow(inp) if title is not None: plt.title(title) plt.pause(0.001) # pause a bit so that plots are updated # 显示 labels_try 的5张图片,即valid里第一个batch的5张图片 out = torchvision.utils.make_grid(inputs_try) imshow(out, title=[dset_classes[x] for x in labels_try])


!wget https://s3.amazonaws.com/deep-learning-models/image-models/imagenet_class_index.json model_vgg = models.vgg16(pretrained=True) with open('./imagenet_class_index.json') as f: class_dict = json.load(f) dic_imagenet = [class_dict[str(i)][1] for i in range(len(class_dict))] inputs_try , labels_try = inputs_try.to(device), labels_try.to(device) model_vgg = model_vgg.to(device) outputs_try = model_vgg(inputs_try) print(outputs_try) print(outputs_try.shape) ''' 可以看到结果为5行,1000列的数据,每一列代表对每一种目标识别的结果。 但是我也可以观察到,结果非常奇葩,有负数,有正数, 为了将VGG网络输出的结果转化为对每一类的预测概率,我们把结果输入到 Softmax 函数 ''' m_softm = nn.Softmax(dim=1) probs = m_softm(outputs_try) vals_try,pred_try = torch.max(probs,dim=1) print( 'prob sum: ', torch.sum(probs,1)) print( 'vals_try: ', vals_try) print( 'pred_try: ', pred_try) print([dic_imagenet[i] for i in pred_try.data]) imshow(torchvision.utils.make_grid(inputs_try.data.cpu()), title=[dset_classes[x] for x in labels_try.data.cpu()])

print(model_vgg) model_vgg_new = model_vgg; for param in model_vgg_new.parameters(): param.requires_grad = False model_vgg_new.classifier._modules['6'] = nn.Linear(4096, 2) model_vgg_new.classifier._modules['7'] = torch.nn.LogSoftmax(dim = 1) model_vgg_new = model_vgg_new.to(device) print(model_vgg_new.classifier)

''' 第一步:创建损失函数和优化器 损失函数 NLLLoss() 的 输入 是一个对数概率向量和一个目标标签. 它不会为我们计算对数概率,适合最后一层是log_softmax()的网络. ''' criterion = nn.NLLLoss() # 学习率 lr = 0.001 # 随机梯度下降 optimizer_vgg = torch.optim.SGD(model_vgg_new.classifier[6].parameters(),lr = lr) ''' 第二步:训练模型 ''' def train_model(model,dataloader,size,epochs=1,optimizer=None): model.train() for epoch in range(epochs): running_loss = 0.0 running_corrects = 0 count = 0 for inputs,classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs,classes) optimizer = optimizer optimizer.zero_grad() loss.backward() optimizer.step() _,preds = torch.max(outputs.data,1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) count += len(inputs) print('Training: No. ', count, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format( epoch_loss, epoch_acc)) # 模型训练 train_model(model_vgg_new,loader_train,size=dset_sizes['train'], epochs=1, optimizer=optimizer_vgg) def test_model(model,dataloader,size): model.eval() predictions = np.zeros(size) all_classes = np.zeros(size) all_proba = np.zeros((size,2)) i = 0 running_loss = 0.0 running_corrects = 0 for inputs,classes in dataloader: inputs = inputs.to(device) classes = classes.to(device) outputs = model(inputs) loss = criterion(outputs,classes) _,preds = torch.max(outputs.data,1) # statistics running_loss += loss.data.item() running_corrects += torch.sum(preds == classes.data) predictions[i:i+len(classes)] = preds.to('cpu').numpy() all_classes[i:i+len(classes)] = classes.to('cpu').numpy() all_proba[i:i+len(classes),:] = outputs.data.to('cpu').numpy() i += len(classes) print('Testing: No. ', i, ' process ... total: ', size) epoch_loss = running_loss / size epoch_acc = running_corrects.data.item() / size print('Loss: {:.4f} Acc: {:.4f}'.format( epoch_loss, epoch_acc)) return predictions, all_proba, all_classes predictions, all_proba, all_classes = test_model(model_vgg_new,loader_valid,size=dset_sizes['valid'])

# 单次可视化显示的图片个数 n_view = 8 correct = np.where(predictions==all_classes)[0] from numpy.random import random, permutation idx = permutation(correct)[:n_view] print('random correct idx: ', idx) loader_correct = torch.utils.data.DataLoader([dsets['valid'][x] for x in idx], batch_size = n_view,shuffle=True) for data in loader_correct: inputs_cor,labels_cor = data # Make a grid from batch out = torchvision.utils.make_grid(inputs_cor) imshow(out, title=[l.item() for l in labels_cor]) # 类似的思路,可以显示错误分类的图片,这里不再重复代码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号