mysql去重、多列去重
MySQL 数据去重可是 MySQL 必会技能之一。比如,在数据库中找出使用相同 email 但不同 username 的用户等应用场景。
本教程将介绍 4 种删除重复数据的方法。SELECT DISTINCT、GROUP BY 、INNER JOIN 、ROW_NUMBER() ,它们各有各的特点。
准备数据
请登录你的 MySQL 服务器,然后将以下代码贴进去执行。我们先来创建教程示例数据:
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
);
INSERT INTO users (first_name,last_name,email)
VALUES ('Chuan ','Jiang','HiJiangChuan@gmail.com'),
('Chuan ','Jiang','HiJiangChuan@gmail.com'),
('Ch. ','Jiang','HiJiangChuan@gmail.com'),
('Ke','Xie','xieke@sina.com'),
('Ke','Xie','xieke@qq.com'),
('Amei','Song','amei@163.com');
select * from users;
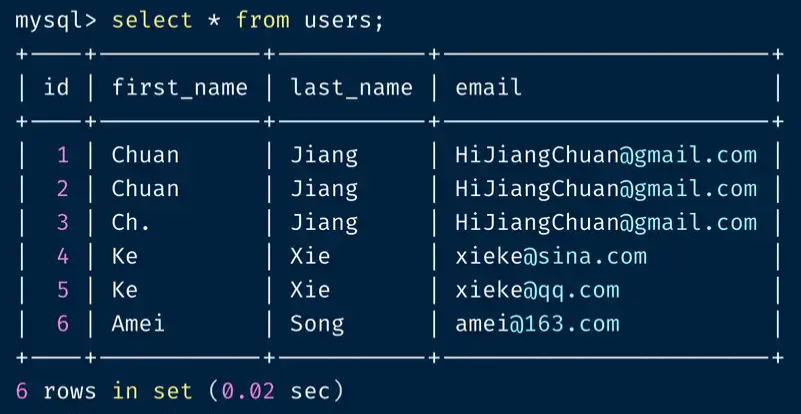
我们可以看到,示例数据中有多组不同程度的重复数据,接下来我们使用 4 种方法演示如何去重。
1. 使用 SELECT DISTINCT 命令去重
需求:查找 users 表中的数据,将记录中 first_name、 last_name、 email 这三列均重复的记录删掉,并重新整理 ID,使 ID 连续。
我们先新建一个表,然后使用 SELECT DISTINCT 去重,并把去重后的数据存进新表。
CREATE TABLE users_copy (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
);
INSERT INTO users_copy (first_name,last_name,email)
SELECT DISTINCT first_name,last_name,email FROM users;
我们用 select 来查看一下去重的效果:
select * from users_copy;
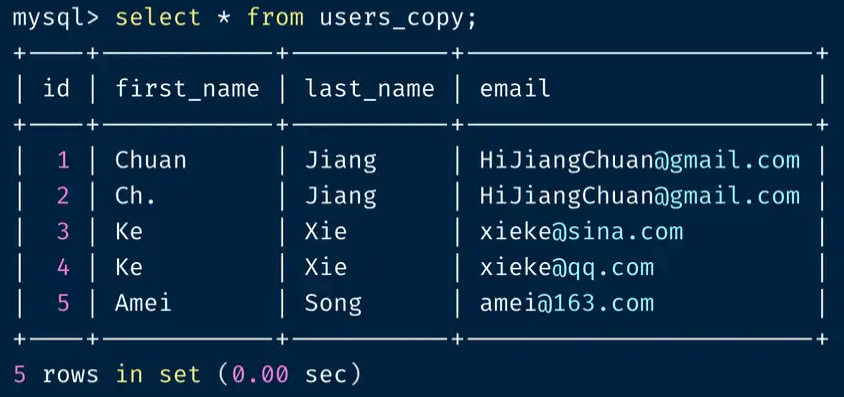
从返回结果看,与 ID 1 一模一样的 ID 2 被删掉,然后表格的 ID 进行了重置。
最后我们删掉 users 表,将 users_copy 改名为 users ,使用这种方法达到将原表去重的目的。
drop tables users;
alter table users_copy rename to users;
select * from users;
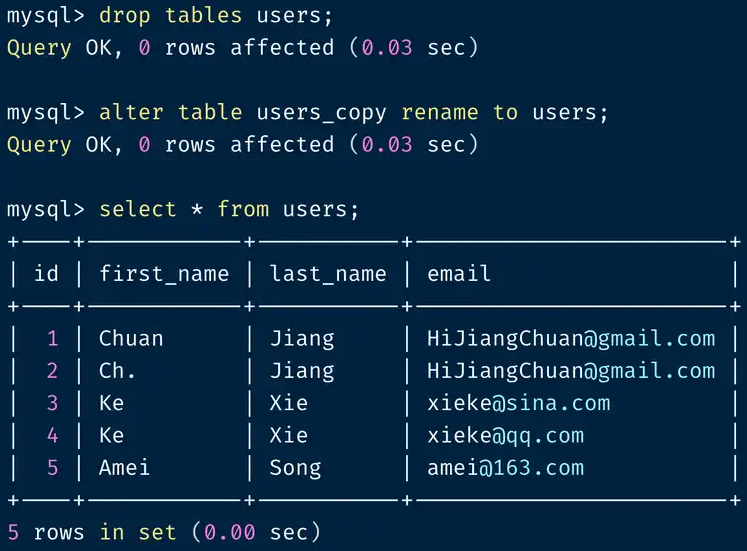
在这个示例中,我们删除了记录中,姓名和邮箱完全一致的重复用户信息,即删除所有列均是重复的记录。如果我们只想查某几个列是否重复应该怎么做呢?
2.使用 group by 命令去重
问题:只想查同一个姓和名,但邮箱不同(用户使用多个邮箱注册)的记录,然后删掉最有一条。
用上文的数据继续操作,我们使用 group by 去重,同样用创建中间表的方案:
CREATE TABLE users_group_by (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
);
INSERT INTO users_group_by (first_name,last_name,email)
SELECT first_name,last_name,ANY_VALUE(email)
FROM users
group by first_name,last_name;
我们来看一下效果:
SELECT * FROM users_group_by;
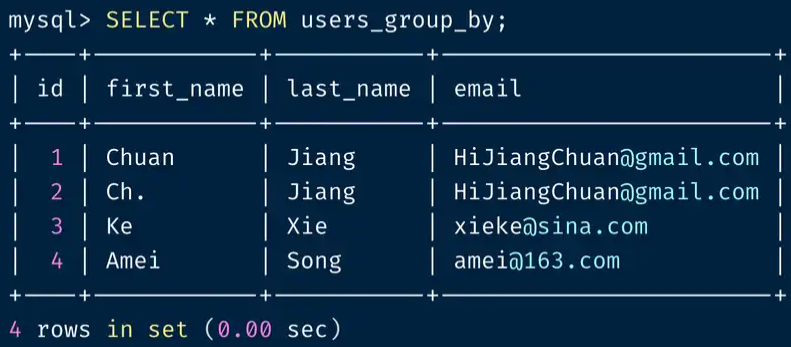
最后我们删掉 users 表,将 users_group_by 改名为 users ,使用这种方法达到将原表去重的目的。
drop tables users;
alter table users_group_by rename to users;
select * from users;
3. 使用 INNER JOIN 删除重复行
我们使用 DELETE 和 INNER JOIN 语句的组合对 MySQL 进行去重。使用这个组合时,我们的表需要有至少一个「唯一」的列(例如主键)
先来重置一下示例数据:
DROP TABLE users;
DROP TABLE users_copy;
DROP TABLE users_group_by;
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
email VARCHAR(255) NOT NULL
);
INSERT INTO users (first_name,last_name,email)
VALUES ('Chuan ','Jiang','HiJiangChuan@gmail.com'),
('Chuan ','Jiang','HiJiangChuan@gmail.com'),
('Ch. ','Jiang','HiJiangChuan@gmail.com'),
('ke','xie','xieke@caowutech.com'),
('ke','xie','xieke@qq.com'),
('amei','song','amei@163.com');
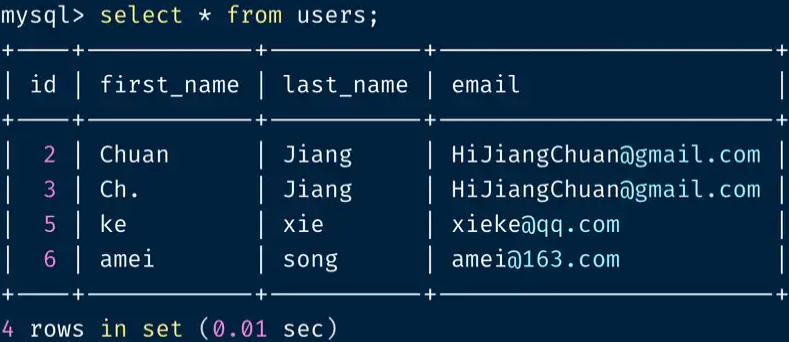
select * from users;
需求:找出 users 表中重复 first_name 和 last_name ,并将这一行记录删掉:
DELETE t1 FROM users t1
INNER JOIN users t2
WHERE
t1.id < t2.id
AND t1.first_name = t2.first_name AND t1.last_name = t2.last_name;
select * from users;
注意看 t1.id < t2.id ,SQL 会删掉两组记录对比中,ID 较小的记录,即重复记录中第一组数据,把这个符号反过来,则会保留重复记录中最后一组数据。
4. 使用 ROW_NUMBER() 删除重复记录
最后,我们来说说 ROW_NUMBER() 函数,从 MySQL 8.0 开始才支持此函数。
需求:找出 users 表中重复的 last_name 和 email,并将这一行记录删掉:
DELETE FROM users
WHERE id IN (
SELECT id
FROM (
SELECT
id, ROW_NUMBER () Over (PARTITION BY last_name,email ORDER BY id) as r
from users
) t
WHERE r > 1
);
select * from users;
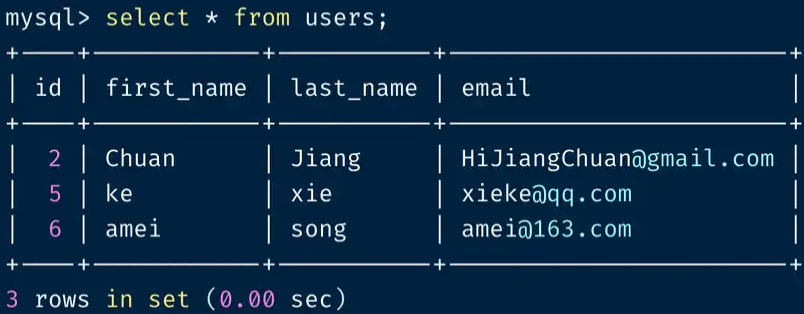
最后,我们获得了一组非常干净的 users 表。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号