

“我觉得无论是表还是库还是系统,能不分,就不分...有的问题,你Hold不住” Me
一、数据库读写分离快速介绍
1.简介
通常一个应用程序对于用户来说,关于数据的访问需求要远远大于数据的写需求,例如:我们可能一天刷100条朋友圈,但只会写一条(微商除外),看几个月抖音也不会传一个段子。在这样的需求背景下,当数据库访问性能瓶颈出现时,可以采取读写分离的方式缓解数据库负载压力,使用一主多从的集群,采取一定策略将写操作分配给主库,将读操作路由到从库来缓解主库压力。大多数关系型数据库都会提供主从复制的集群配置方式,具体的像日志复制、快照复制、同步更新等等,各有利弊,非本文重点描述内容。
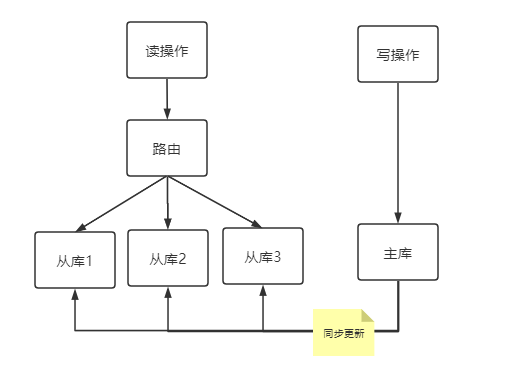
主从集群与读写分离
2.读写分离路由策略
主库路由策略:执行命令都在主库,但是也有查询需要在主库完成,集群数据的同步更新是需要时间代价的,根据业务需求判断,当这个时间代价不能满足强一致性需求时,可以直接从主库读。
从库路由策略:采取随机访问的策略,动态负载均衡策略等。
二、数据库分库分表快速介绍
1.为什么要分库分表
通常,当单表数据达到500W条时,查询效率下降相对显著,为了能够快速的响应,通常将一些体量非常大的数据表进行水平切分,以加快数据的查询性能。在实际应用开发过程中,有些表可能有上百个字段,其中常用的字段可能就那么几个,这时候业务层面上可以将表垂直拆分,使用主外键链接(或者相同主键,但是在一些场合不好保证,比如自增主键)。单库再怎么分表也不能解决单库I/O性能瓶颈问题,这时候可能会用到多库,可以将分表挂载到其他数据库上(数据库水平拆分),也可以根据业务领域划分,直接将库拆分为多个库(数据库垂直拆分)。
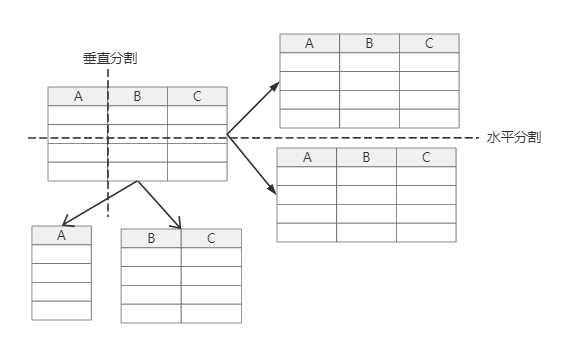
水平分表与垂直分表(BeibeiORM只实现水平分表,垂直分表业务耦合性太强,依赖用户自己实现)
2.水平分表产生的问题
当然,一切并不是那么美好,水平分表多了,系统复杂度就高了。
如何分表?分表与从库路由策略不一样,一定一定不能是随机的,必须是一个稳定的对应关系,这涉及到分表后的其他命令操作,为他们的路由方向建立依据,也是提高查询性能的依据(初衷)。常见的分表策略包括:主键号段分表(主键分为号段,例如从某个数开始,每增加500W条数据一个表。如果是自增主键,也可以采用设置步长的方式,五个表就设置步长为5,1,6,11...一个表,2,7,12...一个表),主键Hash分表(其实和步长分表类似,但是不仅仅是数字型主键),时间分表(不是特别可靠,主机时间可能回滚也可能不精确,力度太粗等等问题),前缀后缀等等等。
分表后如何操作?根据分表策略及其索要的参数来确定命令对象是哪个表,重点是这个查询问题,分表后Join操作、聚合操作、分组操作、排序操作都会受到影响。所以一定要慎重确定分表策略。
三、数据库访问命令设计:
一般的数据库访问工具都会数据库操作以“命令”的形式提供给用户使用,用户访问数据库访问命令接口发起命令(如:增删改查等),ORM工具的命令的内容常常需要动态的构建。
通常,一个命令需要以下几个部件支持:
- 命令的内容(是什么样的命令?命令的对象是谁?)
- 命令的参数(命令与环境的关系)
- 命令的结果
- 构建命令的路由(一个完整命令的构建过程)
1.命令的内容?
类别:对于DML(Data Manipulation Language)而言,一个语义明确的操作可分为两种类别,执行和查询,执行包含(数据库增、删、改操作)等非安全操作,查询即数据库查询操作。
命令的对象:关系、元组、字段。
2.命令的参数
命令参数除了个性化参数(例如:查询的表达式,插入的实体,事务的执行时长)外,需要一些环境参数,例如读写分离策略,分表分库策略及他们所需要的动态参数,这需要我们将这些环境变量封装起来,我称之为方案。
3.命令的结果
没想出啥特殊的地方,刨析的不清晰(暂略)
4.构建命令的路由
命令的路由根据命令的内容与采取的方案共同决定,例如:在”读写分离“策略下,通过内容的类别(增删改\查询)对命令进行路由。通常一个命令的操作对象终将被路由到一个具体的数据库表范围的内容(哪一行,哪些行,哪些字段),找到具体的这个表很重要。所以,在水平分表的要求下该命令对象要向分表策略传递其索要的参数而确定分表位置(哪个逻辑数据库(读写集群)的哪个表),从而再根据操作类别向读写分离策略进一步询问是哪个具体的数据库,最终获得该操作对象所在的具体表位置。
四、命令构建路由系统设计:
1.路由的目的
通过路由,动态构建一个完整的、符合预期的、正确的、可执行的命令。
2.逻辑概念建模
设计思路:根据前面的内容进行梳理,当下第一件事就是要对数据库、表进行逻辑概念的建模。
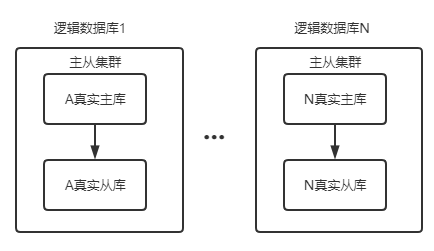
逻辑数据库建模
首先我们可以尝试,对于主从复制的集群,因为拥有相同的数据结构,也拥有相同的业务原因,仅仅是因为备份、性能等非业务原因而扩展的数据库集群划分为一个“逻辑数据库”。
从命令对象角度出发,最终路由匹配的终结点必然是一个具体的表,根据分表策略,全部分表可能是存在于单库,这时,可以通过逻辑数据库名称+表名称+操作类别就可以匹配,但是,也可能存在与跨库分表,所以仅仅对数据库进行逻辑划分是不够的。当出现夸库分表时,表与数据库不再是多对一的关系,而是多对多的关系,同样应当对表内容进行逻辑划分,说明哪些分表属于哪些逻辑数据库。

逻辑数据库、表建模
3.路由过程所需部件及交互过程
- 路由策略:读写分离策略、自定义策略、分库分表策略。
- 路由中间件:根据路由策略来构建完整命令。
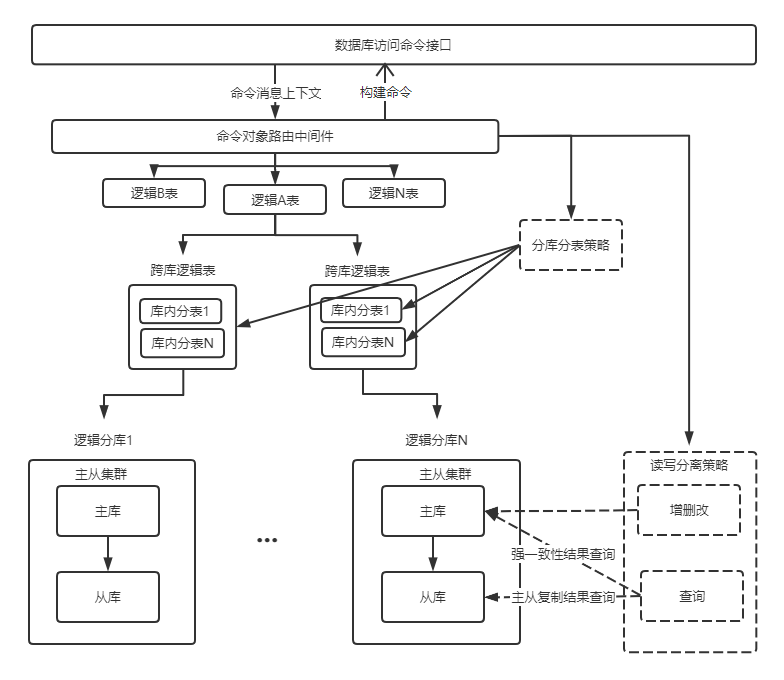
命令构建路由架构
五、总结
1.该部分代码很好实现,难弄的是概念,但是也需要慎重完善,目前未完成暂不开源(持续更新,后续提供系统设计部分)。
2.当出现多库时,事务将被提升为分布式事务,这时候又当如何?请待下文《BeibeiORM支持分库分表与读写分离的设计(一)分布式事务》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号